
NEO4J的安装配置及使用总结
#工具:使用neo4j desktop版本#
一,下载工具
可以到官方网站上下载桌面版或者community版本的,下载地址:https://neo4j.com/, 安装好。
二、配置环境变量
本文参考了http://blog.csdn.net/appleyk/article/details/79091898来配置的。使用的是jdk 1.8 131的版本。
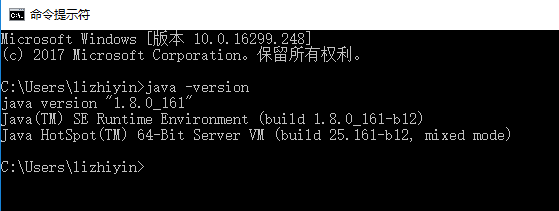
首先,在命令行中输入java -version,查看jvm版本。
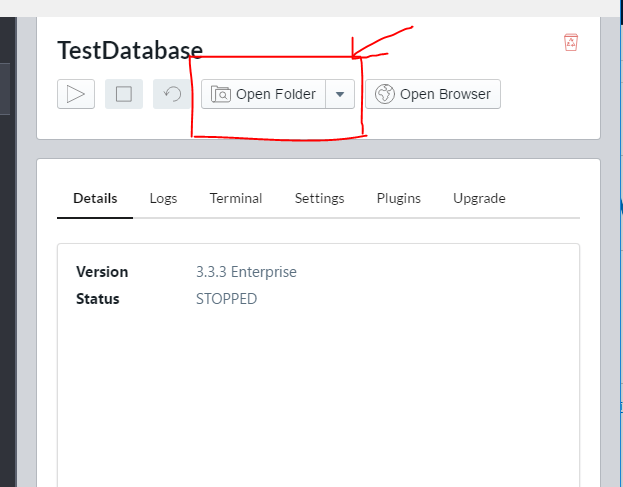
然后,配置环境变量,在计算机-属性-高级系统设置-环境变量,添加NEO4J_HOME=安装包所在的路径,可以根据客户端的应用程序找到,如图所示的位置:
