
雪花算法 Snowflake & Sonyflake
2023-09-27 14:26:23 时间
唯一ID算法Snowflake相信大家都不墨生,他是Twitter公司提出来的算法。非常广泛的应用在各种业务系统里。也因为Snowflake的灵活性和缺点,对他的改造层出不穷,比百度的UidGenerator、美团的Leaf、索尼的Sonyflake等等。这篇帖子主要是讲一下原生的Snowflake算法、缺点及改造方案,并分析索尼的Sonyflake源码对原生Snowflake的改造,
原生Snowflake
原生Snowflake算法使用一个64 bit的整型数据,根据当前的时间来生成ID。
原生Snowflake结构如下:
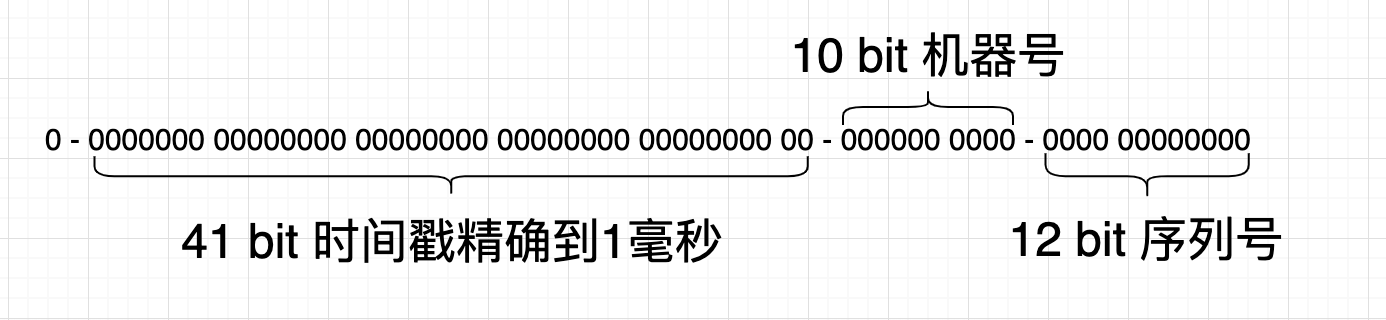
- 因为最高位是标识位,为1表示为负数,所以最高位不使用。
- 41bit 保存时间戳,精确到毫秒。也就是说最大可使用的年限是69年。
- 10bit 的机器位,能部属在1024台机器节点来生成ID。
- 12bit 的序列号,一毫秒最大生成唯一ID的数量为4096个。
原生的Snowflake算法是完全依赖于时间的,如果有时钟回拨的情况发生,会生成重复的ID,市场上的解决方案也是非常多的:
- 最简单的方案,就是关闭生成唯一ID机器的时间同步。
- 使用阿里云的的时间服务器进行同步,2017年1月1日的闰秒调整,阿里云服务器NTP系统24小时“消化”闰秒,完美解决了问题。
- 如果发现有时钟回拨,时间很短比如
5毫秒,就等待,然后再生成。或者就直接报错,交给业务层去处理。 - 可以找2bit位作为时钟回拨位,发现有时钟回拨就将回拨位加1,达到最大位后再从0开始进行循环。
个人比较推荐的是最后一个方案
找2bit位作为时钟回拨位,发现有时钟回拨就将回拨位加1,达到最大位后再从0开始进行循环。
比如下图这样,从机器位上,均出来2位做回拨位:

Sonyflake
Snowflake算法是相当灵活的,我们可以根据自己的业务需要,对63 bit的的各个部分进行增减。索尼公司的Sonyflake对原生的Snowflake进行改进,重新分配了各部分的bit位:

- 39bit 来保存时间戳,与原生的
Snowflake不同的地方是,Sonyflake是以10毫秒为单位来保存时间的。这样的话,可以使用的年限为174年比Snowflake长太多了。
const sonyflakeTimeUnit = 1e7 // nsec, i.e. 10 msec
func toSonyflakeTime(t time.Time) int64 {
return t.UTC().UnixNano() / sonyflakeTimeUnit
}
func currentElapsedTime(startTime int64) int64 {
return toSonyflakeTime(time.Now()) - startTime
}
-
8bit 做为序列号,每10毫最大生成256个,1秒最多生成25600个,比原生的
Snowflake少好多,如果感觉不够用,目前的解决方案是跑多个实例生成同一业务的ID来弥补。 -
16bit 做为机器号,默认的是当前机器的私有IP的最后两位
sf.machineID, err = lower16BitPrivateIP()
func lower16BitPrivateIP() (uint16, error) {
ip, err := privateIPv4()
if err != nil {
return 0, err
}
return uint16(ip[2])<<8 + uint16(ip[3]), nil
}
对于时间回拨的问题Sonyflake简单暴力,就是直接等待 :
