
惊天秘密!从Thread开始,揭露Android线程通讯的诡计和主线程的阴谋
背景介绍
我们在Android开发过程中,几乎都离不开线程。但是你对线程的了解有多少呢?它完美运行的背后,究竟隐藏了多少不为人知的秘密呢?线程间互通暗语,传递信息究竟是如何做到的呢?Looper、Handler、MessageQueue究竟在这背后进行了怎样的运作。本期,让我们一起从Thread开始,逐步探寻这个完美的线程链背后的秘密。
注意,大部分分析在代码中,所以请仔细关注代码哦!
从Tread的创建流程开始
在这一个环节,我们将一起一步步的分析Thread的创建流程。
话不多说,直接代码里看。
线程创建的起始点init()
// 创建Thread的公有构造函数,都调用的都是这个私有的init()方法。我们看看到底干什么了。 * * @param 线程组 * @param 就是我们平时接触最多的Runnable同学 * @param 指定线程的名称 * @param 指定线程堆栈的大小 */ private void init(ThreadGroup g, Runnable target, String name, long stackSize) { Thread parent = currentThread(); //先获取当前运行中的线程。这一个Native函数,暂时不用理会它怎么做到的。黑盒思想,哈哈! if (g == null) { g = parent.getThreadGroup(); //如果没有指定ThreadGroup,将获取父线程的TreadGroup } g.addUnstarted(); //将ThreadGroup中的就绪线程计数器增加一。注意,此时线程还并没有被真正加入到ThreadGroup中。 this.group = g; //将Thread实例的group赋值。从这里开始线程就拥有ThreadGroup了。 this.target = target; //给Thread实例设置Runnable。以后start()的时候执行的就是它了。 this.priority = parent.getPriority(); //设置线程的优先权重为父线程的权重 this.daemon = parent.isDaemon(); //根据父线程是否是守护线程来确定Thread实例是否是守护线程。 setName(name); //设置线程的名称 init2(parent); //纳尼?又一个初始化,参数还是父线程。不急,稍后在看。 /* Stash the specified stack size in case the VM cares */ this.stackSize = stackSize; //设置线程的堆栈大小 tid = nextThreadID(); //线程的id。这是个静态变量,调用这个方法会自增,然后作为线程的id。 }
第二个init2()

至此,我们的Thread就初始化完成了,Thread的几个重要成员变量都赋值了。
启动线程,开车啦!
通常,我们这样了启动一条线程。
Thread threadDemo = new Thread(() - { }); threadDemo.start();
那么start()背后究竟隐藏着什么样不可告人的秘密呢?是人性的扭曲?还是道德的沦丧?让我们一起点进start()。探寻start()背后的秘密。
//如我们所见,这个方法是加了锁的。原因是避免开发者在其它线程调用同一个Thread实例的这个方法,从而尽量避免抛出异常。 //这个方法之所以能够执行我们传入的Runnable里的run()方法,是应为JVM调用了Thread实例的run()方法。 public synchronized void start() { //检查线程状态是否为0,为0表示是一个新状态,即还没被start()过。不为0就抛出异常。 //就是说,我们一个Thread实例,我们只能调用一次start()方法。 if (threadStatus != 0) throw new IllegalThreadStateException(); //从这里开始才真正的线程加入到ThreadGroup组里。再重复一次,前面只是把nUnstartedThreads这个计数器进行了增量,并没有添加线程。 //同时,当线程启动了之后,nUnstartedThreads计数器会-1。因为就绪状态的线程少了一条啊! group.add(this); started = false; try { nativeCreate(this, stackSize, daemon); //又是个Native方法。这里交由JVM处理,会调用Thread实例的run()方法。 started = true; } finally { try { if (!started) { group.threadStartFailed(this); //如果没有被启动成功,Thread将会被移除ThreadGroup,同时,nUnstartedThreads计数器又增量1了。 } } catch (Throwable ignore) { } } }
好吧,最精华的函数是native的,先当黑盒处理吧。只要知道它能够调用到Thread实例的run()方法就行了。那我们再看看run()方法到底干了什么神奇的事呢?

