
Python爬虫超详细讲解(零基础入门,老年人都看的懂)
爬虫准备工作
我们平时都说Python爬虫,其实这里可能有个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多例如:PHP,JAVA,C#,C++,Python,选择Python做爬虫是因为Python相对来说比较简单,而且功能比较齐全。
首先我们需要下载python,我下载的是官方最新的版本 3.8.3
其次我们需要一个运行Python的环境,我用的是pychram
也可以从官方下载,我们还需要一些库来支持爬虫的运行(有些库Python可能自带了)
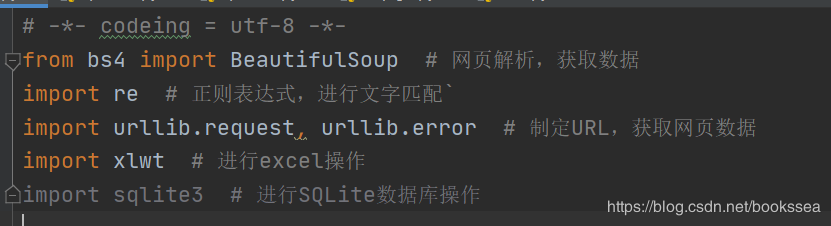
差不多就是这几个库了,良心的我已经在后面写好注释了

(爬虫运行过程中,不一定就只需要上面几个库,看你爬虫的一个具体写法了,反正需要库的话我们可以直接在setting里面安装)
说说当初写的一个集群爬下整个豆瓣的经验吧。
1)首先你要明白爬虫怎样工作。
想象你是一只蜘蛛,现在你被放到了互联“网”上。那么,你需要把所有的网页都看一遍。怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页,这个叫initial pages,用$表示吧。
在人民日报的首页,你看到那个页面引向的各种链接。于是你很开心地从爬到了“国内新闻”那个页面。太好了,这样你就已经爬完了俩页面(首页和国内新闻)!暂且不用管爬下来的页面怎么处理的,你就想象你把这个页面完完整整抄成了个html放到了你身上。
突然你发现, 在国内新闻这个页面上,有一个链接链回“首页”。作为一只聪明的蜘蛛,你肯定知道你不用爬回去的吧,因为你已经看过了啊。所以,你需要用你的脑子,存下你已经看过的页面地址。这样,每次看到一个可能需要爬的新链接,你就先查查你脑子里是不是已经去过这个页面地址。如果去过,那就别去了。
好的,理论上如果所有的页面可以从initial page达到的话,那么可以证明你一定可以爬完所有的网页。
那么在python里怎么实现呢? 很简单

写得已经很伪代码了。所有的爬虫的backbone都在这里,下面分析一下为什么爬虫事实上是个非常复杂的东西——搜索引擎公司通常有一整个团队来维护和开发。
2)效率如果你直接加工一下上面的代码直接运行的话,你需要一整年才能爬下整个豆瓣的内容。更别说Google这样的搜索引擎需要爬下全网的内容了。
问题出在哪呢?
需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有N个网站,那么分析一下判重的复杂度就是N*log(N),因为所有网页要遍历一次,而每次判重用set的话需要log(N)的复杂度。OK,OK,我知道python的set实现是hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?
Bloom Filter. 简单讲它仍然是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随url的数量而增长)以O(1)的效率判定url是否已经在set中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个url不在set中,BF可以100%确定这个url没有看过。但是如果这个url在set中,它会告诉你:这个url应该已经出现过,不过我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。一个简单的教程:Bloom Filters by Example。
3)集群化抓取
爬取豆瓣的时候,我总共用了100多台机器昼夜不停地运行了一个月。想象如果只用一台机子你就得运行100个月了…
那么,假设你现在有100台机器可以用,怎么用python实现一个分布式的爬取算法呢?
我们把这100台中的99台运算能力较小的机器叫作slave,另外一台较大的机器叫作master,那么回顾上面代码中的url_queue,如果我们能把这个queue放到这台master机器上,所有的slave都可以通过网络跟master联通,每当一个slave完成下载一个网页,就向master请求一个新的网页来抓取。而每次slave新抓到一个网页,就把这个网页上所有的链接送到master的queue里去。
同样,bloom filter也放到master上,但是现在master只发送确定没有被访问过的url给slave。Bloom Filter放到master的内存里,而被访问过的url放到运行在master上的Redis里,这样保证所有操作都是O(1)。(至少平摊是O(1),Redis的访问效率见:LINSERT – Redis)
考虑如何用python实现:
在各台slave上装好scrapy,那么各台机子就变成了一台有抓取能力的slave,在master上装好Redis和rq用作分布式队列。
代码于是写成

4)展望及后处理虽然上面用很多“简单”,但是真正要实现一个商业规模可用的爬虫并不是一件容易的事。上面的代码用来爬一个整体的网站几乎没有太大的问题。
但是如果附加上你需要这些后续处理,比如
- 有效地存储(数据库应该怎样安排)
- 有效地判重(这里指网页判重,咱可不想把人民日报和抄袭它的大民日报都爬一遍)
- 有效地信息抽取(比如怎么样抽取出网页上所有的地址抽取出来,“朝阳区奋进路中华
道”),搜索引擎通常不需要存储所有的信息,比如图片我存来干嘛… - 及时更新(预测这个网页多久会更新一次)
如你所想,这里每一个点都可以供很多研究者十数年的研究。虽然如此,“路漫漫其修远兮,吾将上下而求索”。
所以,不要问怎么入门,直接上路就好了
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、Python练习题
检查学习结果。

七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相关文章
- 开源 Python网络爬虫框架 Scrapy
- python爬虫知识点总结(十九)Scrapy命令行详解
- 【2K收藏干货】速看,Python爬虫常用库-requests
- Python爬虫需要学多久才能掌握?
- Python爬虫:用BeautifulSoup进行NBA数据爬取
- 精通Python网络爬虫:核心技术、框架与项目实战.2.2 搜索引擎核心
- 精通Python网络爬虫:核心技术、框架与项目实战.3.1 网络爬虫实现原理详解
- Python爬虫技术--基础篇--Web开发(中)
- Python爬虫技术--基础篇--访问数据库(上)
- Python爬虫技术--基础篇--常用第三方模块virtualenv
- Python爬虫技术--基础篇--常用第三方模块chardet和psutil
- Python爬虫技术--基础篇--内建模块datetime和collections
- Python爬虫技术--基础篇--正则表达式
- Python爬虫技术--基础篇--多进程
- Python爬虫技术--基础篇--函数式编程(中篇)
- Python爬虫技术--基础篇--错误,调试和测试(下)
- Python爬虫技术--基础篇--数据类型和变量,标识符与关键字,运算符和表达式
- Python爬虫技术--基础篇--Python开发环境安装
- python爬虫实战--抖音
- Python实现一个简单的图片爬虫
- Python爬虫-运算符
- Python爬虫之续Urllib&&Jsonpath库的使用
- Python 爬虫 之 爬取王者荣耀的英雄们所有大皮肤图片,并 json 形式保存英雄列表信息到本地
- Python 爬虫基础Selenium
- Python乐园提供Python学习的基地,免费分享与提供基础学习、高级开发、有趣的爬虫、人工智能、系统网站开发、前沿的最新技术、项目架构、以及配套的资料、视频、源码、笔记等等