func (sf *Sonyflake) NextID() (uint64, error) {
const maskSequence = uint16(1<<BitLenSequence - 1)
sf.mutex.Lock()
defer sf.mutex.Unlock()
current := currentElapsedTime(sf.startTime)
if sf.elapsedTime < current {
sf.elapsedTime = current
sf.sequence = 0
} else { // sf.elapsedTime >= current
sf.sequence = (sf.sequence + 1) & maskSequence
if sf.sequence == 0 {
sf.elapsedTime++
overtime := sf.elapsedTime - current
time.Sleep(sleepTime((overtime)))
}
}
return sf.toID()
}
相关文章
- loadView与viewDidLoad不同 && loadView学习总结
- 从.Net到Java学习第六篇——SpringBoot+mongodb&Thymeleaf&模型验证
- OFA & OMF
- 【操作系统 · 并发】死锁 & 饥饿
- [Mobilar] 03 - Multiple Users: post & pagination
- 欧几里得 & 拓展欧几里得算法 解说 (Euclid & Extend- Euclid Algorithm)
- 【数据结构与算法】编译原理基础知识 / 禅与计算机程序设计艺术 & ChatGPT
- 【大数据&AI人工智能】图文详解 ChatGPT、文心一言等大模型背后的 Transformer 算法原理
- [云计算&大数据]概念辨析:数据仓库 | 数据湖 | 数据中心 | 数据中台 | 数据平台 【待续】
- <context:annotation-config> & <context:component-scan>
- 19【C趣味算法 & 却是用Python解决】国王的失算(数量级太大Dev-C++中无法得出结果),考虑用Python实现
- 【机器学习 & 决策树(分类算法)】信息熵 || ID3算法 || C4.5算法 || Cart算法 || ID3算法示例 || 导出决策树
- 17【C语言 & 趣味算法】爱因斯坦的数学问题
- 01【C语言 & 趣味算法】百钱百鸡问题(问题简单,非初学者请忽略叭)。请注意算法的设计(程序的框架),程序流程图的绘制,算法的优化。
- 【数论算法】最大公约数 & 最小公倍数
- IT经典书籍——Head&nbsp;First系列…
- 【&#9733;】KMP算法完整教程
- 【&#9733;】百度网盘背后的真实策略!
- PM2学习(二)配置文件&环境管理
- LRU算法&&LeetCode解题报告
- HDU ACM 2586 How far away ?LCA->并查集+Tarjan(离线)算法
- C++排序算法冒泡排序&插入排序&选择排序&希尔排序算法
- 2019牛客多校第四场J free——分层图&&最短路
- Python 决策树算法(ID3 & C4.5)
- 前向分步算法 && AdaBoost算法 && 提升树(GBDT)算法 && XGBoost算法
- 基于 Webpack & Vue & Vue-Router 的 SPA 初体验
- 我的Android进阶之旅------>解决Jackson等第三方转换Json的开发包在开启混淆后转换的实体类数据都是null的bug
- 我的Java开发学习之旅------>Java经典排序算法之选择排序