
数据导入与预处理-第4章-数据获取python读取docx文档
数据导入与预处理-第4章-pandas数据获取docx文档
1.python读取docx文档概述
1.1 从Word文件获取数据
Word(Microsoft Office Word)是微软公司的一款文字处理软件,在日常工作、学习中常被用于处理或存储文字信息。Word文件有两种扩展名.doc和.docx,其中扩展名.doc为微软专用格式,并未对外完全授权,兼容性低;而扩展名为.docx的文件无论是从文件体积大小、响应速度、兼容性等方面都优于.doc文件。
由于Pandas库中没有提供读取Word文件的功能,这里需要借助第三方库python-docx读取Word文件(扩展名为.docx)中的数据。
python-docx是一个Python中专门用于创建和修改Word(以.docx为后缀名)文件的库,该库中提供了Word文件的全套操作,可以轻松地对Word文件进行读写操作。
如果当前的环境中没有安装过python-docx库,那么需要先通过pip命令安装该库。
pip install python-docx
1.2 python-docx库介绍
python-docx库中主要有一个Document类,Document类的对象表示一个从Word文件加载、类似文件的对象,相当于一个Word文件。不同的Document类的对象对应不同的Word文件,这些对象是独立的,相互之间没有任何影响。
一个Word文件中的内容可能包含段落、标题、表格、样式等几种结构,同样地,Document类的对象包含对应各结构的属性。
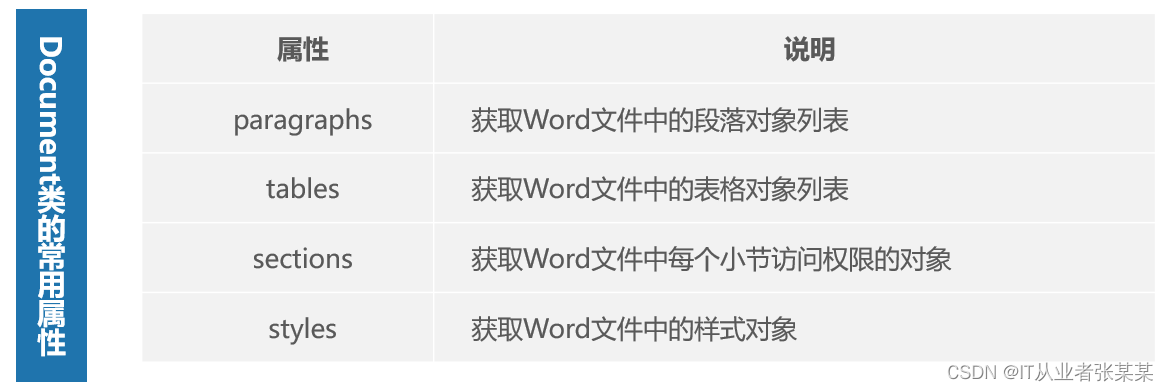
paragraphs和tables属性可用于获取Word文件中段落对象和表格对象的列表,其中段落对象是一个Paragraph类的对象,表格对象是一个Tables类的对象。
