
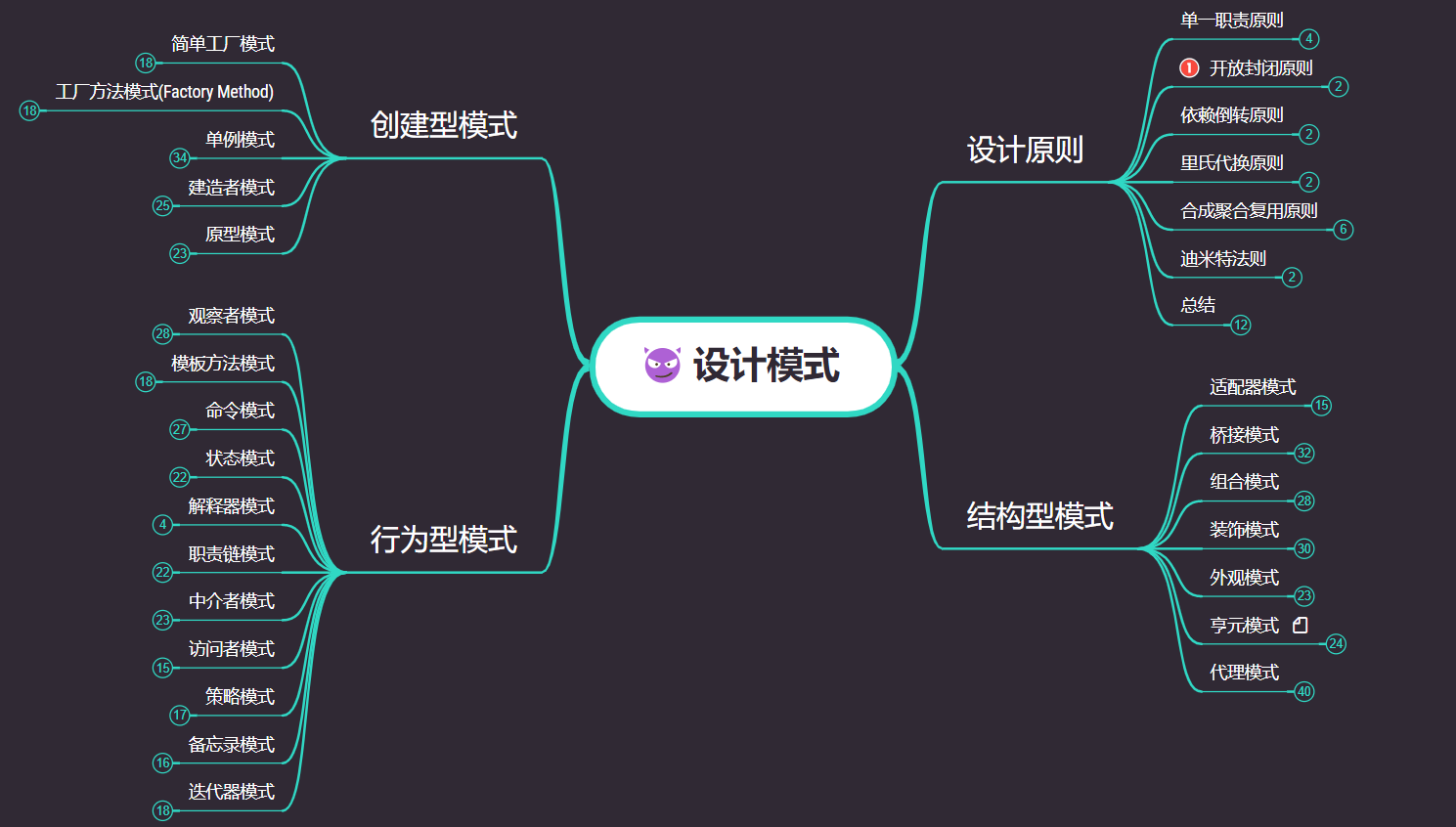
设计模式学习(汇总版)
思维导图下载
我们知道只有运用好设计原则和设计模式,才能让我们写出更加优秀的代码或者设计更好软件架构,在实际开发中,由于许多不遵守设计原则和设计模式的硬编码,导致项目代码及其晦涩难懂的例子比比皆是,作为一个软件开发人员,写出高质量、易懂、已维护的代码应该是我们每个人应该做到的
1. 六大设计原则
我们知道设计模式一共有23种,虽然模式很多,但是都是为了遵守和实现六大设计原则而诞生的,如果我们能够理解六大设计原则,相信我们也能像令狐冲修炼独孤九剑一样无招胜有招,毕竟功夫的最高境界就是忘记招式,下意识使用的就是最合理的招式
其中我们要注意的是,其实六大设计模式主要是为了满足变,这个字,可能是需求变更、可能是场景变更,但是运用好六大设计模式后我们写出的代码就能很好的应对不断变化的场景,做到任他东南西北风我自岿然不动的境界
1.1 单一职责
单一职责原则(Single Responsibility Principle, SRP):一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。
简单的来讲:就是小到一个方法、一个类,大到一个框架,都只负责一件事情
例如:
- Math.round(),只负责完成四舍五入的功能,其他的不负责
- Reader类,只负责读取字符(文本文件)
- SpringMVC,只负责简化MVC的开发(框架)
举个栗子,我们知道,中国有四大发明,分别是造纸术、指南针、火药、活字印刷术,这里要注意的是活字印刷术,而不是印刷术,我们思考一下为什么印刷术出现的比活字印刷术早,但是并没有被列入四大发明呢?活字印刷术看起来不应该只是印刷术的改良版本吗?
我们来设想一个场景,在没有活字印刷术之前如果现在需要批量印刷一篇文章,我们需要怎么做?找人抄吗?高效的方法是拿块木板,用篆刀雕刻出一篇文章,然后搞点墨水,一下就能印出一篇文章,这样的速度非常快!

