
从主成分分析到发育网络的核心算法CCIPCA-CCILCA
在写《特征学习:学习之海中的遗珠》过程中,发现内容太多,已经超过单篇博客的承载能力,另外里面几个内容都有各自己额外的主题。因此,本人将《特征学习:学习之海中的遗珠》第二节(介绍几个经典的特征学习方法)中能够独立成篇的3个小节单独提出形成三篇对应的博客。本篇对应第1小节:从主成分分析到发育网络的核心算法。
文章目录
1.写在前面
PCA可以用来解决的问题【Andrew Ng曾在讲PCA时提到过】:
1)减少数据因为存储而造成的内存和硬盘的占用;
2)加速训练过程;
3)高维数据可视化。
值得注意的是: PCA
并没有把握一定能提高后续机器学习任务的效果,也没有把握能够防止过拟合问题。
主成分分析(Principal Component Analysis,简称PCA) 提供了一种用低维数据来表示高维复杂数据最主要特征的途径。PCA的思想是将 m m m维特征映射到 k k k维空间上 k < m k<m k<m,这 k k k维特征是全新的正交特征,最新构造出来的 k k k维特征,而不是简单地从 m m m维特征中去除其余 m − k m-k m−k维特征。博客主成分分析|PCA算法大全罗列了大部分现有的PCA类算法,包括:针对 非线性数据的KPCA,针对二维图片数据的2DPCA/2D2DPCA以及BDPCA等。此处只介绍原始PCA算法以及它的一个增量式版本——CCIPCA,然后介绍翁巨扬教授提出的发育网络(Developmental Network,简称DN) 中的核心算法增量式叶成分分析(CCILCA)。各部分都可展开成原理、算法推导、示例代码、结果分析四个部分。
本文并非单纯为了罗列方法,驱动我总结这篇博客的原因是主成分分析与发育网络的关系。CCILCA作为发育网络的核心算法,根据新到来的数据对网络的节点进行更新,其中每个节点的更新算法就是一个CCIPCA。也就是说发育网络的核心原理之一竟然是主成分分析(另外一个是赫布学习理论)。CCIPCA与CCILCA的关系会在第四部分进行时详细介绍。
2. 主成分分析(PCA)算法与应用
2.1 原理
PCA可以被定义为数据在低维线性空间上的正交投影,这个线性空间被称为主子空间(principal subspace),使得投影数据的方差被最大化(Hotelling, 1933),即最大方差理论。等价地,它也可以被定义为使得平均投影代价最小的线性投影,即最小误差理论。平均投影代价是指数据点和它们的投影之间的平均平方距离(Pearson, 1901)。从最大方差理论与最小误差理论来推导PCA,最终的结果是一样的。对于数据集 X = { x 1 , x 2 , . . . x n } \mathbf{X}=\{\mathbf{x}_1, \mathbf{x}_2, ...\mathbf{x}_n\} X={x1,x2,...xn},我们以最大方差理论为例来推导PCA:
在信号处理中,认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。因此我们认为,最好的k维特征是将m维样本点变换为k后,每一维上的样本方差都尽可能的大。
2.2 算法推导
首先,考虑在一维空间 ( k = 1 ) (k=1) (k=1)上的投影。我们可以使用 m m m维向量 w \mathbf{w} w定义这个空间的方向。为了方便并不失一般性,我们假定选择一个单位向量,从而 w T w = 1 \mathbf{w}^T \mathbf{w}=1 wTw=1。

(假设数据是零均值化后的)
如上图所示,红色点表示原样本点 u ( i ) \mathbf{u}^{(i)} u(i), w \mathbf{w} w是蓝色直线的斜率也是直线的方向向量,而且是单位向量,直线上蓝色点表示原样本点 u ( i ) \mathbf{u}^{(i)} u(i)在 w \mathbf{w} w上的投影。容易知道投影点离原点的距离是 u ( i ) T w \mathbf{u}^{(i)T} \mathbf{w} u(i)Tw,由于这些原始样本点的每一维特征均值都为0,因此投影到 w \mathbf{w} w上的样本点的均值仍然是0。
假设原始数据集为 X ∈ R m × n \mathbf{X}\in \mathbb{R}^{m\times n} X∈Rm×n,我们的目标是找到最佳的投影空间 W = [ w 1 , w 2 , . . . , w k ] ∈ R n × k \mathbf{W}=[\mathbf{w}_1, \mathbf{w}_2, ..., \mathbf{w}_k]\in \mathbb{R}^{n\times k} W=[w1,w2,...,wk]∈Rn×k,其中 w i \mathbf{w}_i wi是单位向量且 w i \mathbf{w}_i wi是单位向量且 w i \mathbf{w}_i wi与 w j ( i ≠ j ) \mathbf{w}_j(i\neq j) wj(i=j)正交,何为最佳的 W \mathbf{W} W?就是原始样本点投影到 W W W上之后,使得投影后的样本点方差最大。