黑实验
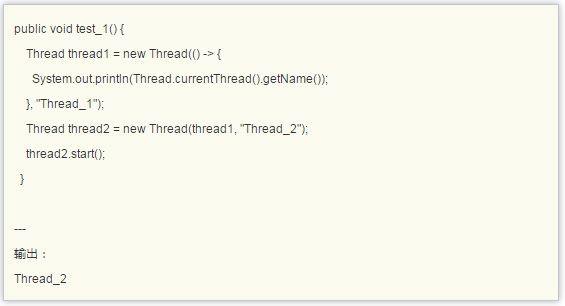
上面的实验表明了,我们完全可以用Thread来作为Runnable。
几个常见的线程手段(操作)
Thread.sleep()那不可告人的秘密
我们平时使用Thread.sleep()的频率也比较高,所以我们在一起研究研究Thread.sleep()被调用的时候发生了什么。
在开始之前,先介绍一个概念——纳秒。1纳秒=十亿分之一秒。可见用它计时将会非常的精准。但是由于设备限制,这个值有时候并不是那么准确,但还是比毫秒的控制粒度小很多。
//平时我们调用的Thread.sleep(long)最后调用到这个方法来,后一个陌生一点的参数就是纳秒。 //你可以在纳秒级控制线程。 public static void sleep(long millis, int nanos) throws InterruptedException { //下面三个检测毫秒和纳秒的设置是否合法。 if (millis 0) { throw new IllegalArgumentException("millis 0: " + millis); } if (nanos 0) { throw new IllegalArgumentException("nanos 0: " + nanos); } if (nanos 999999) { throw new IllegalArgumentException("nanos 999999: " + nanos); } if (millis == 0 nanos == 0) { if (Thread.interrupted()) { //当睡眠时间为0时,检测线程是否中断,并清除线程的中断状态标记。这是个Native的方法。 throw new InterruptedException(); //如果线程被设置了中断状态为true了(调用Thread.interrupt())。那么他将抛出异常。如果在catch住这个异常之后return线程,那么线程就停止了。 //需要注意,在调用了Thread.sleep()之后,再调用isInterrupted()得到的结果永远是False。别忘了Thread.interrupted()在检测的同时还会清除标记位置哦! } return; } long start = System.nanoTime(); //类似System.currentTimeMillis()。但是获取的是纳秒,可能不准。 long duration = (millis * NANOS_PER_MILLI) + nanos; Object lock = currentThread().lock; //获得当前线程的锁。 synchronized (lock) { //对当前线程的锁对象进行同步操作 while (true) { sleep(lock, millis, nanos); //这里又是一个Native的方法,并且也会抛出InterruptedException异常。 //据我估计,调用这个函数睡眠的时长是不确定的。 long now = System.nanoTime(); long elapsed = now - start; //计算线程睡了多久了 if (elapsed = duration) { //如果当前睡眠时长,已经满足我们的需求,就退出循环,睡眠结束。 break; } duration -= elapsed; //减去已经睡眠的时间,重新计算需要睡眠的时长。 start = now; millis = duration / NANOS_PER_MILLI; //重新计算毫秒部分 nanos = (int) (duration % NANOS_PER_MILLI); //重新计算微秒部分 } } }
通过上面的分析可以知道,使线程休眠的核心方法就是一个Native函数sleep(lock, millis, nanos),并且它休眠的时常是不确定的。因此,Thread.sleep()方法使用了一个循环,每次检查休眠时长是否满足需求。
同时,需要注意一点,如果线程的interruted状态在调用sleep()方法时被设置为true,那么在开始休眠循环前会抛出InterruptedException异常。
Thread.yield()究竟隐藏了什么?
这个方法是Native的。调用这个方法可以提示cpu,当前线程将放弃目前cpu的使用权,和其它线程重新一起争夺新的cpu使用权限。当前线程可能再次获得执行,也可能没获得。就酱。
无处不在的wait()究竟是什么?
大家一定经常见到,不论是哪一个对象的实例,都会在最下面出现几个名为wait()的方法。等待?它们究竟是怎样的一种存在,让我们一起点击去看看。
哎哟我去,都是Native函数啊。