但是现在变化来了,前面提到,设计原则主要就是为了应对变化的。现在有个师傅发现好不容易雕刻的木板上有个字写错了!那现在怎么办呢?只能重新篆刻。那如果下次又发现需要更换句子怎么办呢?我们发现雕版印刷术并不能很好的应对变化
再让我们看看活字印刷术是如何处理的?首先我们现在不再直接篆刻一块大大的木板了,我们将原本很大的职责拆分成一个一个的汉字,再通过组合的方式将我们需要的文章拼起来,这样下次字写错了只需要修改一个字即可

这就是单一职责的核心:
通过高内聚、低耦合的设计方案,刚庞大的系统拆成单一职责的小功能,再通过灵活组合的方式完成功能,这样做最大的好处就是可以通过不断的组合,应对不断变化的场景
举个我们在编码中最容易遇到的情况,我们有的时候看别人的函数实现,有的恶心的代码可能一个函数中就有大几百行,然后你们全部都是业务逻辑,比如支付功能的函数中有查询商品库存 -> 查询用户余额 -> 确认订单 -> 调用支付接口这五个步骤,有的同学写代码上去就是搜哈,一股脑全写完,下次遇到个退货的功能需要用到查询商品库存、查询用户余额的代码,直接copy过去,造成代码臃肿,可读性差,正确的方式应该是将其封装成一个个的方法或函数,这样可以做到减少重复代码的效果
关于单一职责,这里就不用代码举例了,大家记住在平时编码中记住单一职责、不断组合就行
1.2 开闭原则
开闭原则(Open Close Principle)
开闭原则就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。所以一句话概括就是:为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类
举个栗子,我现在有一个刮胡刀,刮胡刀的功能应该就是刮胡子,但是我现在想要它拥有吹风机的能力
- 违法开闭原则的做法是,把吹风机的功能加上了,可能就不能刮胡子了
- 符合开闭原则的做法是,把吹风功能加上,且没有影响之前刮胡子的功能
例如我现在有一个商品类Goods,这个类之前有一个方法是获取它的价格,例如:
public class Goods {
private BigDecimal price;
public void setPrice(BigDecimal price) {
this.price = price;
}
public BigDecimal getPrice() {
return this.price;
}
}
现在变化来了,当前商品需要打8折进行销售,不符合开闭原则的做法就是直接进原来的代码中进行修改,例如直接在getter方法中修改
public BigDecimal getPrice() {
// BigDecimal.multiply就是乘法,BigDecimal可以防止精度丢失
return this.price.multiply(new BigDecimal("0.8"));
}
这样显然就是不满足开闭原则的,因为我们对源代码进行了修改,如果下次是打七折,那是不是又要去改源代码呢
正确的做法应该是写一个子类DiscountGoods来拓展父类的功能,再在子类上进行修改,这样就不会破坏父类的功能,又能满足需求
public class DiscountGoods extends Goods{
@Override
public BigDecimal getPrice() {
return super.getPrice().multiply(new BigDecimal("0.8"));
}
}
这就叫对扩展开发,对修改关闭。我们在用设计模式编码时应该时刻注意的是,改源码是一件非常危险的事情,因为一个功能并不是只有你在使用,很容易造成牵一发而动全身的效果
但是如果我们因为要遵守开闭原则,每次对功能进行修改的时候,都去新写一个类,这样的会很繁琐,所以我们的准则是:
- 如果一个类是自己写的,自己修改不会影响该类在其他地方的效果(不会
牵一发而动全身),那你就可以随意修改 - 如果不是自己写的,自己不清楚修改后会带来什么样的影响,那就不要修改,而要符合开闭原则
1.3 接口隔离原则
接口隔离原则(Interface Segregation Principle)
使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口
接口隔离原则在我们设计接口的时候也是非常容易忽略从而造成问题的的一个原则,例如我现在要要设计一个动物的接口,统一动物的行为,我们可能会这样写:
public interface Animal{
void eat();
void swim();
void fly();
}
我们看这三个行为,分别是吃、游泳和飞,我们定义的是动物的接口,这样好像并没有什么问题,动物确实拥有这三个行为,但是问题就在于动物这个接口范围太大了,并不是所以的动物都同时拥有这三个行为
例如下面的小狗类中,狗由于不会非,所以不应该有方法fly() 的实现!
public class Dog implements Animal {
@Override
public void eat() {
System.out.println("小狗在吃东西");
}
@Override
public void swim() {
System.out.println("小狗会狗刨");
}
@Override
public void fly() {
throw new UnsupportedOperationException("小狗不会飞");
}
}
我们现在将这个大接口拆分一下:
interface Eatable{
void eat();
}
interface Swimable{
void swim();
}
interface Flyable{
void fly();
}
再不断的组合,实现不同的接口,其实核心思想还是高内聚,低耦合,通过不断组合不可分割的功能完成最终需要的功能
是不是现在有一点点无招胜有招的感觉了,感觉习惯之后自然而然就好感觉这块设计有问题,然后设计更好能应对变化的方案
public class Dog implements Eatable, Swimable {
@Override
public void eat() {
System.out.println("小狗在吃东西");
}
@Override
public void swim() {
System.out.println("小狗会狗刨");
}
}
1.4 依赖倒置原则
依赖倒置原则(Dependence Inversion Principle)
这个是开闭原则的基础,具体内容:针对接口编程,依赖于抽象而不依赖于具体。实际中开发的实践就是,
面向接口编程
- 上层不应该依赖于下层
- 它们都应该依赖于抽象
依赖倒置在实际编码中通常采取的是:上层不能依赖于下层,他们都应该依赖于抽象
这里区分上下层的方法为:调用别的方法的就是上层,被调用的就是下层
举个栗子:我们现在有三个类,互相有依赖关系
class Person {
public void feed(Dog dog) {
System.out.println("开始喂dog...");
}
}
class Dog {
public void eat() {
System.out.println("狗啃骨头");
}
}
// ================================================================
public class AppTest {
public static void main(String[] args) {
Person person = new Person();
Dog dog = new Dog();
person.feed(dog);
}
}
首先我们在依赖倒置原则里面非常重要的一点是,要区分依赖中的上层和下层,我们时刻要注意调用别的方法的就是上层,被调用的就是下层,所以这里的层级关系为:AppTest是Person的上层,Person是Dog的上层
我们来仔细思考一下上面的代码,这里好像没什么问题,但是我一直强调的是设计模式是为了应对变化,现在变化来了,现在客户端Person不仅需要喂狗,还需要喂猫,我们很容易直接添加一个Cat类
class Cat {
public void eat() {
System.out.println("小猫吃鱼");
}
}
public class AppTest {
public static void main(String[] args) {
Person person = new Person();
Dog dog = new Dog();
Cat cat = new Cat();
// 喂狗
person.feed(dog);
// 喂猫
person.feed(cat);
}
}
这样明显会报错,因为之前的代码中只能喂狗,不能喂猫!