我们先将原始数据集 X \mathbf{X} X零均值化为 U = { u 1 , u 2 , . . . , u n } \mathbf{U}=\{\mathbf{u_1}, \mathbf{u_2}, ..., \mathbf{u_n}\} U={u1,u2,...,un},其中, u i = x i − ∑ j = 1 n x j \mathbf{u_i}=\mathbf{x_i}-\sum_{j=1}^{n} \mathbf{x_j} ui=xi−∑j=1nxj。
由于投影后均值为
0
\mathbf{0}
0,因此数据集
U
\mathbf{U}
U沿某一单位向量
w
\mathbf{w}
w投影后的总方差为:
1
n
∑
i
=
1
n
(
u
i
T
w
)
2
=
1
n
∑
i
=
1
n
w
T
u
i
u
i
T
w
=
w
T
[
1
n
∑
i
=
1
n
u
i
u
i
T
]
w
\frac{1}{n}\sum_{i=1}^n (\mathbf{u}_i^{T}\mathbf{w})^2=\frac{1}{n}\sum_{i=1}^n \mathbf{w}^T\mathbf{u}_i \mathbf{u}_i^{T}\mathbf{w}= \mathbf{w}^T \left[\frac{1}{n}\sum_{i=1}^n \mathbf{u}_i \mathbf{u}_i^{T}\right]\mathbf{w}
n1i=1∑n(uiTw)2=n1i=1∑nwTuiuiTw=wT[n1i=1∑nuiuiT]w
其中 1 n ∑ i = 1 n u i u i T = 1 n ∑ i = 1 n ( x i − ∑ j = 1 n x j ) ( x i − ∑ j = 1 n x j ) T \frac{1}{n}\sum_{i=1}^n \mathbf{u}_i \mathbf{u}_i^{T}=\frac{1}{n}\sum_{i=1}^n (\mathbf{x}_i -\sum_{j=1}^{n}\mathbf{x}_j)(\mathbf{x}_i -\sum_{j=1}^{n}\mathbf{x}_j)^T n1∑i=1nuiuiT=n1∑i=1n(xi−∑j=1nxj)(xi−∑j=1nxj)T就是原始数据集 X \mathbf{X} X的协方差矩阵(因为无偏估计的原因,一般协方差矩阵除以 n − 1 n-1 n−1,这是用 n n n)。
λ
=
w
T
Σ
w
\lambda=\mathbf{w}^T\mathbf{\Sigma} \mathbf{w}
λ=wTΣw
其中,
λ
=
1
n
∑
i
=
1
n
(
x
i
T
w
)
2
,
Σ
=
1
n
∑
i
=
1
n
x
i
x
i
T
\lambda=\frac{1}{n}\sum_{i=1}^n (\mathbf{x}_i^{T}\mathbf{w})^2,\mathbf{\Sigma}=\frac{1}{n} \sum_{i=1}^{n} \mathbf{x}_i \mathbf{x}_i^{T}
λ=n1∑i=1n(xiTw)2,Σ=n1∑i=1nxixiT。
上式两边同时左乘 w \mathbf{w} w,注意到 w w T = 1 \mathbf{w}\mathbf{w}^T=1 wwT=1(单位向量),则有
λ
w
=
Σ
w
\lambda \mathbf{w}=\mathbf{\Sigma} \mathbf{w}
λw=Σw
所以
w
\mathbf{w}
w是矩阵
Σ
\mathbf{\Sigma}
Σ的特征值所对应的特征向量。
欲使投影后的总方差最大,即 λ \lambda λ最大, 可知最佳的投影向量 w w w是特征值 λ \lambda λ最大时对应的特征向量,因此,当我们将 w w w设置为与具有最大的特征值向量相等时,方差会达到最大值。这个特征向量被称为第一主成分。
PCA算法如下图所示:

2.3 示例程序
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits #8x8的手写数字数据
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import time
X, y = load_digits(return_X_y=True)
print('X shape:', X.shape) # 此处会看到X是64维的数据
X_train, x_test, y_train, y_test = train_test_split(X, y)
tic = time.time()
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_train)
print (knn_clf.score(x_test, y_test))
toc = time.time()
print ('Time of method[exec_without_pca] costs:'+str(toc-tic))
print ('----' * 10)
tic = time.time()
knn_clf = KNeighborsClassifier()