1. Paragraph类
Paragraph类对象对应Word文件的段落结构。一个Word文件可能由多个段落组成,一旦该文件中输入了一个换行符,就会产生一个新的段落。
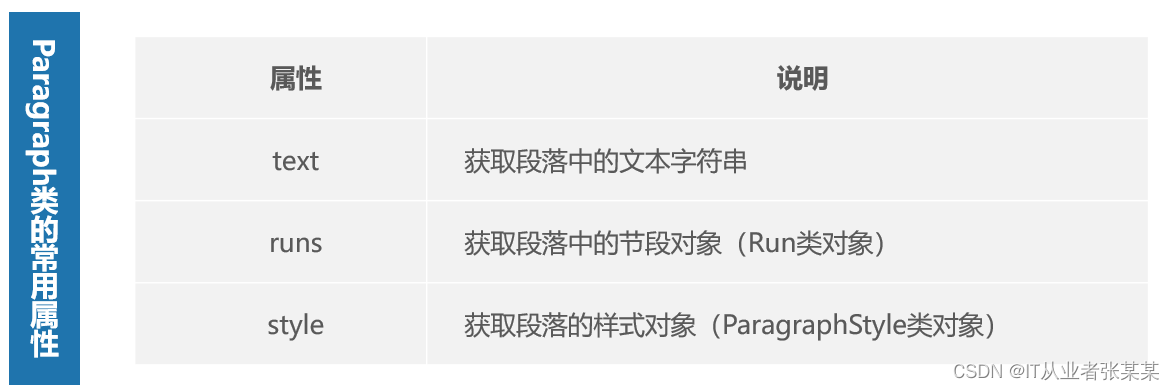
2. Table类
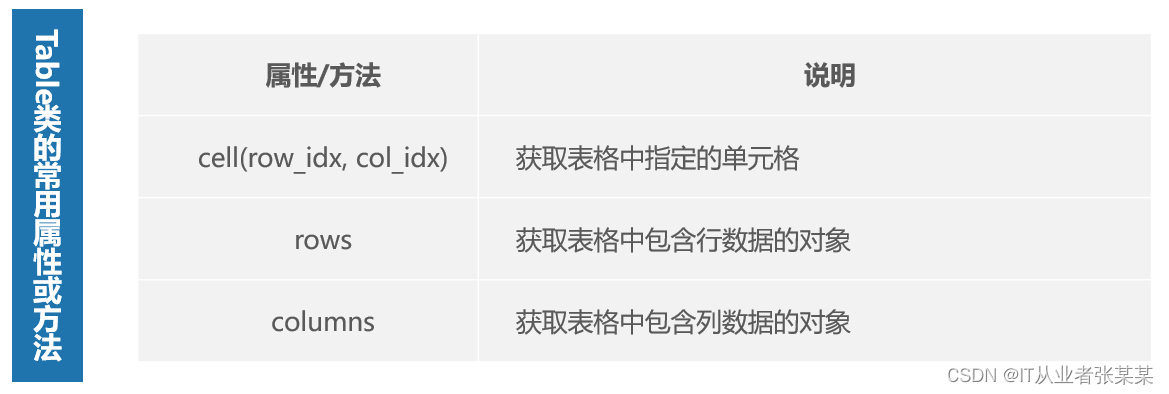
Table类对象对应Word文件的表格结构。虽然一个Word文件可能包含多个表格,但每个表格都是由若干个单元格组成,通过单元格的位置即可获取对象的单元格对象。
2.python-docx案例
2.1 基本操作
使用python-docx库读取Word文件的基本步骤
1.创建一个Document类对象
2.通过Document类对象的paragraphs或tables属性获取文件对象的段落对象或表格对象
3.通过段落对象或表格对象中的属性或方法获取文件内容
有一个Word文档,名称为 集合介绍.docx,下面我们将使用python-docx库读取该文件,并提取相关信息。
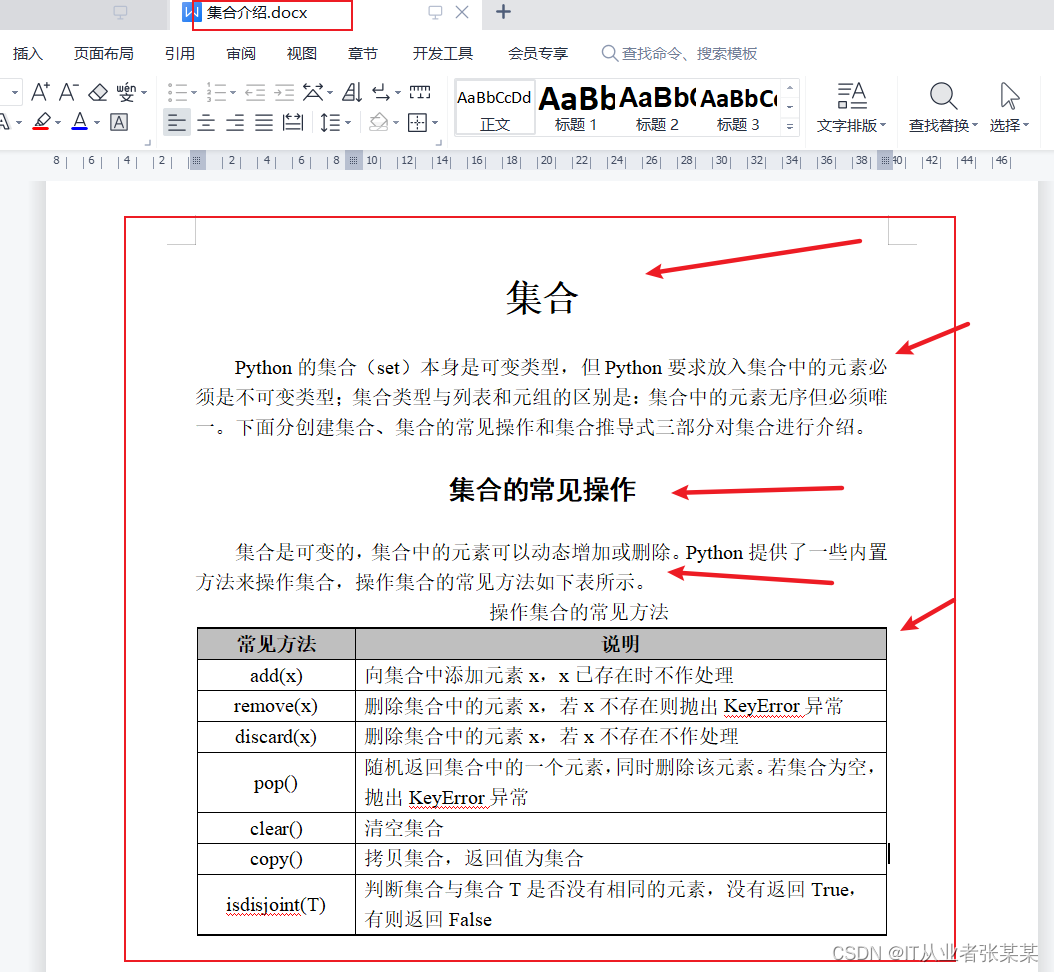
1.获取段落
代码:
import pandas as pd
import numpy as np
from docx import Document
# 创建Document类的对象
docx = Document('集合介绍.docx')
# 获取段落对象
paragraphs = docx.paragraphs
for i in paragraphs:
# 使用text属性获取段落中的字符串
print(i.text)
print("*"*15)
输出为:
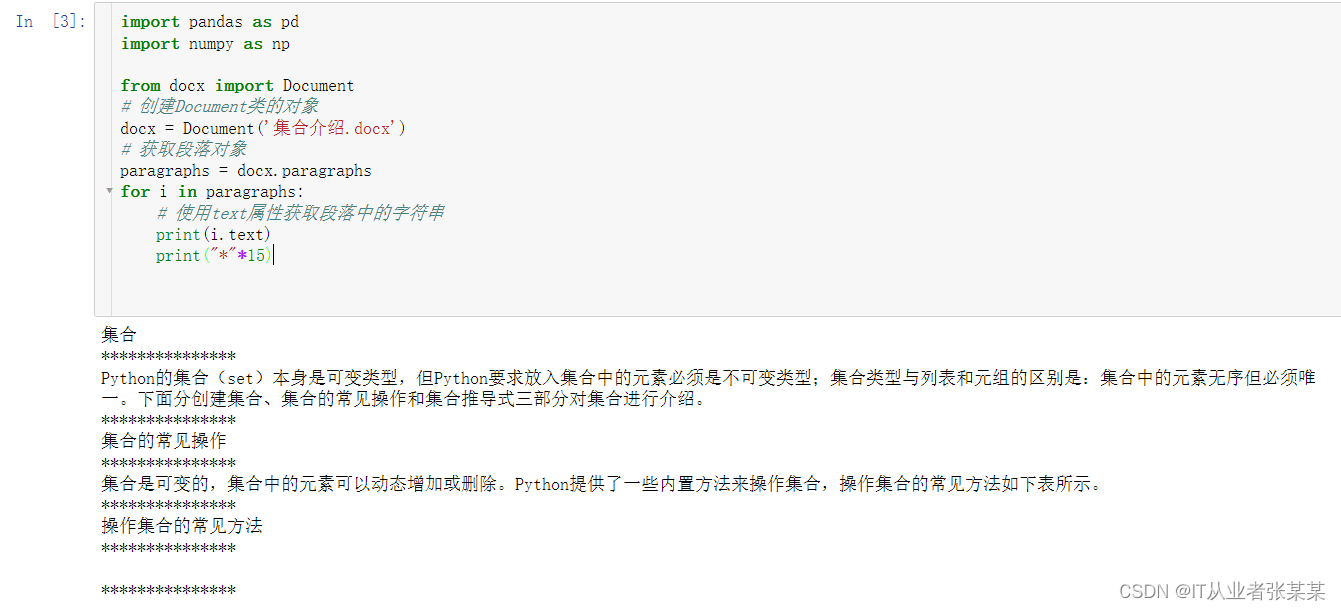
可以看出:每个换行符都代表一个段落
2. 获取表格
代码:
from docx import Document
# 创建Document对象实例
doc = Document('集合介绍.docx')
# 获取表格对象
tables = doc.tables
for table in tables:
for row in table.rows: # 获取行数据对象
row_content = [] # 用于保存表格数据的列表
for cell in row.cells[:]: # 获取单元格对象
row_content.append(cell.text) # 获取单元格中的字符串
print(row_content) # 以列表形式显示每一行数据
print("*"*15)
输出为:
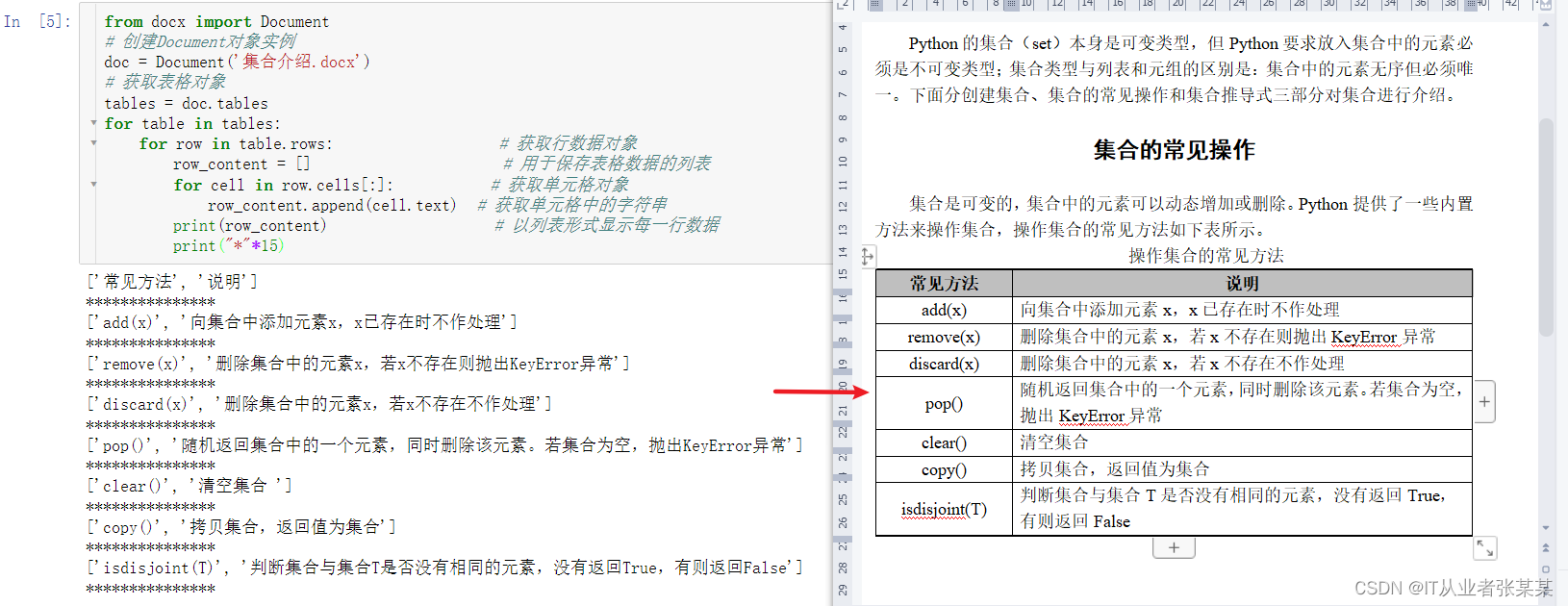
2.2 实战案例
在一个高校里,有许多的人才培养方案,现在需要对人才培养方案统计,提取其中的
人才培养方案为大部分为word文档,格式包含doc和docx两种,部分为PDF格式,PDF格式的文件处理,将在单独写博客进行拓展,本文仅对word文件进行处理。
2.2.1 查看原始数据目录结构
在进行操作前,首先对数据进行编码,去除学院,专业信息。进入到人才培养方案目录下,执行如下命令
E:\vscode\reddemo\edudata>tree /f > tree.txt
生成tree.txt文件,该文件中内容如下:
一级目录01-14代表04个学院,每个学院下有二级目录,二级目录包括一本,普本,双学位,合作办学等多种专业设置,每个二级目录下有对应三级文件,文件为对应专业的人才培养方案。
具体内容如下:
E:.
