
Python爬虫之续Urllib&&Jsonpath库的使用

@作者 : SYFStrive
@博客首页 : HomePage
🥧 Urllib使用传送门
📌:个人社区(欢迎大佬们加入) 👉:社区链接🔗
📌:如果觉得文章对你有帮助可以点点关注 👉:专栏连接🔗
💃:程序员每天坚持锻炼💪
🔗:阅读文章


📋目录
简介🐊
JSONPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python,PHP 和 Java,JsonPath 对于 JSON 来说,相当于 XPath 对于 XML。
爬虫步骤🐯
想要爬什么? 👉 数据类型 👉 找接口 👉爬取数据

JsonPath与Xpath语法对比 ⚖
Json结构清晰,比 XML 简洁得多,可读性高,复杂度低,非常容易匹配,可以很直观地了解存的是什么内容,如👇图所示。
| XPath | JSONPath | 描述 |
|---|---|---|
| / | $ | 根对象/元素 |
| . | @ | 当前对象/元素 |
| / | . or [] | 孩子操作符 |
| … | n/a | 父亲操作符 |
| // | … | 递归下降。JSONPath从E4X借用了这个语法。 |
| * | * | 通配符。所有对象/元素,不管它们的名称。 |
| @ | n/a | 属性的访问。JSON结构没有属性。 |
| [] | [] | 下标操作符。XPath使用它来遍历元素集合和谓词。在Javascript和JSON中,它是原生数组操作符。 |
| I | [,] | XPath中的联合运算符会生成节点集的组合。JSONPath允许替换名称或数组索引集。 |
| n/a | [start🔚step] | 从ES4借用的数组切片操作符。 |
| [] | ?() | 应用筛选器(脚本)表达式。 |
| n/a | () | 脚本表达式,使用底层脚本引擎。 |
| () | n/a | 分组在Xpath |
官网:https://goessner.net/articles/JsonPath/
续Urllib的相关使用
