
[Terraform] 06 - Autoscaling and ELB
and 06 Terraform
2023-09-27 14:23:24 时间
Ref: https://www.udemy.com/course/terraform-cn/learn/lecture/21107132#overview
先创建一个ce2,然后cpu 拉高,触发报警,并创建另一个,分担压力。
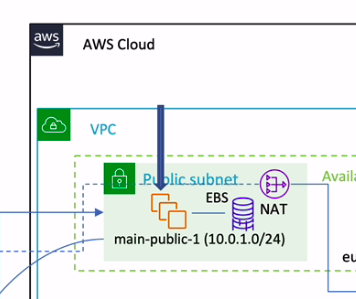
EC2模式
一、关键代码解析
[ autoscaling.tf ]
# 对新增实例的定义
resource "aws_launch_configuration" "example-launchconfig" { name_prefix = "example-launchconfig" image_id = var.AMIS[var.AWS_REGION] instance_type = "t2.micro" key_name = aws_key_pair.mykeypair.key_name security_groups = [aws_security_group.allow-ssh.id] }
resource "aws_autoscaling_group" "example-autoscaling" { name = "example-autoscaling" vpc_zone_identifier = [aws_subnet.main-public-1.id, aws_subnet.main-public-2.id] launch_configuration = aws_launch_configuration.example-launchconfig.name min_size = 1 max_size = 2 health_check_grace_period = 300 # <---- 单位是sec health_check_type = "EC2" force_delete = true tag { key = "Name" value = "ec2 instance" propagate_at_launch = true } }
[ autoscalingpolicy.tf ]
增容。
# scale up alarm resource "aws_autoscaling_policy" "example-cpu-policy" { name = "example-cpu-policy" autoscaling_group_name = aws_autoscaling_group.example-autoscaling.name adjustment_type = "ChangeInCapacity" scaling_adjustment = "1" cooldown = "300" policy_type = "SimpleScaling" }
# 触发警报配置 resource "aws_cloudwatch_metric_alarm" "example-cpu-alarm" { alarm_name = "example-cpu-alarm" alarm_description = "example-cpu-alarm" comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = "2" metric_name = "CPUUtilization" namespace = "AWS/EC2" period = "120" statistic = "Average" threshold = "30" dimensions = { "AutoScalingGroupName" = aws_autoscaling_group.example-autoscaling.name } actions_enabled = true alarm_actions = [aws_autoscaling_policy.example-cpu-policy.arn] }
减容。
# scale down alarm resource "aws_autoscaling_policy" "example-cpu-policy-scaledown" { name = "example-cpu-policy-scaledown" autoscaling_group_name = aws_autoscaling_group.example-autoscaling.name adjustment_type = "ChangeInCapacity" scaling_adjustment = "-1" cooldown = "300" policy_type = "SimpleScaling" }
# 触发报警配置 resource "aws_cloudwatch_metric_alarm" "example-cpu-alarm-scaledown" { alarm_name = "example-cpu-alarm-scaledown" alarm_description = "example-cpu-alarm-scaledown" comparison_operator = "LessThanOrEqualToThreshold" evaluation_periods = "2" metric_name = "CPUUtilization" namespace = "AWS/EC2" period = "120" statistic = "Average" threshold = "5" dimensions = { "AutoScalingGroupName" = aws_autoscaling_group.example-autoscaling.name } actions_enabled = true alarm_actions = [aws_autoscaling_policy.example-cpu-policy-scaledown.arn] }
二、架构检查
-
AUTO SCALING
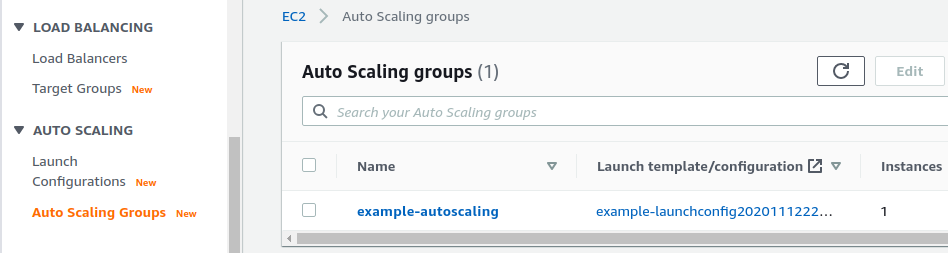
-
CloudWatch
| Conditions |
| CPUUtilization >= 30 for 2 datapoints within 4 minutes |
