
AI-多模态-2022:TCL【triple contrastive learning】【三重对比学习的视觉-语言预训练模型】
论文:https://arxiv.org/pdf/2202.10401.pdf
代码:https://github.com/uta-smile/TCL
写在前面:
CPC[1]这篇论文中,作者对互信息的公式进行了分析,得到互信息下界的相反数为InfoNCE loss,即最小化InfoNCE Loss可以最大化互信息的下界,从而使得互信息最大。即对比学习的infoNCE等价于最大互信息。在TCL这篇文章中,作者即说用了对比学习,又说用了最大化互信息,实则二者都是infoNCE loss。
Summary
这篇论文是在ALBEF[2]的基础进行扩充的。ALBEF(Align before Fusion)的idea通过在多模态特征融合前对齐不同模态之间的表示,从而解决了融合编码器难以融合异构,且维度不同的多模态数据。但是ALBEF的对齐是image-text pair之间的全局对齐,没有考虑到模态内部的对齐,以及global-local的细粒度对齐。所以TCL这篇论文把ALBEF中的一种对齐方式扩展到了三种对齐方式。这便是题目的来源:Triple Contrastive Learning.
Method
三个对比学习损失:
CMA(Cross-Modal Alignment):拉近相似的image-text pair ,拉远不相似的image-text pair。图像和文本可以看做相同语义的两个不同视图view,即最大化这两个视图之间的互信息。负样本来自memory bank。
IMC(Intra-Modal Contrastive ):同一数据样本会经过一个编码器和一个动量编码器,得到一个样本的两个视图view,即最大化这两个视图之间的全局互信息。负样本来自memory bank。
LMI(Local MI Maximization):最大化全局表示和局部表示互信息,例如,要最大化图像的全局表示和图像中每个patch的互信息,最大化句子表示和句子中每个token的互信息。负样本来自memory bank。

两个预训练任务:
ITM(Image Text Matching):多模态预训练模型中常见的预训练任务,判断图像和文本是否匹配。
MLM(Masked Language Modeling):类似于BERT中的MLM完形填空,mask的是图像文本对中文本的某些token,让模型预测这些token的ground-truth。
CMA
这里使用编码器[CLS]处的输出,当做图像和文本的全局表示。这个Cross-Modal ALignment就是对齐image-text pair。使用对比学习的InfoNCE 当做损失函数。
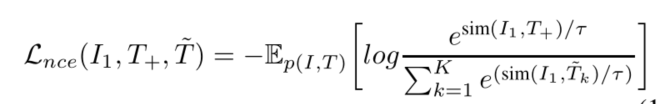
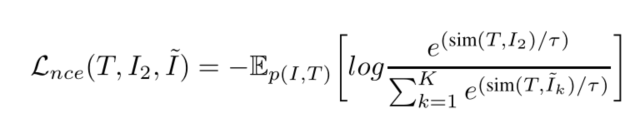
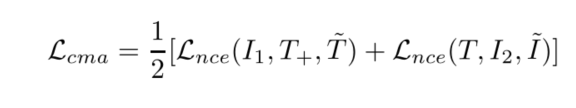
I1,I2 表示同一张图I的两个不同视角,是一个图片的全局表示。 T,T+ 表示同一概率下dropout的输出,看做文本的两个视角。 T~ 表示与图像I_1不匹配负例文本,和MOCO一样使用队列存储负例。 I~ 表示与文本 T 不匹配的负例图像。 τ 表示温度超参数。sim表示两个向量之间的相似度。最小化这个损失函数,等价于最大化log的分子,最小化log的分母,即增加正例相似度,减小负例的相似度。