pca = PCA(n_components=0.95) # 重构阈值为95%
pca.fit(X_train, y_train)
X_train_dunction = pca.transform(X_train)
X_test_dunction = pca.transform(x_test)
knn_clf.fit(X_train_dunction, y_train)
print (knn_clf.score(X_test_dunction, y_test))
toc = time.time()
print ('Time of method[exec_with_pca] costs:'+str(toc-tic))
import matplotlib.pyplot as plt
%matplotlib inline
def draw_graph():
pca = PCA(n_components=2)
pca.fit(X)
X_reduction = pca.transform(X)
for i in range(10):
plt.scatter(X_reduction[y==i,0], X_reduction[y==i,1], alpha=0.8, label='%s' % i)
plt.legend()
plt.show()
输出:

降维数据可视化结果:’

其它数据显示:
经过PCA降维后,发现降到28维(原始维数为64维)后,就能达到95%数据重构精度。
>>print(len(pca.components_))
28
>>print(pca.explained_variance_ratio_)
[0.14797442 0.13659413 0.11802823 0.08412275 0.05932165 0.05048908
0.04237307 0.0355668 0.0334889 0.03029803 0.02443289 0.02229051
0.01804256 0.01782603 0.01516046 0.01396237 0.013309 0.01217414
0.01043489 0.00897301 0.00880779 0.00771099 0.00760128 0.00726781
0.00689468 0.00609627 0.00579926 0.00505733]
将这前28特征向量打印出来:
A = pca.components_
print(pca.explained_variance_ratio_)
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(12, 8))
for i in range(len(A)):
fig.add_subplot(4, 7, i+1)
plt.title(i+1)
plt.imshow(A[i].reshape((8,8)))
plt.xticks([])
plt.yticks([])
plt.axis("off")
plt.show()

2.4 结果分析
以上示例与结果表明,数据经PCA降维后的准确率没有明显提高。但是经过PCA降维后,用于训练的数据维度变少了,因此计算成本明显降低了。并且,在原始高维空间中揉杂在一起,不可分的数据,利用PCA降维的低维空间中,数据也还是揉杂在一起的。
3 增量式PCA(CCIPCA)算法与应用
candid covariance-free incremental principle component analysis直接协方差无关的增量式主成分分析,简称CCIPCA
考虑到很多实际应用无法一次性收集足够的训练数据,更普遍的情况是:数据是随着时间不断产生的,按序列依次输入到学习系统中。要应对这种情况,算法必需能够具备仅仅依靠已经学到的知识与新接受到的数据进行增量式的学习。明显地,原始PCA算法无法应对这种情况,本节介绍的CCIPCA是对原始PCA的改进,它能够只依赖当前的新数据进行学习降维模型。
3.1 算法推导
上一节根据最大方差理论推导PCA过程中,可得数据集
X
\mathbf{X}
X沿某一单位向量
w
\mathbf{w}
w投影后的总方差
Σ
(
n
)
\mathbf{\Sigma}(n)
Σ(n)为:
Σ
n
=
1
n
∑
i
=
1
n
(
x
i
−
m
n
)
(
x
i
−
m
n
)
T
=
1
n
∑
i
=
1
n
u
i
u
i
T
(1)
\mathbf{\Sigma}_n= \frac{1}{n}\sum_{i=1}^n (\mathbf{x}_i -\mathbf{m}_n)(\mathbf{x}_i -\mathbf{m}_n)^T= \frac{1}{n}\sum_{i=1}^n \mathbf{u}_i \mathbf{u}_i^T \tag{1}
Σn=n1i=1∑n(xi−mn)(xi−mn)T=n1i=1∑nuiuiT(1)
其中 m n = 1 n ∑ i = 1 n x i \mathbf{m}_n=\frac{1}{n}\sum_{i=1}^n \mathbf{x}_i mn=n1∑i=1nxi就是原始数据集 X \mathbf{X} X的协方差矩阵(因为 x i \mathbf{x}_i xi的均值为 0 \mathbf{0} 0,因为无偏估计的原因,一般协方差矩阵除以 n − 1 n-1 n−1,这是用n)。
