
什么是商业智能BI数据分析的指标爆炸?
指标爆炸这个词大家可能都是第一次听说,指标怎么会爆炸呢?其实这个是我们很多年前在一些商业智能BI项目上总结出来的一种场景或者现象,就是过于的开放给业务人员在BI自助分析过程中创造了很多衍生性的分析指标,结果就造成了前端指标过于臃肿的局面。
什么是指标爆炸
简单来说,指标爆炸具体的表现主要是:
第一,每个人都有能力自己造指标,造成指标的定义在不同的部门或者业务领域出现重复,但实际指标的含义相差甚远。比如名称叫的一样,但是业务计算公式可能不相同,在可视化页面上大家可能看到的名称一样,但解释口径完全不同,指标相互打架。
第二,造了很多临时性的分析指标,指标越来越多,缺乏统一管理,复用度很低,指标像爆炸了一样,越到后期越难管理。
第三,随着业务的变化和调整,指标的业务计算规则可能在一个新的业务周期它的业务逻辑已经发生更改,于是业务人员在前端对指标的一些计算逻辑、聚合规则做了改变,但是这种改变是以直接覆盖的形式,即早期的数据应该保留早期计算规则的但并没有保留,就形成了在一些历史数据在呈现的时候不正确,因为用了新的计算规则来计算。
 数据可视化 - 派可数据商业智能BI可视化分析平台
数据可视化 - 派可数据商业智能BI可视化分析平台
这上面的三种情况随着商业智能BI的应用面越深、越广就越来越混乱,所以我们把这种场景就叫做指标爆炸。
这种场景一般的公司可能基本上碰不到指标爆炸,为什么?这些公司对商业智能BI的应用能力还没有真正达到让业务人员能够完全自助的参与到可视化分析、可视化报表的设计上。只有对商业智能BI应用比较深的,业务人员参与越多的、对业务人员开放性更大的企业才会出现这种问题。
指标爆炸分析
这个问题我们之前碰到过,基本上一碰到苗头就打下去了,但也要去做出一些平衡。有两个关键的点:第一,就是IT和业务在商业智能BI上的边界是什么?第二,指标应该如何统一来管理,如何在自助和规范上做到平衡。自助就意味着能力的开放,规范就是往回拉,要控制。
先来说下第一个点,IT和业务在商业智能BI上的边界是什么?这个大家要结合之前发过的文章视频《BI的后端建模和前端建模有什么区别和联系》,去了解下前后端建模。简单来说IT和业务的边界就在于数据仓库这个层面,从底层业务系统数据源到数据仓库的数据打通、ETL开放、建模等等这些都是IT的活,BI开发人员的活。
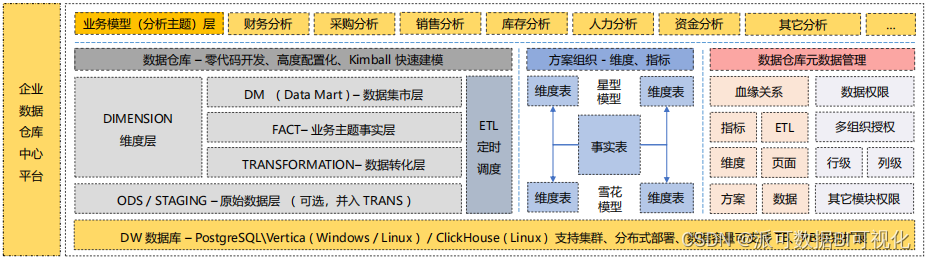 数据仓库 - 派可数据商业智能BI可视化分析平台
数据仓库 - 派可数据商业智能BI可视化分析平台
在数据仓库这个层面对业务人员、前端的BI可视化分析工具开放数据集市层即Data Mart,业务人员日常用到的维度或者事实表指标都在这个层上,通过权限控制让不同的业务人员访问不同的分析模型,这样通过前端建模也可以自助的做各种各样的自助分析,这个问题是可以解决的。
其次,原则上不允许前端业务人员在做商业智能BI分析的时候自己创建新的指标,对于分析指标有一套完整的管理机制,从指标的定义、业务规则的审核、开发、发布和培训有一套完整的流程。
每一个指标都有一个Owner 所有者,避免指标的定义发生歧义,指标的业务规则只能有一套口径,这些指标 定义好了,IT、BI开发人员来开发,开发好了更新到某一个分析模型中或者发布一个新的模型,给业务人员做好分析场景的演示和培训,告诉大家怎么用。