这个方法忽略了模态内的自监督信号,无法保证能学到理想的表示。文本和图像不是完全匹配的,文字捕捉的仅仅是图像中的显著物体。因此简单地将图像-文本表示拉近会导致退化的表示。可以理解为含有丰富信息的图像表示向含有少量信息的文本表示靠近,会导致丰富信息的表示退化为少量信息的表示。因此图像不能之和文本表示对齐,和相似的图像表示对齐,可以缓解这种情况,进而学到更加合理的表示。
举个例子,紫框图片为原始图片I, 两个绿框图片 I1,I2 为原始图片augmentation后的图片,在嵌入空间中分别为蓝色点和绿色点。与图片匹配的文本,也用绿色点表示。如果现在只考虑CMA,那么蓝点应该向文本的绿点(上面的)靠近,这会导致学到的图像表示会是一个退化的表示。如果此时同时考虑ITC,即蓝点也要考虑向图像的绿点(下面的)靠近,此时原来蓝色点就会被拉到蓝色方块的位置。这样会学到一个合理的表示。

IMC
Intra-Modal Contrastive 在同一模态下学习正负样本之间的语义差异。同一个图片/文本不同视角的表示应当是相似的,ITC的这个思想就是经典的单模态对比学习,与SimCLR[3],MOCO[4],SimCSE[5]相似。这里构建图像的不同视角采用的是随机调整图像大小,随机颜色抖动,随机灰度转换,随机高斯模糊,随机水平翻转和RandAugment。构建文本的不同视角采用的是SimCSE中的dropout构建正例,负例不是像SimCSE中的in-batch负例,而是和MOCO一样的采用队列存储,队列长度65536。
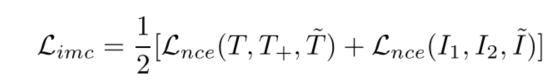
I1,I2 表示同一张图I的两个不同视角,是一个图片的全局表示。 T,T+ 表示同一概率下dropout的输出,看做文本的两个视角。
IMC对齐的是[CLS]位置处的global表示,IMC增大不同视图之间的全局互信息。然而全局MI最大化的有两个缺点:(1)忽略细粒度的局部信息。(2)某些不相关的局部区域可能支配互信息,例如,含有噪声的patch具由更多的信息量,这会影响全局的互信息。基于此,引入LMI,估计global-local的互信息。
LMI
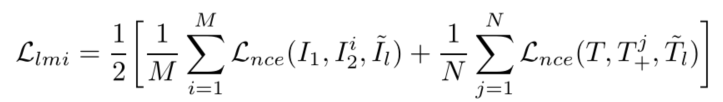
LMI可以学到所有local共享的表示,解决了部分local支配互信息。同时使得模型更好地捕捉细粒度的信息。
ITM
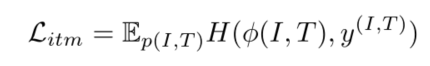
ITM预测image-text pair是否匹配,是一个二分类问题。 ϕ(I,T) 是全连接层输出图像-文本匹配的概率, y(I,T) 是标签,匹配的图文y=1,反之y=0。 H(;) 是交叉熵。
MLM
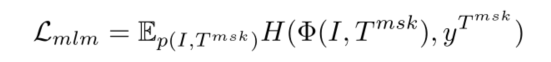
MLM给定图文对,mask掉部分文本token,然后完形填空。 Φ(I,Tmsk) 表示预测被mask掉token的概率。 yTmsk 为ground-truth。
整个模型训练的目标函数为五个部分的累加 L=Lcma+Limc+Llmi+Litm+Lmlm
Backbone