| CPUUtilization <= 5 for 2 datapoints within 4 minutes |
一个scaling up, 一个scaling down。
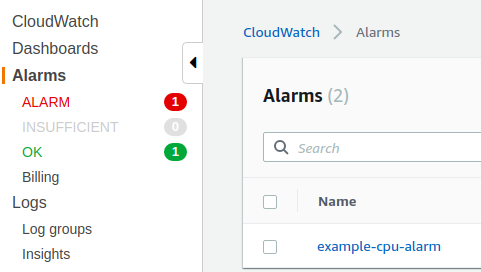
三、提高cpu使用率
通过安装stress命令,进行压力测试。
ssh -i mykey ubuntu@<ip address>
(1) Scaling up
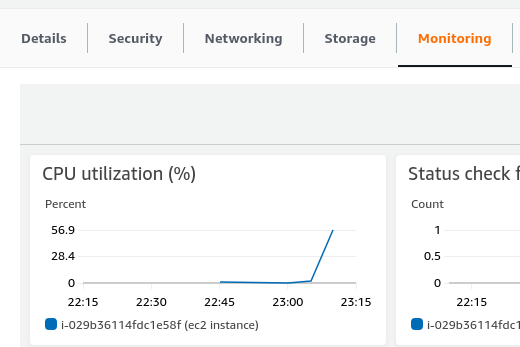
自动新创建了一个 instance。

(2) 然后自动 scaling down
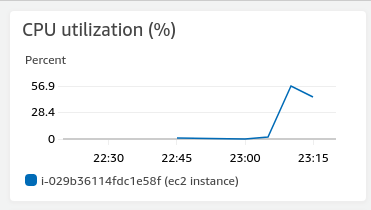
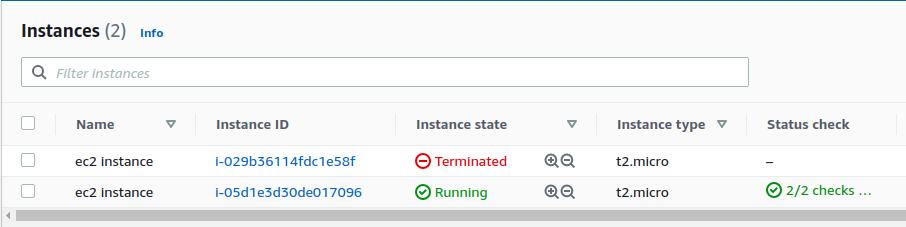
触发了警报。

自动随机地 terminate 了其中一个 instance。
ELB模式
一、Load Balancer 配置
resource "aws_autoscaling_group" "example-autoscaling" { name = "example-autoscaling" vpc_zone_identifier = [aws_subnet.main-public-1.id, aws_subnet.main-public-2.id] launch_configuration = aws_launch_configuration.example-launchconfig.name min_size = 2 max_size = 2 health_check_grace_period = 300 health_check_type = "ELB" load_balancers = [aws_elb.my-elb.name] force_delete = true tag { key = "Name" value = "ec2 instance" propagate_at_launch = true } }
-
-
生成新实例
-
resource "aws_launch_configuration" "example-launchconfig" { name_prefix = "example-launchconfig" image_id = var.AMIS[var.AWS_REGION] instance_type = "t2.micro" key_name = aws_key_pair.mykeypair.key_name security_groups = [aws_security_group.myinstance.id] user_data = "#!/bin/bash\napt-get update\napt-get -y install net-tools nginx\nMYIP=`ifconfig | grep -E '(inet 10)|(addr:10)' | awk '{ print $2 }' | cut -d ':' -f2`\necho 'this is: '$MYIP > /var/www/html/index.html" lifecycle { create_before_destroy = true } }
-
-
elb.tf 配置
-
nginx默认端口80,作为新实例生成的 health检查标准。
resource "aws_elb" "my-elb" { name = "my-elb" subnets = [aws_subnet.main-public-1.id, aws_subnet.main-public-2.id] security_groups = [aws_security_group.elb-securitygroup.id] listener { instance_port = 80 instance_protocol = "http" lb_port = 80 lb_protocol = "http" } health_check { healthy_threshold = 2 # 检查的次数,两次都health,才是真health unhealthy_threshold = 2 timeout = 3 target = "HTTP:80/" interval = 30 } cross_zone_load_balancing = true connection_draining = true connection_draining_timeout = 400 tags = { Name = "my-elb" } }
二、配置结果
耐心等待两个instance的初始化脚本都安装结束。
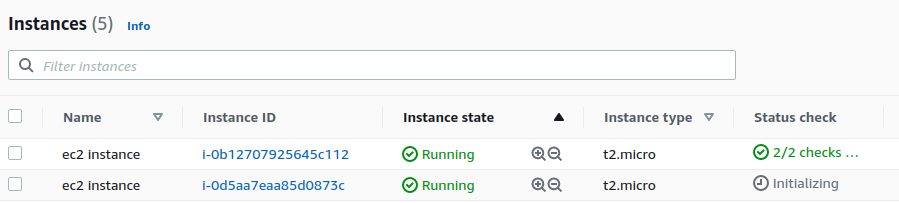
Load Balancer未激活状态?
但结果就是,返回两个vpc子网的其中一个。
End.
相关文章
- Lintcode: Binary Tree Serialization (Serialization and Deserialization Of Binary Tree)
- Summary: Arrays vs. Collections && The differences between Collection Interface and Collections Class
- IIS URL Rewriting and ASP.NET Routing
- What are the differences between Flyweight and Object Pool patterns?
- 【CF429E】Points and Segments(欧拉回路)
- 【CF1097E】Egor and an RPG game(动态规划,贪心)
- ActiveMQ, Qpid, HornetQ and RabbitMQ in Comparison
- POJ 1704 Georgia and Bob (博弈)
- DRF 3.x URLs and Router 链接和路由使用示例和配置方法
- What is the difference between GUI and UI?
- 《Learning both Weights and Connections for Efficient Neural Networks》论文笔记
- 质数(素数)and sqrt()