
机器学习-有监督学习-分类算法:k-近邻(KNN)算法【多分类】【使用场景: 小数据场景/小样本学习,几千~几万样本】【使用faiss库实现快速计算KNN】
2023-09-27 14:20:37 时间
一、K-近邻算法简介
1、K-近邻算法(KNN)概念
KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,注意KNN算法是有监督学习中的分类算法,它看起来和另一个机器学习算法Kmeans有点像(Kmeans是无监督学习算法),但却是有本质区别的。那么什么是KNN算法呢,接下来我们就来介绍介绍吧。
k-近邻算法:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
相似的样本,同一特征的值应该是相近的。
k的取值会影响结果。
就是通过你的"邻居"来判断你属于哪个类别。
如何计算你到你的"邻居"的距离:一般时候,都是使用欧氏距离
KNN的全称是K Nearest Neighbors,意思是K个最近的邻居,从这个名字我们就能看出一些KNN算法的蛛丝马迹了。K个最近邻居,毫无疑问,K的取值肯定是至关重要的。那么最近的邻居又是怎么回事呢?其实啊,KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。听起来有点绕,还是看看图吧。
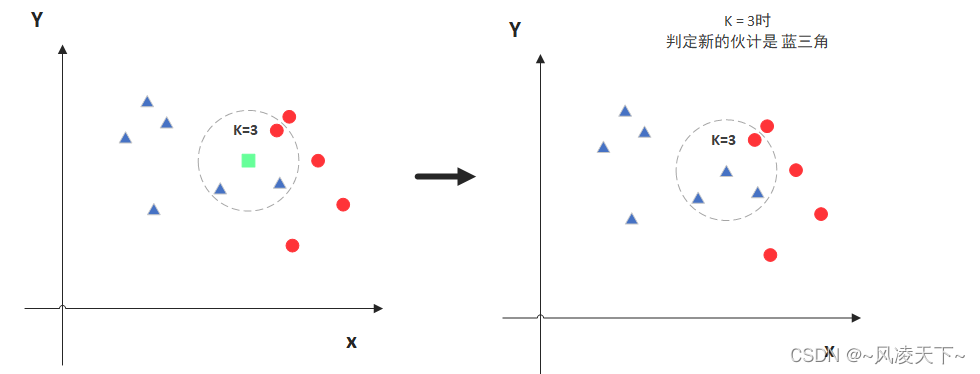
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多
相关文章
- 基于Spark的机器学习实践 (七) - 回归算法
- 机器学习入门:多变量线性回归
- 让机器有温度:带你了解文本情感分析的两种模型
- 机器学习算法模型,如何区分分类还是回归?
- 机器学习-有监督学习-分类算法:决策树算法【CART树:分类树(基于信息熵;分类依据:信息增益、信息增益率、基尼系数)、回归树(基于均方误差)】【损失函数:叶节点信息熵和】【对特征具有很好的分析能力】
- python语言写的代码如何加速:能矩阵运算的就矩阵运算;利用第三方科学计算库(基本都是c++写的);高阶函数;利用好数据结构;使用pypy代替cpython;加机器来提速;最后迫不得已才用C++重写
- 清华大学计算机科学与技术系朱军教授:机器学习里的贝叶斯基本理论、模型和算法
- 机器学习之用Python从零实现贝叶斯分类器
- 机器学习---三种线性算法的比较(线性回归,感知机,逻辑回归)(Machine Learning Linear Regression Perceptron Logistic Regression Comparison)
- 机器学习算法总结(十)——朴素贝叶斯
- 题目:在一个文件中有 10G 个整数,乱序排列,要求找出中位数。内存限制为 2G。只写出思路即可(内存限制为 2G的意思就是,可以使用2G的空间来运行程序,而不考虑这台机器上的其他软件的占用内存)。
- 《构建实时机器学习系统》一1.3 机器学习领域分类
- 机器学习笔记之类别特征处理
- 机器学习笔记之range, numpy.arange 和 numpy.linspace的区别
- 机器学习将成为对抗蜂窝网络欺诈的秘密武器
- 机器学习:基本算法分类体系结构和文章汇总
- 机器学习:Sklearn算法选择路径图
- 机器学习十大算法!入门看这个就够了~
- 机器学习中的监督学习和非监督学习有什么区别?
- 机器学习有哪些应用?机器学习应用领域盘点
- 传智播客 机器学习基础 学习笔记
- 传智播客 机器学习和深度学习之 Scikit-learn与特征工程 学习笔记
- 七月算法机器学习 9 推荐系统与应用 小案例
- 七月算法机器学习 9 推荐系统与应用
- 七月在线Opencv学习机器视觉 学习笔记之 Fundamental of Computer Vision
- Power AI:堪称机器学习的“破壁人”
- 中国首个!阿里巴巴获机器视觉顶级会议ACM MM2020主办权
- 机器学习自主解决安全威胁离我们还有多远?
- (转)从最大似然估计开始,你需要打下的机器学习基石
- 机器视觉公司速感科技完成千万美元B轮融资,或为下一个视觉行业独角兽
- AcWing 376. 机器任务