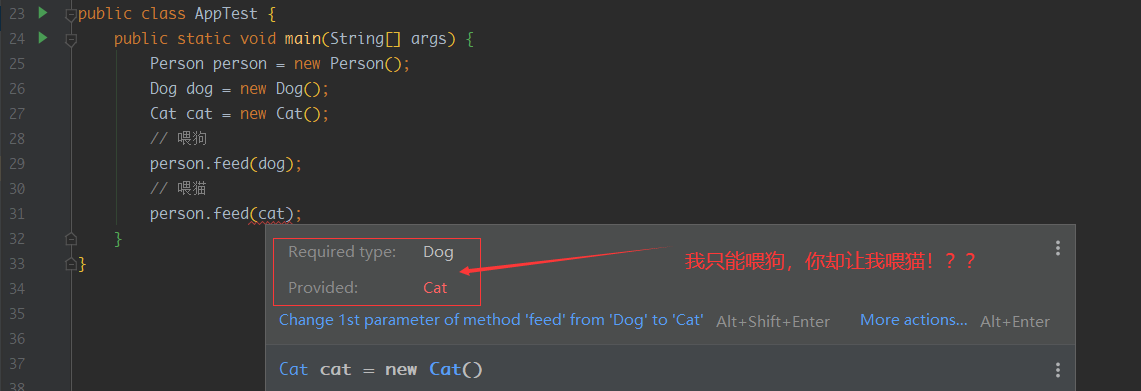
那怎么办呢?我直接重载一个方法,让Person类可以喂猫不就好了吗?
class Person {
public void feed(Dog dog) {
System.out.println("开始喂dog...");
}
public void feed(Cat dog) {
System.out.println("开始喂Cat...");
}
}
好家伙,这是不是为了应对变化直接改源码了?首当其冲的就是破坏了开闭原则,其次如果每次要多喂养一种动物就要去重载一个方法,这显然也不合理叭,这就是因为上层依赖于下层
读者可以先自己试着将这几个类的UML类图画出来,可能有的读者不太会画,这里补充一下UML类图的画法
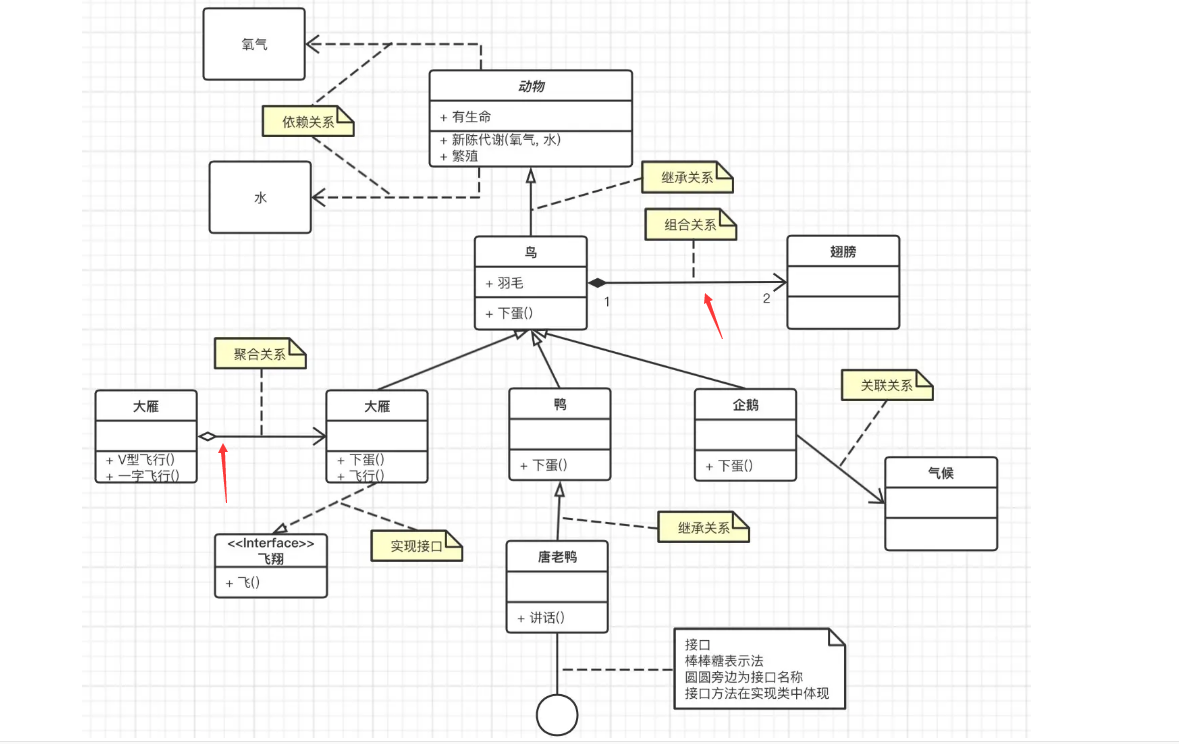
我们知道类和类之间的关系有:关联、依赖、泛化、实现(空心三角箭头的虚线表示实现,实现接口)
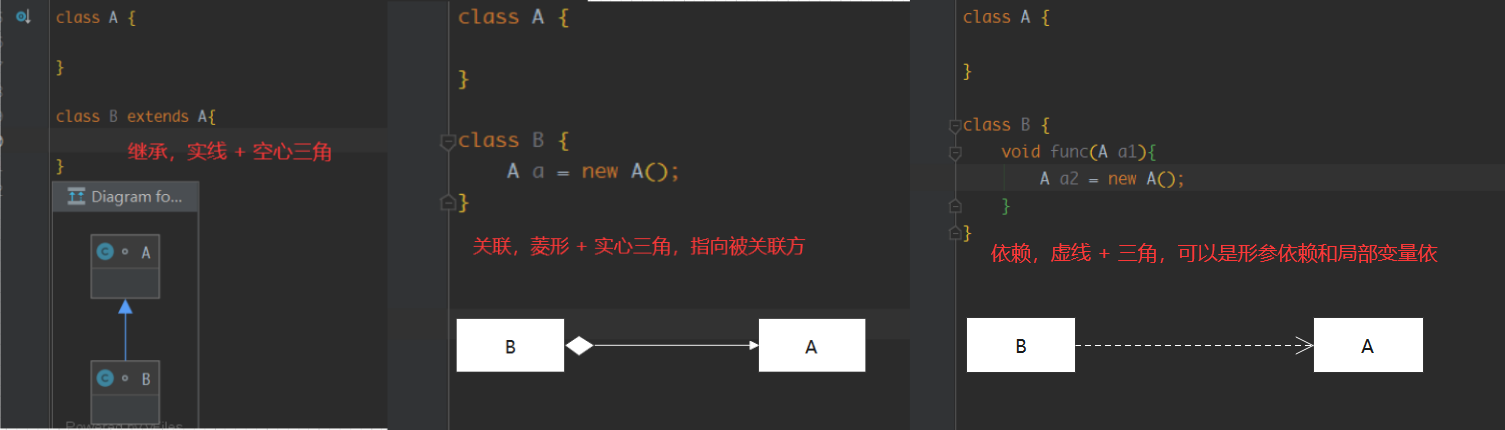
其中关联又可以分为组合 + 聚和,如果没有细分,可以画成实线 + 箭头,不用画菱形
- 组合关系是强关联,失去关联方,两者都不完整,例如大雁和翅膀,就是强关联,大雁不能失去翅膀
- 聚和是弱关联,失去关联方,被关联方依旧完整,例如雁群和大雁,失去一只大雁,不影响雁群整体
现在我们来画一下上面人喂动物的UML类图,由于动物作为形参传入人类中,所以明显这是依赖关系,我们用虚线三角画即可
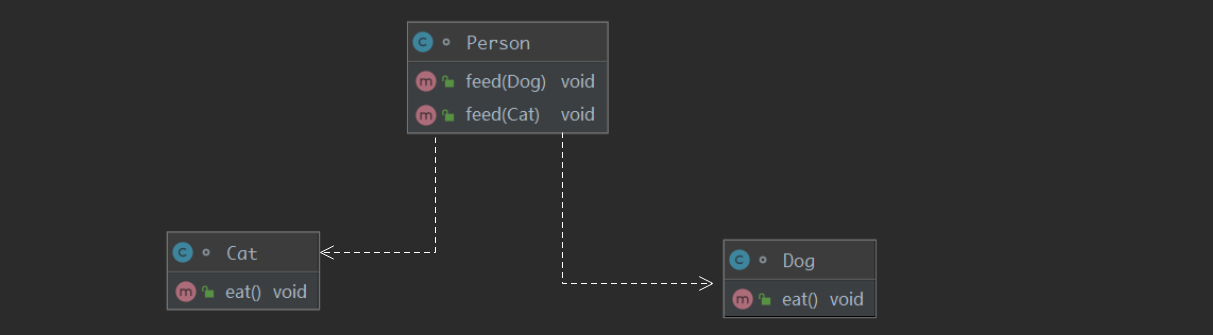
我们看出上面代码的问题,就是每当一个新的类需要依赖时,就要重载一个方法,这里就违反了依赖倒置原则,每当下层发生改变时,上层都要一起改变,这样的设计没有拓展性,我们不应该依赖于具体的类,而应该依赖于抽象的接口!