Python之Urllib爬取前后端分离Json格式的后端数据Ajaxget(以🌴为例(其他类似))
注意⚠:open方法默认情况下载的是gbk的编码,如果我们要下载保存汗字,那么需要在open方法中指定编码格式💭
Ⅰ爬取json数据格式化数据ctrl + alt +L
Ⅱ下载数据到本地的两种方法:
方法1、 fs=open(保存的文件名,’类型‘,’等‘)
fs.write(要写入 或 要读取数据)
方法2、 with open(保存的文件名,’类型‘,‘等’) as fs:
fs.write(要写入 或 要读取数据)
- 步骤
- 查看数据是不是我们想要的
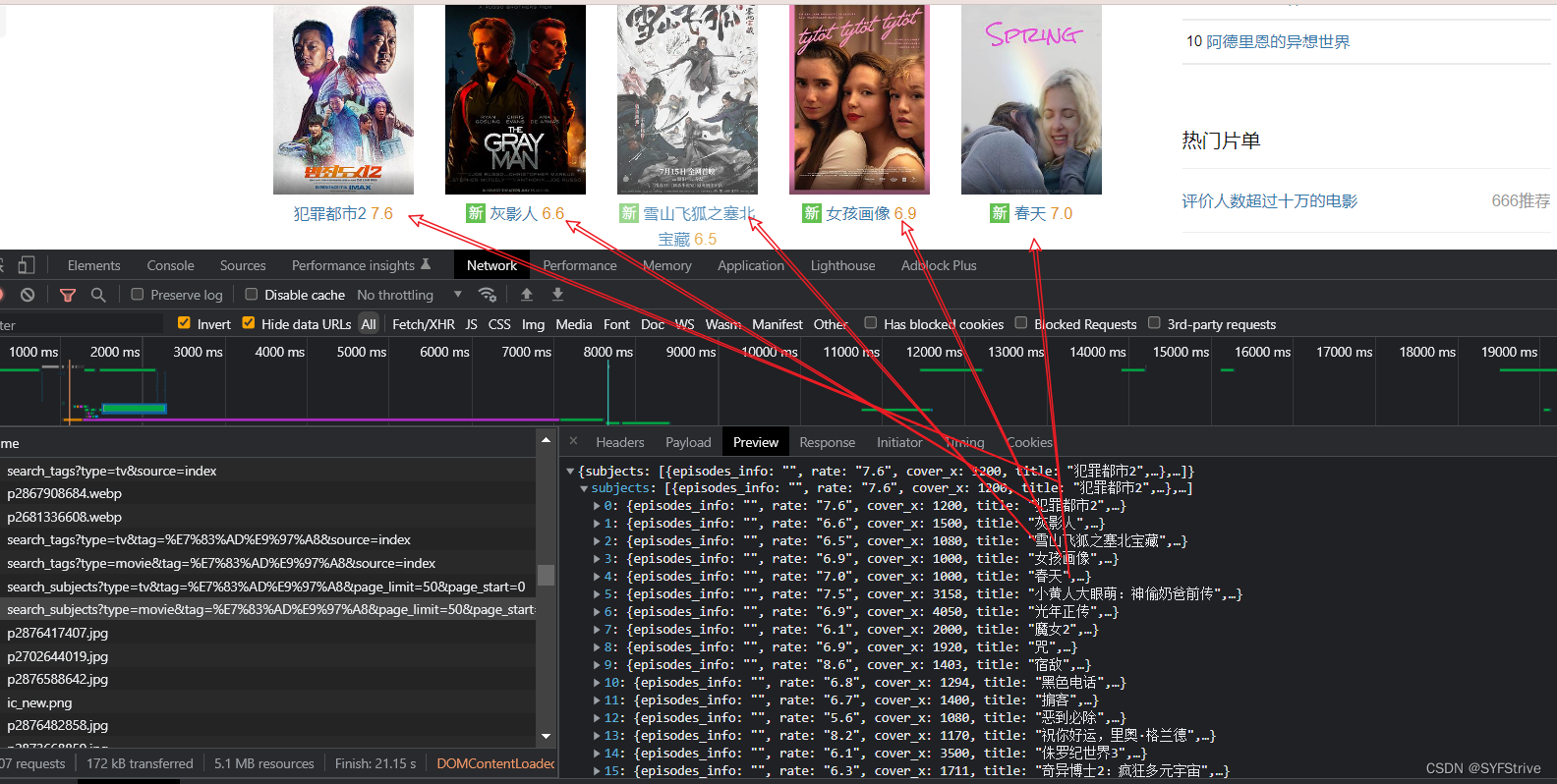
- 复制接口
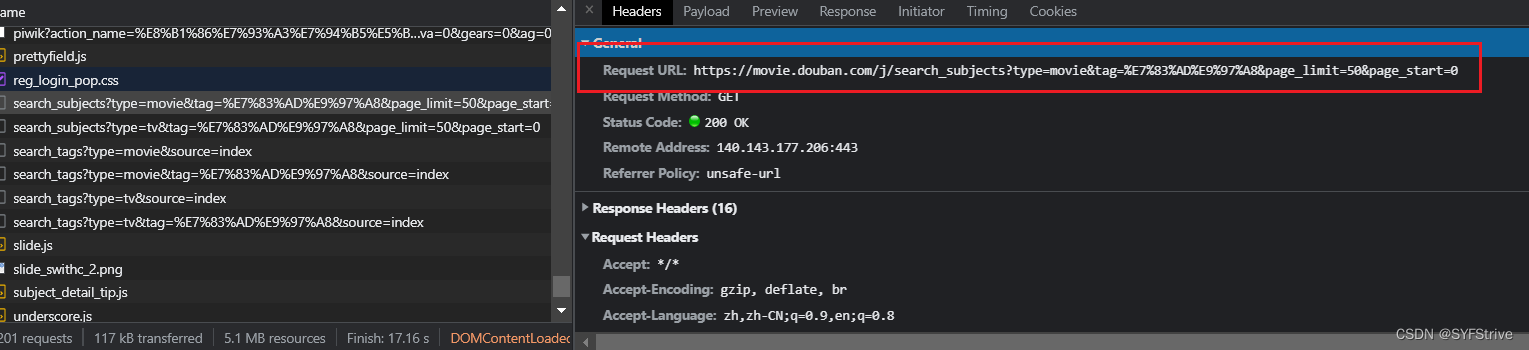
3. 找到接口就可以爬了
📰代码演示:
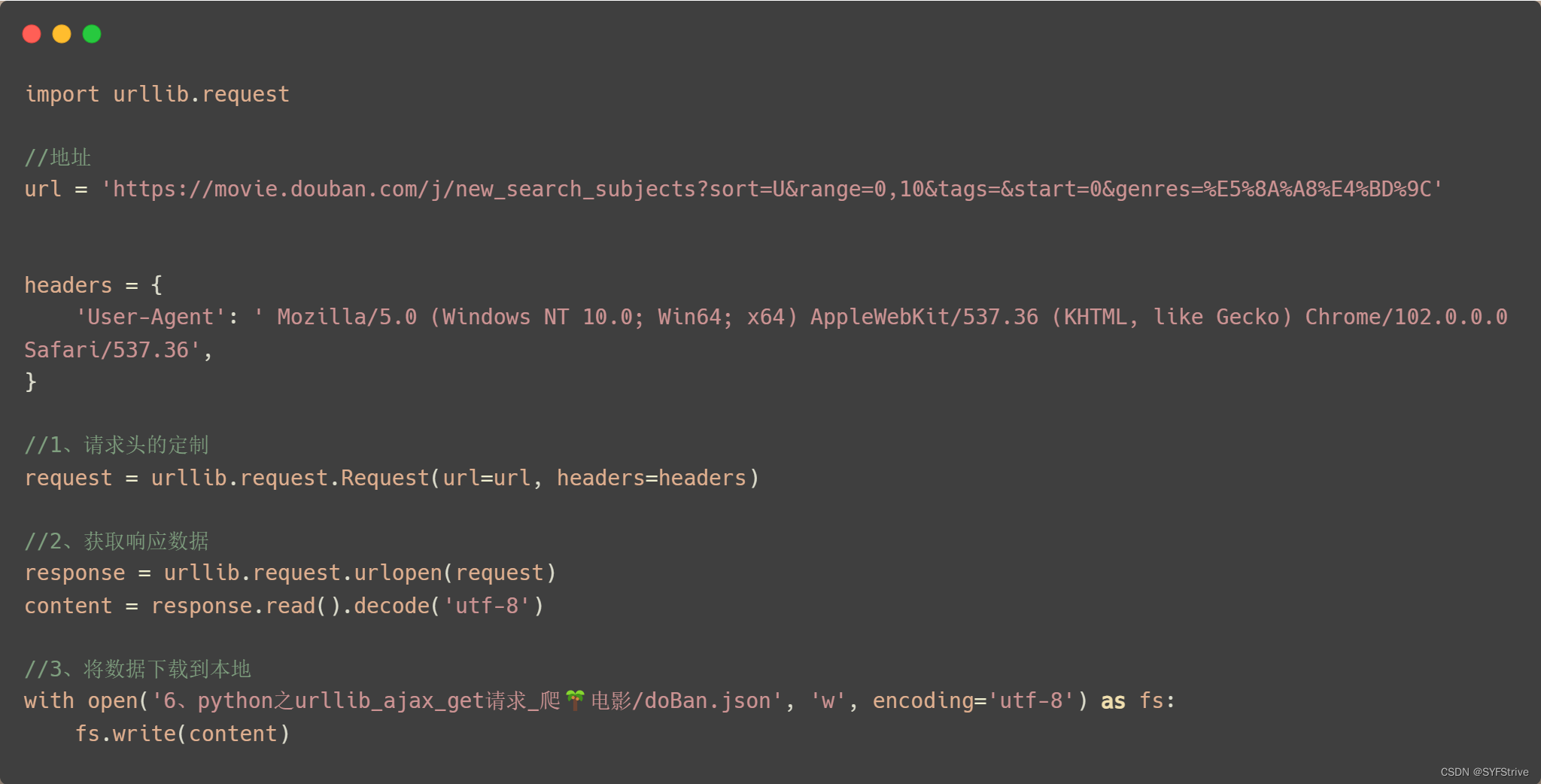
如下图(爬取成功🆗):