│ tree.txt
│
├─01
│ ├─一本
│ │ 01人才培养方案(2021版)2021年9月13日 - 02.docx
│ │ 02人才培养方案-2021版.doc
│ │
│ └─普本
│ 03.doc
│ 04.doc
│ 05.docx
│
├─02
│ │ 0224+工程造价双学位(更新后20211009).doc
│ │
│ ├─一本
│ │ 01.docx
│ │ 02.docx
│ │
│ ├─双学位
│ │ 022.doc
│ │ 042.doc
│ │
│ └─普本
│ 03.docx
│ 04.docx
│ 05.docx
│ 06.docx
│ 08.docx
│
├─03
│ ├─一本
│ │ 04.docx
│ │
│ └─普本
│ 01.docx
│ 02.docx
│ 03.docx
│ 05.docx
│
├─04
│ ├─普本
│ │ 01.doc
│ │ 01.docx
│ │ 02.docx
│ │ 03.docx
│ │
│ └─第二学士学位
│ 012.doc
│ 022.docx
│
├─05
│ ├─一本
│ │ 05.doc
│ │
│ └─普本
│ 04.docx
│ 06.docx
│
├─06
│ ├─一本
│ │ 01.docx
│ │
│ └─普本
│ 01.docx
│ 03.docx
│ 04.docx
│ 05.docx
│
├─07
│ 01.doc
│ 02.docx
│ 03.docx
│ 04.docx
│
├─08
│ ├─一本
│ │ 06.docx
│ │
│ └─普本
│ 01.pdf
│ 02.pdf
│ 05.docx
│
├─09
│ │ 01.docx
│ │ 02.doc
│ │ 03.docx
│ │ 04.docx
│ │
│ └─合作办学
│ 01.docx
│
├─10
│ 01.doc
│ 02.docx
│ 03.docx
│ 04.docx
│
├─11
│ └─普本
│ │ 01.docx
│ │ 03.docx
│ │ 04.docx
│ │
│ └─第二学士学位
│ 04.docx
│
├─12
│ ├─普本
│ │ 01.docx
│ │ 02.docx
│ │ 03.docx
│ │
│ └─第二学位
│ 03金融数学专业第二学士学位.docx
│
├─13
│ 01.docx
│ 02.docx
│
└─14
│ 01.docx
│
├─专升本
│ 01.docx
│
├─双学位
│ 012.docx
│
└─第二学士学位
01.docx
查看单个文件 E:\vscode\reddemo\edudata\02\一本\02.docx,内容如下:
02专业(本科)人才培养方案
一、专业名称:02
二、修业年限及毕业学分要求:基本学XXX求170学分。
三、授予学位:工学学士
四、培养目标:
本专业培养适应我国社会XX用型人才。
五、毕业要求:
1 工程知识:能够将XXX题。
指标1.1 能够XX问题;
指标1.2 能够XX模型;
指标1.3 能够XX方案;
2 问题分析:能够XX结论。
指标2.1 能够XX环节;
指标2.2 能够XX表达;
指标2.3 能够XX结论。
3 设计/开发解决方案:能够XX等因素。
指标3.1 掌握XX因素;
指标3.2 能够XX审核;
指标3.3 能够XX改进;
指标3.4 能XX因素。
4 研究:能够XX结论。
指标4.1 能够XX方案;
指标4.2 能够XX方案;
指标4.3 能够XX数据;
指标4.4 能够XX结论。
5 使用XX局限性。
指标5.1 了解XX性;
指标5.2 能够XX并运用于复杂工程问题;
指标5.3 能够XX其局限性。
6 工程与社会:能够XX的责任。
指标6.1 能够XX影响;
指标6.2 能够XX影响。
指标6.3 能够XX责任。
7 环境和XX的影响。
指标7.1 能够XX内涵;
指标7.2 能XX评价;
指标7.3 能够XX理念。
8 职业规范:具有XX责任。
指标8.1 能够XX国情;
指标8.2 能够XX责任。
9 个人和团队:能够XX角色。
指标9.1 能够胜任XX的任务;
指标9.2 能够与XX能力。
10 沟通:能够XX交流。
指标10.1 能够XX交流;
指标10.2 了解XX交流。
11 项目管理:理解XX应用。
指标11.1 掌握XX方法;
指标11.2 了解建XX问题;
指标11.3 能够XX控制。
12.终身学习:具有XX能力。
指标12.1 拥有健康的体魄,能够正确面对压力,快速适应社会的发展;
指标12.2 能够认识到自主学习和终身学习的重要性,拥有自主学习的能力,XX问题;
指标12.3 能够适应行业发展,具有不断跟踪和学习学科前沿的能力。
六、主干学科:
(1)管XX程
(2)土XX程
七、主要课程:
工程XX审计等。
八、学分学时比例说明:
总学分为170学分,其中课内学分(含课内实践)为119.5学分,占总学分的70.29%,实践教学(含课内实践、集中实践、综合实践)学分为60.5学分,占总学分的35.59%;选修课学分为44学分,占总学分的25.88%。通识教育平台学分为48学分,占总学分的28.24%,学科基础教育平台学分为29.5学分,占总学分的17.35%,专业教育平台学分为42学分,占总学分的24.71%。
课内总学时(含课内实践)为1976学时,其中选修课学时为400学时,占课内总学时的20.24%。通识教育平台学时为832学时,占课内总学时的42.11%;学科基础教育平台学时为472学时,占课内总学时的23.89%,专业教育平台学时为672学时,占课内总学时的34.01%。
九、备注说明:
--------。
十、附表
附表1:专业XX配表
附表2:专业XX示表
附表3:实践XX平台
附表4:通识XX平台
附表5:学科XX平台
附表6:专业XX平台
附表7:毕业XX矩阵
附表8:毕业XX矩阵
2.2.2 将doc文件转换成docx文件
采用pywin32操做Word,doc文件转换为docx文件。安装pywin32库
pip install pywin32==227
转换代码如下:
from win32com import client as wc
def doc_read(file1):
word = wc.Dispatch("Word.Application") # 打开word程序
doc = word.Documents.Open(file1) # 打开word文档
doc.SaveAs(file1+"x",12) # 另存为