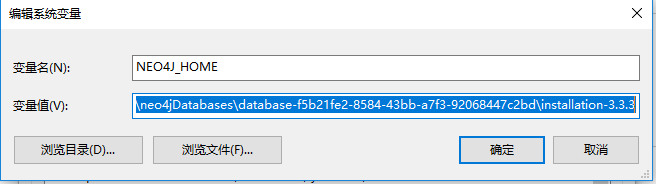
接着,复制路径即可,
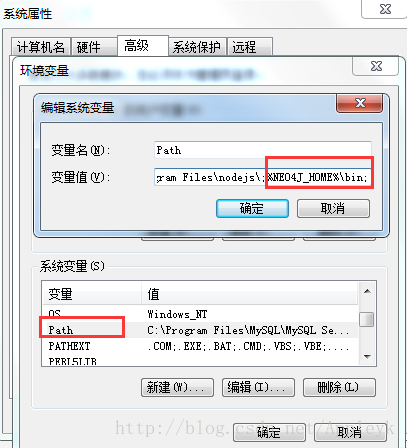
然后,在配置path路径,path中添加%NEO4J_HOME%\bin,即Path = %NEO4J_HOME%\bin;
三、测试
以管理员的身份运行命令行,输入
neo4j.bat console命令之后;
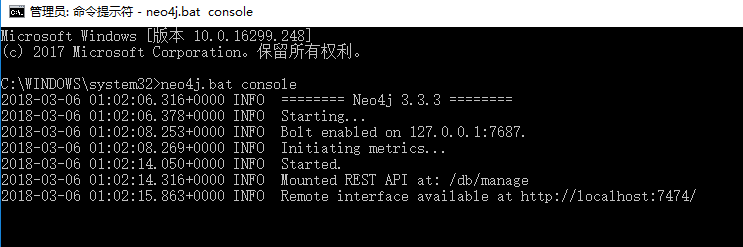
如图所示,已经开启了NEO4J数据库,
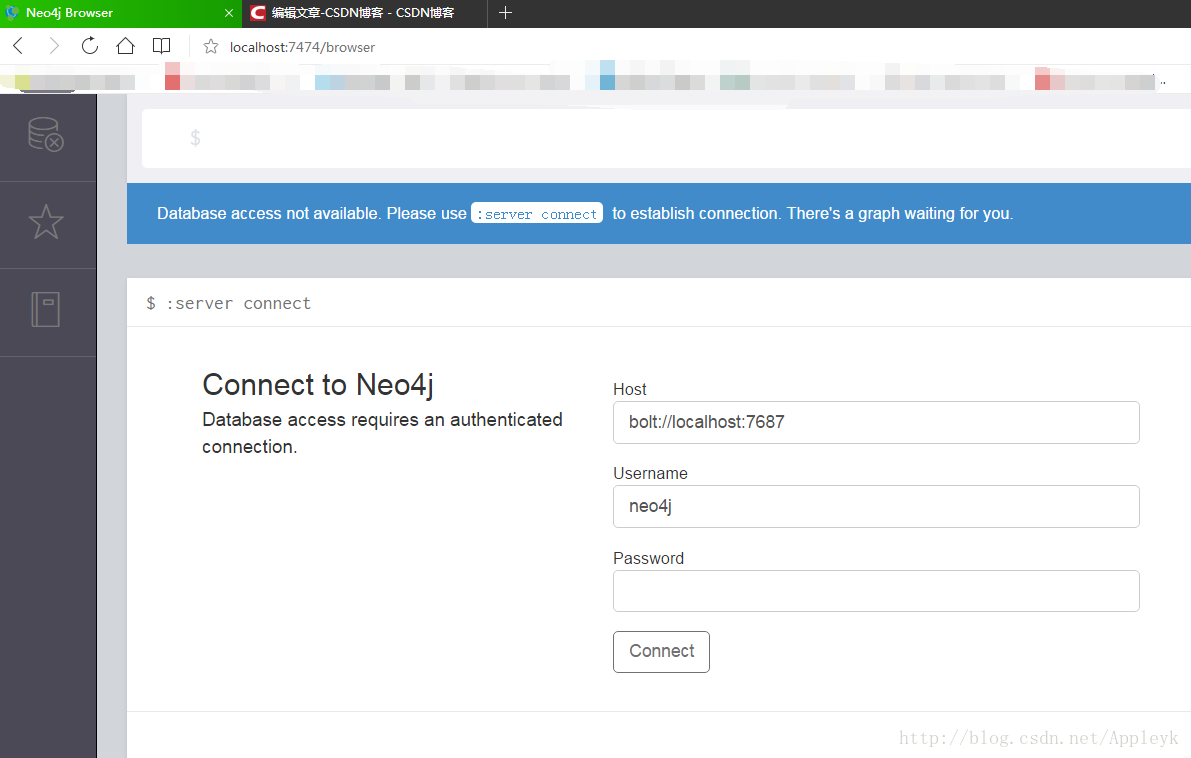
配置成功后,可以在浏览器中使用http://localhost:7474网址查看数据库,但是前提是得把桌面的应用程序关掉。
记住数据库的用户名和密码,一般默认的是:用户:neo4j, 密码:neo4j.
