
OCR识别,tesseract模块安装
2023-09-27 14:26:27 时间
下载
https://digi.bib.uni-mannheim.de/tesseract/
github地址:https://github.com/UB-Mannheim/tesseract
下载地址截图
安装
双击程序运行
一般直接点默认即可
- 注意语言的添加和路径的更改
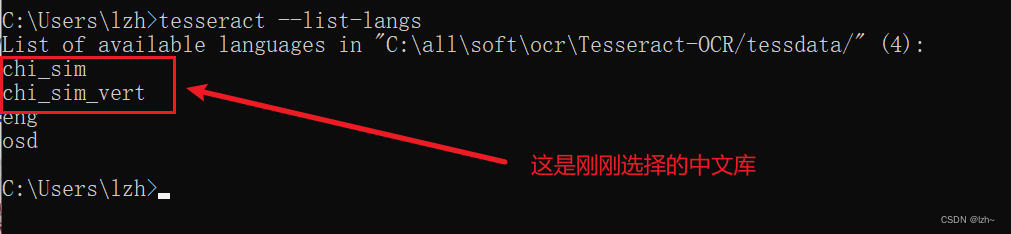
注意这一步可以选择自己语言,这里勾选简体中文
(这里不选的话可以点击上面github网址,在里面进行下载并放在相应的路径即可)
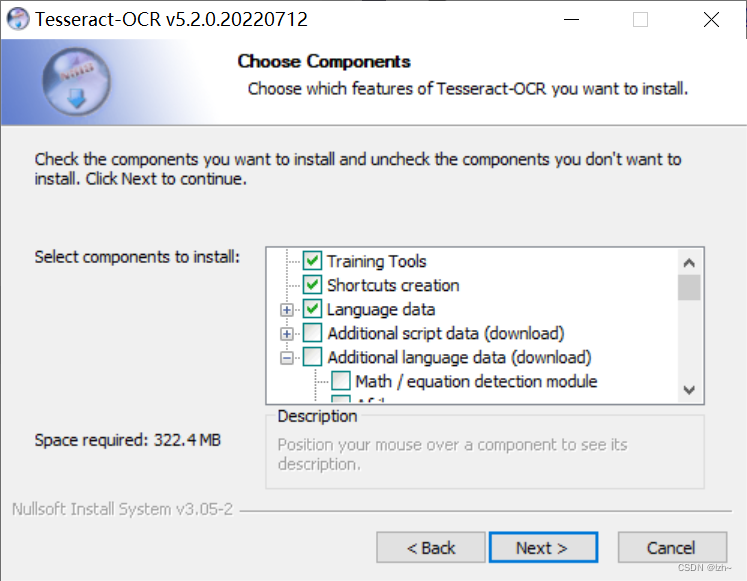
