
弄明白python reduce 函数
作者:Panda Fang
出处:http://www.cnblogs.com/lonkiss/p/understanding-python-reduce-function.html
原创文章,转载请注明作者和出处,未经允许不可用于商业营利活动
reduce() 函数在 python 2 是内置函数, 从python 3 开始移到了 functools 模块。
官方文档是这样介绍的
reduce(...)
reduce(function, sequence[, initial]) -> valueApply a function of two arguments cumulatively to the items of a sequence,
from left to right, so as to reduce the sequence to a single value.
For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates
((((1+2)+3)+4)+5). If initial is present, it is placed before the items
of the sequence in the calculation, and serves as a default when the
sequence is empty.从左到右对一个序列的项累计地应用有两个参数的函数,以此合并序列到一个单一值。
例如,reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) 计算的就是((((1+2)+3)+4)+5)。
如果提供了 initial 参数,计算时它将被放在序列的所有项前面,如果序列是空的,它也就是计算的默认结果值了
嗯, 这个文档其实不好理解。看了还是不懂。 序列 其实就是python中 tuple list dictionary string 以及其他可迭代物,别的编程语言可能有数组。
reduce 有 三个参数
| function | 有两个参数的函数, 必需参数 |
| sequence | tuple ,list ,dictionary, string等可迭代物,必需参数 |
| initial | 初始值, 可选参数 |
reduce的工作过程是 :在迭代sequence(tuple ,list ,dictionary, string等可迭代物)的过程中,首先把 前两个元素传给 函数参数,函数加工后,然后把得到的结果和第三个元素作为两个参数传给函数参数, 函数加工后得到的结果又和第四个元素作为两个参数传给函数参数,依次类推。 如果传入了 initial 值, 那么首先传的就不是 sequence 的第一个和第二个元素,而是 initial值和 第一个元素。经过这样的累计计算之后合并序列到一个单一返回值
reduce 代码举例,使用REPL演示
>>> def add(x, y):
... return x+y
...
>>> from functools import reduce
>>> reduce(add, [1,2,3,4])
10
>>>上面这段 reduce 代码,其实就相当于 1 + 2 + 3 + 4 = 10, 如果把加号改成乘号, 就成了阶乘了
当然 仅仅是求和的话还有更简单的方法,如下
>>> sum([1,2,3,4])
10
>>>
很多教程只讲了一个加法求和,太简单了,对新手加深理解还不够。下面讲点更深入的例子
还可以把一个整数列表拼成整数,如下
>>> from functools import reduce
>>> reduce(lambda x, y: x * 10 + y, [1 , 2, 3, 4, 5])
12345
>>>
对一个复杂的sequence使用reduce ,看下面代码,更多的代码不再使用REPL, 使用编辑器编写
from functools import reduce
scientists =({'name':'Alan Turing', 'age':105},
{'name':'Dennis Ritchie', 'age':76},
{'name':'John von Neumann', 'age':114},
{'name':'Guido van Rossum', 'age':61})
def reducer(accumulator , value):
sum = accumulator['age'] + value['age']
return sum
total_age = reduce(reducer, scientists)
print(total_age)这段代码会出错,看下图的执行过程

所以代码需要修改
from functools import reduce
scientists =({'name':'Alan Turing', 'age':105, 'gender':'male'},
{'name':'Dennis Ritchie', 'age':76, 'gender':'male'},
{'name':'Ada Lovelace', 'age':202, 'gender':'female'},
{'name':'Frances E. Allen', 'age':84, 'gender':'female'})
def reducer(accumulator , value):
sum = accumulator + value['age']
return sum
total_age = reduce(reducer, scientists, 0)
print(total_age)7, 9 行 红色部分就是修改 部分。 通过 help(reduce) 查看 文档,
reduce 有三个参数, 第三个参数是初始值的意思,是可有可无的参数。
修改之后就不出错了,流程如下
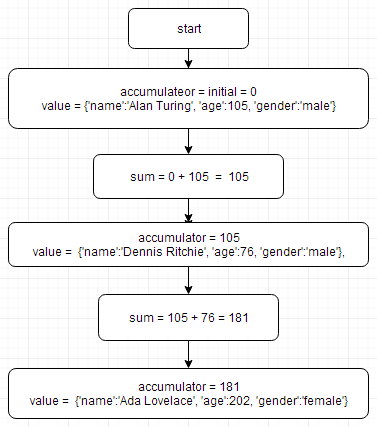
这个仍然也可以用 sum 来更简单的完成
sum([x['age'] for x in scientists ])做点更高级的事情,按性别分组
from functools import reduce
scientists =({'name':'Alan Turing', 'age':105, 'gender':'male'},
{'name':'Dennis Ritchie', 'age':76, 'gender':'male'},
{'name':'Ada Lovelace', 'age':202, 'gender':'female'},
{'name':'Frances E. Allen', 'age':84, 'gender':'female'})
def group_by_gender(accumulator , value):