第 i i i个特征值和特征向量的计算公式为 λ i n w i n = Σ n w i n \lambda_{in} \mathbf{w}_{in}=\mathbf{\Sigma}_n \mathbf{w}_{in} λinwin=Σnwin,其中 w i n \mathbf{w}_{in} win为第 n n n输入时待求的第 i i i个特征向量, λ i n \lambda_{in} λin为对应的特征值 。CCIPCA算法为了加快迭代的速度,整个迭代是对特征值和特征向量的乘积 λ i n w i n \lambda_{in} \mathbf{w}_{in} λinwin进行的,设第 n n n个输入时有
v i n = λ i n w i n = Σ n w i n (2) \mathbf{v}_{in}=\lambda_{in} \mathbf{w}_{in}=\mathbf{\Sigma}_n \mathbf{w}_{in} \tag{2} vin=λinwin=Σnwin(2)
把(1)式代入(2)式,可得
v
i
n
=
1
n
∑
j
=
1
n
u
j
u
j
T
w
i
n
(3)
\mathbf{v}_{in}=\frac{1}{n}\sum_{j=1}^n \mathbf{u}_j \mathbf{u}_j^T \mathbf{w}_{in}\tag{3}
vin=n1j=1∑nujujTwin(3)
若通过迭代获得特征值和特征向量的乘积 v i n \mathbf{v}_{in} vin,因特征向量是归一的,只要对(2)式求模(内积,开根),可求得 λ i n = ∣ ∣ v i n ∣ ∣ , w i n = v i n ∣ ∣ v i n ∣ ∣ \lambda_{in}=||\mathbf{v}_{in}||,\mathbf{w}_{in}=\frac{\mathbf{v}_{in}}{||\mathbf{v}_{in}||} λin=∣∣vin∣∣,win=∣∣vin∣∣vin。
迭代采用(3)式,把 v i , n − 1 ∣ ∣ v i , n − 1 ) ∣ ∣ \frac{\mathbf{v}_{i,n-1}}{||\mathbf{v}_{i,n-1})||} ∣∣vi,n−1)∣∣vi,n−1近似为 w i n \mathbf{w}_{in} win代入(3)式,经变换可得CCIPCA的基本迭代公式:
v i n = n − 1 n v i , n − 1 + 1 n u n u n T v i , n − 1 ∣ ∣ v i , n − 1 ∣ ∣ (4) \mathbf{v}_{in}=\frac{n-1}{n}\mathbf{v}_{i,n-1}+\frac{1}{n}\mathbf{u}_n \mathbf{u}_n^T\frac{\mathbf{v}_{i,n-1}}{||\mathbf{v}_{i,n-1}||} \tag{4} vin=nn−1vi,n−1+n1ununT∣∣vi,n−1∣∣vi,n−1(4)
其中, n − 1 n \frac{n-1}{n} nn−1为上一步的迭代值 v i , n − 1 \mathbf{v}_{i,n-1} vi,n−1的权值,第2项的 1 n \frac{1}{n} n1相当于迭代的调整步长。
u n = x n − m n \mathbf{u}_n=\mathbf{x}_n-\mathbf{m}_n un=xn−mn作为第 n n n个新输入数据对迭代向量 v i n \mathbf{v}_{in} vin的调整,在迭代中 v i n \mathbf{v}_{in} vin逐步收敛到所求的第 i i i个特征向量。
对不同序号的向量 v i \mathbf{v}_i vi,都可以用(4)式迭代,只是输入的向量 u n \mathbf{u}_n un不同。求最大的特征值对应的特征向量时, u n \mathbf{u}_n un为机器人采到的第 n n n个均值化的数据。在求第2,第3乃至更后面的特征向量时,须作以下处理:
已经通过迭代得到第1个特征向量,先设
u
1
n
=
u
n
\mathbf{u}_{1n}=\mathbf{u}_n
u1n=un,并把
u
1
n
\mathbf{u}_{1n}
u1n投影到上一个已经求到的特征向量上(现为第1个特征向量),求出残差数据
u
2
n
\mathbf{u}_{2n}
u2n,如下式表示:
u
2
n
=
u
1
n
−
u
1
n
T
v
1
n
∣
∣
v
1
n
∣
∣
v
1
n
∣
∣
v
1
n
∣
∣
\mathbf{u}_{2n}=\mathbf{u}_{1n}-\mathbf{u}_{1n}^T\frac{\mathbf{v}_{1n}}{||\mathbf{v}_{1n}||}\frac{\mathbf{v}_{1n}}{||\mathbf{v}_{1n}||}
u2n=u1n−u1nT∣∣v1n∣∣v1n∣∣v1n∣∣v1n
