
亿级下ApsaraDB HBase Phoenix秒级内RT在大搜车实践
HBase 实践 RT 亿级 Phoenix 秒级
2023-09-27 14:23:40 时间
大搜车中国领先的车商服务平台。凭借多年对汽车行业的深刻洞察与理解推出了适合汽车经销商集团及大型二手车商的业务经营管理系统“大风车”适合中小二手车商的经营管理系统“车牛”汽车消费延保产品“大搜车质保”以及基于蚂蚁金服开放平台赋能的信用购车 先用后买金融服务方案—“弹个车”为车商提供软件服务、金融服务、交易服务及营销服务等助力经销商提高管理及盈利能力。
使用阿里云数据集成 服务将mysql数据导入至PHoenix,不过它使用的HBase原生api导入,所以索引数据需要在导完之后再重建。 使用MapReduce的方式,这种更友好,直接导出为HFile文件,不必走HBase API,这样会减少集群的负载以及网络消耗,速度更快。但使用的是阿里云HBase,依赖的Hadoop集群不对外。 使用Phoenix提供的 psql.py脚本以csv文件的方式导入。

应用GC情况 左边为应用日志 右边为GC(对应列分别为S0 S1 E O M CCS YGC YGCT FGC FGCT GCT),应用本身GC状态良好。
 HBase负载,从HBase 两台数据节点负载看得出压测的时候已经完全将HBase负载压到极限之上,所以不难得出如果在系统资源充足的情况下,并发数相同的情况下,TPS、RT远远比目前的结果要好。
HBase负载,从HBase 两台数据节点负载看得出压测的时候已经完全将HBase负载压到极限之上,所以不难得出如果在系统资源充足的情况下,并发数相同的情况下,TPS、RT远远比目前的结果要好。

进过压力测试,以及上线了一段时间,ApsaraDB HBase Phoenix能满足我们的业务场景的使用。同时Aliyun HBase支持横向扩展以及靠谱的运维能力,也为后面支持更高的并发提供夯实的基础。 结合我们业务场景,基本都是单表的复杂聚合操作,对IO消耗比较大,因此最近迁移了HBase,把云盘换成了SSD盘。提高IO的能力。迁移工具 同时期待Aliyun HBase的数据迁移能更加完善。
Phoenix on HBase+Solr = 易用一体化大数据在线宽表引擎 在大数据场景中,HBase由于其高吞吐,高并发,实时可见等特性往往被作为在线主存储,云HBase团队融合了在线存储引擎和全文引擎的优势,解决了针对在线大数据存储的复杂查询难题,并提供SQL统一表达,降低用户使用门槛。通过一站式产品能力,用户可以更加灵活高效地解决业务问题。
第十二届 BigData NoSQL Meetup — 基于hbase的New sql落地实践 立即下载
大搜车业务线众多,对于数据的需求也各种各样,本文将介绍其中之一的大搜车车商客户实时数据需求,例如车商PC|H5端店铺、车辆、分享等实时流量数据报表;随着数据量级的增长,目前数据量级在亿级以上,原有以mysql提供查询服务不再适合此场景,经过多方面的考虑,存储最终选择Aliyun HBase,同时为了几乎0成本的切换,采用Phoenix On HBase Sql中间件,它管理着HBase的二级索引并且它对sql的支持友好,本文也将介绍Phoenix和HBase结合场景下的压力测试。
二、数据系统架构 实时数据来源为采集PC|H5端访问日志,通过Flume收集这些日志,并按照业务场景需求,通过流试计算清洗、过滤、统计,使用Phoenix api实时推送到HBase。 由于Phoenix管理HBase二级索引,使用Phoenix api推送数据索引表的也会被更新,这样对于编码成本很低。 原始的日志同时会通过Flume 持久化至HDFS,方便离线计算数据分析。统一通过数据网关提供业务查询。
*架构图:* 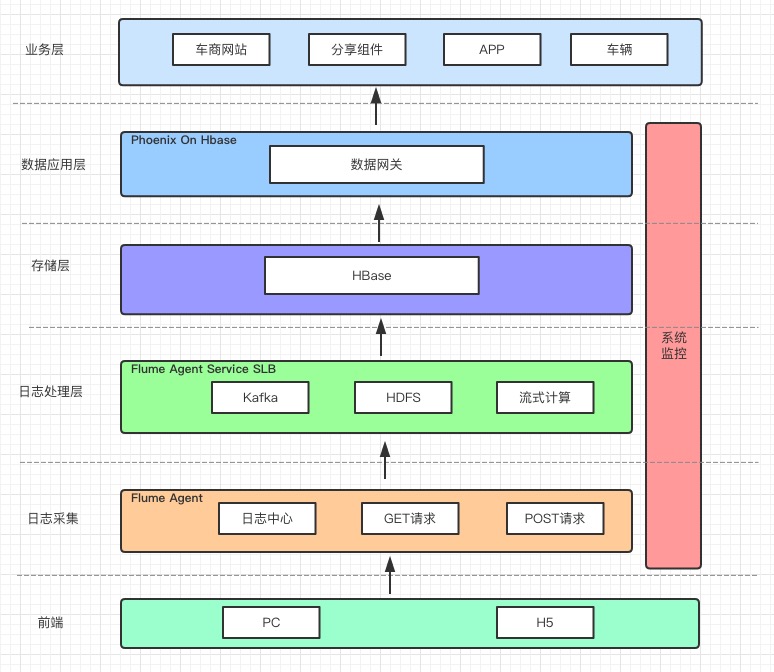
使用阿里云数据集成 服务将mysql数据导入至PHoenix,不过它使用的HBase原生api导入,所以索引数据需要在导完之后再重建。 使用MapReduce的方式,这种更友好,直接导出为HFile文件,不必走HBase API,这样会减少集群的负载以及网络消耗,速度更快。但使用的是阿里云HBase,依赖的Hadoop集群不对外。 使用Phoenix提供的 psql.py脚本以csv文件的方式导入。
考虑到是一次性的工作,本次压测数据我采用Phoenix提供的脚本的方式导入数据。
表建立 参考
CREATE TABLE FLOW.SHOP_DATA_BY_SALER_CAR_V2 ( PK varchar primary key, INFO.DATE_STR BIGINT, INFO.STORE_ID VARCHAR, INFO.CAR_ID VARCHAR, INFO.SELLER_ID VARCHAR, INFO.SHARE_PV INTEGER, INFO.SHARE_UV INTEGER, INFO.FLOW_PV INTEGER, INFO.FLOW_UV INTEGER, INFO.CALL_PV INTEGER, INFO.CALL_UV INTEGER, INFO.APPOINT_PV INTEGER, INFO.APPOINT_UV INTEGER, INFO.LAST_UPDATE_TIME DATE ) COMPRESSION=SNAPPY,DATA_BLOCK_ENCODING=DIFF;
