
【数学建模】“华为杯”高级神经网络Keras(Python代码实现)
目录
2.2 两类模型:序贯模型(Sequential)和函数式模型(Model)
1 Keras概述
1.1 简介
keras是一个用Python写的深度学习API,它运行在机器学习平台TensorFlow上。换句话说,Keras是接口(Interface),TensorFlow是平台(Platform)。
Keras是由纯python编写的基于theano/tensorflow的深度学习框架。
Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结果,如果有如下需求,可以优先选择Keras:
a)简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
b)支持CNN和RNN,或二者的结合
c)无缝CPU和GPU切换
1.2 设计原则
a)用户友好:Keras是为人类而不是天顶星人设计的API。用户的使用体验始终是我们考虑的首要和中心内容。Keras遵循减少认知困难的最佳实践:Keras提供一致而简洁的API, 能够极大减少一般应用下用户的工作量,同时,Keras提供清晰和具有实践意义的bug反馈。
b)模块性:模型可理解为一个层的序列或数据的运算图,完全可配置的模块可以用最少的代价自由组合在一起。具体而言,网络层、损失函数、优化器、初始化策略、激活函数、正则化方法都是独立的模块,你可以使用它们来构建自己的模型。
c)易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可。创建新模块的便利性使得Keras更适合于先进的研究工作。
d)与Python协作:Keras没有单独的模型配置文件类型(作为对比,caffe有),模型由python代码描述,使其更紧凑和更易debug,并提供了扩展的便利性。
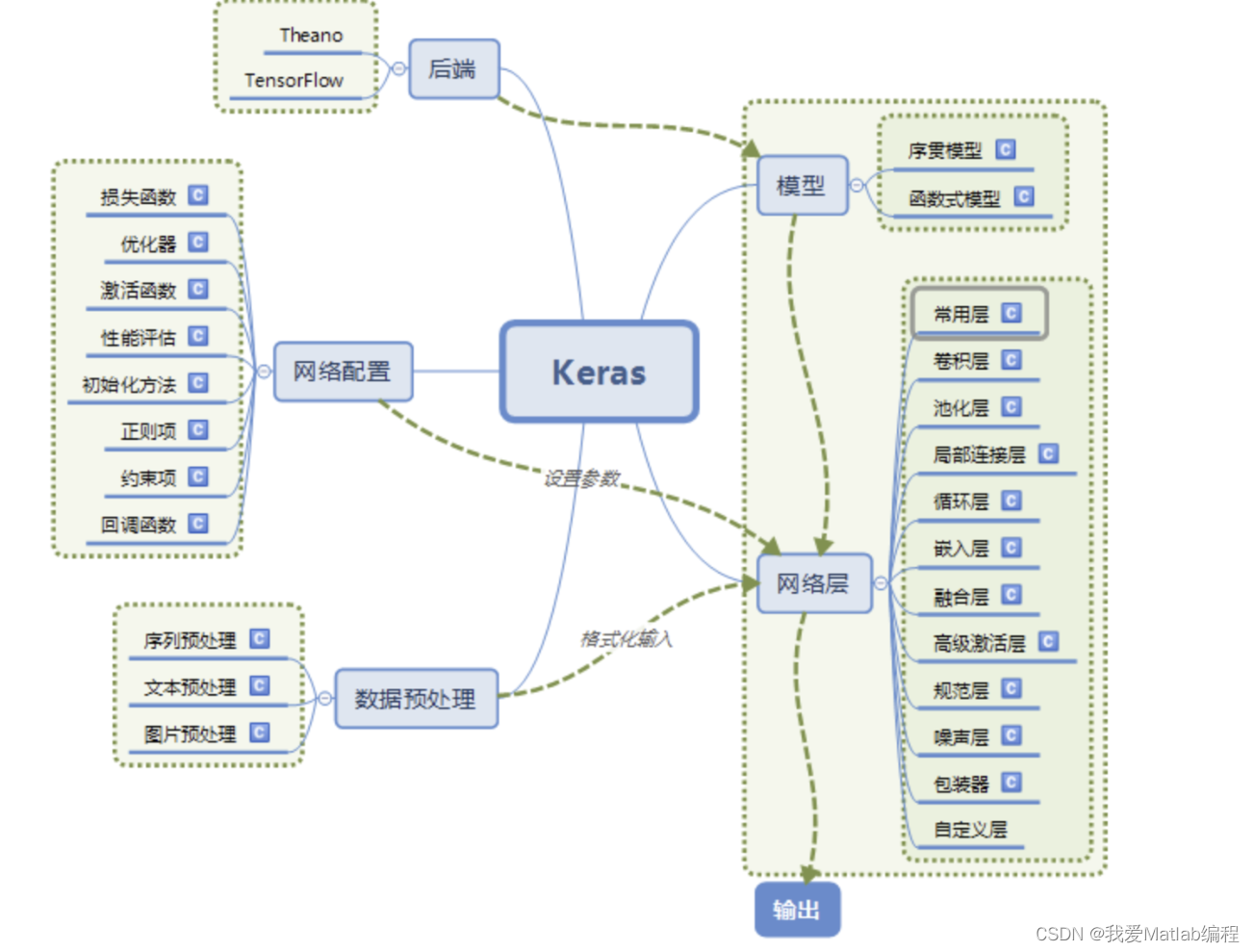
2 Keras的模块结构
2.1 底层库Theano或TensorFlow
Keras的底层库使用Theano或TensorFlow,这两个库也称为Keras的后端。无论是Theano还是TensorFlow,都是一个“符号式”的库。符号计算首先定义各种变量,然后建立一个“计算图”,计算图规定了各个变量之间的计算关系。
2.2 两类模型:序贯模型(Sequential)和函数式模型(Model)
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
a)序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
b)函数式模型(Model):多输入多输出,层与层之间任意连接。这种模型编译速度慢。
2.3 核心数据结构
Keras的核心数据结构是layers(层)和models(模型)。
3 使用Keras搭建一个神经网络
4 入门理解
4.1 算例1网络搭建代码入门
用代码看看整个流程:
#======导入相关库===============
from keras.models import Sequential #神经网络预测
from keras.layers import Dense,Activation #Dense层属于网络层,Activation:激活层