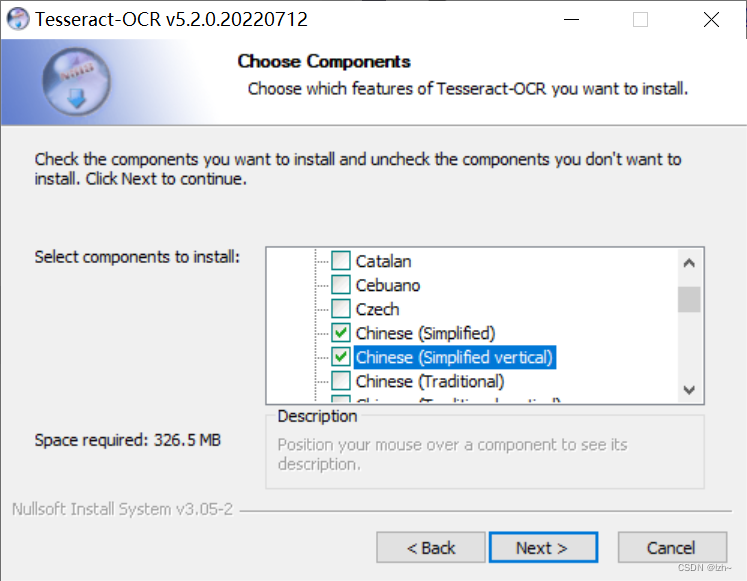
更改安装路径
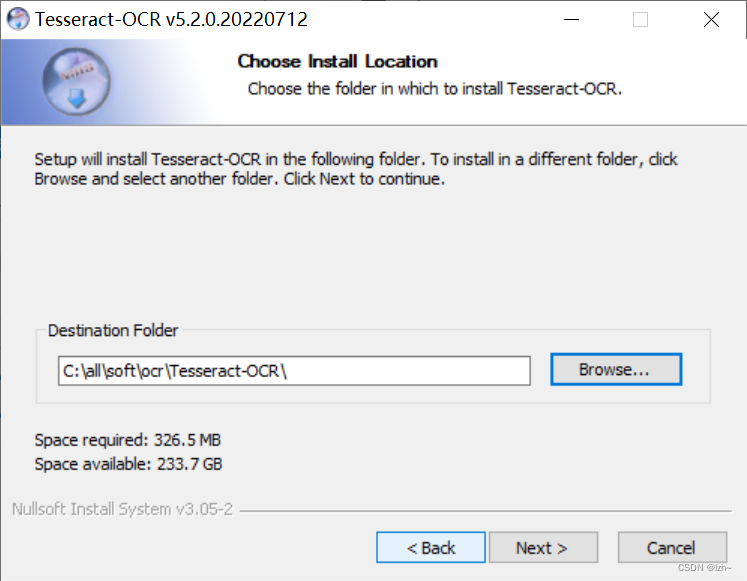
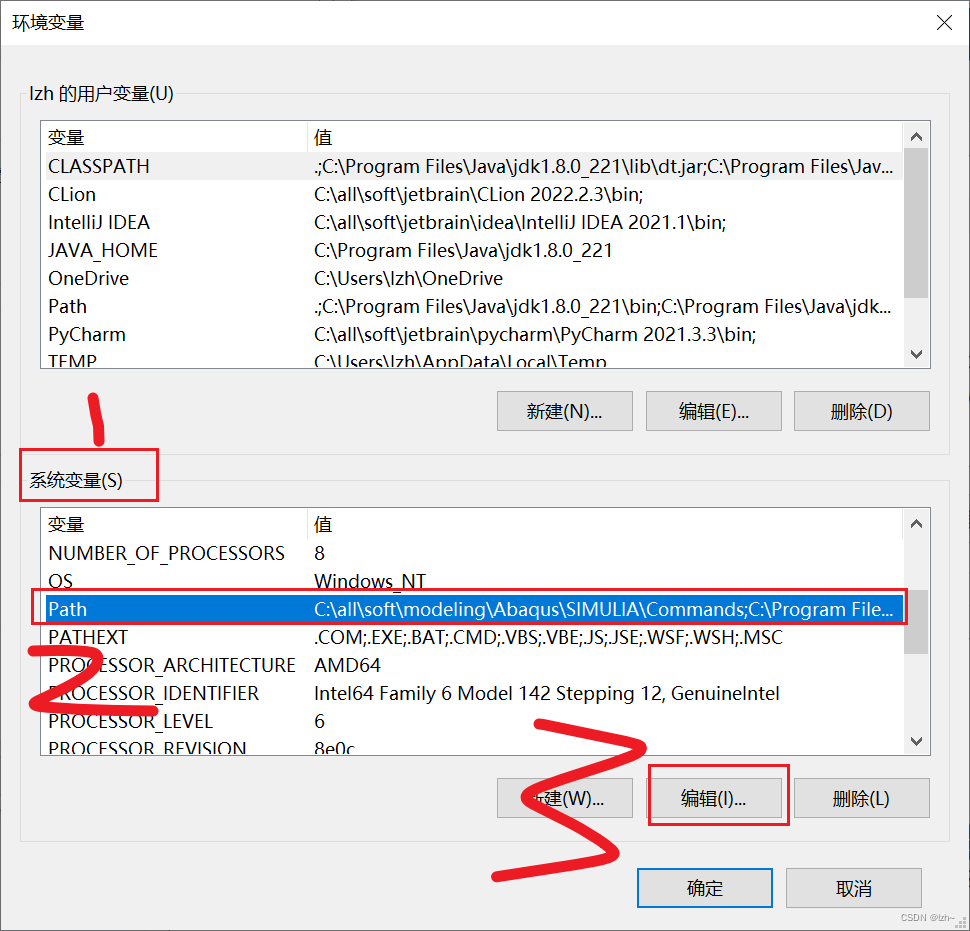
设置环境变量
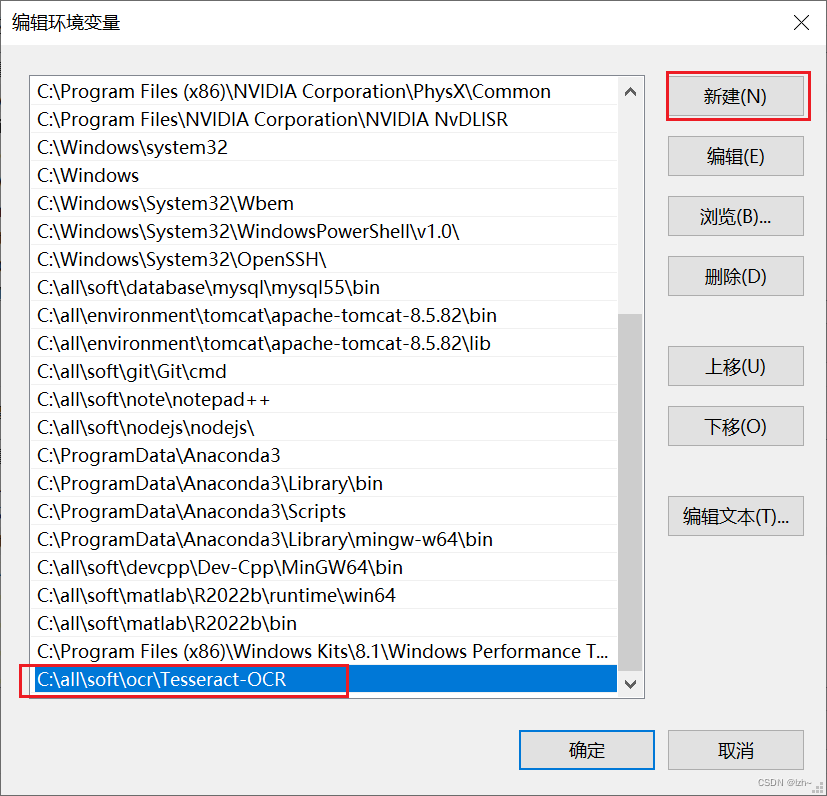
系统变量中找到path,点击编辑,里面加入刚刚安装的路径
检测安装效果
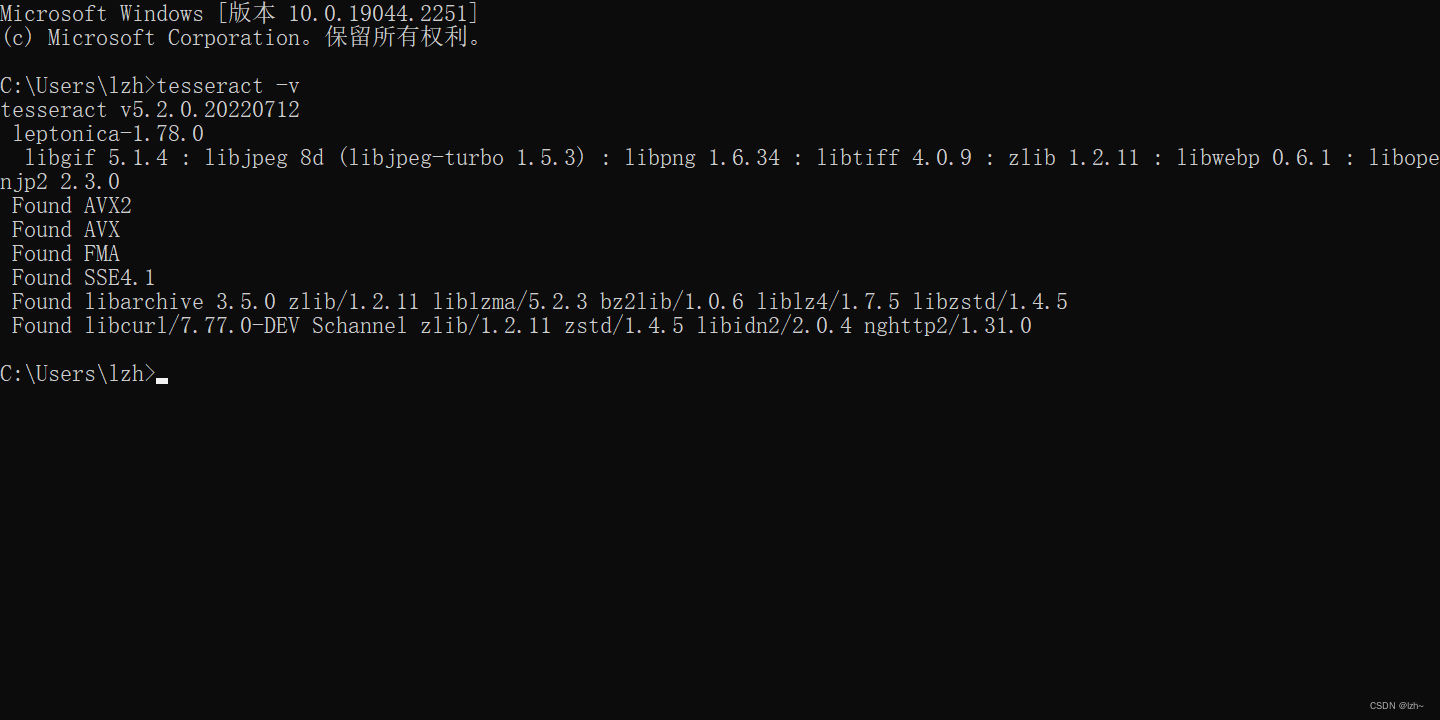
在cmd中输入tesseract -v检测是否安装成功
在cmd中输入tesseract --list-langs查看安装的语言