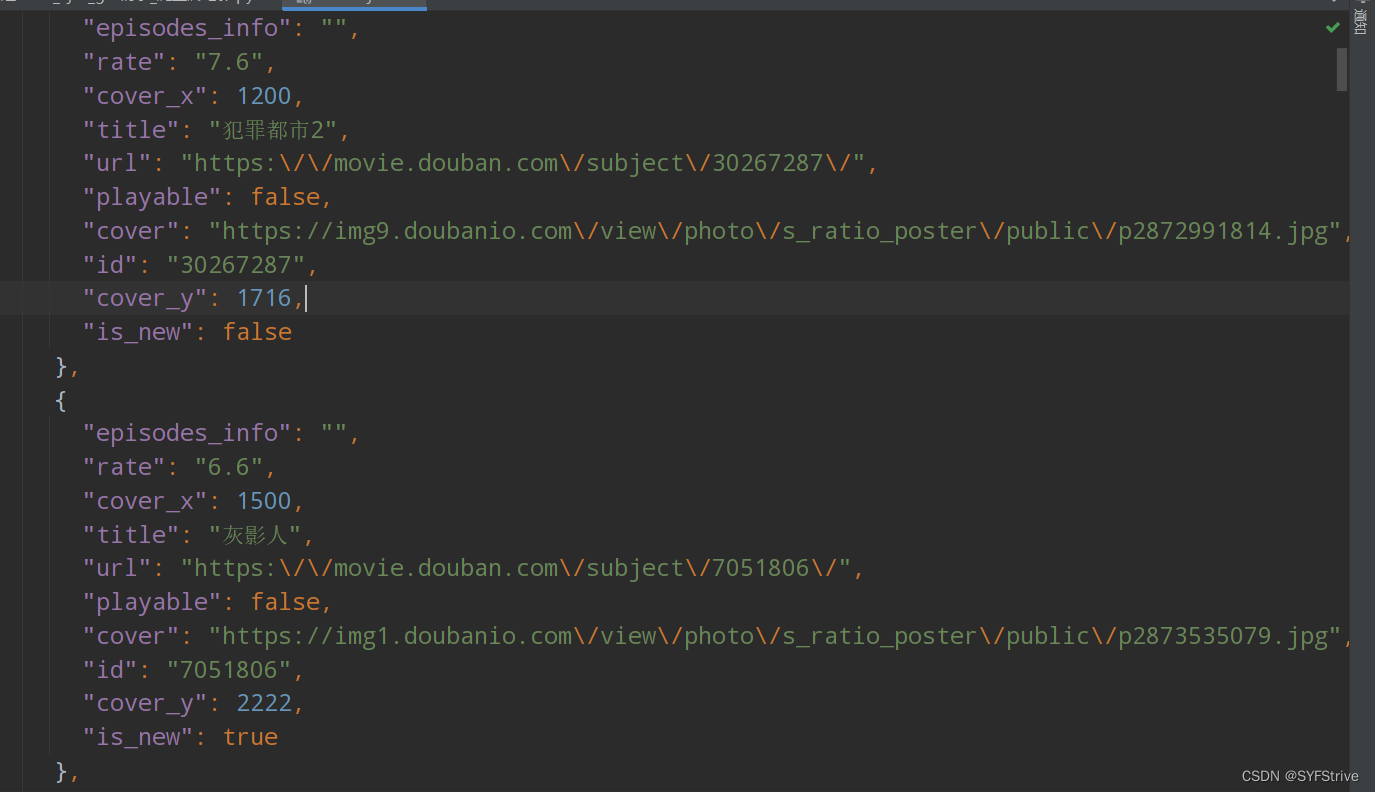
快跟我爬起来吧😀
Python之Urllib爬取前后端分离Json格式的后端数据Ajaxget动态爬取多少页(以🌴为例(其他类似))
步骤:找页码规律
当我往下滑的时候会发现不断更新数据(利用Axios技术)

同时我们获取刷新数据的接口 如👇
https://movie.douban.com/j/sort=U&range=0,10&tags=&start=0&genres=%E5%8A%A8%E4%BD%9C
https://movie.douban.com/j/sort=U&range=0,10&tags=&start=20&genres=%E5%8A%A8%E4%BD%9C
https://movie.douban.com/j/sort=U&range=0,10&tags=&start=40&genres=%E5%8A%A8%E4%BD%9C
我们可以发现 如👇(所以从这里入手)
start=0
start=20
start=40
📰代码演示:
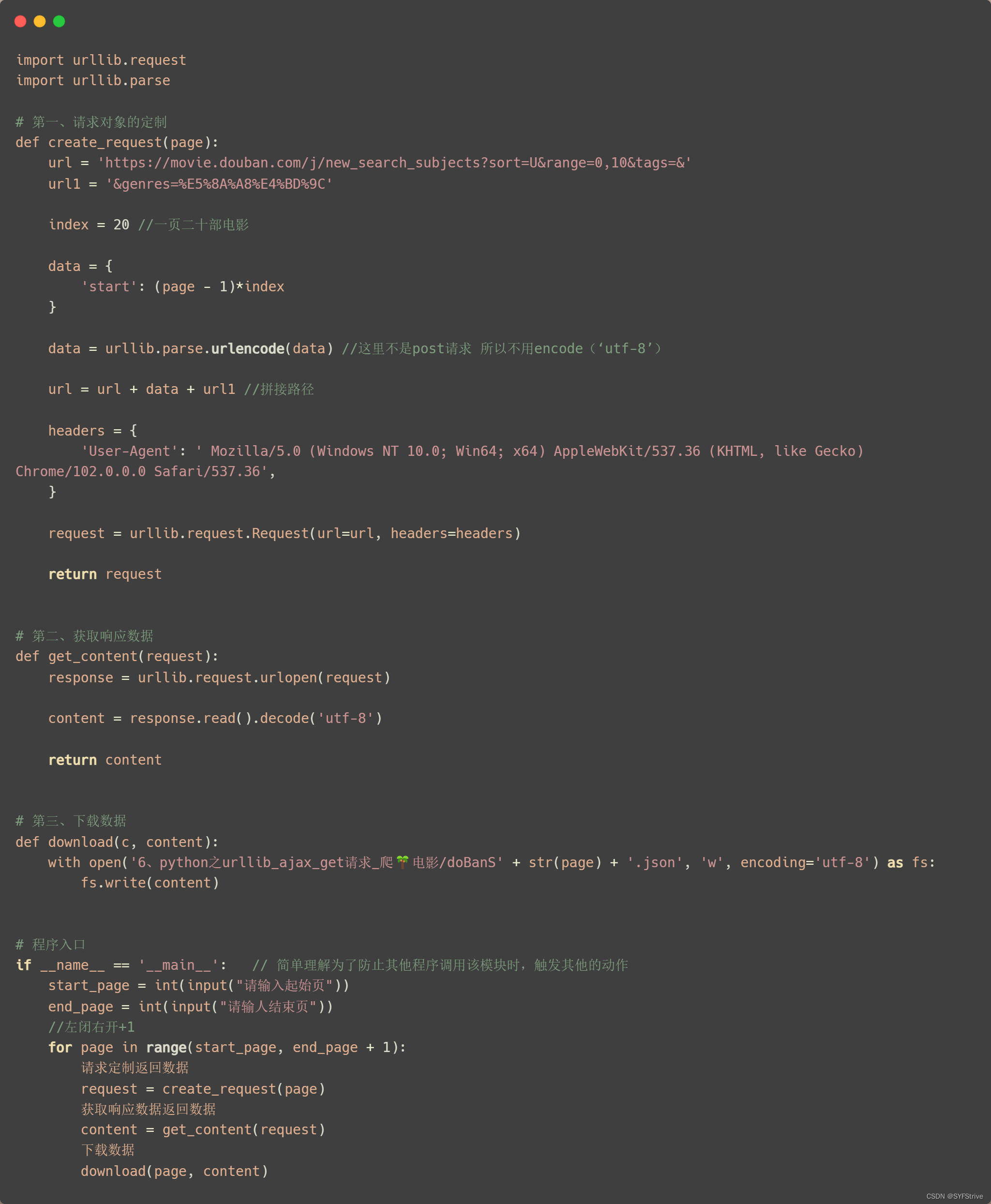
如下图(爬取成功🆗):
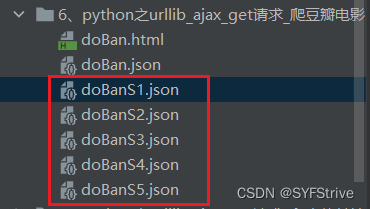
快跟我爬起来吧😀

Python之Urllib爬取🍔餐厅的信息Ajaxpost动态爬取多少页
步骤:找页码规律
当我点击下一页的时候会发现随之数据页发生变化

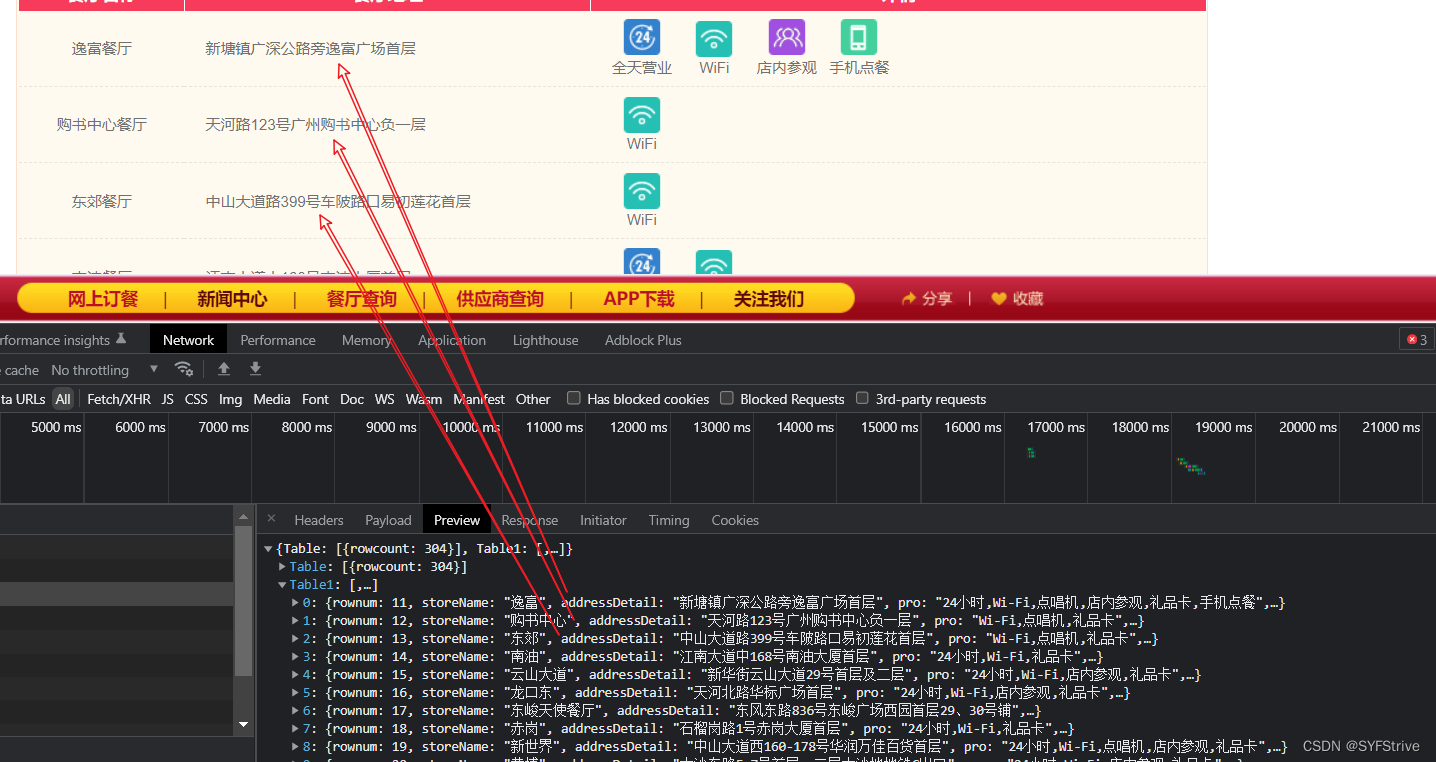
同时我们获取刷新数据的接口 如👇
http://www.kfc.com.cn/GetStoreList.ashx?op=cname
cname: 汕头
pid:
pageIndex: 1
pageSize: 10
http://www.kfc.com.cn/GetStoreList.ashx?op=cname
cname: 汕头
pid:
pageIndex: 2
pageSize: 10
我们可以发现 如👇(所以从这里入手)
pageIndex: 1
pageIndex: 2
📰代码演示:
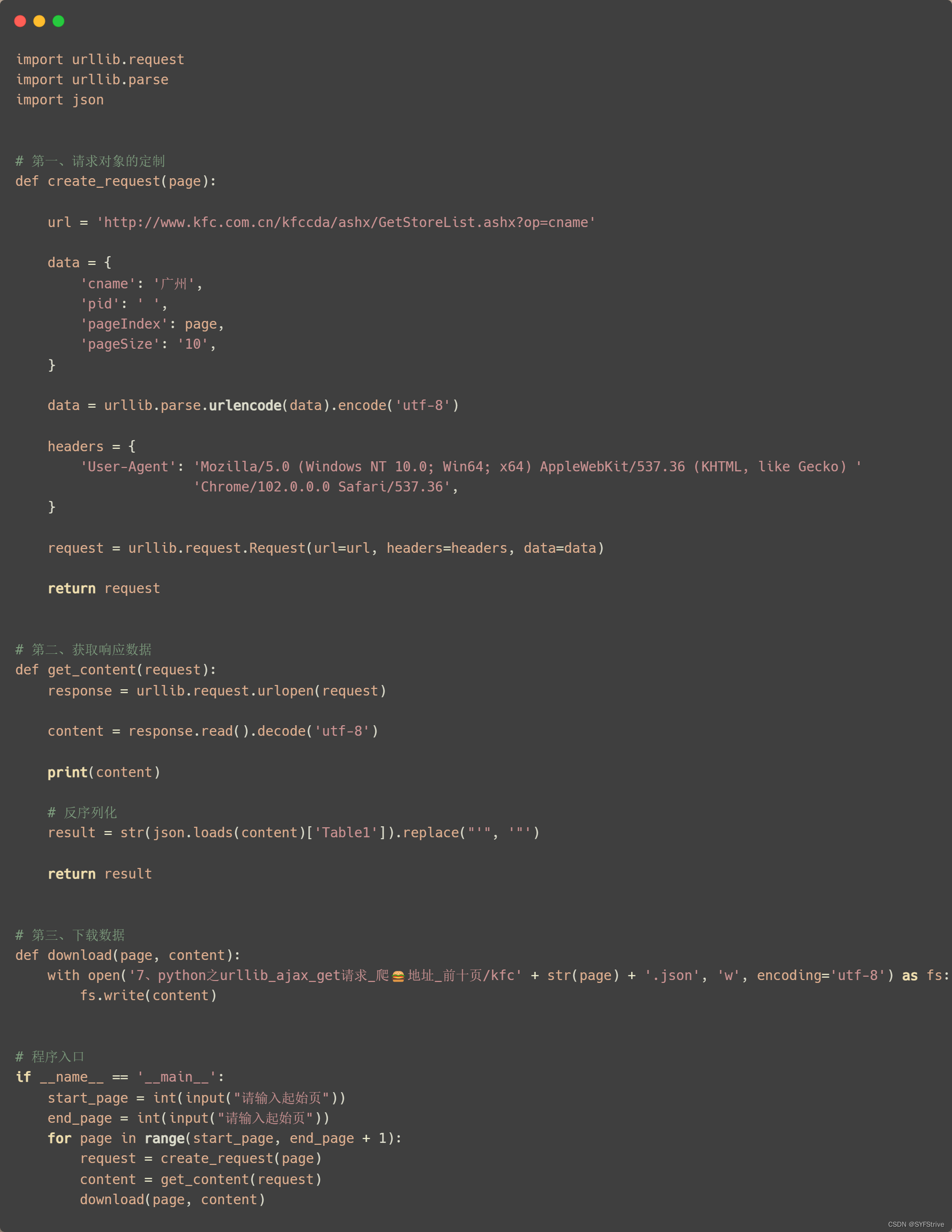
如下图(爬取成功🆗):

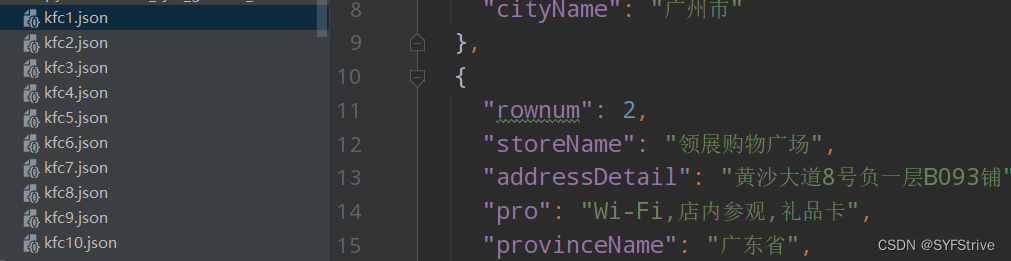
Python之Jsonpath简单使用🐗
安装:pip intsall jsonpath(由于库很小可以不使用镜像)
推荐一篇不错的文章:点击跳转
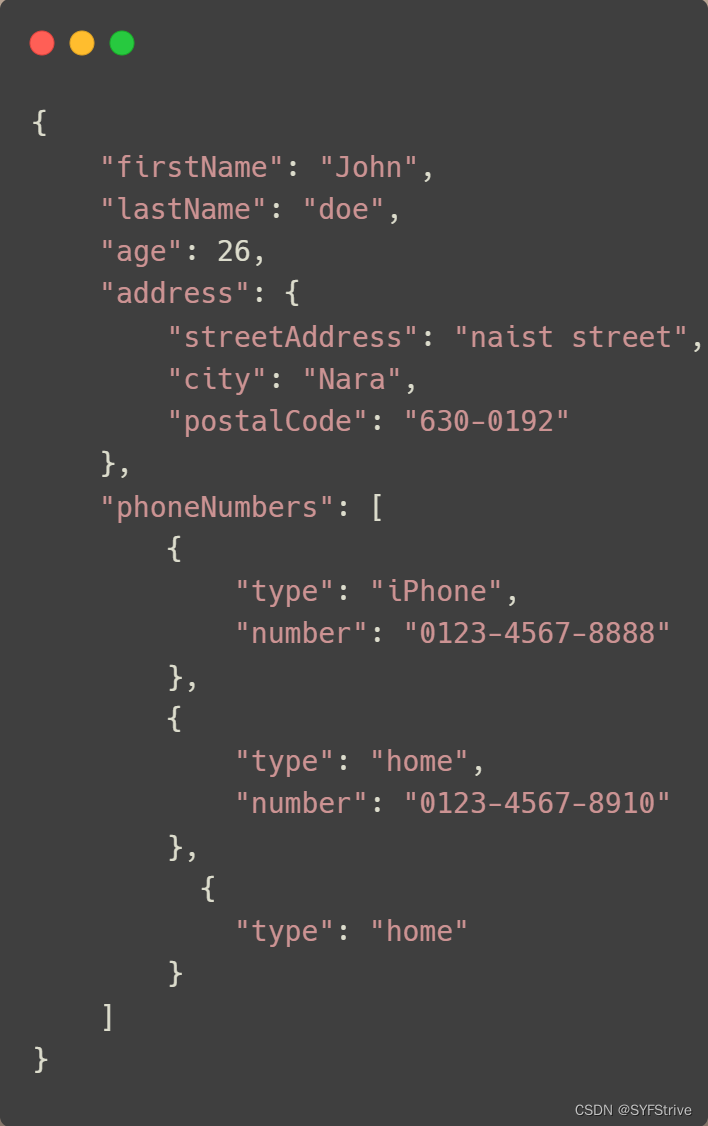
📰JsonPath要爬的数据
📰代码演示:
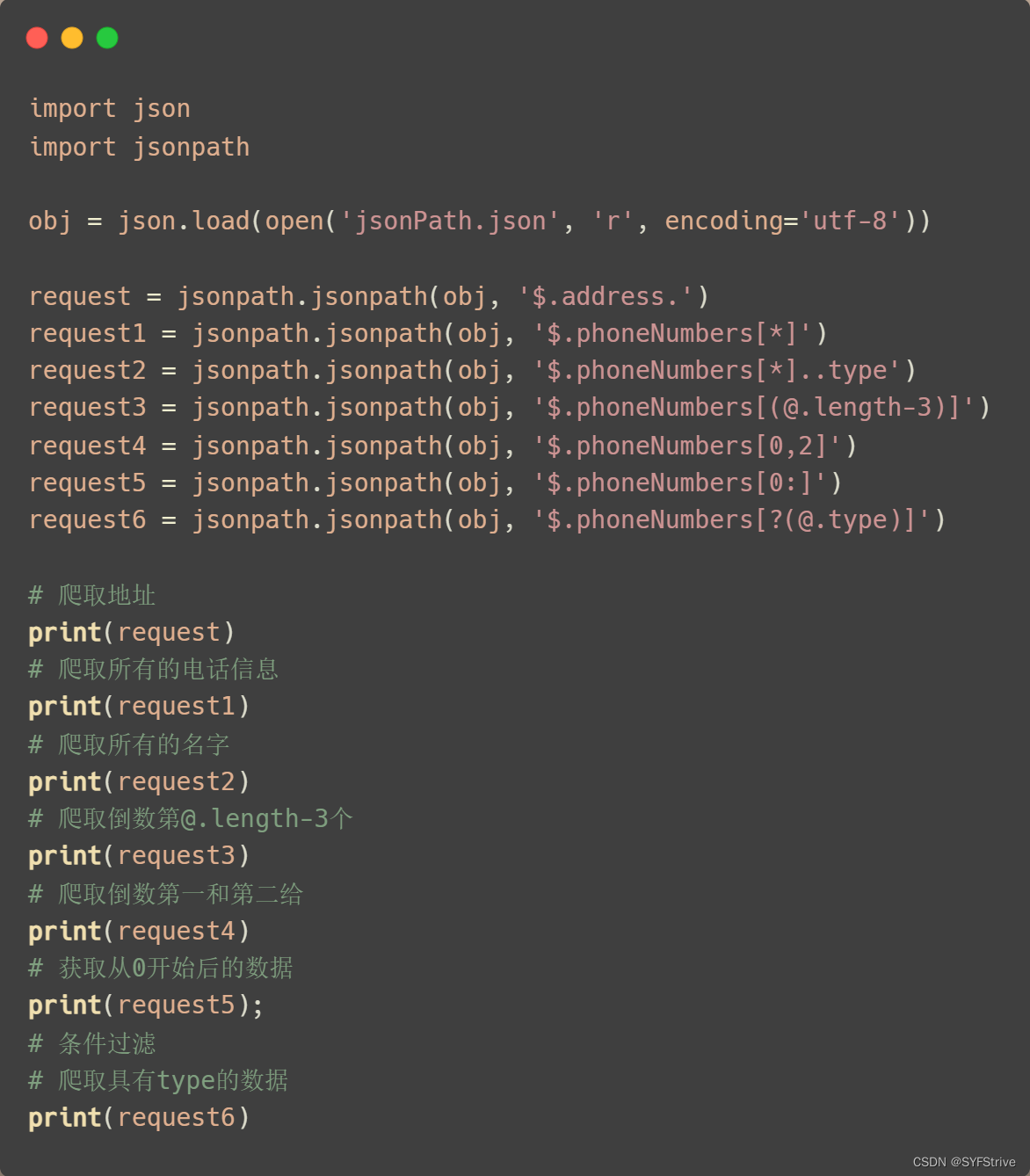
如下图(获取想要的数据🆗):

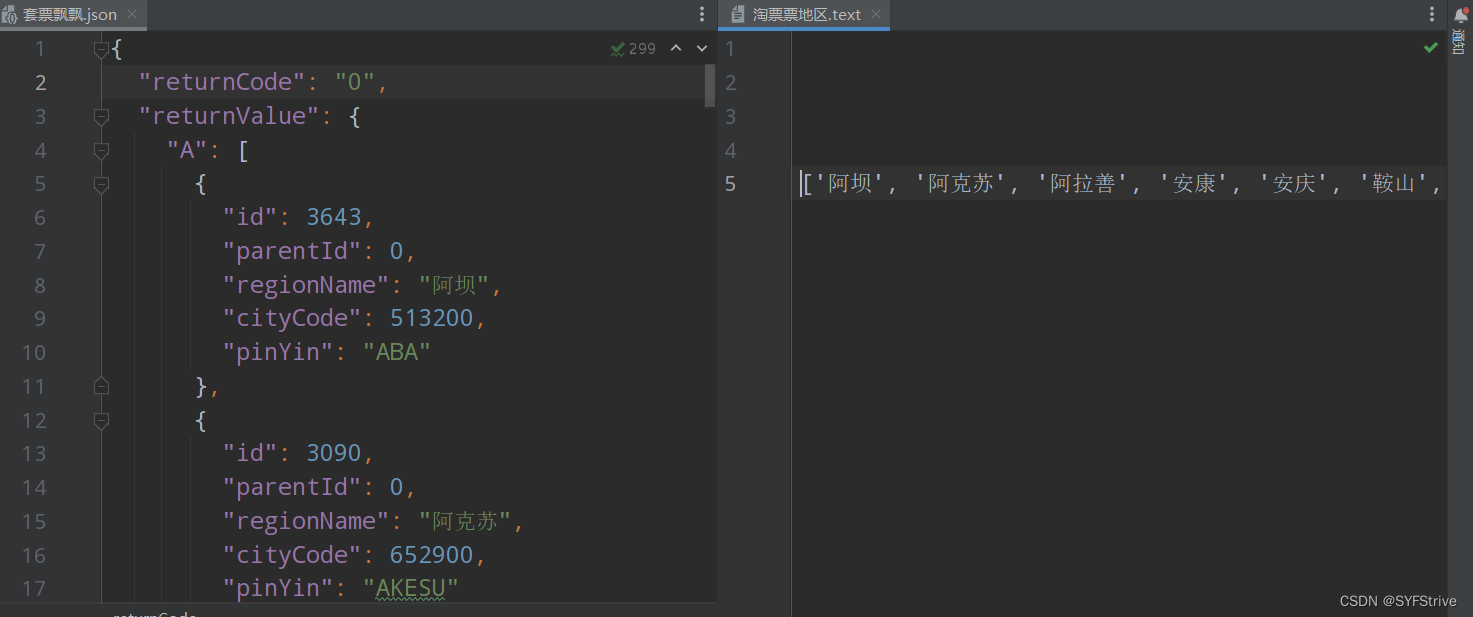
Python之Jsonpath爬取淘🎫🎫数据然后使用Jsonpath获取想要的数据🐗

📰代码演示:
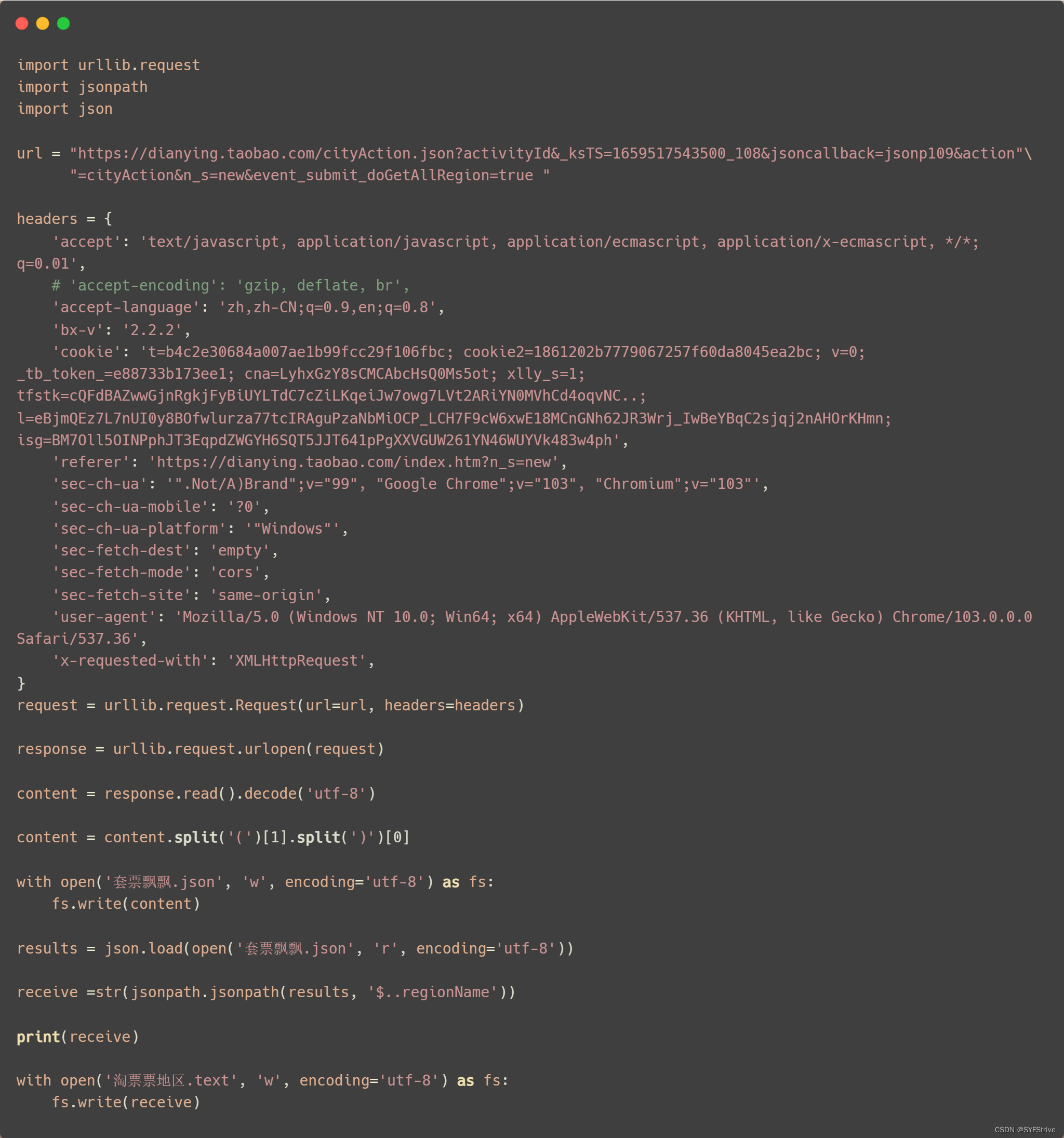
如下图(获取数据成功🆗):


最后