如果业务人员就是想自己造一个指标来用,那这个指标一定是临时性的,就自己在自己的私有报表页面上用,不允许发布到对外的正式可视化页面当中。如果这个指标经过验证,并且得到一致的认同,可以按照之前的管理流程走一遍。这个时候可以通知IT部门BI团队将这个临时性的指标维护到正式的商业智能BI数据仓库中,这样就形成了指标的统一管理,指标也得到了高度可复用、沉淀下来,并且一定是一套统一的口径。
 指标管理 - 派可数据商业智能BI可视化分析平台
指标管理 - 派可数据商业智能BI可视化分析平台
这种方式就可以解决很多问题,既可以保证指标的统一管理、公共指标下沉、指标的复用性,又可以避免业务人员自造指标出现指标爆炸的问题。包括像前面讲到的指标场景,由于业务逻辑发生变更的情况下,需要维护两套或者多套的业务计算规则,这个问题在底层数据仓库上就很容易维护进去,对于业务人员在前端根本就不用关心这些事情了。
这种方法论可以支撑非常大体系的商业智能BI项目,我们之前在一个项目上就涉及到了几百个业务用户,几千张分析报表,业务人员自助做的可视化页面就达到了两千多张,靠的就是这种方式,是已经验证过的非常成功的一种方式。
指标爆炸问题核心
大家注意到没有,解决指标爆炸的核心是什么?第一就是后端建模、完整的数据仓库底座作为基础,没有底层的数据仓库构建,是不可能解决这类问题的,这个结论我就在这里直接告诉给大家。
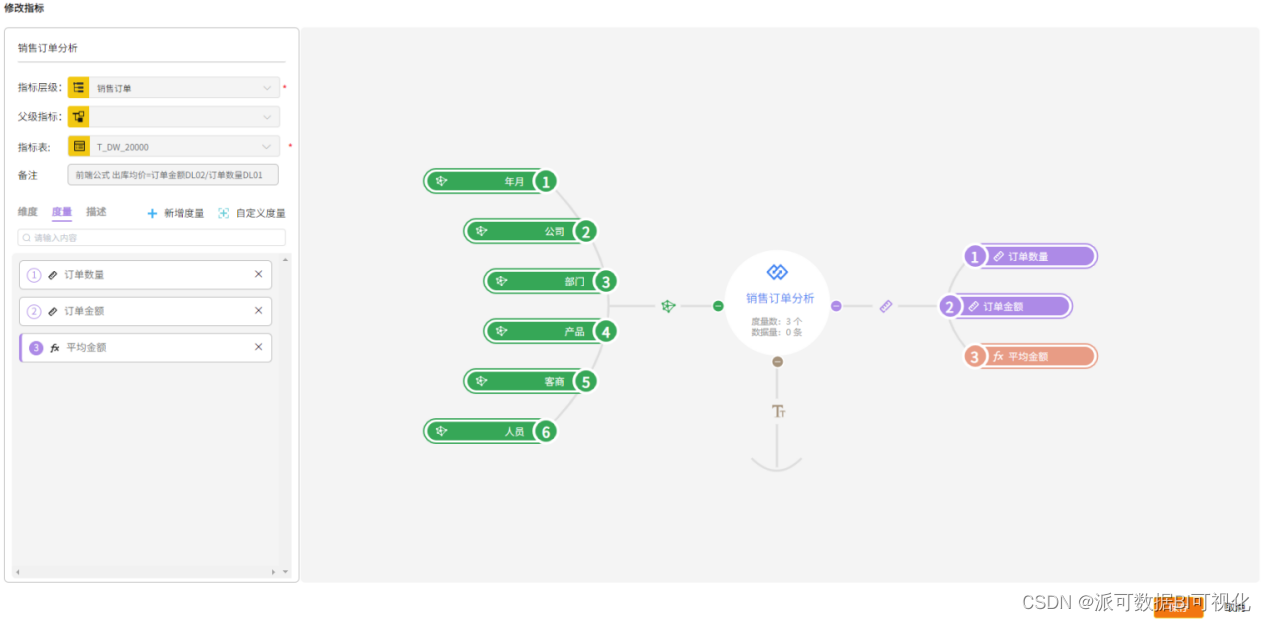 指标管理 - 派可数据商业智能BI可视化分析平台
指标管理 - 派可数据商业智能BI可视化分析平台
第一不管你是传统的基于关系型的数据仓库建模,还是基于大数据架构的数据仓库建模,都是数据仓库建模。第二就是一套完整的关于指标的管理机制,没有这种机制去管理、去控制和平衡IT和业务的边界,对于指标的管理一定会失控,只是会在第一年失控还是在第二年、第三年失控。
规矩往往是最开始定下来比较好,等到真正出现指标失控、指标爆炸的情况再去解决,基本上就已经丧失最好的时机了。客户就会觉得你很不专业,后面要投入这么大的精力、时间来解决这个问题,你到底有没有大项目的规划和建设经验呢?这些问题为什么不一开始就告诉我们呢?当这些事情发生的时候就会很被动。
相关文章
- 大数据分析市场潜力巨大 业务价值已成关注焦点
- 一篇文章解决你所有关于数据分析的问题!
- 数据分析与可视化,你靠什么搞定?
- 数据分析-day02-numpy-分析案例3:抽取数据文件中的数据进行拼接
- 《R语言游戏数据分析与挖掘》一1.4 小结
- 7个影响数据分析的数据建模错误
- Spark是什么?用Spark进行数据分析
- 国内趋于概念化的 “数据分析”在硅谷是怎样真正落地的?
- 游击式大数据软件使农民的数据分析速度加快了五倍
- JMP Discovery Summit数据分析峰会登陆中国
- 数据分析方法论革命来袭,再不掌握敏捷思维你就OUT了!
- 大数据分析模型到底需要满足哪些条件?
- Splunk机器数据分析进军iOS移动应用领域
- 用Excel学数据分析
- 《大数据分析原理与实践》——1.3 什么是大数据分析
- 走出大数据分析误区 寄云多行业工业案例树标杆
- 数字化时代,数据分析到底有什么意义
- 数据分析真的每天都是python,SQL吗?转行数据分析的话要重点学习什么呢?
- 精益数据分析卡片:留存分析
- 大数据分析工具Power BI(七):DAX使用场景及常用函数
- 医疗服务行业大数据分析商业模式分析