小案例说明
命令行实现
命令行输入 tesseract test.png result -l chi_sim
其中-l chi_sim代表要识别中文
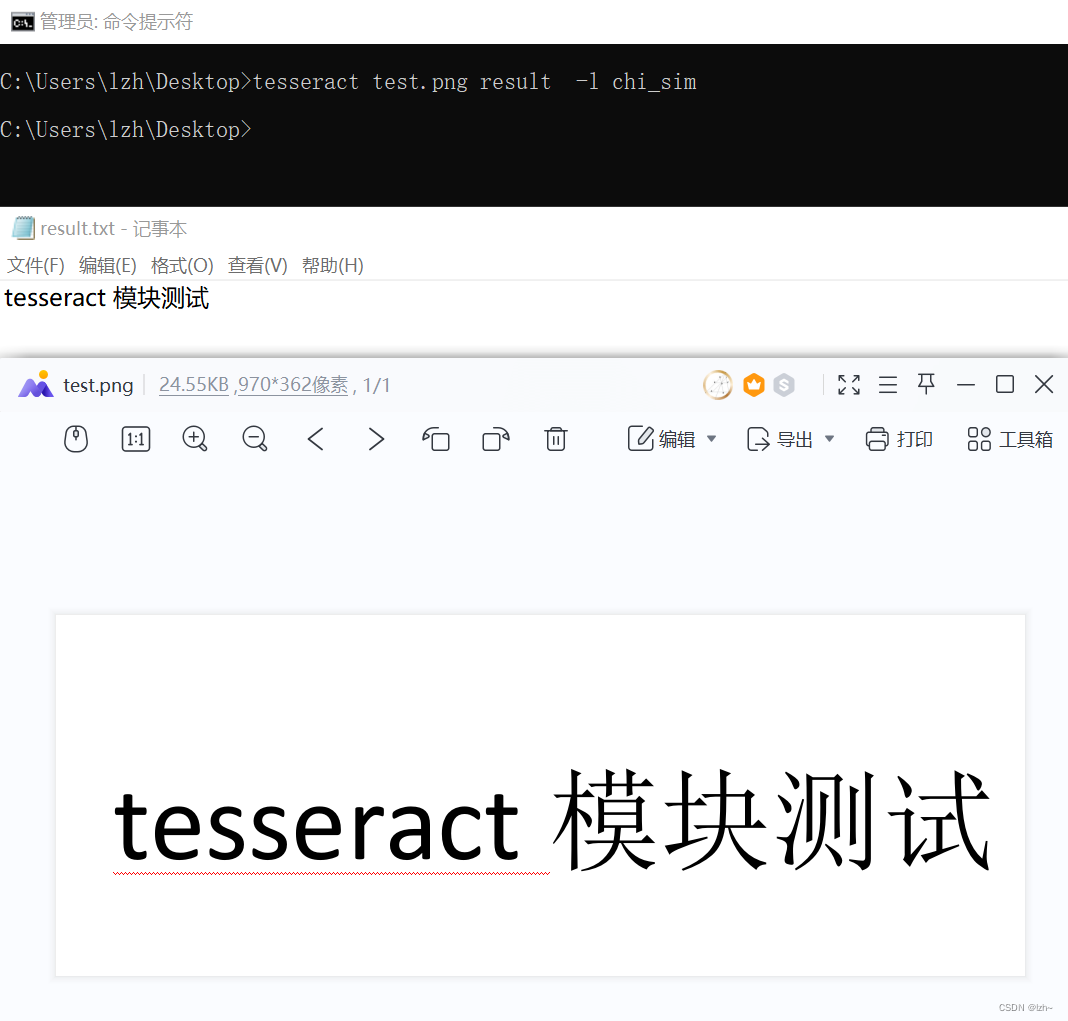
python代码实现
先在对应的环境下安装包
pip install pytesseract
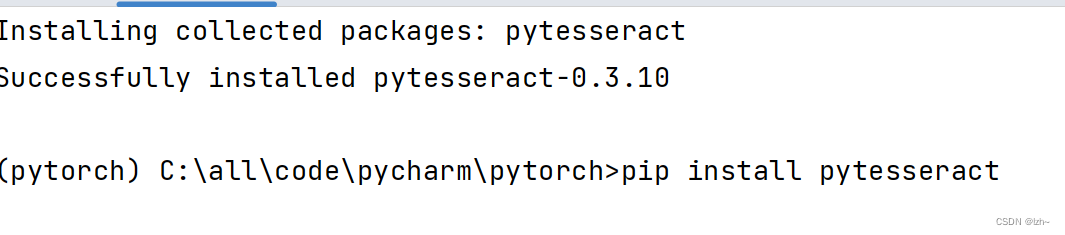
安装完之后找到安装环境目录下面的 pytesseract.py 文件
我这边直接在pycharm中查找更改,点击External Libraries->site-pactages->pytesseract->pysseract.pu