doc.Close() # 关闭 word 文档
word.Quit() # 关闭 office
2.2.3 查看单个文件,并提取培养目标和学分学时比例说明
导入相关依赖
from glob import glob
import re
from win32com import client as wc
# import docx
from docx import Document
import pandas as pd
import os
import numpy as np
# Python glob()函数,是种文件通配符,非常常用。glob模块提供了函数用于从目录通配符搜索中生成文件列表
读取单个文件,并获取培养目标和学分学时比例说明数据
filename1 = r"E:\vscode\reddemo\edudata\02\一本\02.docx"
# 可以存储到字典中了,但字典格式可以优化下
import numpy as np
# 创建一个接受匹配不成功的反馈记录
# 第4项的数据 培养目标
re_4_start =re.compile("^四.{1}培养目标") # 匹配用 四.{1}培养目标 开头的文本
re_4_end =re.compile("^五.{1}毕业要求:")
# 第8项的数据 学分学时比例说明数据
re_8_start =re.compile("^八.{1}学分学时比例说明")
re_8_end =re.compile("^九.{1}备注说明")
# 抽取模式,不校验数据的准确性
def docx_read(file1):
# 定义接受当前文档的part_4和part_8
part_all_dict_new = {}
# print("当前文件:====>",os.path.join("",file1))
document = Document(os.path.join("",file1))
# df=pd.DataFrame(columns =['总学分','课内学分','课内学分占比','实践教学学分','实践教学占比','选修课学分',
# '选修课学分占比','通识教育平台学分','通识教育平台学分占比','学科基础教育平台学分','学科基础教育平台学分占比',
# '专业教育平台学分','专业教育平台学分占比'])
# 所有的段落,存放list
all_paragraphs = document.paragraphs
start_4_part = 0 # 培养目标 起始位置
end_4_part = 0 # 培养目标 结束位置
start_8_part = 0 # 学分学时比例说明 起始位置
end_8_part = 0 # 学分学时比例说明 结束位置
start_paragraphs_num = 0 # 定义段落初始值为0
for i in all_paragraphs: # 便利所有的段落
start_paragraphs_num +=1
if(re.match(re_4_start,i.text)): # 如果该段以 四.{1}培养目标 为开头
start_4_part = start_paragraphs_num # 将该段落的值设置为 培养目标 起始位置
elif (re.match(re_4_end,i.text)): # 如果该段以 五.{1}毕业要求: 为开头
end_4_part = start_paragraphs_num
elif(re.match(re_8_start,i.text)): # 如果该段以 八.{1}学分学时比例说明 为开头
start_8_part = start_paragraphs_num
elif(re.match(re_8_end,i.text)): # 如果该段以 九.{1}备注说明 为开头
end_8_part = start_paragraphs_num
else:
pass
# 提取第4部分内容
str_4_part_all = ""
if start_4_part ==0 or end_4_part ==0 :
print(file1,"的第4部分无法匹配")
else:
print("start_4_part : ",start_4_part)
print("end_4_part : ",end_4_part)
part_4 = all_paragraphs[start_4_part:end_4_part-1] # 通过list切片的方式获取 第4部分培养目标 的全部段落数据
for i in part_4:
str_4_part_all = str_4_part_all+i.text # 把所有段落拼接到一个字符串变量str_4_part_all 中
# print(str_4_part_all,"第4段的完成匹配")
# 提取第8部分内容
str_8_part_all = ""
if start_8_part ==0 or end_8_part ==0 :
print(file1,"的第8部分无法匹配")
else:
print("start_8_part : ",start_8_part)
print("end_8_part : ",end_8_part)
part_8 = all_paragraphs[start_8_part:end_8_part-1]
for i in part_8:
str_8_part_all = str_8_part_all+i.text
# print(str_8_part_all,"的第8部分完成匹配")
# print()
# part_all_dict_new[file1+".id"] = file1
# part_all_dict_new[file1+".part_4"] = str_4_part_all
# part_all_dict_new[file1+".part_8"] = str_8_part_all
# ID为文件名称 part_4为第4部分数据 part_8为第8部分数据
part_all_dict_new[file1]={
"ID":file1,
"part_4":str_4_part_all,
"part_8":str_8_part_all,
}
return file1,part_all_dict_new
print("*"*10)
file1,part_all_dict_new = docx_read(filename1)
print(file1)
print(part_all_dict_new)