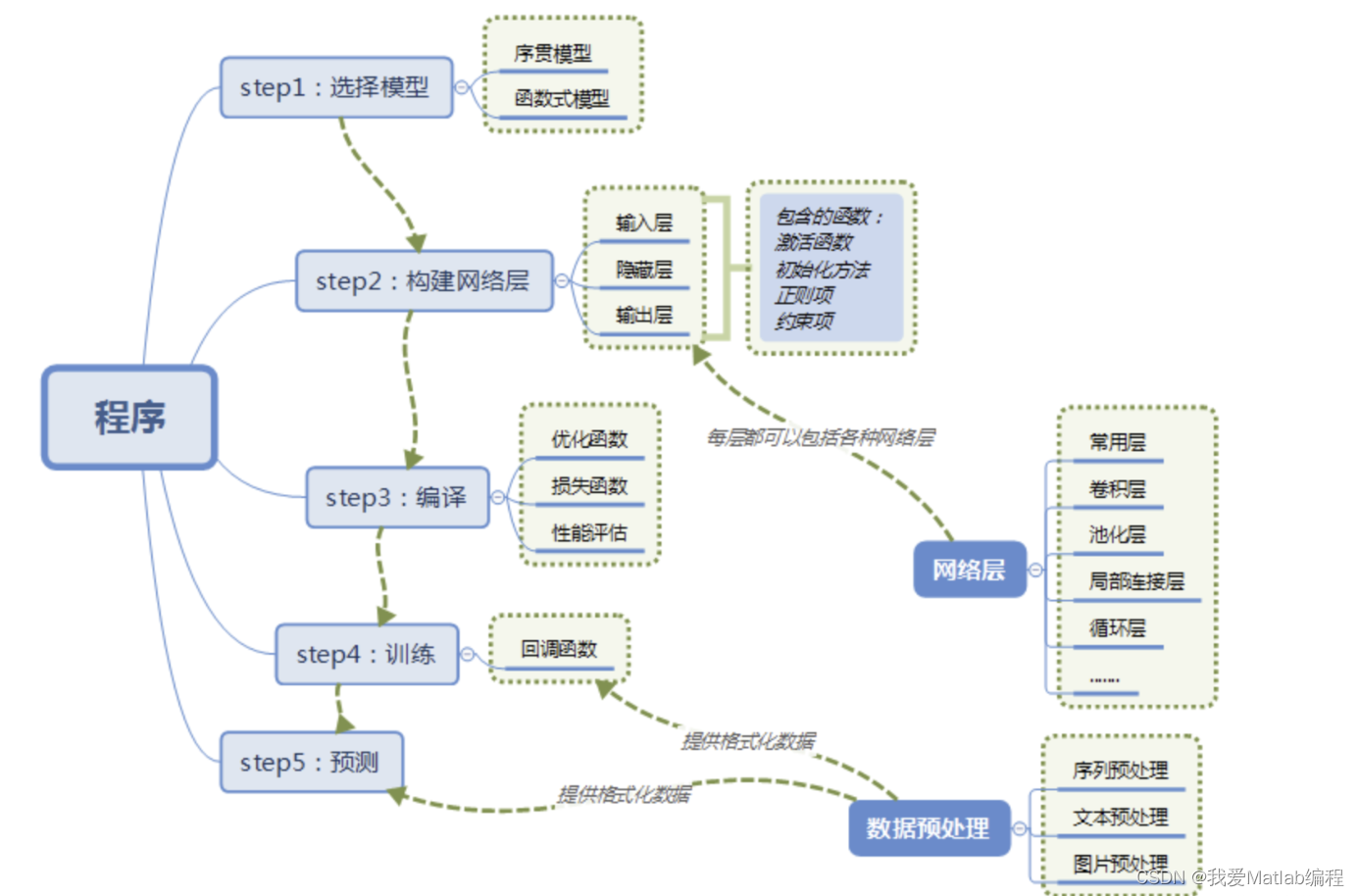
#====step1 选择模型=============
model_1 = Sequential()
#====step2 构建网络层===============
model_1.add(Dense(units=365,activation="relu", input_dim=729)) #729个特征
model_1.add(Dense(units=365,activation="softmax"))
model_1.add(Dense(units=1,activation="sigmoid"))
#=====step3 编译================
model_1.compile(optimizer='adam',loss='binary_crossentropy') #编译,不能少
model_1.summary()
#====step4 训练===========
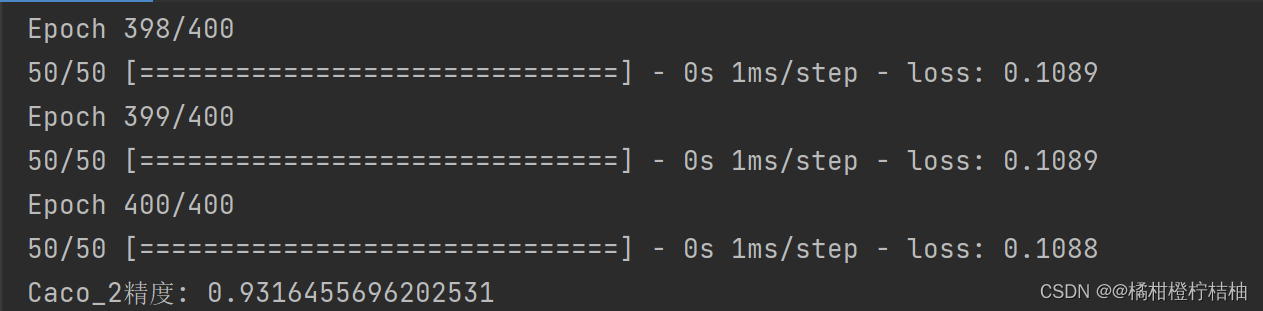
model_1.fit(X_train_std,y_Caco_2_train,epochs=400) # 训练数据,前面数据标准化,后文会有所有代码
#====step5 预测===========
y_Caco_2_test_predict = model_1.predict(X_test_std) # 使用模型预测
for i in range(y_Caco_2_test_predict.shape[0]):
if y_Caco_2_test_predict[i,:]>0.5:
y_Caco_2_test_predict[i,:]=1
else:
y_Caco_2_test_predict[i,:]=0
y_Caco_2_test_predict = np.array(y_Caco_2_test_predict,dtype=int)
#=====精度===============
from sklearn.metrics import accuracy_score #精度
Caco_2_accuracy = accuracy_score(y_Caco_2_test,y_Caco_2_test_predict)
print("Caco_2精度:",Caco_2_accuracy)结果:
重要参数解释:
#====step2 构架网络层=======
Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
(1)units:正整数,输出空间维度
(2)activation:激活函数
(3)kernel_initializer: kernel 权值矩阵的初始化器 (详见 initializers)。
(4)bias_initializer: 偏置向量的初始化器 (see initializers).
(5)regularizer:正则化函数
(6)constraints:约束函数
#======step3 编译===============
compile参数介绍:
model.compile( optimizer, loss = None, metrics = None )常用的三个参数
