
Sqoop集群环境搭建 | MySQL数据导出HDFS测试
🚀 作者 :“大数据小禅”
🚀 简介:详细讲解Sqoop的环境搭建,通过Sqoop将mysql导出到HDFS,附带过程截图。
🚀 安装包获取:获取对应的安装包可以通过最下方公众号联系我备注获取。
1.Sqoop简介
Apache Sqoop是在Hadoop生态体系和*RDBMS体系之间传送数据的一种工具。来自于Apache软件基金会提供。,主要用于在Hadoop(Hive)与传统的数据库间进行数据的传递,可以将一个关系型数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop工作机制是将导入或导出命令翻译成mapreduce程序来实现。在翻译出的mapreduce中主要是对inputformat和outputformat进行定制。
Hadoop生态系统包括:HDFS、Hive、Hbase等
RDBMS体系包括:Mysql、Oracle等关系型数据库
Sqoop可以理解为:“SQL 到 Hadoop 和 Hadoop 到SQL”
2.Sqoop安装
1.sqoop安装包解压
对应安装包可以私聊获取,在主节点node1上进行安装。
#解压
tar -xf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /app
#修改安装包名字
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop-1.4.6
2.修改配置文件
Sqoop的运行依赖于Hadoop,导入Hive的环境变量是因为MySQL导入到Hive需要用到Hive依赖。具体搭建流程可以再环境搭建专栏进行查看。
ZK的环境变量可以用于将数据导入到HBase。这个根据个人情况进行配置。
vim /app/sqoop-1.4.6/sqoop-env.sh
#增加如下内容
export HADOOP_COMMON_HOME=/app/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/app/hadoop-3.1.3
export HIVE_HOME=/app/hive
export ZOOKEEPER_HOME=/app/zookeeper-3.5.7
export ZOOCFGDIR=/app/zookeeper-3.5.7/conf
3.添加JDBC驱动
#将mysql-connector-java-5.1.48.jar上传到sqoop的lib的目录
cp mysql-connector-java-5.1.48.jar /app/sqoop-1.4.6/lib
3.Sqoop运行测试
#使用bin/sqoop help 可以看到一些提示命令
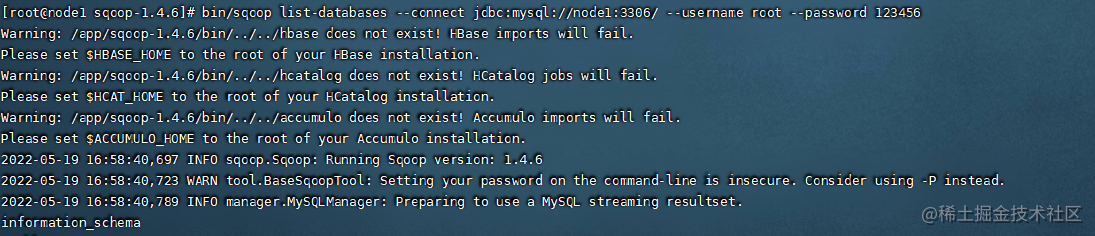
#测试Sqoop是否可以连接到数据库运行如下命令,注意你机器的数据库密码与端口根据情况修改。可以看到如下的数据库信息输出
bin/sqoop list-databases --connect jdbc:mysql://node1:3306/ --username root --password 123456
4.MySQL数据导出到HDFS
在mysql建立个表,两个字段id 与name 用于测试
mysql> insert into mysql_hdfs values(1,"test");
Query OK, 1 row affected (0.00 sec)
mysql> insert into mysql_hdfs values(2,"tes2");
Query OK, 1 row affected (0.00 sec)
mysql> insert into mysql_hdfs values(3,"te3s");
Query OK, 1 row affected (0.00 sec)
#运行如下的命令导出数据到HDFS
#前三个字段用于配置基本的连接信息
参数解释:
--table:mysql的表
--columns:导出的列
--target-dir:到HDFS的目标路径
--split-by:指的是map端的切片操作,按照id进行切片
--fields-terminated-by '\t':mysql中的是结构化数据,导入HDFS指定分隔符
bin/sqoop import \
--connect jdbc:mysql://node1:3306/test \
--username root \
--password 123456 \
--table mysql_hdfs \
--columns id,name \
--target-dir /sql_hdfs \
--delete-target-dir \
--fields-terminated-by '\t' \
--num-mappers 2 \
--split-by id
这里解释一下 --split-by的分片规则
切片规则:假如说id的最大值为20,最小值是1,那么切片的时候就会分成两份1-10,10-20,之后每个部分一个map。
运行上面的命令后可以在HDFS对应的路径查看生成的内容。
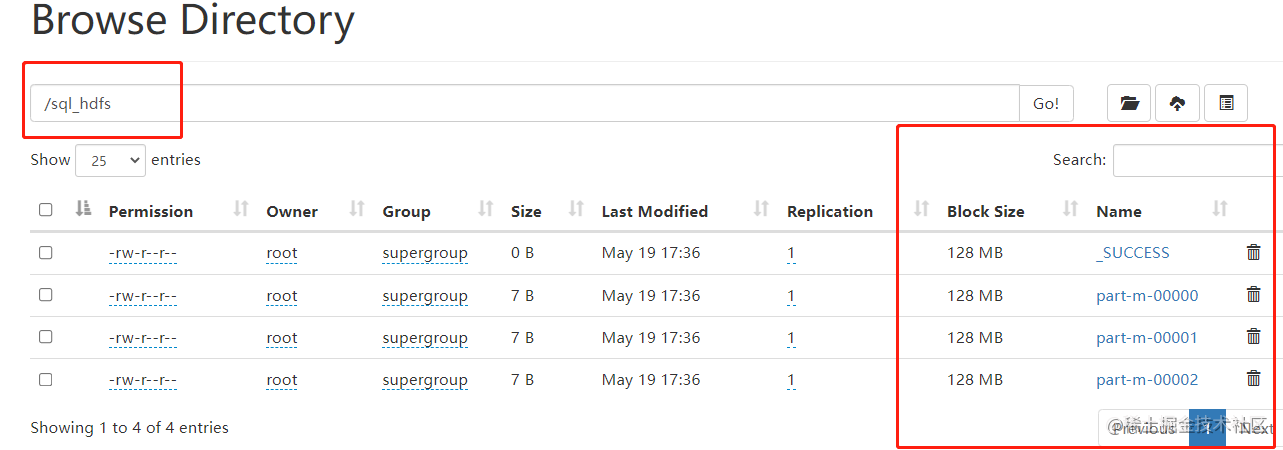
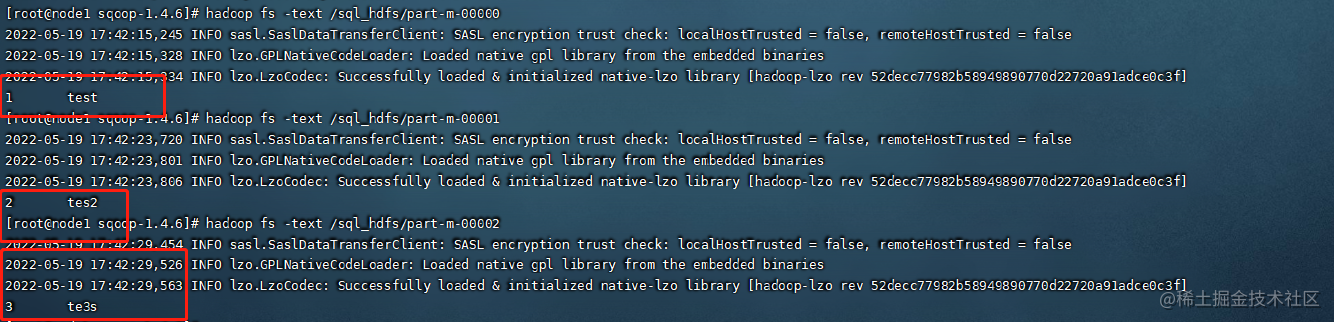
到这里sqoop的正常使用测试完成
欢迎小伙伴们 点赞👍、收藏⭐、留言💬
👇🏻 关注公众号: 大数据小禅👇🏻,获取对应安装包与资料
相关文章
- MySQL数据库使用mysqldump导出数据详解
- mysql binary like_MYSQL的binary解决mysql数据大小写敏感问题的方法
- Sqoop2 将hdfs中的数据导出到MySQL
- Sqoop-将Hive ORC表导出到MySQL(全量、更新)
- 使用 sqoop 将 hive 数据导出到 mysql (export)
- Linux安装Mysql
- C#中缓存的使用 ajax请求基于restFul的WebApi(post、get、delete、put) 让 .NET 更方便的导入导出 Excel .net core api +swagger(一个简单的入门demo 使用codefirst+mysql) C# 位运算详解 c# 交错数组 c# 数组协变 C# 添加Excel表单控件(Form Controls) C#串口通信程序
- [转]mysql如何利用Navicat 导出和导入数据库
- Php Mysql
- MySQL导出数据文件
- 安装Mysql中报的错
- MySQL命令行导出数据库(sql脚本)
- MySQL数据库导入、导出、复制表、重命名表
- mysql数据导出为excel文件
- mysql load data, select into outfile 导入和导出 CSV格式
- 《MySQL高效编程》一一1.4 SQL语言
- MySQL锁系列(一)之锁的种类和概念
- 利用phpstudy导入mysql文件
- 基于php和mysql实现(Web)学生课外活动成果统计系统【100010274】
- 基于Java+Mysql实现(WEB)宿舍管理系统【100010016】
- mysql使用Navicat 导出和导入数据库
- ubuntu16.04x64环境下 tar方式 安装mysql-5.7.21 试水过程记录
- Django+Bootstrap+Mysql 搭建个人博客(五)
- MySQL数据库使用mysqldump导出数据详解
- mysql 导入导出sql文件
- java从mysql导出数据例子
- 利用Java进行MySql数据库的导入和导出
- (1.9)SQL优化——mysql导入导出优化
- mysql导入导出数据
- 解决MySQL Workbench导出乱码问题
- mysql数据库表结构导出
- MySQL 教程(基础篇)第06话:MySQL 常用 SQL 语句大全——DDL、DML 和 DCL 详解
- MySQL SQLyog导入一个sql脚本