运行,输出为:
**********
start_4_part : 8
end_4_part : 10
start_8_part : 63
end_8_part : 66
E:\vscode\reddemo\edudata\02\一本\02.docx
{‘E:\vscode\reddemo\edudata\02\一本\02.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\02\一本\02.docx’, ‘part_4’: ‘本专业培养适应我国社会主义现代化建设需要,德智体美劳全面发展,具有扎XX领域理论基础和专业知识,并熟练XXX人才。’, ‘part_8’: ‘总学分为170学分,其中课内学分(含课内实践)为119.5学分,占总学分的70.29%,实践教学(含课内实践、集中实践、综合实践)学分为60.5学分,占总学分的35.59%;选修课学分为44学分,占总学分的25.88%。通识教育平台学分为48学分,占总学分的28.24%,学科基础教育平台学分为29.5学分,占总学分的17.35%,专业教育平台学分为42学分,占总学分的24.71%。课内总学时(含课内实践)为1976学时,其中选修课学时为400学时,占课内总学时的20.24%。通识教育平台学时为832学时,占课内总学时的42.11%;学科基础教育平台学时为472学时,占课内总学时的23.89%,专业教育平台学时为672学时,占课内总学时的34.01%。’}}
2.2.4 获取指定目录下所有文档中的数据
通过遍历的方式,获取指定目录下的所有文件,并对doc文件另存为docx文件,提取docx中的相关数据,代码如下:
filedirs=r'E:\vscode\reddemo\edudata' # 所有文件存在的路径
# filenames = os.listdir("str1")
part_all_dict_new = {} # 存放所有匹配到的文件中的 四.{1}培养目标" 和八.{1}学分学时比例说明 数据
def contentExtract(str1): # 内容抽取函数
files = glob(str1 + '/*') # 匹配指定目录下的所有多层目录
print(files)
for i in files:
print("当前文件为:",i)
if re.findall('.docx',i): # 如果当前文件为docx结尾
fname,part_all_dict = docx_read(str(i)) # fname为文件名称ID,part_all_dict为该文件内容抽取后匹配到的数据
# print(part_all_dict[fname])
part_all_dict_new[fname] = part_all_dict[fname] # 将指定文件抽取后的数据 写入 part_all_dict_new字典, 用文件名称ID作为key
# print("part_all_dict_new[fname]",part_all_dict_new[fname])
# print(part_all_dict)
# part_all_dict_new.update(part_all_dict)
elif re.findall('.doc',i): # 如果当前文件以doc结尾
doc_read(str(i)) # 将doc文件另存为docx
fname,part_all_dict =docx_read(str(i) + 'x') # 读取另存后的docx文件
part_all_dict_new[fname] = part_all_dict[fname]
# print(part_all_dict)
# part_all_dict_new.update(part_all_dict)
elif re.findall('.pdf',i): # 如果当前文件以pdf结尾
print("这是一个pdf文件")
elif os.path.isdir(i):
print("当前为目录:",i)
contentExtract(str(i)) # 迭代 如果为目录
# print("part_all_dict_new*******",part_all_dict_new)
return part_all_dict_new
part_all_dict_new1 = contentExtract(filedirs)
part_all_dict_new1
输出为:
Output exceeds the size limit. Open the full output data in a text editor
[‘E:\vscode\reddemo\edudata\01’, ‘E:\vscode\reddemo\edudata\02’, ‘E:\vscode\reddemo\edudata\03’, ‘E:\vscode\reddemo\edudata\04’, ‘E:\vscode\reddemo\edudata\05’, ‘E:\vscode\reddemo\edudata\06’, ‘E:\vscode\reddemo\edudata\07’, ‘E:\vscode\reddemo\edudata\08’, ‘E:\vscode\reddemo\edudata\09’, ‘E:\vscode\reddemo\edudata\10’, ‘E:\vscode\reddemo\edudata\11’, ‘E:\vscode\reddemo\edudata\12’, ‘E:\vscode\reddemo\edudata\13’, ‘E:\vscode\reddemo\edudata\14’, ‘E:\vscode\reddemo\edudata\tree.txt’]
当前文件为: E:\vscode\reddemo\edudata\01
当前为目录: E:\vscode\reddemo\edudata\01
[‘E:\vscode\reddemo\edudata\01\一本’, ‘E:\vscode\reddemo\edudata\01\普本’]
当前文件为: E:\vscode\reddemo\edudata\01\一本
当前为目录: E:\vscode\reddemo\edudata\01\一本