(1)optimizer:优化器,用于控制梯度裁剪。必选项
sgd:随机梯度下降优化器
(2)loss:损失函数(或称目标函数、优化评分函数)。必选项,上面采用交叉熵作为损失函数。mse:mean_squared_error,均方误差
(3)metrics:评价函数用于评估当前训练模型的性能。当模型编译后(compile),评价函数应该作为 metrics 的参数来输入。评价函数和损失函数相似,只不过评价函数的结果不会用于训练过程中。
Sequential是实现全连接网络的最好方式, 是多个网络层的线性堆栈。model = Sequential()创建一个线性模型后,可以用add()将不同层网络叠加,构成一个网络:
from keras.layers import Dense,Activation
model.add(Dense(units=64,input_dim=100))
model.add(Activation('relu'))
model.add(Dense(units=10))
model.add(Activation('softmax'))或者是直接输入一个list来完成Sequential模型的创建,我一般喜欢上面一种
model = Sequential([
(Dense(units=64,input_dim=100)),
(Activation('relu')),
(Dense(units=10)),
(Activation('softmax'))
])4.2 算例2手写数字的识别
这里也采用介绍神经网络时常用的一个例子:手写数字的识别。
在写代码之前,基于这个例子介绍一些概念,方便大家理解。
PS:可能是版本差异的问题,官网中的参数和示例中的参数是不一样的,官网中给出的参数少,并且有些参数支持,有些不支持。所以此例子去掉了不支持的参数,并且只介绍本例中用到的参数。
1)Dense(500,input_shape=(784,))
a)Dense层属于网络层-->常用层中的一个层
b) 500表示输出的维度,完整的输出表示:(*,500):即输出任意个500维的数据流。但是在参数中只写维度就可以了,比较具体输出多少个是有输入确定的。换个说法,Dense的输出其实是个N×500的矩阵。
c)input_shape(784,) 表示输入维度是784(28×28,后面具体介绍为什么),完整的输入表示:(*,784):即输入N个784维度的数据
2)Activation('tanh')
a)Activation:激活层
b)'tanh' :激活函数
3)Dropout(0.5)
在训练过程中每次更新参数时随机断开一定百分比(rate)的输入神经元,防止过拟合。
4)数据集
数据集包括60000张28×28的训练集和10000张28×28的测试集及其对应的目标数字。如果完全按照上述数据格式表述,以tensorflow作为后端应该是(60000,28,28,3),因为示例中采用了mnist.load_data()获取数据集,所以已经判断使用了tensorflow作为后端,因此数据集就变成了(60000,28,28),那么input_shape(784,)应该是input_shape(28,28,)才对,但是在这个示例中这么写是不对的,需要转换成(60000,784),才可以。为什么需要转换呢?