accumulator[value['gender']].append(value['name'])
return accumulator
grouped = reduce(group_by_gender, scientists, {'male':[], 'female':[]})
print(grouped)输出
{'male': ['Alan Turing', 'Dennis Ritchie'], 'female': ['Ada Lovelace', 'Frances E. Allen']}可以看到,在 reduce 的初始值参数传入了一个dictionary,, 但是这样写 key 可能出错,还能再进一步自动化,运行时动态插入key
修改代码如下
grouped = reduce(group_by_gender, scientists, collections.defaultdict(list))当然 先要 import collections 模块
这当然也能用 pythonic way 去解决
import itertools
scientists =({'name':'Alan Turing', 'age':105, 'gender':'male'},
{'name':'Dennis Ritchie', 'age':76, 'gender':'male'},
{'name':'Ada Lovelace', 'age':202, 'gender':'female'},
{'name':'Frances E. Allen', 'age':84, 'gender':'female'})
grouped = {item[0]:list(item[1])
for item in itertools.groupby(scientists, lambda x: x['gender'])}
print(grouped)
再来一个更晦涩难懂的玩法。工作中要与其他人协作的话,不建议这么用,与上面的例子做同样的事,看不懂无所谓。
from functools import reduce
scientists =({'name':'Alan Turing', 'age':105, 'gender':'male'},
{'name':'Dennis Ritchie', 'age':76, 'gender':'male'},
{'name':'Ada Lovelace', 'age':202, 'gender':'female'},
{'name':'Frances E. Allen', 'age':84, 'gender':'female'})
grouped = reduce(lambda acc, val: {**acc, **{val['gender']: acc[val['gender']]+ [val['name']]}}, scientists, {'male':[], 'female':[]})
print(grouped)**acc, **{val['gneder']... 这里使用了 dictionary merge syntax , 从 python 3.5 开始引入, 详情请看 PEP 448 - Additional Unpacking Generalizations 怎么使用可以参考这个 python - How to merge two dictionaries in a single expression? - Stack Overflow
python 社区推荐写可读性好的代码,有更好的选择时不建议用reduce,所以 python 2 中内置的reduce 函数 移到了 functools模块中
相关文章
- python split(),os.path.split()和os.path.splitext()函数用法
- Python查询Mysql时返回字典结构的代码
- Python 字符串_python 字符串截取_python 字符串替换_python 字符串连接
- python的内置函数
- Python聚类算法之基本K均值实例详解
- Python os模块——与操作系统相关的函数
- 【OpenCV-Python】教程:7-1 理解 kNN (k-Nearest Neighbour)
- Python日期时间函数处理
- Python编程语言学习:python中与数字相关的函数(取整等)、案例应用之详细攻略
- Python编程语言学习:python编程语言中重要函数讲解之map函数等简介、使用方法之详细攻略
- Python之 sklearn:sklearn中的RobustScaler 函数的简介及使用方法之详细攻略
- Python之多线程:python多线程设计之同时执行多个函数命令详细攻略
- Python语言学习:基于python五种方法实现使用某函数名【func_01】的字符串格式('func_01')来调用该函数【func_01】执行功能
- 零基础学Python(第十六章 函数·重点)
- Python每日一练(数据分析篇新题库)——第42天:排序、函数
- Python每日一练——第25天:内置函数
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 已解决2. Set PROTOCOL_BUPFERS_PYTHON_iMPLEMENTATION=python (but this will use pure-Python parsing and w
- 〖Python接口自动化测试实战篇⑧〗- 小案例 - 使用python实现接口请求 [查询天行数据]
- 从零开始学python | 使用Python映射,过滤和缩减函数:所有您需要知道的
- GitHub热榜|5款优质的Python小工具,最后一款真神器!
- Python编程:playhouse模块转peewee的model对象为字典dict
- Python编程:查看python语法中的关键字keyword
- Python编程:使用textrank4zh、jieba、snownlp提取中文文章关键字和摘要
- python csv文件转换成xml, 构建新xml文件
- python 读不同编码的文本,传递一个可选的encoding 参数给open() 函数
- ubuntu使用python调用C语言函数
- python 实现函数的递归
- python里使用正则的findall函数
- python学习之基本语法---语法规则---注释,标识符,关键字,命名规则(二)day8
- Python练习4
- 【异常】前端ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.
- Python(8):函数和包
- 转载:大厂5G python自动化测试面试必会 | 匿名函数lambda & 递归函数 & 函数属性和注解 & 函数式编程工具
- Python常用内置函数(python 3.x)