[‘E:\vscode\reddemo\edudata\01\一本\01人才培养方案(2021版)2021年9月13日 - 02.docx’, ‘E:\vscode\reddemo\edudata\01\一本\02人才培养方案-2021版.doc’, ‘E:\vscode\reddemo\edudata\01\一本\02人才培养方案-2021版.docx’]
当前文件为: E:\vscode\reddemo\edudata\01\一本\01人才培养方案(2021版)2021年9月13日 - 02.docx
E:\vscode\reddemo\edudata\01\一本\01人才培养方案(2021版)2021年9月13日 - 02.docx 的第4部分无法匹配
E:\vscode\reddemo\edudata\01\一本\01人才培养方案(2021版)2021年9月13日 - 02.docx 的第8部分无法匹配
当前文件为: E:\vscode\reddemo\edudata\01\一本\02人才培养方案-2021版.doc
start_4_part : 9
end_4_part : 18
E:\vscode\reddemo\edudata\01\一本\02人才培养方案-2021版.docx 的第8部分无法匹配
当前文件为: E:\vscode\reddemo\edudata\01\一本\02人才培养方案-2021版.docx
start_4_part : 9
end_4_part : 18
E:\vscode\reddemo\edudata\01\一本\02人才培养方案-2021版.docx 的第8部分无法匹配
当前文件为: E:\vscode\reddemo\edudata\01\普本
当前为目录: E:\vscode\reddemo\edudata\01\普本
[‘E:\vscode\reddemo\edudata\01\普本\03.doc’, ‘E:\vscode\reddemo\edudata\01\普本\03.docx’, ‘E:\vscode\reddemo\edudata\01\普本\04.doc’, ‘E:\vscode\reddemo\edudata\01\普本\04.docx’, ‘E:\vscode\reddemo\edudata\01\普本\05.docx’]
当前文件为: E:\vscode\reddemo\edudata\01\普本\03.doc
start_4_part : 9
end_4_part : 11
start_8_part : 21
…
end_4_part : 9
start_8_part : 22
end_8_part : 25
当前文件为: E:\vscode\reddemo\edudata\tree.txt
Output exceeds the size limit. Open the full output data in a text editor
{‘E:\vscode\reddemo\edudata\01\一本\01人才培养方案(2021版)2021年9月13日 - 02.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\01\一本\01人才培养方案(2021版)2021年9月13日 - 02.docx’,
‘part_4’: ‘’,
‘part_8’: ‘’},
‘E:\vscode\reddemo\edudata\01\一本\02人才培养方案-2021版.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\01\一本\02人才培养方案-2021版.docx’,
‘part_4’: ‘培养XX并具有自主学习和适应发展的能力。’,
‘part_8’: ‘’},
‘E:\vscode\reddemo\edudata\01\普本\03.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\01\普本\03.docx’,
‘part_4’: ‘本专业XX应用技术型人才。’,
‘part_8’: ‘总学分为170学分,XX占课内总学时的26.2%。’},
‘E:\vscode\reddemo\edudata\01\普本\04.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\01\普本\04.docx’,
‘part_4’: ‘本专业培养适应XX应用技术型人才。’,
‘part_8’: ‘总学分为170学分,其中课内XX占总学时的21%。’},
‘E:\vscode\reddemo\edudata\01\普本\05.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\01\普本\05.docx’,
‘part_4’: ‘培养适应XX才。’,
‘part_8’: ‘总学分为170学分,XX占课内总学时的15.02%。’},
‘E:\vscode\reddemo\edudata\02\0224+工程造价双学位(更新后20211009).docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\02\0224+工程造价双学位(更新后20211009).docx’,
‘part_4’: ‘’,
‘part_8’: ‘’},
‘E:\vscode\reddemo\edudata\02\一本\01.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\02\一本\01.docx’,
‘part_4’: ‘工程管理专业培养适应XX能力。’,
‘part_8’: ‘总学分为170学分,XX占课内总学时的31.20%。’},
‘E:\vscode\reddemo\edudata\02\一本\02.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\02\一本\02.docx’,
‘part_4’: ‘本专业培养XX人才。’,
‘part_8’: ‘总学分为170学分,XX占课内总学时的34.01%。’},
‘E:\vscode\reddemo\edudata\02\双学位\022.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\02\双学位\022.docx’,
…
‘part_4’: ‘法学双学位XX工作。’,
‘part_8’: ‘总学分为50学分,XX占课内总学时的37.5%。’},