我们想要的结果是下层代码发生变化,对于上层来说是无感知的!代码也不需要改动,这就是依赖倒置的核心!
我们回过头来分析问题,我们人类的动作是什么?是喂养动物!不是喂狗、喂猫,狗和猫只是动物的实现!所以我们应该进行依赖倒置,依赖抽象不依赖实现,这里我们只需要依赖一个抽象的动物类或者接口即可
class Person {
public void feed(Animal animal) {
System.out.println("开始喂dog...");
}
}
interface Animal {
void eat();
}
class Dog implements Animal{
@Override
public void eat() {
System.out.println("狗啃骨头");
}
}
class Cat implements Animal{
@Override
public void eat() {
System.out.println("小猫吃鱼");
}
}
// ================================================================
public class AppTest {
public static void main(String[] args) {
Person person = new Person();
Dog dog = new Dog();
Cat cat = new Cat();
// 喂狗
person.feed(dog);
// 喂猫
person.feed(cat);
}
}
我们来看一下类图的变化:
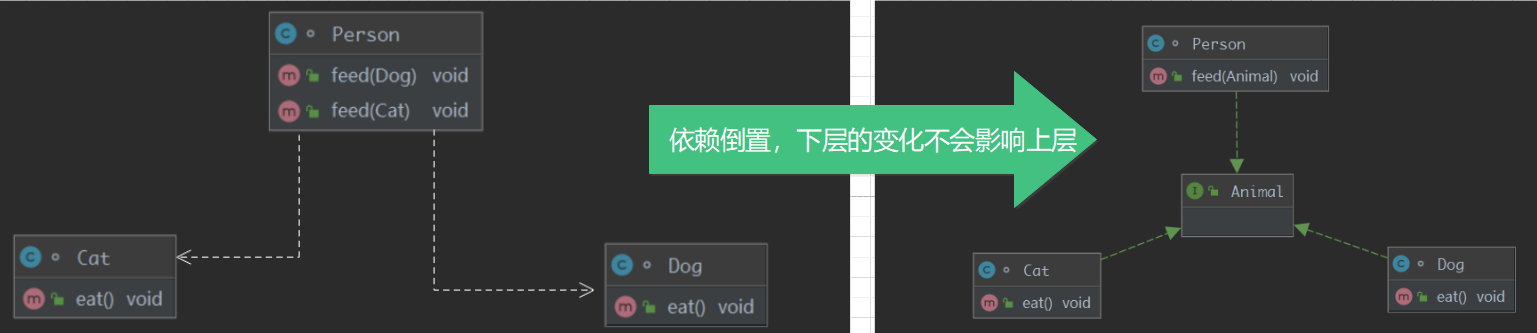
这里可能有的读者会有疑问,为什么下层变了,上层不知道要叫依赖倒置,就叫下层变了,上层不知道不行吗?