本文章到这里就结束了,觉得不错的请给我专栏点点订阅,你的支持是我们更新的动力,感谢大家的支持,希望这篇文章能帮到大家

下篇文章再见ヾ( ̄▽ ̄)ByeBye

相关文章
- python魔法方法之-Python __repr__()方法:显示属性
- <<Python基础教程>>学习笔记 | 第10章 | 充电时刻
- 【华为OD机试真题 python】 获取最大软件版本号【2022 Q4 | 100分】
- Python学习
- Python && JAVA 去除字符串中空格的五种方法
- gyp ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.
- Python爬虫技术--基础篇--Python开发环境安装
- 源码编译vi过程中进行配置时报“checking if compile and link flags for Python are sane... no: PYTHON DISABLED”怎么办?
- 《Python极客项目编程 》——导读
- 用Python解锁更多乐趣和生产力:发现为什么大多数人都在学它
- Python Excel教程之如何将多个 excel 文件合并为一个文件(教程含源码)
- dython:Python数据建模宝藏库
- (数据科学学习手札18)二次判别分析的原理简介&Python与R实现
- Python的MySQLdb模块安装
- Python爬虫之Web自动化测试工具Selenium&&Chrome handless
- Python爬虫之lxml&&BeautifulSoup库基本使用
- 2022&2023华为OD机试 - 找单词(Python)
- 【Python】python扩展
- Python 基础 之 python 进程知识点整理,实现一个简单使用进程池的多进程文件夹文件copy器
- 【python 学习】——pycharm终端解释器和Python解释器配置
- 学习笔记(20):Python网络编程&并发编程-互斥锁与join的区别
- [Python]2分钟完成python + Selenium Web端自动化环境搭建,开启~~~