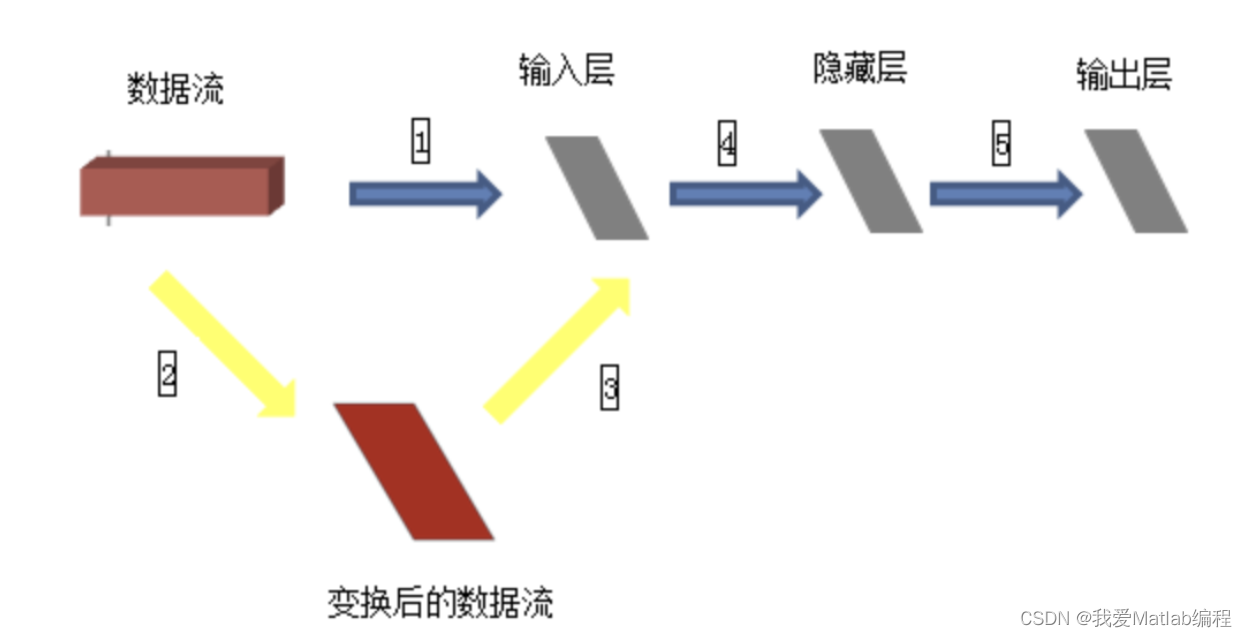
如上图,训练集(60000,28,28)作为输入,就相当于一个立方体,而输入层从当前角度看就是一个平面,立方体的数据流怎么进入平面的输入层进行计算呢?所以需要进行黄色箭头所示的变换,然后才进入输入层进行后续计算。至于从28*28变换成784之后输入层如何处理,就不需要我们关心了。(喜欢钻研的同学可以去研究下源代码)。
并且,Keras中输入多为(nb_samples, input_dim)的形式:即(样本数量,输入维度)。
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD
from keras.datasets import mnist
import numpy
'''
第一步:选择模型
'''
model = Sequential()
'''
第二步:构建网络层
'''
model.add(Dense(500,input_shape=(784,))) # 输入层,28*28=784
model.add(Activation('tanh')) # 激活函数是tanh
model.add(Dropout(0.5)) # 采用50%的dropout
model.add(Dense(500)) # 隐藏层节点500个
model.add(Activation('tanh'))
model.add(Dropout(0.5))
model.add(Dense(10)) # 输出结果是10个类别,所以维度是10
model.add(Activation('softmax')) # 最后一层用softmax作为激活函数
'''
第三步:编译
'''
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) # 优化函数,设定学习率(lr)等参数
model.compile(loss='categorical_crossentropy', optimizer=sgd, class_mode='categorical') # 使用交叉熵作为loss函数
'''
第四步:训练
.fit的一些参数
batch_size:对总的样本数进行分组,每组包含的样本数量
epochs :训练次数
shuffle:是否把数据随机打乱之后再进行训练
validation_split:拿出百分之多少用来做交叉验证
verbose:屏显模式 0:不输出 1:输出进度 2:输出每次的训练结果
'''
(X_train, y_train), (X_test, y_test) = mnist.load_data() # 使用Keras自带的mnist工具读取数据(第一次需要联网)
# 由于mist的输入数据维度是(num, 28, 28),这里需要把后面的维度直接拼起来变成784维
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1] * X_train.shape[2])
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1] * X_test.shape[2])
Y_train = (numpy.arange(10) == y_train[:, None]).astype(int)
Y_test = (numpy.arange(10) == y_test[:, None]).astype(int)
model.fit(X_train,Y_train,batch_size=200,epochs=50,shuffle=True,verbose=0,validation_split=0.3)
model.evaluate(X_test, Y_test, batch_size=200, verbose=0)
'''
第五步:输出
'''
print("test set")
scores = model.evaluate(X_test,Y_test,batch_size=200,verbose=0)
print("")
print("The test loss is %f" % scores)
result = model.predict(X_test,batch_size=200,verbose=0)
result_max = numpy.argmax(result, axis = 1)
test_max = numpy.argmax(Y_test, axis = 1)
result_bool = numpy.equal(result_max, test_max)
true_num = numpy.sum(result_bool)
print("")
print("The accuracy of the model is %f" % (true_num/len(result_bool)))5 算例3“华为杯”“华为杯”高级神经网络Keras实现
5.1 算例
乳腺癌是目前世界上最常见,致死率较高的癌症之一。乳腺癌的发展与雌激素受体密切相关,有研究发现,雌激素受体α亚型(Estrogen receptors alpha, ERα)在不超过10%的正常乳腺上皮细胞中表达,但大约在50%-80%的乳腺肿瘤细胞中表达;而对ERα基因缺失小鼠的实验结果表明,ERα确实在乳腺发育过程中扮演了十分重要的角色。目前,抗激素治疗常用于ERα表达的乳腺癌患者,其通过调节雌激素受体活性来控制体内雌激素水平。因此,ERα被认为是治疗乳腺癌的重要靶标,能够拮抗ERα活性的化合物可能是治疗乳腺癌的候选药物。比如,临床治疗乳腺癌的经典药物他莫昔芬和雷诺昔芬就是ERα拮抗剂。