看上面的图!之前的箭头是向下指的,是依赖具体的实现,现在箭头倒置过来了,大家都依赖于抽象!这就叫依赖倒置,如果看不明白翻到上面再看一遍下来,好好体会这个倒置的作用。这样以来,不论怎么改变,只需要不断添加新的依赖关系依赖抽象即可,以不变应万变。这里读者再三强调,所以的设计原则核心思想都是一个字,变,都是为了以不变应万变
对上层来说,就是分层,解耦,就是一个分字
编码中我们时刻要注意的就是:
- 上层不应该依赖于下层
- 它们都应该依赖于抽象
其中这种思想在工作中生活中也有很多栗子,很多时候问题都是出现在太依赖某些东西了,当依赖的东西变化,自己就乱了
举几个栗子:
-
在软件开发公司,老板不能具体依赖一些人或者某些语言开发系统,例如java、go、csharp等等,如果产生依赖了就会导致如果现在会Java的跑了,公司没有会Java的了,只能更换架构体系,但是如果领导只管最终的结果,不管具体实现过程,那么矛盾就转移到下层了
-
例如在用人体系,老板不应该直接管理众多的员工,如果过度依赖某些员工,势必会造成问题,一个好的公司不是靠人,而是靠制度、靠规范,应该让所有人依赖制度,老板只需要管理好制度,就能管理好所有人!这就是依赖倒置,在生活中这就叫
画饼!一个大企业不可能去管理每个员工,但是只要管理好抽象的规则制度,让员工都遵守,就可能以不变应万变!!!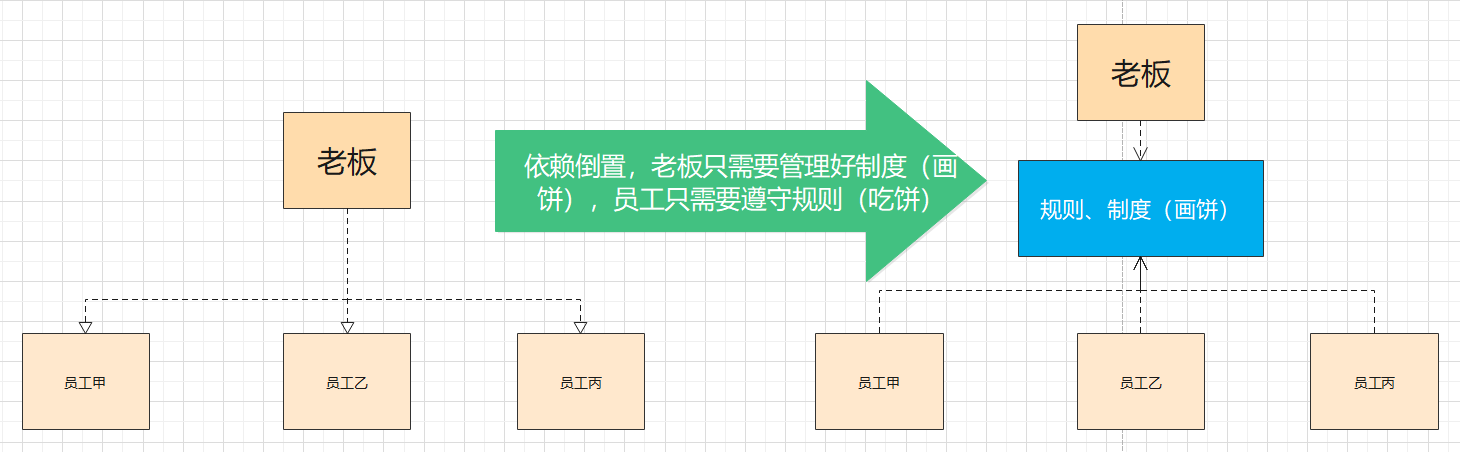
-
例如在教育孩子的时候不应该过分管控孩子的行为,不如给孩子设立目标或者崇高的理想,由外驱力转化为孩子的内驱力,这样才能达到更好的效果。当然这样的例子还有很多,这里就不举例了,再举例下去就变成哲学了
1.5 迪米特法则
迪米特法则(最少知道原则)(Demeter Principle)
为什么叫最少知道原则,就是说:一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立
- 一个类,对于其他类,要知道的越少越好,其实就是封装的思想,封装内部细节,向外暴露提供功能的接口
- 只和朋友通讯,朋友是指:
- 类中的字段
- 方法的参数
- 方法的返回值
- 方法中实例化出来的对象
- 对象本身
- 集合中的泛型
我们来看对于类的例子,现在我们有一个电脑类,里面有一些电脑关机时的操作,然后还有一个人类,里面有一个方法为关闭电脑,需要组合电脑类,并执行电脑类里面的方法
class Compute {
public void saveData() {
System.out.println("正在保存数据");
}
public void killProcess() {
System.out.println("正在关闭程序");
}
public void closeScreen() {
System.out.println("正在关闭屏幕");
}
public void powerOff() {
System.out.println("正在断电");
}
}
class Person {
Compute compute = new Compute();
public void shutDownCompute() {
compute.saveData();
compute.killProcess();
compute.closeScreen();
compute.powerOff();
}
}
这样看上去好像也没什么问题,但是现在变化来了,如果现在关机操作的步骤有几十上百项呢?难道我们要在shutDownCompute方法中去调用上百个方法吗?这里的问题就是:
- 对于
Person类而言,知道Compute中细节太多了 - 其实不需要知道这么多细节,只要知道关机按钮在哪里就行,不需要知道具体的关机流程
- 如果使用者在调用方法时的顺序出错,例如把关电和保存数据的顺序弄错,就容易导致问题
所以正确的方法就是尽量高内聚设计,隐藏实现细节,只暴露出单独的接口实现单一的功能
class Compute {
private void saveData() {