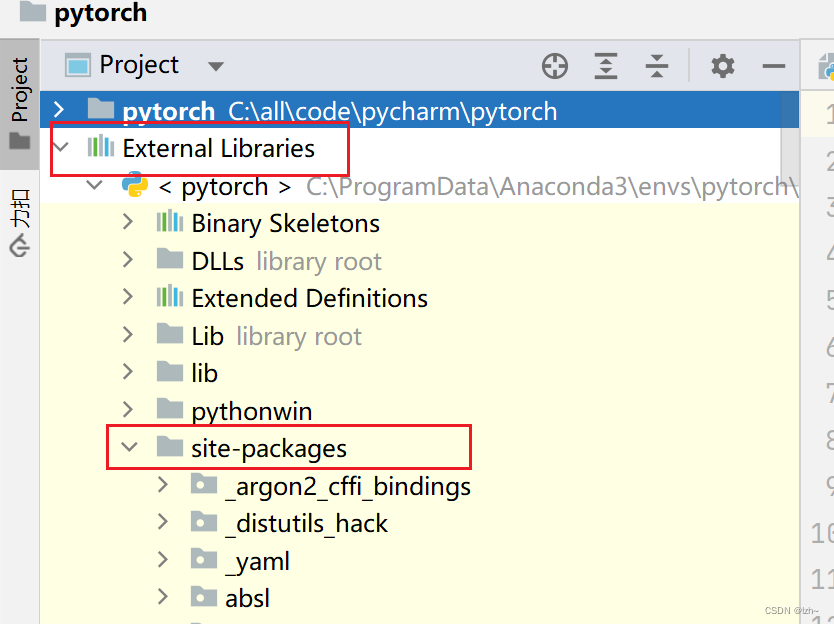
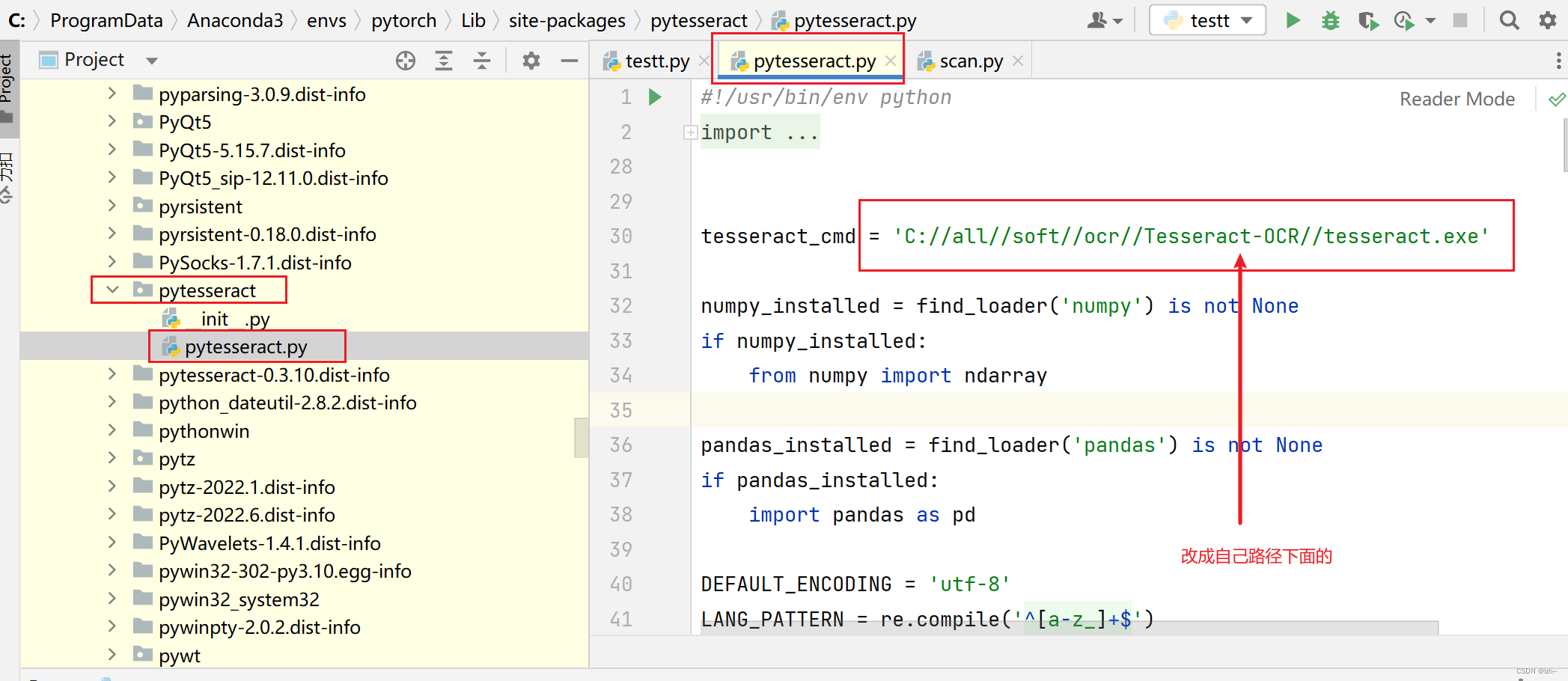
代码
import pytesseract
from PIL import Image
def demo():
# 打开要识别的图片
image = Image.open('test.png')
# 调用image_to_string方法进行识别,
# 传入要识别的图片,lang='chi_sim'是设置为中文识别
text = pytesseract.image_to_string(image, lang='chi_sim')
# 输入所识别的文字
print(text)