目前,在药物研发中,为了节约时间和成本,通常采用建立化合物活性预测模型的方法来筛选潜在活性化合物。具体做法是:针对与疾病相关的某个靶标(此处为ERα),收集一系列作用于该靶标的化合物及其生物活性数据,然后以一系列分子结构描述符作为自变量,化合物的生物活性值作为因变量,构建化合物的定量结构-活性关系(Quantitative Structure-Activity Relationship, QSAR)模型,然后使用该模型预测具有更好生物活性的新化合物分子,或者指导已有活性化合物的结构优化。
一个化合物想要成为候选药物,除了需要具备良好的生物活性(此处指抗乳腺癌活性)外,还需要在人体内具备良好的药代动力学性质和安全性,合称为ADMET(Absorption吸收、Distribution分布、Metabolism代谢、Excretion排泄、Toxicity毒性)性质。其中,ADME主要指化合物的药代动力学性质,描述了化合物在生物体内的浓度随时间变化的规律,T主要指化合物可能在人体内产生的毒副作用。一个化合物的活性再好,如果其ADMET性质不佳,比如很难被人体吸收,或者体内代谢速度太快,或者具有某种毒性,那么其仍然难以成为药物,因而还需要进行ADMET性质优化。为了方便建模,本试题仅考虑化合物的5种ADMET性质,分别是:1)小肠上皮细胞渗透性(Caco-2),可度量化合物被人体吸收的能力;2)细胞色素P450酶(Cytochrome P450, CYP)3A4亚型(CYP3A4),这是人体内的主要代谢酶,可度量化合物的代谢稳定性;3)化合物心脏安全性评价(human Ether-a-go-go Related Gene, hERG),可度量化合物的心脏毒性;4)人体口服生物利用度(Human Oral Bioavailability, HOB),可度量药物进入人体后被吸收进入人体血液循环的药量比例;5)微核试验(Micronucleus,MN),是检测化合物是否具有遗传毒性的一种方法。
5.2 数据集介绍及建模目标
本试题针对乳腺癌治疗靶标ERα,首先提供了1974个化合物对ERα的生物活性数据。这些数据包含在文件“ERα_activity.xlsx”的training表(训练集)中。training表包含3列,第一列提供了1974个化合物的结构式,用一维线性表达式SMILES(Simplified Molecular Input Line Entry System)表示;第二列是化合物对ERα的生物活性值(用IC50表示,为实验测定值,单位是nM,值越小代表生物活性越大,对抑制ERα活性越有效);第三列是将第二列IC50值转化而得的pIC50(即IC50值的负对数,该值通常与生物活性具有正相关性,即pIC50值越大表明生物活性越高;实际QSAR建模中,一般采用pIC50来表示生物活性值)。该文件另有一个test表(测试集),里面提供有50个化合物的SMILES式。
其次,在文件“Molecular_Descriptor.xlsx”的training表(训练集)中,给出了上述1974个化合物的729个分子描述符信息(即自变量)。其中第一列也是化合物的SMILES式(编号顺序与上表一样),其后共有729列,每列代表化合物的一个分子描述符(即一个自变量)。化合物的分子描述符是一系列用于描述化合物的结构和性质特征的参数,包括物理化学性质(如分子量,LogP等),拓扑结构特征(如氢键供体数量,氢键受体数量等),等等。关于每个分子描述符的具体含义,请参见文件“分子描述符含义解释.xlsx”。同样地,该文件也有一个test表,里面给出了上述50个测试集化合物的729个分子描述符。
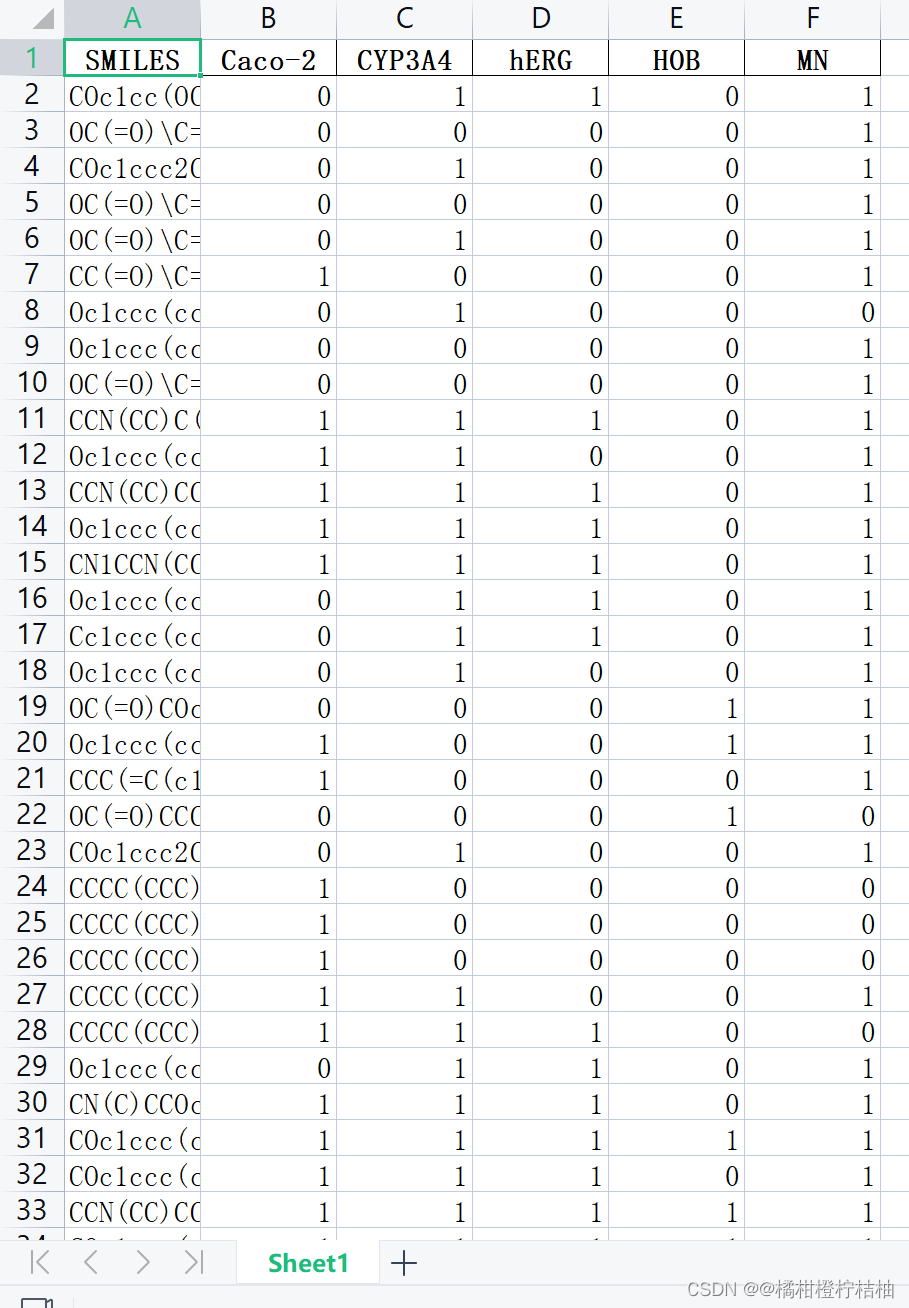
最后,在关注化合物生物活性的同时,还需要考虑其ADMET性质。因此,在文件“ADMET.xlsx”的training表(训练集)中,提供了上述1974个化合物的5种ADMET性质的数据。其中第一列也是表示化合物结构的SMILES式(编号顺序与前面一样),其后5列分别对应每个化合物的ADMET性质,采用二分类法提供相应的取值。Caco-2:‘1’代表该化合物的小肠上皮细胞渗透性较好,‘0’代表该化合物的小肠上皮细胞渗透性较差;CYP3A4:‘1’代表该化合物能够被CYP3A4代谢,‘0’代表该化合物不能被CYP3A4代谢;hERG:‘1’代表该化合物具有心脏毒性,‘0’代表该化合物不具有心脏毒性;HOB:‘1’代表该化合物的口服生物利用度较好,‘0’代表该化合物的口服生物利用度较差;MN:‘1’代表该化合物具有遗传毒性,‘0’代表该化合物不具有遗传毒性。同样地,该文件也有一个test表,里面提供有上述50个化合物的SMILES式(编号顺序同上)。
建模目标:根据提供的ERα拮抗剂信息(1974个化合物样本,每个样本都有729个分子描述符变量,1个生物活性数据,5个ADMET性质数据),构建化合物生物活性的定量预测模型和ADMET性质的分类预测模型,从而为同时优化ERα拮抗剂的生物活性和ADMET性质提供预测服务。
5.3 题目
请利用文件“Molecular_Descriptor.xlsx”提供的729个分子描述符,针对文件“ADMET.xlsx”中提供的1974个化合物的ADMET数据,分别构建化合物的Caco-2、CYP3A4、hERG、HOB、MN的分类预测模型,并简要叙述建模过程。然后使用所构建的5个分类预测模型,对文件“ADMET.xlsx”的test表中的50个化合物进行相应的预测,并将结果填入“ADMET.xlsx”的test表中对应的Caco-2、CYP3A4、hERG、HOB、MN列。
5.4 解决方案
方案:机器学习分类模型中五分类。
5.5 Python代码实现
'''导入相关库'''
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split #拆分数据集
from sklearn.preprocessing import StandardScaler #标准化数据
from keras.models import Sequential #神经网络预测