针对sql模板场景,建立索引表,索引类为覆盖索引 Secondary Indexing
CREATE INDEX SHOP_DATA_BY_SALER_CAR_V2_INDEX ON FLOW.SHOP_DATA_BY_SALER_CAR_V2 (INFO.STORE_ID, INFO.DATE_STR) INCLUDE (INFO.SELLER_ID, INFO.CAR_ID, INFO.SHARE_PV, INFO.FLOW_PV, INFO.CALL_PV, INFO.APPOINT_PV) COMPRESSION=SNAPPY,DATA_BLOCK_ENCODING=DIFF
CREATE INDEX SHOP_DATA_BY_SALER_CAR_V2_INDEX1 ON FLOW.SHOP_DATA_BY_SALER_CAR_V2 (INFO.CAR_ID, INFO.DATE_STR, INFO.SHARE_PV) INCLUDE (INFO.SELLER_ID, INFO.FLOW_PV, INFO.CALL_PV, INFO.APPOINT_PV) COMPRESSION=SNAPPY,DATA_BLOCK_ENCODING=DIFF
数据样例的选择:sql查询时间范围均为1个月,查询条件由挑选出这1个月中按车商、销售、车辆各个分组总条数在前300、300、300的数据按照模板随机组合查询。保证sql查询都能命中数据,同时也排除每次都是量很大的数据。数据样例见最后。测试表的数据量级在亿行以上。
压测分别从10 ~ 100并发之前压测,以10为累加单位进行压测,压测时间为10分钟。目前我们业务场景每秒并发数在50 ~ 80左右,高峰期高于80。
压测的场景模拟线上的请求,查询基本是都是单表比较复杂的聚合操作。 压测结果分别从TPS(每秒处理任务数)、RT(平均响应数据)两个指标衡量。
应用GC情况 左边为应用日志 右边为GC(对应列分别为S0 S1 E O M CCS YGC YGCT FGC FGCT GCT),应用本身GC状态良好。
HBase负载,从HBase 两台数据节点负载看得出压测的时候已经完全将HBase负载压到极限之上,所以不难得出如果在系统资源充足的情况下,并发数相同的情况下,TPS、RT远远比目前的结果要好。
进过压力测试,以及上线了一段时间,ApsaraDB HBase Phoenix能满足我们的业务场景的使用。同时Aliyun HBase支持横向扩展以及靠谱的运维能力,也为后面支持更高的并发提供夯实的基础。 结合我们业务场景,基本都是单表的复杂聚合操作,对IO消耗比较大,因此最近迁移了HBase,把云盘换成了SSD盘。提高IO的能力。迁移工具 同时期待Aliyun HBase的数据迁移能更加完善。
数据样例, ps:数据集经过特殊处理。
车商数据集
010140548,001106040,001109847,001104443,001106241,001101049,001110943,001131047,001119549,001121749,001102043,001142748,001118444,001108248,001111340,001108240,001151942 .......
车辆数据集
Cg6f7hXsfkqffgWHsafk,adfu3fMhZsfkDffBFsa4kNadf,fcfchesfkdfg15saakcadf6d487b834e2b8eb81217c,72f8hOsfkRffgdIsaQkMadf,75fah8sfk3fg8fsa4kdadf7c4e03b9e46a864b858b6,59f0hesfk5ffg96sadk8adf934d72b4f8119f0e38acb .......
销售数据集
11234,11791,18782,13298,15889,13069,13213,18231,18988,18346,18946,13137,15051,15320,15680,15066,15512,13585,15555,13235,18195,13888,13363,13921,17777,18088,13188,15708 .....
Phoenix on HBase+Solr = 易用一体化大数据在线宽表引擎 在大数据场景中,HBase由于其高吞吐,高并发,实时可见等特性往往被作为在线主存储,云HBase团队融合了在线存储引擎和全文引擎的优势,解决了针对在线大数据存储的复杂查询难题,并提供SQL统一表达,降低用户使用门槛。通过一站式产品能力,用户可以更加灵活高效地解决业务问题。
第十二届 BigData NoSQL Meetup — 基于hbase的New sql落地实践 立即下载