
深度学习笔记-----多输入网络 (Siamese网络,Triplet网络)
目录
1,什么时候需要多个输入
深度学习网络一般是输入都是一个,或者是一段视频切片,因为大部分的内容是对一张图像或者一段视频内容进行分析。但是也有任务需要输入图像对来得到相对结果,比如检测两个图像的相似度,通过目标跟踪得到相对位置。还有些网络也可以输入多张图像进行多尺度的特征提取。比如图像检测,目标跟踪,相对排序。
2,常见的多输入网络
2.1 Siamese网络(孪生网络)
典型的Siamese网络结构:如下图,其中网络1和网络2是两个一模一样的子网络。两者共享权值。在试使用该网络的时候,分别给这两个网络输入不同的图像,其完成特征提取之后会进行一些匹配工作。

孪生网络的训练过程,如下图所示:

(1) 通过网络传递图像对的第一张图像。
(2) 通过网络传递图像对的第二张图像。
(3) 使用(1)和(2)中的输出来计算损失。
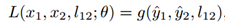
其中,l12为标签,用于表示x1的排名是否高于x2。
训练过程中两个分支网络的输出为高级特征,可以视为quality score。在训练时,输入是两张图像,分别得到对应的分数,将分数的差异嵌入loss层,再进行反向传播。
(4) 返回传播损失计算梯度。
(5) 使用优化器更新权重。
对比损失函数(Contrastive Loss function)
孪生架构的目的不是对输入图像进行分类,而是区分它们。因此,分类损失函数(如交叉熵)不是最合适的选择,这种架构更适合使用对比函数。对比损失函数如下:
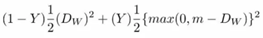
(以判断图片相似度为例)其中Dw被定义为姐妹孪生网络的输出之间的欧氏距离。Y值为1或0。如果模型预测输入是相似的,那么Y的值为0,否则Y为1。m是大于0的边际价值(margin value)。有一个边际价值表示超出该边际价值的不同对不会造成损失。
Siamese网络架构需要一个输入对,以及标签(类似/不相似)。
Siamese网络的代码地址:
https://github.com/xialeiliu/RankIQA
2.1 Triplet网络
Triplet网络作者在前人提出的多个特征提取方法的基础上提出该模型,通过比较距离来学习有用的变量(深度学习中拟合出函数),在多个不同的数据集显示Triplet network比直接计算方法的Siamese network模型效果更好。
Triplet network基本原理:
在Siamese network中,会出现如下的问题,当使用随机对象的数据集时,一个对象可能被认为与另一个对象相似,但是当我们只想区分一组个体中的两个对象时,可能被认为与同样的另一个对象不相似。当选取特征时,并不能够足够判断两者之间的关系,在面对训练样本数量较少的简单分类问题,可能会产生误差。 因此,作者提出了Triplet network,利用三个样本组成一个训练组,从中获取拟合函数。
其基本结构如图1所示:
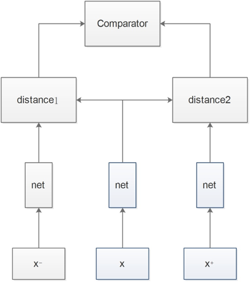
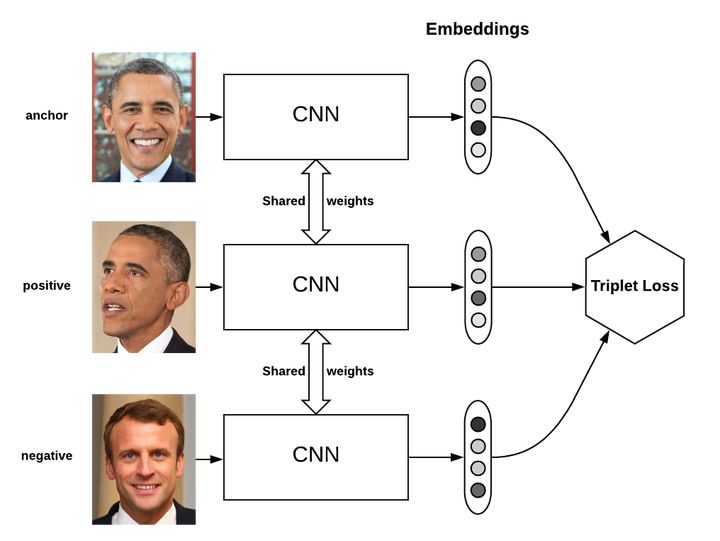
该网络由3个具有相同前馈网络(共享参数)组成的,需要输入是3个样本,一个正样本和两个负样本,或者一个负样本和两个正样本。训练的目标是让相同类别之间的距离竟可能的小。让不同的类别之间距离竟可能的大。就是3个输入表示为x,x+和x-,并将网络的嵌入层表示表示为Net(x)。 简单来说,triplet是一个三元组,这个三元组是这样构成的:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor (记为x)属于同一类的样本和不属于同一类的样本,这两个样本对应的称为Positive (记为x+)和Negative (记为x-),由此构成一个(Anchor,Positive,Negative)三元组。他们之间的关系用欧氏距离表示,并通过训练参数使得x向x+靠近,远离x-,从而实现分类任务。