vision encoder: 使用ViT-B/16
text encoder: BERT base前六层
fusion encoder BERT base后六层
Experiments
使用COCO,Visual Genome(VG),Conceptual Captions (CC) , SBU Captions进行预训练。共计400万个图片,510万个图文对。
在跨模态检索数据集上zero-shot的结果
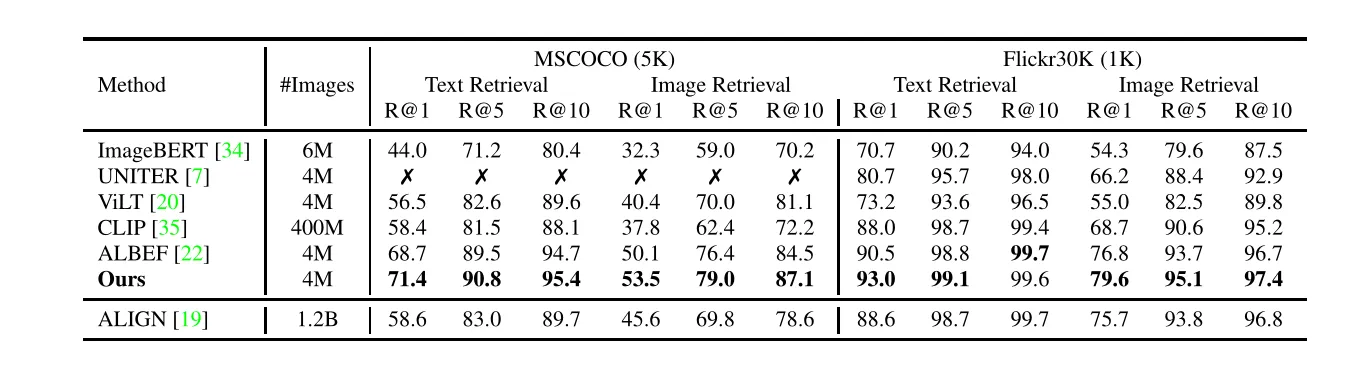
在跨模态检索数据集上finetune的结果

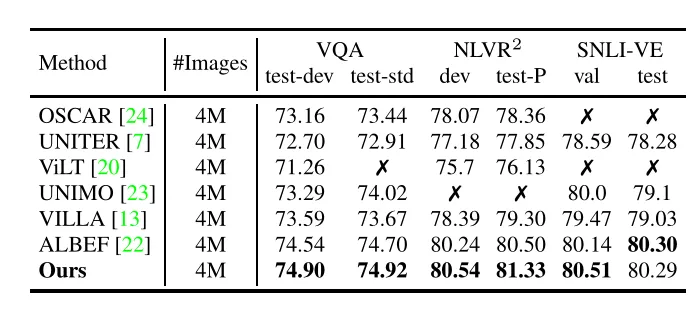
其他多模态任务上finetune的结果
总结
这篇CVPR2022的论文,在多模态预训练中引入三种对比学习,实现了比ALBEF更高的性能。
My thoughts
想法:只mask文本的token。如果mask的是只依靠文本就把mask的预测正确的虚词,模型会不会学到捷径。从而不考虑图像的信息或者很少考虑图像的信息。百度在ERNIE-ViL[6]中引入场景图,确保mask的token都是有语义的实词。感觉这会是个改进点。
疑惑:不知道是不是作者时间不够了,只在4M的预训练数据集上做了实验,并且baseline的选取也都是14M的。感觉时间够的话,完全可以在14M的预训练数据集上跑一下。
收获:1. 把infoNCE一个东西说成,对比学习和互信息最大化,这样写论文就更有故事性。2. 论文中的三个点在需要循序渐进的叙述出来,创新点之间需要进行很好的衔接。这些衔接恰好可以作为论文的motivation。
参考
- ^[1] https://arxiv.org/pdf/1807.03748.pdf
- ^[2] https://arxiv.org/abs/2107.07651
- ^[3] https://arxiv.org/abs/2002.05709
- ^[4] https://arxiv.org/abs/1911.05722
- ^[5] https://arxiv.org/pdf/2104.08821.pdf
- ^[6] https://arxiv.org/abs/2006.16934
相关文章
- 关系抽取标注两条数据训练报错
- (《机器学习》完整版系列)第5章 神经网络——5.3 SOW网络(“灯阵”面板)、Elman网络(将训练集转化时序数据)、Boltzmann机(达到Boltzmann分布)
- Caffe初试(三)使用caffe的cifar10网络模型训练自己的图片数据
- 如何用OpenCV自带的adaboost程序训练并检测目标
- 【PPO姿态控制】基于强化学习(Proximal Policy Optimization)PPO训练的无人机姿态控制simulink仿真
- 【神经网络控制器】基于神经网络的离线训练辨识在线控制的控制系统仿真
- tensorflow 1.0 学习:用别人训练好的模型来进行图像分类
- 【前端作业系列】HTML基础点 , 训练<有序列表><无序列表>(2022年6月15日作业)
- NVIDIA公司推出的GPU运行环境下的机器人仿真环境(NVIDIA Isaac Gym)的安装要求——强化学习的仿真训练环境
- 蓝桥杯训练7
- 【深度学习】——训练过程