那就看看文档它到底是什么吧。
根据文档的描述,wait()配合notify()和notifyAll()能够实现线程间通讯,即同步。在线程中调用wait()必须在同步代码块中调用,否则会抛出IllegalMonitorStateException异常。因为wait()函数需要释放相应对象的锁。当线程执行到wait()时,对象会把当前线程放入自己的线程池中,并且释放锁,然后阻塞在这个地方。直到该对象调用了notify()或者notifyAll()后,该线程才能重新获得,或者有可能获得对象的锁,然后继续执行后面的语句。
呃。。。好吧,在说明一下notify()和notifyAll()的区别。
notify()调用notify()后,对象会从自己的线程池中(也就是对该对象调用了wait()函数的线程)随机挑选一条线程去唤醒它。也就是一次只能唤醒一条线程。如果在多线程情况下,只调用一次notify(),那么只有一条线程能被唤醒,其它线程会一直在
notifyAll()调用notifyAll()后,对象会唤醒自己的线程池中的所有线程,然后这些线程就会一起抢夺对象的锁。
扒一扒Looper、Handler、MessageQueue之间的爱恨情仇
我们可能过去都写过形如这样的代码:

很多同学知道,在线程中使用Handler时(除了Android主线程)必须把它放在Looper.prepare()和Looper.loop()之间。否则会抛出RuntimeException异常。但是为什么要这么做呢?下面我们一起来扒一扒这其中的内幕。

从Looper.prepare()开始
当Looper.prepare()被调用时,发生了什么?

经过上面的分析,我们已经知道Looper.prepare()调用之后发生了什么。
但是问题来了!sThreadLocal是个静态的ThreadLocal 实例(在Android中ThreadLocal的范型固定为Looper)。就是说,当前进程中的所有线程都共享这一个ThreadLocal。那么,Looper.prepare()既然是个静态方法,Looper是如何确定现在应该和哪一个线程建立绑定关系的呢?我们接着往里扒。
来看看ThreadLocal的get()、set()方法。

