
hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接!
一、前期准备:
1、jdk安装 不要用centos7自带的openJDK
2、hostname 配置 配置位置:/etc/sysconfig/network文件
3、hosts 配置 配置位置 : /etc/hosts
4、date 配置 date -s "....."设置日期一致
5、 关闭安全机制 /etc/sysconfig/selinux
6、 关闭防火墙:firewall iptables off
7、映射文件更改 :windows 域名映射 /etc/hosts文件
本环境的搭建角色:主结点node01,从结点node02,、node03,、node04,第二主节点secondaryNameNode的位置:node02
密匙文件分发到从结点
分发命令举例:
[root@node01 hadoop-2.6.5]# scp id_dsa.pub node02:`pwd`/node01.pub
这些都设置好了之后才具备全分布式搭建的条件
二、环境搭建
节点: node01/02/03/04全分布分配方案:
NN SNN DN
NODE01 *
NODE02 * *
NODE03 *
NODE04 *
节点状态:
node01: 伪分布
node02/03/04 : ip配置完成
建立各节点通讯(hosts) 可以通过Ping 结点主机的别名来检查是否结点之间能够通讯成功
设置时间同步:date -s “xxxx-x-xx xx:xx:xx”
秘钥分发:
在每个节点上登录一下自己:产生.ssh目录 ------------------------具体的从新登陆代码:
从node01向node02/node03/node04分发公钥 (公钥的名称要变化)
scp id_dsa.pub node03:`pwd`/node06.pub ---------------------》要明白这里的主结点分发给从结点的公钥文件的名称为啥要变化,是为了如果有其他的结 点 也想要管理这个几点的话, 也会发公钥文件给从结点,如果不改名的话,第二个管理结 点的分发的公钥文件会覆盖掉第一个下发的公钥文件。
各节点把node01的公钥追加到认证文件里:
cat ~/node06.pub >> ~/.ssh/authorized_keys ----------------------》这样之后才会能够实现主结点到从结点的免密登录
node02/node03/node04安装jdk环境,node01分发profile给其他节点,并重读配置文件 :通过source 或者. /etc/profile的形式
分发hadoop部署程序2.6.5 到其他节点
copy node06 下的 hadoop 为 hadoop-local (管理脚本只会读取hadoop目录)
[root@node06 etc]# cp -r hadoop/ hadoop-pesudo --------------->作为分布式集群的备份目录,如果以后想要启动伪分布式集群的话,则可以将这个备份文件改名为hadoop
配置core-site.xml ---------------------》需要配置的是产生的dataNode、DataNode等结点的数据文件,如fsimage文件的位置
配置hdfs-site.xml ---------------------》配置从结点的个数和,第二主结点的位置,如可以将第二个主结点放到其他的某个从结点的位置 之上
配置slaves
分发sxt目录以及他一下的所有的内容及目录 到其他07,08,09节点 ----------------》这样做的好处就是,不用在其他的每个从结点上再去一一的建立一个相同的目录了
格式化集群:hdfs namenode -format ----------------->注意这里格式化完毕之后仅仅是产生一个头结点的数据文件,其他的服务器上 的从结点的数据文 件 和存放数据文件的目录是集群启动的时候才会产生的
至此集群搭建完毕!!!
三、集群启动
启动集群:start-dfs.sh
Jps 查看各节点进程启动情况
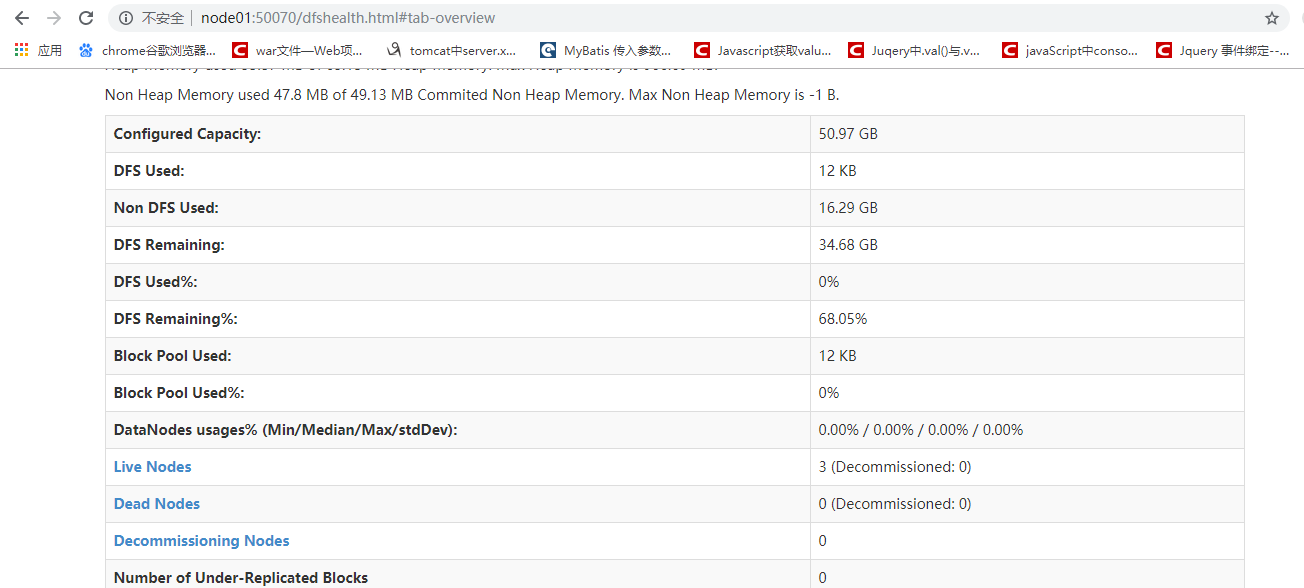
之后如果想要浏览器访问集群的话,需要查询集群和浏览器交互的端口号,一般是50070 ------------》ss -nal
浏览器成功的访问分布式存储系统
四、文件上传
- 上传文件到分布式存储系统
先创建一个用于上传的1.4M大小的文件
[root@node01 hadoop-2.6.5]# for i in `seq 100000`;do echo "hello sxt $i" >> test.txt;done
效果