u 2 n \mathbf{u}_{2n} u2n作为求第2个特征向量的输入,类似的可求出第3,第4,…个特征向量。因残差数据和上1个特征向量所恢复的数据正交,从而可求出所有相互正交的特征向量。另外,每输入1个新的数据时,均值也要更新,对(1)式,输入第 n n n个数据时的均值 采用如下迭代式, m n = n − 1 n m n − 1 + 1 n u n T \mathbf{m}_n=\frac{n-1}{n}\mathbf{m}_{n-1}+\frac{1}{n}\mathbf{u}^T_n mn=nn−1mn−1+n1unT
注意:最终的特征向量 w i = v i ∣ ∣ v i ∣ ∣ \mathbf{w}_{i}=\frac{\mathbf{v}_{i}}{||\mathbf{v}_{i}||} wi=∣∣vi∣∣vi.
CCIPCA算法如下图所示:

3.2 示例程序
# CCIPCA
import numpy as np
import time
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
X, y = load_digits(return_X_y=True)
k = 28
V = np.zeros((k, 64))
n = 1
mt = 0.1*np.random.randn(64)
tic = time.time()
for j in range(len(X)):
u = X[j]
if n == 1: mt = mt + u
else: mt = float(n-1)*mt/n + u/float(n)
u1 = u-mt
for i in range(min(k, n)):
if (i+1) == n: V[i,:] = u1
else:
V[i,:] = (n-1)*V[i,:]/float(n)+(np.linalg.norm(u1)**2)*V[i,:]/(n*np.linalg.norm(V[i,:]))
u1 = u1 - np.sum(u1*V[i,:].reshape(-1))*V[i,:]/(np.linalg.norm(V[i,:])**2)
n = n+1
toc = time.time()
W = V/np.linalg.norm(V, axis=1, keepdims=True)
X = X-mt
X_train, X_test, y_train, y_test = train_test_split(X, y)
knn_clf = KNeighborsClassifier()
X_train_dunction = np.dot(V, X_train.T).T
X_test_dunction = np.dot(V, X_test.T).T
knn_clf.fit(X_train_dunction, y_train)
print (knn_clf.score(X_test_dunction, y_test))
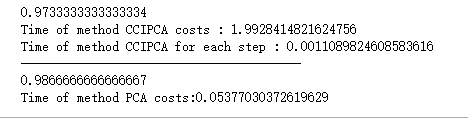
print("Time of method CCIPCA costs : "+str(toc-tic))
print ('----' * 10)
tic = time.time()
knn_clf = KNeighborsClassifier()
pca = PCA(n_components=0.95)
pca.fit(X_train, y_train)
X_train_dunction = pca.transform(X_train)
X_test_dunction = pca.transform(X_test)
knn_clf.fit(X_train_dunction, y_train)
print (knn_clf.score(X_test_dunction, y_test))
toc = time.time()
print ('Time of method PCA costs:'+str(toc-tic))
特征向量可视化:
经过CCIPCA降维后,28个特征向量如下所示。

3.3 结果分析
以上示例与结果表明,增量式PCA(CCIPCA)算法的恢复精度略低于原始的PCA算法。对于同样数量的样本,CCIPCA的总计算时间成本明显高于原始PCA。但是,PCA的时间成本约为CCIPCA的每一步更新时间成本的50倍。另一方面,CCIPCA解决的一个最重要的问题,就是使学习系统能够仅依赖依次到来的新数据,学习特征向量。CCIPCA随着数据的不断加入,降维模型也不断更新。
CCIPCA还有一个好处【也是增量式学习的好处】就是:它的降维模型的训练与利用是可以并存的,这使得CCIPCA可以作为学习系统的终身学习算法。(原始PCA需要在训练结束后,才能使用学习到的降维模型。)
4. 发育网络的核心算法——CCILCA
Candid Covariance-Free Incremental Principal Component Analysis 直接协方差无关的增量式,简称CCILCA
4.1 叶成分
在给定神经元个数
c
c
c,叶成分分析(LCA)将样本空间
X
\mathcal{X}
X划分成
c
c
c个不重叠的区域,我们称其为叶子区域:
X
=
R
∪
R
∪
.