if __name__ == '__main__':
demo()
结果
在py中竟然识别错误,cmd命令识别正确Σ(⊙▽⊙"a
相关文章
- 利用Python批量识别电子账单数据
- Tensorflow MNIST 手写体识别代码注释(4)
- NLP-信息抽取-NER-2015-BiLSTM+CRF(二):损失函数【BiLSTM+CRF模型适用于:中文分词、词性标注、命名实体识别】
- ABBYY FineReader2020图片文字识别中文版下载激活密钥安装介绍教程
- ABBYY最新OCR文字识别软件 ,需激活码序列号密钥安装下载
- ABYY OCR 文字识别软件 V15. 安装教程
- 逆向知识十一讲,识别函数的调用约定,函数参数,函数返回值.
- 北大团队研发“车脸”识别系统,不看车牌看外观特征实现精确识别
- js识别不同浏览器
- 57行价值八千万美元的车牌识别代码
- PaddleOCR识别繁体中文和其他国家文字
- C# OpenCV OpenCVSharp OCR识别实例演示与代码--Tesseract数字识别
- OpenCV图像处理——(实战)答题卡识别试卷
- 使用Python,OpenCV进行Tesseract-OCR绑定及识别
- 计算机视觉系列-使用模板匹配识别信用卡数字案例实战(5)
- UIGestureRecognizer ios手势识别温习
- 木马开启智能识别?深度解析新型变形恶意软件LokiBot!