具体的对于上传的文件的分割的大小可以做规定,一般的是默认128M每一块,我们可以通过以下的命令来设置
命令意义:将test.txt文件分割上传,并设置分割大小为1M,所以比如这个文件的总的大小是1.4M 的话,会分成两块
[root@node01 software]# hdfs dfs -D dfs.blocksize=1048576 -put test.txt
上传之后的效果
1)从浏览器上看
块1的存储效果
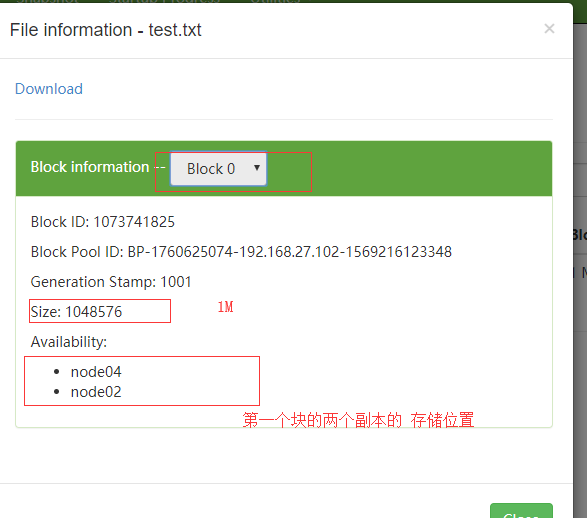
块2的存储效果

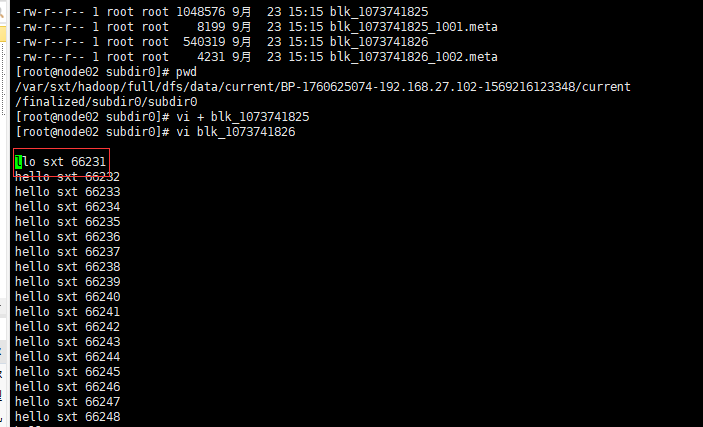
2)从xshell中看
输入命令
所在目录:存储有数据块的从结点的/var/sxt/hadoop/full/dfs/data/current/BP-1760625074-192.168.27.102-1569216123348/current路径下的文件,如下图

打开底层存储的文本文件test.txt 的blk_107341825的效果
block0

block1
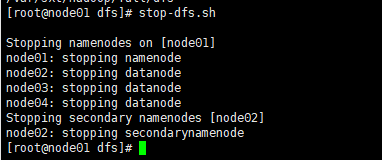
集群停止:
[root@node01 dfs]# stop-dfs.sh
相关文章
- cdh搭建hadoop集群
- 基于docker搭建Hadoop CDH高可用集群
- Avro:数据序列化系统【Hadoop中的一个子项目】【用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换】
- 大数据-Hadoop-HDFS(四):DataNode【数据完整性校验算法:crc、md5、sha1】【DataNode掉线时限:HDFS默认超过10分钟+30秒无心跳则死亡】
- 基于zookeeper的高可用Hadoop HA集群安装
- Hadoop何以快速成为最佳网络安全工具?
- hadoop 集群的搭建
- hadoop分布式集群搭建
- 从入门到实战Hadoop分布式文件系统
- [Spark] 00 - Install Hadoop & Spark
- Hadoop技术让大数据处理变得简单
- hadoop-1.1.0 rpm + centos 6.3 64虚拟机 + JDK7 搭建分布式集群
- Hadoop 2.8集群安装及配置记录
- [大数据学习研究] 错误排查,Hadoop集群部分DataNode不能启动
- Hadoop集群搭建
- Hadoop教程 day04 源码编译
- 大数据 IMF 传奇 困扰很久的问题解决!ecliplse 远程提交程序到虚拟机 hadoop集群 ,ecliplse 没有显示输出 的问题解决!
- 生产环境实战spark (8)分布式集群 Hadoop集群WEBUI打不开问题解决,关闭防火墙firewall
- 生产环境实战spark (7)分布式集群 5台设备 Hadoop集群安装
- Hadoop集群容易被攻击的几个场景
- hadoop备战:yarn框架的简单介绍(mapreduce2)
- 大数据成长之路------hadoop集群的部署 配置系统网络(静态) 新增集群(三台)
- 对于ElasticSearch与Hadoop是如何互相调用的?
- 大数据Hadoop(二十四):MapReduce高阶训练
- 大数据Hadoop(六):全网最详细的Hadoop集群搭建
- Hadoop-Impala学习笔记之入门
- hadoop中NameNode、DataNode和Client三者之间协作关系及通信方式介绍
- hadoop分布式计算,集群
- Hadoop-2.7.0 HDFS DataXceiverServer两个参数的疑问
- Hadoop Common源码分析之SerializationFactory、Serialization