
awk系列:如何使用awk的特殊模式 BEGIN 和 END
在 awk 系列的第八节,我们介绍了一些强大的 awk 命令功能,它们是变量、数字表达式和赋值运算符。
本节我们将学习更多的 awk 功能,即 awk 的特殊模式:BEGIN 和 END。
随着我们逐渐展开,并探索出更多构建复杂 awk 操作的方法,将会证明 awk 的这些特殊功能的是多么强大。
开始前,先让我们回顾一下 awk 系列的介绍,记得当我们开始这个系列时,我就指出 awk 指令的通用语法是这样的:
# awk script filenames
在上述语法中,awk 脚本拥有这样的形式:
/pattern/ { actions }
你通常会发现脚本中的模式(/pattern/)是一个正则表达式,此外,你也可以在这里用特殊模式 BEGIN 和 END。因此,我们也能按照下面的形式编写一条 awk 命令:
awk BEGIN { actions } /pattern/ { actions } /pattern/ { actions } ………. END { actions } filenames
假如你在 awk 脚本中使用了特殊模式:BEGIN 和 END,以下则是它们对应的含义:
BEGIN 模式:是指 awk 将在读取任何输入行之前立即执行 BEGIN 中指定的动作。 END 模式:是指 awk 将在它正式退出前执行 END 中指定的动作。含有这些特殊模式的 awk 命令脚本的执行流程如下:
当在脚本中使用了 BEGIN 模式,则 BEGIN 中所有的动作都会在读取任何输入行之前执行。 然后,读入一个输入行并解析成不同的段。 接下来,每一条指定的非特殊模式都会和输入行进行比较匹配,当匹配成功后,就会执行模式对应的动作。对所有你指定的模式重复此执行该步骤。 再接下来,对于所有输入行重复执行步骤 2 和 步骤 3。 当读取并处理完所有输入行后,假如你指定了 END 模式,那么将会执行相应的动作。当你使用特殊模式时,想要在 awk 操作中获得最好的结果,你应当记住上面的执行顺序。
为了便于理解,让我们使用第八节的例子进行演示,那个例子是关于 Tecmint 拥有的域名列表,并保存在一个叫做 domains.txt 的文件中。
news.tecmint.com tecmint.com linuxsay.com windows.tecmint.com tecmint.com news.tecmint.com tecmint.com linuxsay.com tecmint.com news.tecmint.com tecmint.com linuxsay.com windows.tecmint.com tecmint.com
$ cat ~/domains.txt
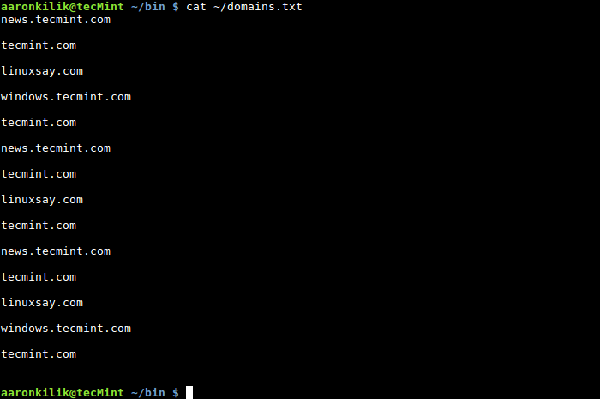
查看文件内容在这个例子中,我们希望统计出 domains.txt 文件中域名 tecmint.com 出现的次数。所以,我们编写了一个简单的 shell 脚本帮助我们完成任务,它使用了变量、数学表达式和赋值运算符的思想,脚本内容如下:
#!/bin/bash for file in $@; do if [ -f $file ] ; then ### 输出文件名 echo "File is: $file" ### 输出一个递增的数字记录包含 tecmint.com 的行数 awk /^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; } $file else ### 若输入不是文件,则输出错误信息 echo "$file 不是一个文件,请指定一个文件。" 2 exit 1 done ### 成功执行后使用退出代码 0 终止脚本 exit 0
现在让我们像下面这样在上述脚本的 awk 命令中应用这两个特殊模式:BEGIN 和 END:
我们应当把脚本:
awk /^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; } $file
改成:
awk BEGIN { print "文件中出现 tecmint.com 的次数是:" ; } /^tecmint.com/ { counter+=1 ; } END { printf "%s\n", counter ; } $file
在修改了 awk 命令之后,现在完整的 shell 脚本就像下面这样:
#!/bin/bash for file in $@; do if [ -f $file ] ; then ### 输出文件名 echo "File is: $file" ### 输出文件中 tecmint.com 出现的总次数 awk BEGIN { print "文件中出现 tecmint.com 的次数是:" ; } /^tecmint.com/ { counter+=1 ; } END { printf "%s\n", counter ; } $file else ### 若输入不是文件,则输出错误信息 echo "$file 不是一个文件,请指定一个文件。" 2 exit 1 done ### 成功执行后使用退出代码 0 终止脚本 exit 0
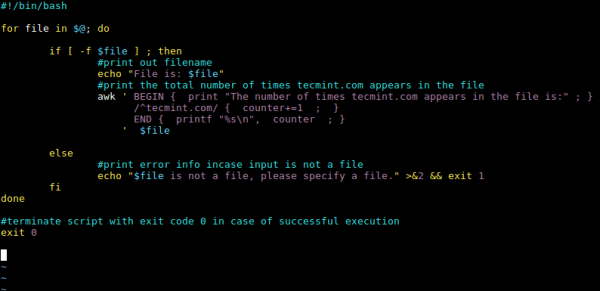
awk 模式 BEGIN 和 END当我们运行上面的脚本时,它会首先输出 domains.txt 文件的位置,然后执行 awk 命令脚本,该命令脚本中的特殊模式 BEGIN将会在从文件读取任何行之前帮助我们输出这样的消息“文件中出现 tecmint.com 的次数是:”。
接下来,我们的模式 /^tecmint.com/ 会在每个输入行中进行比较,对应的动作 { counter+=1 ; } 会在每个匹配成功的行上执行,它会统计出 tecmint.com 在文件中出现的次数。
最终,END 模式将会输出域名 tecmint.com 在文件中出现的总次数。
$ ./script.sh ~/domains.txt

用于统计字符串出现次数的脚本最后总结一下,我们在本节中演示了更多的 awk 功能,并学习了特殊模式 BEGIN 和 END 的概念。
正如我之前所言,这些 awk 功能将会帮助我们构建出更复杂的文本过滤操作。第十节将会给出更多的 awk 功能,我们将会学习 awk 内置变量的思想,所以,请继续保持关注。
作者:Aaron Kili 来源:51CTO相关文章
- 9、【设计模式】外观模式(门面模式)
- 如何写一篇人工智能领域的期刊论文(SCI论文的固定模式和一些套路)
- sqoop如何指定pg库的模式
- 从“模式创新”到“科技破局”,云从科技如何穿越时代变革周期?
- 快速迭代的互联网研发模式下测试如何突破?
- IOS设计模式之三:MVC模式
- 如何在UEFI模式下安装Linux
- WDS(Windows部署服务)如何为boot.wim或install.wim添加驱动 GUI模式
- 03.如何实现一个遥控器-命令模式
- Spring Boot 2.5 重磅发布,黑暗模式太炸了!
- Ubuntu如何进入命令模式
- 设计模式--装饰器模式
- FTP基础知识 FTP port(主动模式) pasv(被动模式) 及如何映射FTP
- 如何借助云实现运营模式的转型:六个步骤
- 岩田聪:云计算游戏模式很难保证低延迟
- 029_siwft_两种单例模式
- 如何使用MVP模式搭建我们的Android应用?
- WCF如何克服HTTP传输协议的局限提供对不同消息传输模式的实现
- 【OkHttp】OkHttp 源码分析 ( 网络框架封装 | OkHttp 4 迁移 | OkHttp 建造者模式 )
- PHP设计模式——命令模式
- 浅谈设计模式-组合模式
- Java设计模式之单例模式