‘E:\vscode\reddemo\edudata\14\第二学士学位\01.docx’: {‘ID’: ‘E:\vscode\reddemo\edudata\14\第二学士学位\01.docx’,
‘part_4’: ‘本专业XX人才。’,
‘part_8’: ‘总学分为80学分,XX占课内总学时的51.6%。’}}
以上会返回一个字典,包含了文件名,第4部分内容,第8部分内容
2.2.5 将结果字典保存到DataFrame中
通过字典转换为DataFrame格式。
df1 = pd.DataFrame(part_all_dict_new)
df1
转置DataFrame,并重置索引
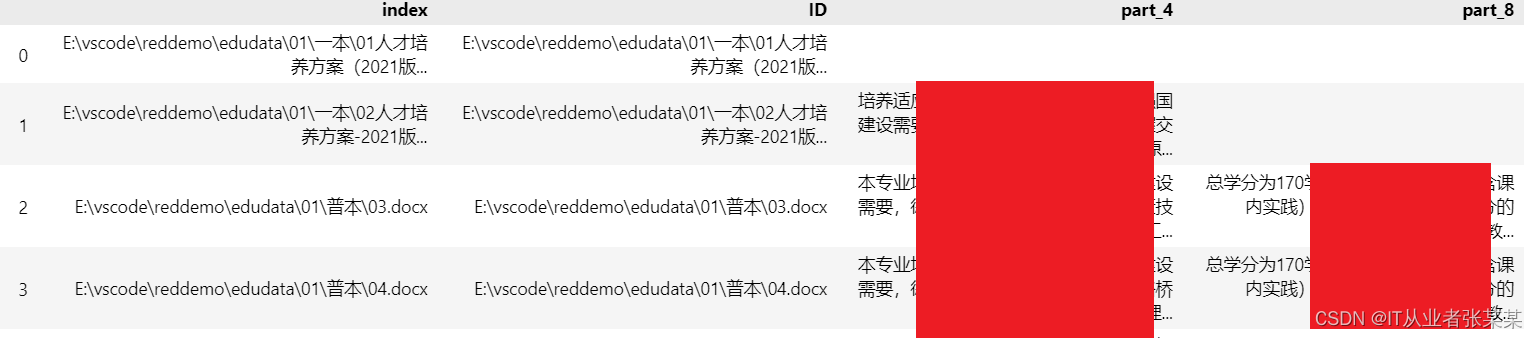
dfnew = df1.T
dfnew1 = dfnew.reset_index()
dfnew1
输出为:
删除index列
del dfnew1["index"]
dfnew1
输出为:

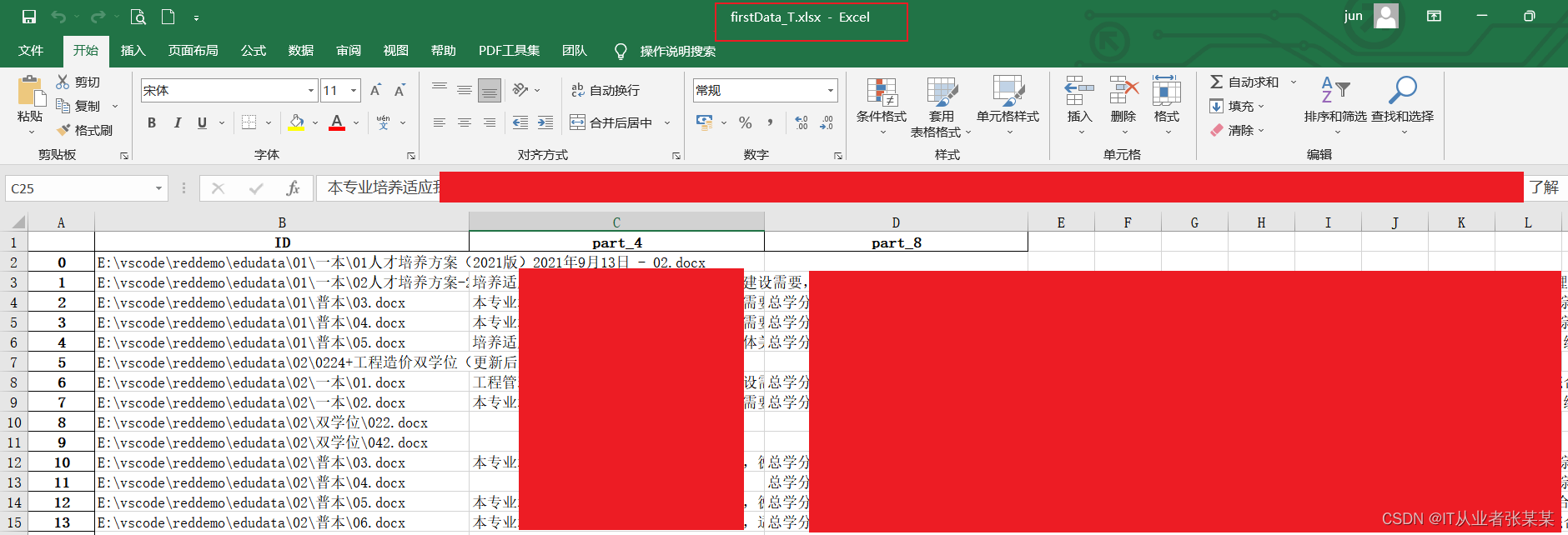
把数据保存到excel中
dfnew1.to_excel("firstData_T.xlsx",encoding="UTF-8")
生成的如下所示:
2.2.6 提取学分学时数据并保存
定义一个DataFrame,用来获取part_8中的学分学时信息
dfnew1_split=pd.DataFrame(columns =['总学分','课内学分','课内学分占比','实践教学学分','实践教学占比','选修课学分',
'选修课学分占比','通识教育平台学分','通识教育平台学分占比','学科基础教育平台学分','学科基础教育平台学分占比',
'专业教育平台学分','专业教育平台学分占比','课内总学时','选修课学时','选修课学时占比','通识教育平台学时',
'通识教育平台学时占比','学科基础教育平台学时','学科基础教育平台学时占比','专业教育平台学时',
'专业教育平台学时占比','ID'])
print(dfnew1_split.shape)
dfnew1_split.set_index('ID',inplace=True)
dfnew1_split
输出为:
 以上代码定义了一个空的DataFrame。
以上代码定义了一个空的DataFrame。
遍历dfnew1的每一行数据,并对part_8列数据进行正则表达式匹配,获取学时学分数据。
dfnew1的数据如下:
代码如下:
for i in range(dfnew1['ID'].count()): # 根据数据行数进行遍历
str1 = dfnew1['ID'][i] # 获取第i行的id 即文件全路径
str1 = str1[26:] # 切片操作
str1 = str1.replace('.docx','') # 替换掉docx
# 定义正则表达式匹配数据
# 原始数据为
'''
总学分为173学分,其中课内学分(含课内实践)为134学分,占总学分的77.5%,
实践教学(含课内实践、集中实践、综合实践)学分为60.5学分,占总学分的35%;
选修课学分为21学分,占总学分的12.1%。
通识教育平台学分为48学分,占总学分的27.7%,
学科基础教育平台学分为44学分,占总学分的25.4%,专业教育平台学分为42学分,占总学分的24.3%。
课内总学时(含课内实践)为2208学时,其中选修课学时为336学时,占课内总学时的15.2%。
通识教育平台学时为832学时,占课内总学时的37.7%;
学科基础教育平台学时为704学时,占课内总学时的31.9%,
专业教育平台学时为672学时,占课内总学时的30.4%。
'''
reg = '总学分.*课内学分.*实践教学.*选修课.*通识教育平台.*学科基础教育.*专业教育平台.*课内总学时.*选修课.*通识教育平台.*学科基础教育.*专业教育平台.*'
if len(re.findall(reg,str(dfnew1['part_8'][i])))!=0:
q=re.findall(r'[0-9]+\.?[0-9]*',str(dfnew1['part_8'][i]))
# q的值为list类型,值为 '170 129 75.88 73.5 43.24 23 13.53 48 28.24 26 15.29 55 32.35 2128 368 17.29 832 39.10 416 19.55 880 41.35'
# print(len(q))
# print(q)
dfnew1_split.loc[str1]=q
else:
dfnew1_split.loc[str1]=''
dfnew1_split
保存数据到excel
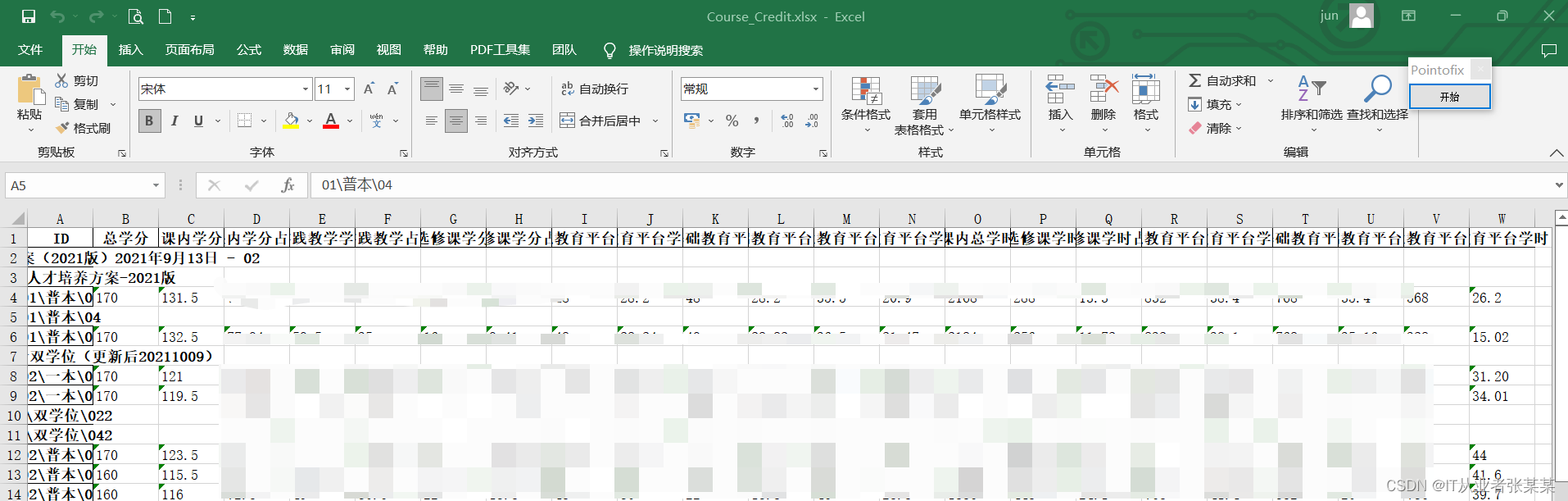
dfnew1_split.to_excel("Course_Credit.xlsx",encoding="UTF-8")
保存后的数据如下:
相关文章
- Python练习1-文档格式化成html
- Python中的Pexpect模块的简单使用
- python与C++的效率区别、模型部署/ONNXRuntime/tensorrt
- python 判断文件夹或文件是否存在
- python lambda表达式解释实例
- 弄明白python reduce 函数
- Word处理控件Aspose.Words功能演示:在 Python 中比较两个 Word 文档
- Word处理控件Aspose.Words功能演示:使用 Python 在 Word 文档中创建表格
- 【华为OD机试真题 python】 数字反转打印【2022 Q4 | 100分】
- python函数的用法详解(作用、定义、调用、函数参数、函数返回值、函数说明文档、函数嵌套使用)
- 22 python - 字典常见API
- wmic linux python
- python版本升级及pip部署方法
- 学习Python的第七节课(函数调用、列表解析、嵌套和递归等等)
- Python视频剪辑AutoCut在文档中合成制作口播视频
- (数据科学学习手札107)在Python中利用funct实现链式风格编程
- 基于 Python 官方 GitHub 构建 Python 文档
- Python Selenium自动化(二)自动化注册流程
- Step by Step Learn Python(1)