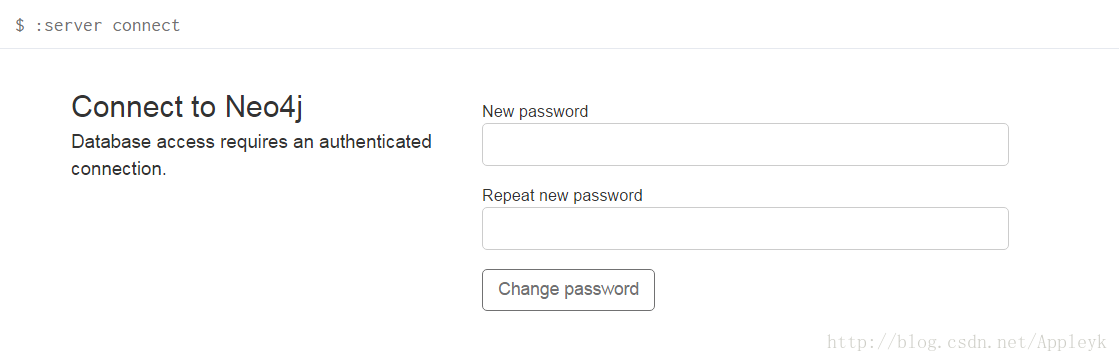
登陆后重新设置密码:
在浏览器上输入用户:user和密码:admin(这里是我的账户)
四、注册NEO4J服务
输入命令:
neo4j install-service
本地服务查看:

五、开启NEO4J服务
输入命令;
neo4j start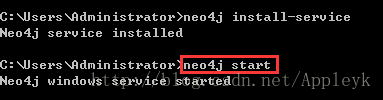
停止、重启、查询Neo4j服务
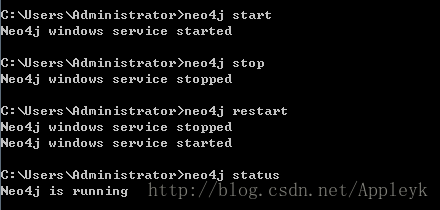
接着,进入数据库操作。
可以使用cypher语言对neo4j数据库进行操作了,此处省略。。。。
这部分首先,在neo4j的数据库中已经进行了,试存储,使用cypher语言,可以把RDFt数据形式的数据存储为图形式的数据了,也就是在谓语的边上添加了关系的属性。实验的例子就是本论文中想到的一个小例子。
如果觉得这样存储数据比较慢的话,可以试试直接将大规模数据导入进neo4j数据库中。
可以观看本博客其他的文章。
原文地址:https://blog.csdn.net/weixin_37197708/article/details/79453703
相关文章
- Hadoop学习笔记(一)——编译安装和配置
- Android Studio 安装配置教程 - MacOS(详细版)
- Python安装及配置
- 在 RHEL/CentOS 7.0 中安装 LAMP
- redhat linux卸载默认的openjdk与安装sun的jdk
- Memcached 笔记与总结(1)Linux(CentOS 6.6) 和 Windows(7)下安装与配置 Memcached (1.4.24)与 Memcached 基础命令
- ubuntu 18.04 安装并配置adb
- Windows系统XAMPP安装Moodle教程
- NTP 安装及配置
- 国产计算框架mindspore在gpu环境下1.3.0版本的分布式计算组件安装 ——(openmpi 和 nccl 的安装,配置,示例代码的运行)
- centos7 mysql数据库安装和配置
- 第一次尝试学习java 安装jdk 与配置环境变量 写第一个java程序 并运行
- MySQL数据库主从同步安装与配置总结
- 手把手学习springcloudalibaba:Git安装和项目克隆
- Linux 之 Ubuntu FTP服务的安装/配置,并使用FileZilla客户端进行文件互传的简单整理
- 解决:eth0安装插卡无法自己主动,网卡的配置信息不network-scripts于
- Mac下四步安装Emacs macport
- 在VirtualBox中安装了Ubuntu后,Ubuntu的屏幕分辨率非常小,操作非常不便。通过安装VirtualBox提供的“增强功能组件”,-摘自网络
- Windows下安装ZooKeeper
- Linux安装Java和tomcat,并添加开机启动服务
- 内网穿透服务、局域网映射到公网,不用写代码轻松实现,安装即使用,基于netty io 实现服务转发与映射,项目封装为 jar 包,可供二次开发和项目集成,比向日葵、nat123、ngrok更有可控性
- Linux CentOS 系统安装 和 相关配置
- Debian 7 安装配置总结