from keras.layers import Dense,Activation #Dense层属于网络层,Activation:激活层
import tensorflow as tf
from sklearn.metrics import accuracy_score #精度
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei',font_scale=1.5) # 解决Seaborn中文显示问题并调整字体大小
'''1读取数据'''
y = pd.read_excel("./ADMET.xlsx") # 读取训练数据
X = pd.read_excel("./Molecular_Descriptor.xlsx") # 读取数据
X = X.drop(["SMILES"], axis=1) # 删除描述
y = y.drop(["SMILES"], axis=1) #删除描述
'''2分割数据'''
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666) # 分割
'''3数据标准化'''
std = StandardScaler()
std.fit(X_train)
X_train_std = std.transform(X_train)
X_test_std = std.transform(X_test)
'''4提取五个特征的训练和测试'''
y_Caco_2_train = y_train.loc[:,"Caco-2"]
y_CYP3A4_train = y_train.loc[:,"CYP3A4"]
y_hERG_train = y_train.loc[:,"hERG"]
y_HOB_train = y_train.loc[:,"HOB"]
y_MN_train = y_train.loc[:,"MN"]
y_Caco_2_test = y_test.loc[:,"Caco-2"]
y_CYP3A4_test = y_test.loc[:,"CYP3A4"]
y_hERG_test = y_test.loc[:,"hERG"]
y_HOB_test = y_test.loc[:,"HOB"]
y_MN_test = y_test.loc[:,"MN"]
'''5搭建神经网络模型'''
#=====(1)对Caco-2进行训练=======
#======导入相关库===============
from keras.models import Sequential #神经网络预测
from keras.layers import Dense,Activation #Dense层属于网络层,Activation:激活层
#====step1 选择模型=============
model_1 = Sequential()
#====step2 构建网络层===============
model_1.add(Dense(units=365,activation="relu", input_dim=729)) #729个特征
model_1.add(Dense(units=365,activation="softmax"))
model_1.add(Dense(units=1,activation="sigmoid"))
#=====step3 编译================
model_1.compile(optimizer='adam',loss='binary_crossentropy') #编译,不能少
model_1.summary()
#====step4 训练===========
model_1.fit(X_train_std,y_Caco_2_train,epochs=400) # 训练数据,前面数据标准化,后文会有所有代码
#====step5 预测===========
y_Caco_2_test_predict = model_1.predict(X_test_std) # 使用模型预测
for i in range(y_Caco_2_test_predict.shape[0]):
if y_Caco_2_test_predict[i,:]>0.5:
y_Caco_2_test_predict[i,:]=1
else:
y_Caco_2_test_predict[i,:]=0
y_Caco_2_test_predict = np.array(y_Caco_2_test_predict,dtype=int)
#=====精度===============
from sklearn.metrics import accuracy_score #精度
Caco_2_accuracy = accuracy_score(y_Caco_2_test,y_Caco_2_test_predict)
print("Caco_2精度:",Caco_2_accuracy)
#(2)对CYP3A4进行训练并预测
model_2 = Sequential()
model_2.add(Dense(units=365,activation="relu", input_dim=729))
model_2.add(Dense(units=365,activation="softmax"))
model_2.add(Dense(units=1,activation="sigmoid"))
model_2.compile(optimizer='adam',loss='binary_crossentropy')
model_2.fit(X_train_std,y_CYP3A4_train,epochs=400)
y_CYP3A4_test_predict = model_2.predict(X_test_std)