.
.
∪
R
c
\mathcal{X}=\mathcal{R} \cup \mathcal{R} \cup ... \cup \mathcal{R_c}
X=R∪R∪...∪Rc
其中,如果
i
≠
j
i\neq j
i=j,则有
R
i
∪
R
j
=
∅
\mathcal{R}_i \cup \mathcal{R}_j=\empty
Ri∪Rj=∅,具体叶成分可参照下图。

每一个叶区域可以由一个单独的特征向量
v
i
\mathbf{v}_i
vi表示,被称为叶成分。这些叶成分不需要正交,也不需要线性独立。它们撑起一个叶特征子空间
S
S
S
S
=
s
p
a
n
{
v
1
,
v
2
,
.
.
.
,
v
c
}
S=span\{\mathbf{v}_1, \mathbf{v}_2, ..., \mathbf{v}_c\}
S=span{v1,v2,...,vc}
通常情况下,子空间 S S S的维数可以比原始输入空间 X \mathcal{X} X的维数要低。
4.2 算法推导
给定状态空间
X
\mathcal{X}
X的数据集
X
\mathbf{X}
X,我们可以通过
R
j
=
{
x
∣
j
=
a
r
g
max
1
≤
i
≤
c
x
T
v
i
}
\mathcal{R}_j=\{\mathbf{x}|j=arg \max_{1 \leq i \leq c} \mathbf{x}^T \mathbf{v}_i\}
Rj={x∣j=arg1≤i≤cmaxxTvi}
将
X
\mathbf{X}
X划分到各叶区域
R
i
,
i
=
1
,
2
,
.
.
.
,
c
\mathcal{R}_i, i=1,2,...,c
Ri,i=1,2,...,c中,得到与各叶区域相关的子数据集
X
i
,
i
=
1
,
2
,
.
.
.
,
c
\mathbf{X}_i,i=1,2,...,c
Xi,i=1,2,...,c。
那么在已知 X i \mathbf{X}_i Xi,我们怎么求 R i \mathcal{R}_i Ri的最优特征向量 v i \mathbf{v}_i vi呢?