创建Handler
Handler可以用来实现线程间的通行。在Android中我们在子线程作完数据处理工作时,就常常需要通过Handler来通知主线程更新UI。平时我们都使用new Handler()来在一个线程中创建Handler实例,但是它是如何知道自己应该处理那个线程的任务呢。下面就一起扒一扒Handler。
public Handler() { this(null, false); public Handler(Callback callback, boolean async) { //可以看到,最终调用了这个方法。 if (FIND_POTENTIAL_LEAKS) { final Class ? extends Handler klass = getClass(); if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) (klass.getModifiers() Modifier.STATIC) == 0) { Log.w(TAG, "The following Handler class should be static or leaks might occur: " + klass.getCanonicalName()); } } mLooper = Looper.myLooper(); //重点啊!在这里Handler和当前Thread的Looper绑定了。Looper.myLooper()就是从ThreadLocale中取出当前线程的Looper。 if (mLooper == null) { //如果子线程中new Handler()之前没有调用Looper.prepare(),那么当前线程的Looper就还没创建。就会抛出这个异常。 throw new RuntimeException( "Cant create handler inside thread that has not called Looper.prepare()"); } mQueue = mLooper.mQueue; //赋值Looper的MessageQueue给Handler。 mCallback = callback; mAsynchronous = async; }
Looper.loop()
我们都知道,在Handler创建之后,还需要调用一下Looper.loop(),不然发送消息到Handler没有用!接下来,扒一扒Looper究竟有什么样的魔力,能够把消息准确的送到Handler中处理。
public static void loop() { final Looper me = myLooper(); //这个方法前面已经提到过了,就是获取到当前线程中的Looper对象。 if (me == null) { //没有Looper.prepare()是要报错的! throw new RuntimeException("No Looper; Looper.prepare() wasnt called on this thread."); } final MessageQueue queue = me.mQueue; //获取到Looper的MessageQueue成员变量,这是在Looper创建的时候new的。 //这是个Native方法,作用就是检测一下当前线程是否属于当前进程。并且会持续跟踪其真实的身份。 //在IPC机制中,这个方法用来清除IPCThreadState的pid和uid信息。并且返回一个身份,便于使用restoreCallingIdentity()来恢复。 Binder.clearCallingIdentity(); final long ident = Binder.clearCallingIdentity(); for (;;) { //重点(敲黑板)!这里是个死循环,一直等待抽取消息、发送消息。 Message msg = queue.next(); // 从MessageQueue中抽取一条消息。至于怎么取的,我们稍后再看。 if (msg == null) { // No message indicates that the message queue is quitting. return; } // This must be in a local variable, in case a UI event sets the logger final Printer logging = me.mLogging; if (logging != null) { logging.println(" Dispatching to " + msg.target + " " + msg.callback + ": " + msg.what); } final long traceTag = me.mTraceTag; //取得MessageQueue的跟踪标记 if (traceTag != 0) { Trace.traceBegin(traceTag, msg.target.getTraceName(msg)); //开始跟踪本线程的MessageQueue中的当前消息,是Native的方法。 } try { msg.target.dispatchMessage(msg); //尝试分派消息到和Message绑定的Handler中 } finally { if (traceTag != 0) { Trace.traceEnd(traceTag); //这个和Trace.traceBegin()配套使用。 } } if (logging != null) { logging.println(" Finished to " + msg.target + " " + msg.callback); } final long newIdent = Binder.clearCallingIdentity(); //what?又调用这个Native方法了。这里主要是为了再次验证,线程所在的进程是否发生改变。 if (ident != newIdent) { Log.wtf(TAG, "Thread identity changed from 0x" + Long.toHexString(ident) + " to 0x" + Long.toHexString(newIdent) + " while dispatching to " + msg.target.getClass().getName() + " " + msg.callback + " what=" + msg.what); } msg.recycleUnchecked(); //回收释放消息。 } }
从上面的分析可以知道,当调用了Looper.loop()之后,线程就就会被一个for(;;)死循环阻塞,每次等待MessageQueue的next()方法取出一条Message才开始往下继续执行。然后通过Message获取到相应的Handler (就是target成员变量),Handler再通过dispatchMessage()方法,把Message派发到handleMessage()中处理。
这里需要注意,当线程loop起来是时,线程就一直在循环中。就是说Looper.loop()后面的代码就不能被执行了。想要执行,需要先退出loop。
Looper myLooper = Looper.myLoop(); myLooper.quit(); //普通退出方式。 myLooper.quitSafely(); //安全的退出方式。
现在又产生一个疑问,MessageQueue的next()方法是如何阻塞住线程的呢?接下来,扒一扒这个幕后黑手MessageQueue。
幕后黑手MessageQueue
MessageQueue是一个用单链的数据结构来维护消息列表。

可以看到。MessageQueue在取消息(调用next())时,会进入一个死循环,直到取出一条Message返回。这就是为什么Looper.loop()会在queue.next()处等待的原因。
那么,一条Message是如何添加到MessageQueue中呢?要弄明白最后的真相,我们需要调查一下mHandler.post()这个方法。
Handler究竟对Message做了什么?
Handler的post()系列方法,最终调用的都是下面这个方法:
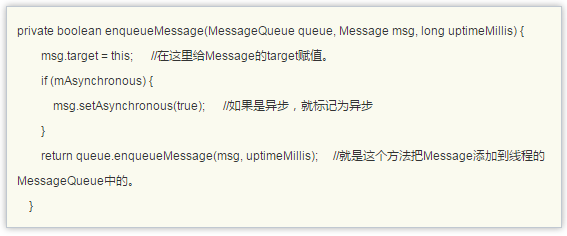
接下来就看看MessageQueue的enqueueMessage()作了什么。