for i in range(y_CYP3A4_test_predict.shape[0]):
if y_CYP3A4_test_predict[i,:]>0.5:
y_CYP3A4_test_predict[i,:]=1
else:
y_CYP3A4_test_predict[i,:]=0
y_CYP3A4_test_predict = np.array(y_CYP3A4_test_predict,dtype=int)
CYP3A4_accuracy = accuracy_score(y_CYP3A4_test,y_CYP3A4_test_predict)
print("CYP3A4精度:",CYP3A4_accuracy)
#(3)预测hERG:
model_3 = Sequential()
model_3.add(Dense(units=365,activation="relu", input_dim=729))
model_3.add(Dense(units=365,activation="softmax"))
model_3.add(Dense(units=1,activation="sigmoid"))
model_3.compile(optimizer='adam',loss='binary_crossentropy')
model_3.fit(X_train_std,y_hERG_train,epochs=400)
y_hERG_test_predict = model_3.predict(X_test_std)
for i in range(y_hERG_test_predict.shape[0]):
if y_hERG_test_predict[i,:]>0.5:
y_hERG_test_predict[i,:]=1
else:
y_hERG_test_predict[i,:]=0
y_hERG_test_predict = np.array(y_hERG_test_predict,dtype=int)
hERG_accuracy = accuracy_score(y_hERG_test,y_hERG_test_predict)
print("hERG精度:",hERG_accuracy)
#(4)对HOB进行训练并预测
model_4 = Sequential()
model_4.add(Dense(units=365,activation="relu", input_dim=729))
model_4.add(Dense(units=365,activation="softmax"))
model_4.add(Dense(units=1,activation="sigmoid"))
model_4.compile(optimizer='adam',loss='binary_crossentropy')
model_4.fit(X_train_std,y_HOB_train,epochs=400)
y_HOB_test_predict = model_4.predict(X_test_std)
for i in range(y_HOB_test_predict.shape[0]):
if y_HOB_test_predict[i,:]>0.5:
y_HOB_test_predict[i,:]=1
else:
y_HOB_test_predict[i,:]=0
y_HOB_test_predict = np.array(y_HOB_test_predict,dtype=int)
HOB_accuracy = accuracy_score(y_HOB_test,y_HOB_test_predict)
print("HOB精度:",HOB_accuracy)
#(5)对MN进行训练并预测
model_5 = Sequential()
model_5.add(Dense(units=365,activation="relu", input_dim=729))
model_5.add(Dense(units=365,activation="softmax"))
model_5.add(Dense(units=1,activation="sigmoid"))
model_5.compile(optimizer='adam',loss='binary_crossentropy')
model_5.fit(X_train_std,y_MN_train,epochs=400)
y_MN_test_predict = model_5.predict(X_test_std)
for i in range(y_MN_test_predict.shape[0]):
if y_MN_test_predict[i,:]>0.5:
y_MN_test_predict[i,:]=1
else:
y_MN_test_predict[i,:]=0
y_MN_test_predict = np.array(y_MN_test_predict,dtype=int)
MN_accuracy = accuracy_score(y_MN_test,y_MN_test_predict)
print("MN精度:",MN_accuracy)
'''读取测试数据,准备填表'''
test = pd.read_excel("./ADMET.xlsx",sheet_name='test') # 读取训练数据
'''使用模型预测并填充到表格:'''
data_ADMET_test = pd.read_excel("./ADMET.xlsx",sheet_name="test") #输出
origin_molecular = pd.read_excel("./Molecular_Descriptor.xlsx",sheet_name='test') #特征