该问题可转变成最大化期望
E
[
∣
∣
x
i
j
T
v
i
∣
∣
2
]
=
∑
j
=
1
N
i
(
x
i
j
T
v
i
)
T
(
x
i
j
T
v
i
)
=
v
i
T
Σ
i
v
i
=
λ
i
E[||\mathbf{x}^T_{ij} \mathbf{v}_i||^2]=\sum_{j=1}^{N_i} (\mathbf{x}^T_{ij} \mathbf{v}_i)^T (\mathbf{x}^T_{ij} \mathbf{v}_i)=\mathbf{v}_i^T \mathbf{\Sigma}_i \mathbf{v}_i=\lambda_i
E[∣∣xijTvi∣∣2]=j=1∑Ni(xijTvi)T(xijTvi)=viTΣivi=λi
其中, Σ i = ∑ j = 1 N i x i j x i j T \mathbf{\Sigma}_i=\sum_{j=1}^{N_i} \mathbf{x}_{ij}\mathbf{x}_{ij}^T Σi=∑j=1NixijxijT为子数据集 X i \mathbf{X}_i Xi的总协方差, ∑ i = 1 c N i = N \sum_{i=1}^{c} N_i=N ∑i=1cNi=N为 X \mathbf{X} X中元素总个数。
根据PCA的的基本理论,可知上式中取与最大特征值 λ i m a x \lambda_{imax} λimax对应的特征相向量 v i \mathbf{v}_i vi为最优特征向量。
因此,针对每个叶区域,特征向量的核心迭代更式与CCIPCA相同,如下图所示。
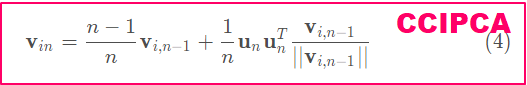
由于每个叶区域
R
i
\mathcal{R}_i
Ri只需要维护一个最优的
v
i
\mathbf{v}_i
vi,可以看作是CCIPCA(维护
k
k
k个特征向量)的特殊形式。【此处结论:CCILCA算法的基础元件是CCIPCA算法。】
v i n i = n i − 1 n i v i , n i − 1 + 1 n i y i n i x n \mathbf{v}_{in_i}=\frac{n_i-1}{n_i}\mathbf{v}_{i,n_i-1}+\frac{1}{n_i}y_{in_i}\mathbf{x}_{n} vini=nini−1vi,ni−1+ni1yinixn
其中, y i n i = x n T v i , n i − 1 ∣ ∣ v i , n i − 1 ∣ ∣ y_{in_i}=\frac{\mathbf{x}_{n}^T\mathbf{v}_{i,n_i-1}}{||\mathbf{v}_{i,n_i-1}||} yini=∣∣vi,ni−1∣∣xnTvi,ni−1为第 n n n个输入 x n \mathbf{x}_n xn对第 i i i个叶区域的响应值,该值度量当前状态与该叶区域的相似性,相似性越高表明 x n \mathbf{x}_n xn属于 R i \mathcal{R}_i Ri的可能性越大。
其于以上分析可总结CCILCA的算法如下:
CCILCA算法

4.3 例子程序
# CCILCA
import numpy as np
from sklearn.datasets import load_digits
X, _ = load_digits(return_X_y=True)
c = 10 #feature nodes numbers
k = 1 # topk
V = np.zeros((c, 64))
n = np.ones(c)
for i in range(c):
index = np.random.randint(len(X))
V[i] = X[index]
def topk(array, k):
k_index = np.argpartition(-array, k-1)[0:k+1]
k_array = array[k_index]
ynorm = [(k_array[i]-k_array[-1])/(k_array[0]-k_array[-1]) for i in range(k)]
return k_array, k_index, ynorm
for j in range(1, len(X)):
index = np.random.randint(len(X))
xt = X[index]
Vnorm = np.linalg.norm(V, axis=1)
Y = np.array([np.sum(xt*V[a])/Vnorm[a] for a in range(c)])
k_array, k_index, ynorm = topk(Y, k)
for i in range(k):
n[k_index[i]] += ynorm[i]
V[k_index[i],:] = (n[k_index[i]]-1)*V[k_index[i],:]/float(n[k_index[i]])+k_array[i]*xt/float(n[k_index[i]])
特征向量可视化:
经过CCILCA学习后,10个特征向量如下所示(题图标号只是特征向量的序号而已,并不是类标)。