triplet loss:
在有监督的机器学习领域,通常有固定的类别,这时就可以使用基于softmax的交叉熵损失函数进行训练。但有时,类别是一个变量,此时使用triplet loss就能解决问题。在人脸识别,Quora question pair任务中,triplet loss的优势在于细节区分,即当两个输入相似时,triplet loss能够更好地对细节进行建模,相当于加入了两个输入差异性差异的度量,学习到输入的更好表示,从而在上述两个任务中有出色的表现。当然,triplet loss的缺点在于其收敛速度慢,有时不收敛。
Triplet loss的动机是要让属于同一个人的人脸尽可能地“近”(在embedding空间里),而与其他人脸尽可能地“远”。
Triplet loss 定义:
triplet loss的目标是:
两个具有同样标签的样本,他们在新的编码空间里距离很近。
两个具有不同标签的样本,他们在新的编码空间里距离很远。
进一步,我们希望两个positive examples和一个negative example中,negative example与positive example的距离,大于positive examples之间的距离,或者大于某一个阈值:margin。
triplet loss定义在下面三元组概念之上:
- an anchor(基准正例)
- a positive of the same class as the anchor (正例)
- a negative of a different class (负例)
对于(a,p,n)这个triplet(三元组),其triplet loss就可以写作:
![]()
这时可以通过最小化上述损失函数,a与p之间的距离d(a,p)=0,而a与n之间的距离d(a,n)大于d(a,p)+margin。当negative example很好识别时,上述损失函数为0,否则是一个比较大的值。
相关文章
- Text to image论文精读 AttnGAN: Fine-Grained TexttoImage Generation with Attention(带有注意的生成对抗网络细化文本到图像生成)
- 2016年的软件定义网络SDN会有什么变化?
- 【数学建模】“华为杯”高级神经网络Keras(Python代码实现)
- 【BZOJ】1458: 士兵占领(上下界网络流)
- 《大数据、小数据、无数据:网络世界的数据学术》一 1.2 大数据与小数据
- Android 网络请求OkHttp3流程分析
- SDN交换机在云计算网络中的应用场景
- CVPR2017:深度纹理编码网络 (Deep TEN: Texture Encoding Network)
- 《中国制造业走向2025》从构建新价值网络开始
- 走过软件定义网络“来时的路”
- 【Networking】k8s容器网络 && golang相关
- day26<网络编程>
- iOS 网络输入流提供请求体(适用于大容量内容)
- 2023.2.8,周三【图神经网络 学习记录21】动态图分类(重点 以离散网络 和 连续型网络为例);DySAT算法:快照,结构Self-Attention构造,时域Self-Attention的计算
- 2023.1.29,周日【图神经网络 学习记录12】图 注意力机制网络HAN模型:详细断点调试(Debug)过程;模型的几个常见评价指标:TP,TN,FP,FN;查准率,查全率;macro-F1
- pytorch搭建yolov3网络
- 网络摄像头的地盘争夺战——四款僵尸软件的技术解析
- boost中asio网络库多线程并发处理实现,以及asio在多线程模型中线程的调度情况和线程安全。
- 关于cors,(网络请求的)
- 网络技术:以太网