System.out.println("正在保存数据");
}
private void killProcess() {
System.out.println("正在关闭程序");
}
private void closeScreen() {
System.out.println("正在关闭屏幕");
}
private void powerOff() {
System.out.println("正在断电");
}
public void shutDownCompute() {
this.saveData();
this.killProcess();
this.closeScreen();
this.powerOff();
}
}
class Person {
Compute compute = new Compute();
public void shutDown() {
compute.shutDownCompute();
}
}
那么这个封装和暴露的火候该怎么掌握呢?我们接下来看看对于朋友而言的最少知道原则
-
如果对于作为
返回类型、方法参数、成员属性、局部变量的类,不需要过多的封装,应该提供应有的细节,由调用者自己弄清楚细节并承担异常的后果,这样由我们直接创造的对象,我们就能把它称为我们的朋友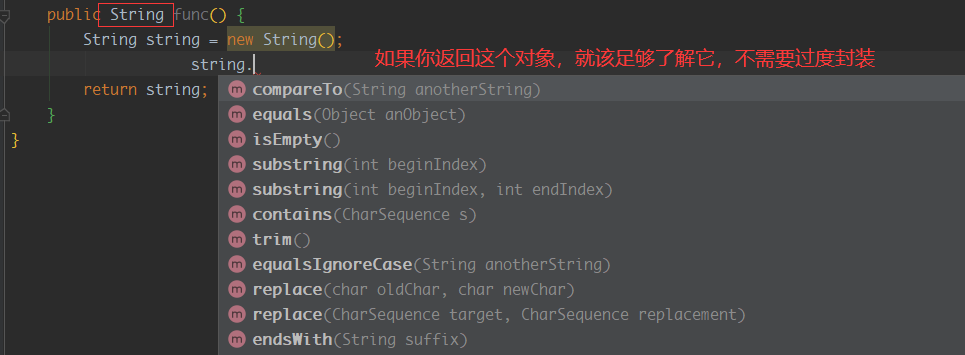
-
但是如果这个对象不是我们自己获得的,而是由被人提供的,就不是朋友,
即朋友的朋友并不是自己的朋友public class AppTest { public void func() { AppBean appBean = BeanFactory.getAppBean(); // 朋友的朋友就不是朋友了 appBean.getStr(); } } class BeanFactory { public static AppBean getAppBean() { return new AppBean(); } } class AppBean { public String getStr() { return ""; } }那么想要和这个
AppBean做朋友该怎么办呢?需要在系统里面造出许多小方法,将朋友的朋友变成自己的朋友,例如:public class AppTest { public void func() { AppBean appBean = BeanFactory.getAppBean(); // 朋友的朋友就不是朋友了 this.getStr(appBean); } /* 将朋友的朋友的细节转换为自己熟悉的方法 */ public String getStr(AppBean appBean){ return appBean.getStr(); } }有的同学可能觉得有点鸡肋这样,确实迪米特法则的缺点就是会制造出很多小方法,让代码结构混乱,所以有的时候适当违反一下也是可以的,但是
封装和暴露的思想我们一定要有,后面我们的门面模式和中介者模式其实也是基于迪米特法则的,读者先不要急,看到后面再回顾这一段,相信会有跟好的理解
1.6 里式替换原则
里氏代换原则(Liskov Substitution Principle)
里氏代换原则(Liskov Substitution Principle LSP)面向对象设计的基本原则之一,里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。
- 简单的来讲,任何能够用父类实现的地方,都应该可以使用其子类进行
透明的替换。替换就是子类对象替换父类对象- 子类对象替换父类后,不会有任何影响
- 是否有is-a的关系
- 有is-a关系后,要考虑子类替换父类后会不会出现逻辑变化
这里我们来看一下方法重写的定义:
- 方法重写是指:在子类和父类中,出现了返回类型相同、方法名相同、方法参数相同的方法时,构成方法重写
- 子类重写父类时,子类的访问修饰符不能比父类更加严格
- 子类重写父类时,不能比父类抛出更多的异常
如果我们故意在子类中抛出比父类更多的异常会怎么样呢?