X_final = origin_molecular.drop(['SMILES'],axis=1) #去掉不是特征后,得到要测试的特征
#对预测值做均值方差归一化
std = StandardScaler()
std.fit(X_final)
X_final_std = std.transform(X_final)
#预测Caco_2指标并填入excel表
Caco_2_predict = model_1.predict(X_final_std)
for i in range(Caco_2_predict.shape[0]):
if Caco_2_predict[i,:]>0.5:
Caco_2_predict[i,:]=1
else:
Caco_2_predict[i,:]=0
Caco_2_predict = np.array(Caco_2_predict,dtype=int)
data_ADMET_test.loc[:,["Caco-2"]] = Caco_2_predict
#预测CYP3A4指标并填入excel表
CYP3A4_predict = model_2.predict(X_final_std)
for i in range(CYP3A4_predict.shape[0]):
if CYP3A4_predict[i,:]>0.5:
CYP3A4_predict[i,:]=1
else:
CYP3A4_predict[i,:]=0
CYP3A4_predict = np.array(CYP3A4_predict,dtype=int)
data_ADMET_test.loc[:,["CYP3A4"]] = CYP3A4_predict
#预测hERG指标并填入excel表
hERG_predict = model_3.predict(X_final_std)
for i in range(hERG_predict.shape[0]):
if hERG_predict[i,:]>0.5:
hERG_predict[i,:]=1
else:
hERG_predict[i,:]=0
hERG_predict = np.array(hERG_predict,dtype=int)
data_ADMET_test.loc[:,["hERG"]] = hERG_predict
#预测HOB指标并填入excel表
HOB_predict = model_4.predict(X_final_std)
for i in range(HOB_predict.shape[0]):
if HOB_predict[i,:]>0.5:
HOB_predict[i,:]=1
else:
HOB_predict[i,:]=0
HOB_predict = np.array(HOB_predict,dtype=int)
data_ADMET_test.loc[:,["HOB"]] = HOB_predict
#预测MN指标并填入excel表
MN_predict = model_5.predict(X_final_std)
for i in range(MN_predict.shape[0]):
if MN_predict[i,:]>0.5:
MN_predict[i,:]=1
else:
MN_predict[i,:]=0
MN_predict = np.array(MN_predict,dtype=int)
data_ADMET_test.loc[:,["MN"]] = MN_predict
'''预测并保存:'''
data_ADMET_test.to_excel("ADMET_predict.xlsx",index=False)5.6 运行结果
5.7 致谢
川川大神:华为杯数学建模第三题
6 写在最后
keras具有的特性
1、相同的代码可以在cpu和gpu上切换;
2、在模型定义上,可以用函数式API,也可以用Sequential类;
3、支持任意网络架构,如多输入多输出;
4、能够使用卷积网络、循环网络及其组合。
keras与后端引擎
Keras 是一个模型级的库,在开发中只用做高层次的操作,不处于张量计算,微积分计算等低级操作。但是keras最终处理数据时数据都是以张量形式呈现,不处理张量操作的keras是如何解决张量运算的呢?
keras依赖于专门处理张量的后端引擎,关于张量运算方面都是通过后端引擎完成的。这也就是为什么下载keras时需要下载TensorFlow 或者Theano的原因。而TensorFlow 、Theano、以及CNTK都属于处理数值张量的后端引擎。
相关文章
- python ssh 交互式命令行脚本,查找关键字,进行下一步命令操作。
- Python 机器学习 | 超参数优化 黑盒(Black-Box)非凸优化技术实践
- Python机器学习数据建模与分析——Numpy和Pandas综合应用案例:空气质量监测数据的预处理和基本分析
- python小知识点
- python真值表
- 成功解决:Can‘t find Python executable “python“, you can set the PYTHON env variable.
- 【Python入门】Python基础语法
- shell脚本调用python脚本的路径问题
- PyQt(Python+Qt)学习随笔:QListWidget的addItem方法
- python图像处理(直方图增强)
- Python numpy.rint 函数方法的使用
- 列举几个python解决数学建模的例子
- 我们怎么卷?推荐6款GitHub上的Python热门项目,一起学起来
- 【深度学习 内力篇】Chap.1 单变量线性回归问题+梯度下降算法+Python建模实战
- Python类,特殊方法, __getitem__,__len__, __delitem__
- python学习之数据结构(四):数据结构与算法:栈、队列