至此,我们已经揭露了Looper、Handler、MessageQueue隐藏的秘密。
另一个疑问?
也许你已经注意到在主线程中可以直接使用Handler,而不需要Looper.prepare()和Looper.loop()。为什么可以做到这样呢?根据之前的分析可以知道,主线程中必然存在Looper.prepare()和Looper.loop()。既然如此,为什么主线程没有被loop()阻塞呢?看一下ActivityThread来弄清楚到底是怎么回事。

注意ActivityThread并没有继承Thread,它的Handler是继承Handler的私有内部类H.class。在H.class的handleMessage()中,它接受并执行主线程中的各种生命周期状态消息。UI的16ms的绘制也是通过Handler来实现的。也就是说,主线程中的所有操作都是在Looper.prepareMainLooper()和Looper.loop()之间进行的。进一步说是在主Handler中进行的。
总结
Android中Thread在创建时进行初始化,会使用当前线程作为父线程,并继承它的一些配置。 Thread初始化时会被添加到指定/父线程的ThreadGroup中进行管理。 Thread正真启动是一个native函数完成的。 在Android的线程间通信中,需要先创建Looper,就是调用Looper.prepare()。这个过程中会自动依赖当前Thread,并且创建MessageQueue。经过上一步,就可以创建Handler了,默认情况下,Handler会自动依赖当前线程的Looper,从而依赖相应的MessageQueue,也就知道该把消息放在哪个地方了。MessageQueue通过Message.next实现了一个单链表结构来缓存Message。消息需要送达Handler处理,还必须调用Looper.loop()启动线程的消息泵送循环。loop()内部是无限循环,阻塞在MessageQueue的next()方法上,因为next()方法内部也是一个无限循环,直到成功从链表中抽取一条消息返回为止。然后,在loop()方法中继续进行处理,主要就是把消息派送到目标Handler中。接着进入下一次循环,等待下一条消息。由于这个机制,线程就相当于阻塞在loop()这了。经过上面的揭露,我们已经对线程及其相互之间通讯的秘密有所了解。掌握了这些以后,相信在以后的开发过程中我们可以思路清晰的进行线程的使用,并且能够吸收Android在设计过程中的精华思想。
本文作者:佚名 来源:51CTOAndroid 组件化(二)注解与注解处理器、组件通讯 在上一篇文章中,我们完成了组件的创建、gradle统一管理、组件模式管理和切换,那么这一篇文章,我们需要做的就是组件之间的通讯了。
相关文章
- Android多线程研究(1)——线程基础及源代码剖析
- Android在未root手机获取应用内置的SQLite数据库到电脑上处理的方法(数据库备份与恢复-支持SDK30+)
- Android入门之login设计
- Android基础之使用Fragment控制切换多个页面
- android反编译
- Android子线程更新UI的方法总结
- Android+Jquery Mobile学习系列(4)-页面跳转及参数传递
- Android Studio系列教程一--下载与安装
- android vector pathData探究,几分钟绘制自己的vectordrawable
- android开发 drawtext的开始坐标位置
- android退出登陆后,清空之前所有的activity,进入登陆主界面
- debian sid 安装android studio
- android学习-进程/线程管理-完整
- android样式跟主题
- flutter制作博客展示平台,现已支持 Web、macOS 应用、Android 和 iOS
- android 在非UI线程更新UI仍然成功原因深入剖析
- Android学习之子线程更新UI的方法
- Android学习之线程如何多次实现start
- android历史
- android 通过子线程跳转activity并传递内容
- Android 百度地图开发(一)--- 申请API Key和在项目中显示百度地图
- 【Android】学习日记一 初识Activity
- 跑ios自动化,新建线程执行android自动化