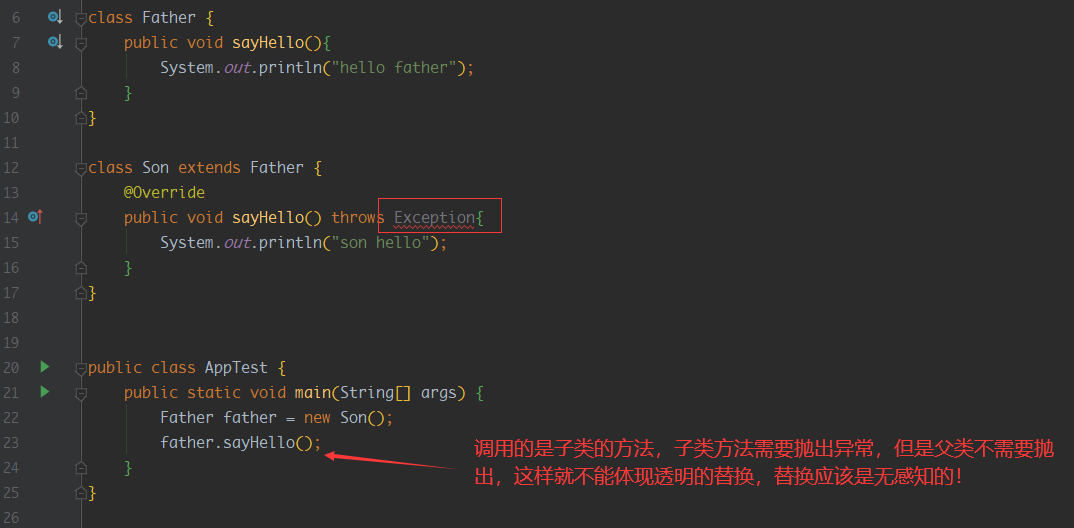
如果没有比父类更多的异常,父类现在在执行方法时就会进行catch,并且能够捕获子类中更少的异常,所以这样进行替换时,就不会影响代码的结构,做到透明、无感知
有很多的例子都可以用里式替换进行解释,著名的例子有:
- 鸵鸟非鸟问题
- 长方形正方形问题
1.7 组合优于继承原则
组合优于继承原则(Composite Reuse Principle)
组合优于继承原则强调的是在复用时要尽量使用关联关系,少用继承
- 组合,是一种强关联关系,整体对象和局部对象的生命周期是一样的,类似于大雁和翅膀的关系
- 整体对象负责局部对象的生命周期;
- 局部对象不能被其他对象共享;
- 如果整体对象被销毁或破坏,那么局部对象也一定会被销毁或破坏
- 聚和,它是一种弱关联,是 【整体和局部】之间的关系,且局部可以脱离整体独立存在,类似于雁群和其中一只大雁的关系
- 代表局部的对象有可能会被多个代表整体的对象所共享,而且不一定会随着某个代表整体的对象被销毁或破坏而被销毁或破坏,甚至代表局部的对象的生命周期可以超越整体
- 总而言之,组合是值的关联(Aggregation by Value),而聚合是引用的关联(Aggregation by Reference)
我们在之前又讲过,关联关系有两种,实心菱形的是组合、空心菱形的是聚和,如果不区分就用虚线指向,组合是作为成员变量作为另一个类的引用,聚和是作为形参或者局部变量作为另一个类的引用
组合大家在平时编码的时候一定经常使用,举一个简单的例子,如果我们现在要有链表实现队列应该怎么做呢?队列的特点就是先进先出,完全可以用链表实现,我们可以用继承关系来做:
public class Queue <E> extends LinkedList<E> {
/**
* 入队
*/
public void enQueue(E element){
this.add(element);
}
/**
* 出队
*/
public E deQueue(){
return this.remove(0);
}
}
我们发现这样并没有什么问题,队列类继承自链表类,并暴露自己提供给外界的方法,但是当我们调用这个Queue时就会发现问题:
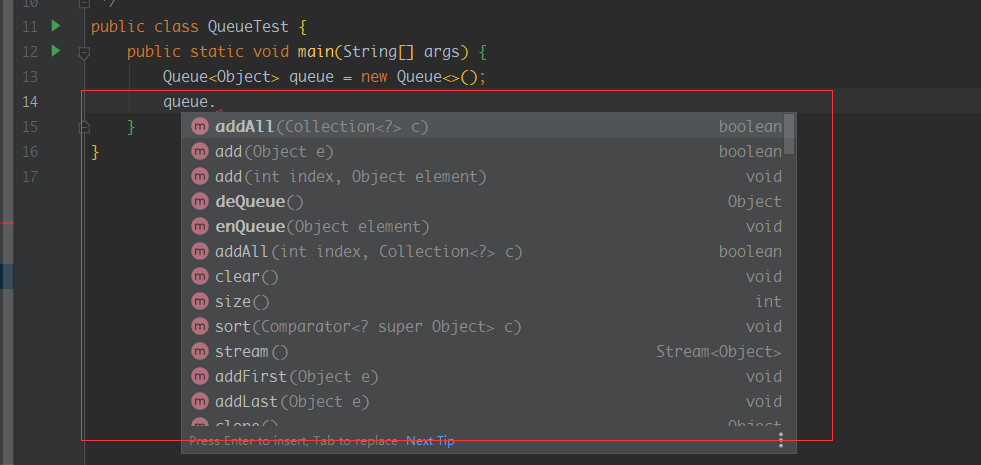
好家伙,我的Queue本来只需要入队和出队两个方法,但是居然有这么多细节的方法供我使用,这就违背了迪米特法则,一个类的内部实现应该不要提供给外界,只暴露该提供的方法,这就是继承的问题,继承复用破坏包装,因为继承将基类的实现都暴露给派生类
如果我们换成组合该怎么做呢?