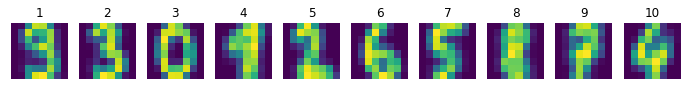
将学习到的特征向量应用于分类问题
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
knn_clf = KNeighborsClassifier()
emdX = np.dot(X, V.T) # 利用特征向量组成的转换矩阵将数据转换到特征空间
X_train, X_test, y_train, y_test = train_test_split(emdX, y)
knn_clf.fit(X_train, y_train)
print (knn_clf.score(X_test, y_test))
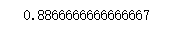
4.4 结果分析
以上示例与结果表明,增量式叶成分分析(CCILCA)算法可以学习得到一个聚类模型,每个聚类中心可用相应的特征向量表示。CCILCA也可以作为降维算法使用,上面我们利用学习到的特征向量将数据转换到特征空间后,再学习分类任务。在测试数据集上的准确率为88.6%,不是很高(毕竟从64维降到了10维)。
另外,CCILCA作为发育网络的核心算法是用于整个网络中的节点更新的全局算法,而CCIPCA则是单个节点的更新算法。这一节主要是介绍了发育网络的核心算法CCILCA,本节可以作为【博客】发育网络(DN): 一个涌现的图灵机的补充内容。
总结
主成分分析作为最经典的特征学习算法之一,已经被广泛应用于机器学习的数据预处理中。但是,主成分分析仅利用了输入状态空间的信息对特征进行学习,它只能保证利用剩余的k维特征还原原始状态数据的准确率。 由于PCA完全忽略标签、有监督信号的信息,因此:PCA并没有把握一定能提高后续机器学习任务的效果,也没有把握能够防止过拟合问题。
实际数据中,各维度可能具有物理意义,也可能没有物理意义,这些维度上的数据尺度有可能相差非常大,加上每个维度对最终的学习结论(分类结果、回归值)的重要性也不是相等的。有些维度的数值比其他维度的数值小太多,但是该维度可能与结论有很大的关联。这种数值幅值比其他维度数值小太多的维度往往会被PCA当作噪声舍弃。因此,PCA可能一不小心就帮我们败掉了数据90%的信息。
对于聚类任务,或者只有状态数据,而无标签信息可用的任务时,预处理(只能)上各种PCA就行了。对于分类或回归任务,如果输入状态空间的各维度是经过专业设计考量的,那么(懒的话)PCA也能用。不过,我们放弃的那些信息,肯定会影响最终的学习效果。
对于输入状态空间各维度的设计不是那么讲究(又或者说,很难通过主观经验设计好)的分类与回归任务,我们怎么办呢?我们怎么将标签信息加入到特征学习中?特征学习可以学出状态各维度的重要性吗?答案是肯定的。后续我将继续总结特征学习相关的研究。
参考文献
[1] Weng J , Zhang Y , Hwang W S . Candid covariance-free incremental principal component analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(8):0-1040.
[2] Weng J , Luciw M . Dually Optimal Neuronal Layers: Lobe Component Analysis[J]. IEEE Transactions on Autonomous Mental Development, 2009, 1(1):68-85.
相关文章
- MySQL索引背后的数据结构及算法原理
- 【超树+蝶形】基于的超树结构和蝶形运算单元的无线传感器网络路由算法FPGA实现详解
- 京东面试——算法工程师
- 基于MATLAB的Kmeans聚类算法的仿真与分析
- 【车牌识别】基于HOG特征提取和GRNN网络的车牌识别算法matlab仿真
- 【波长分配】无线传感器WSN网络中的一种波长分配算法的仿真
- 基于随机接入代价的异构网络速率分配算法研究
- 异构网络垂直切换算法lte/wimax
- 基于无线传感器网络LEACH算法的改进
- ZigBee网络路由算法设计
- C#,图论与图算法,寻找图强连通单元(Strongly Connected Components)的罗伯特·塔扬(Robert Tarjan‘s Algorithm)算法与源程序
- 机器学习笔记之Sigmoid信念网络(三)KL散度角度观察醒眠算法
- 2014各大网络公司校招笔试算法题(收集并更新中)
- 深入浅出的排序算法-冒泡排序
- 深入浅出的排序算法-选择排序
- 为你的回归问题选择最佳机器学习算法
- 算法是问题解决步骤的描述,与具体语言无关
- 操作系统 | 银行家算法举例
- 华为OD机试 - 热点网络统计(JavaScript) | 机试题+算法思路+考点+代码解析 【2023】
- 华为OD机试 -单词反转(Java) | 机试题+算法思路+考点+代码解析 【2023】
- 华为OD机试 - 计算网络信号(Java) | 机试题+算法思路+考点+代码解析 【2023】
- 王道数据结构 (33) Prim 算法的实现思想
- 32数据结构与算法分析之---图的存储方式