public class Queue<E> {
// 成员变量 -> 组合关系
LinkedList<E> list = new LinkedList<>();
/**
* 入队
*/
public void enQueue(E element) {
list.add(element);
}
/**
* 出队
*/
public E deQueue() {
return list.remove(0);
}
}
所以如果我们仅仅只是为了复用代码,可以优先考虑组合,如果是为了实现多态,可以优先继承
我们也来看一个反例叭,其实在Java中有很多不合理的设计,例如Serializable接口,Date类等等,这里就讲一个java.util.Stack的糟糕设计
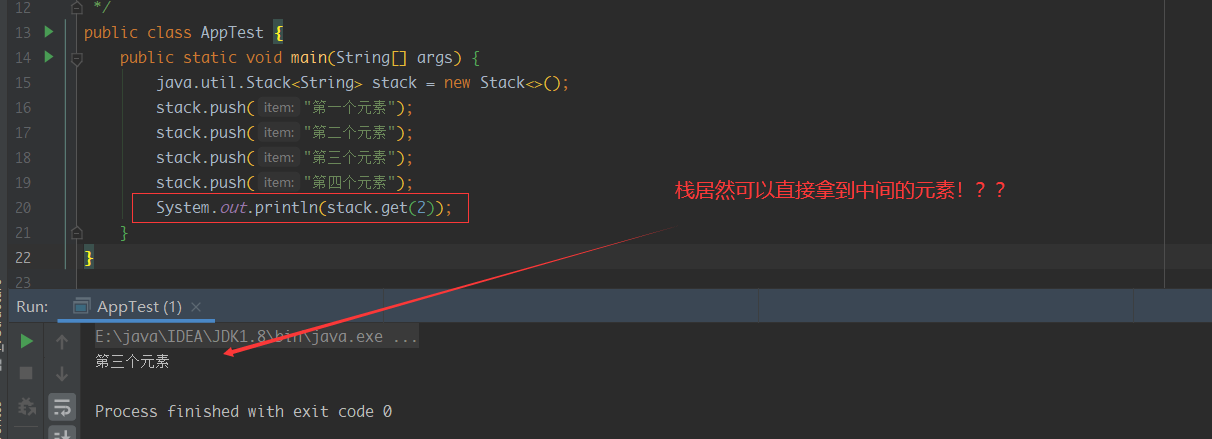
点进源码中看我们发现,原来是继承了Vector类,让其拥有了链表的能力,看着这个兄弟设计模式也没学好
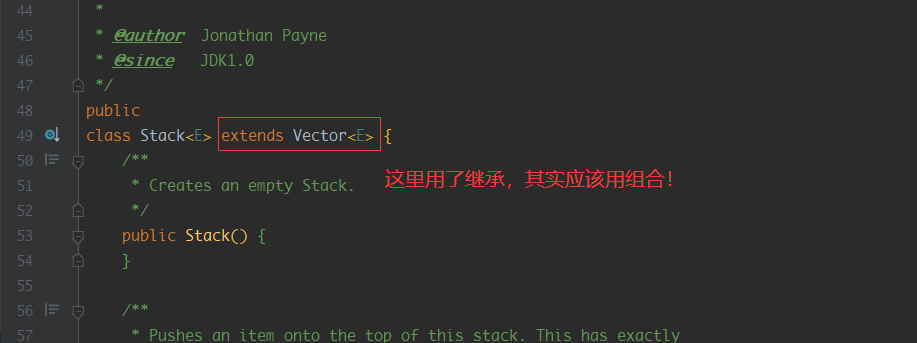
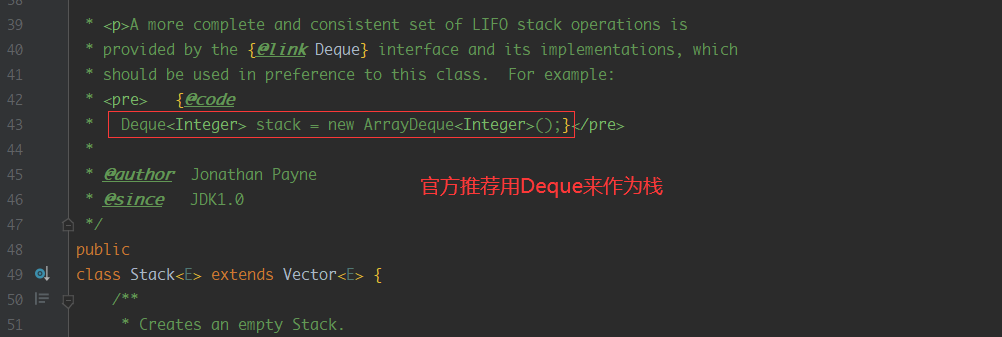
官方也意思到了这个设计不合理的地方,推荐我们使用Deque来实现栈
1.8 设计原则总结
其实我们看完了这些设计原则,就会发现其实都是为了应对不断变化的,在看一些源码中,例如Spring的源码、dubbo的源码、netty的源码中也是非常严谨的遵守这些开发规范的
2. 创建型模式
接下来我们来看看设计原则的最佳实践
设计模式的类型
根据设计模式的参考书 Design Patterns - Elements of Reusable Object-Oriented Software(中文译名:设计模式 - 可复用的面向对象软件元素) 中所提到的,总共有 23 种设计模式。这些模式可以分为三大类:创建型模式(Creational Patterns)、结构型模式(Structural Patterns)、行为型模式(Behavioral Patterns)。当然,我们还会讨论另一类设计模式:J2EE 设计模式。
| 序号 | 模式 & 描述 | 包括 |
|---|---|---|
| 1 | 创建型模式 这些设计模式提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象。这使得程序在判断针对某个给定实例需要创建哪些对象时更加灵活。 | 工厂模式(Factory Pattern)抽象工厂模式(Abstract Factory Pattern)单例模式(Singleton Pattern)建造者模式(Builder Pattern)原型模式(Prototype Pattern) |
| 2 | 结构型模式 这些设计模式关注类和对象的组合。继承的概念被用来组合接口和定义组合对象获得新功能的方式。 | 适配器模式(Adapter Pattern)桥接模式(Bridge Pattern)过滤器模式(Filter、Criteria Pattern)组合模式(Composite Pattern)装饰器模式(Decorator Pattern)外观模式(Facade Pattern)享元模式(Flyweight Pattern)代理模式(Proxy Pattern) |
| 3 | 行为型模式 这些设计模式特别关注对象之间的通信。 | 责任链模式(Chain of Responsibility Pattern)命令模式(Command Pattern)解释器模式(Interpreter Pattern)迭代器模式(Iterator Pattern)中介者模式(Mediator Pattern)备忘录模式(Memento Pattern)观察者模式(Observer Pattern)状态模式(State Pattern)空对象模式(Null Object Pattern)策略模式(Strategy Pattern)模板模式(Template Pattern)访问者模式(Visitor Pattern) |
| 4 | J2EE 模式 这些设计模式特别关注表示层。这些模式是由 Sun Java Center 鉴定的。 | MVC 模式(MVC Pattern)业务代表模式(Business Delegate Pattern)组合实体模式(Composite Entity Pattern)数据访问对象模式(Data Access Object Pattern)前端控制器模式(Front Controller Pattern)拦截过滤器模式(Intercepting Filter Pattern)服务定位器模式(Service Locator Pattern)传输对象模式(Transfer Object Pattern) |
2.1 工厂设计模式
工厂设计模式属于创建型模式,创建型模式的核心是隐藏细节,并创建实例,我们看工厂模式中的模式都是能够向外提供类的实例对象的
其中工厂设计模式分为三种:
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
在讲工厂设计模式之前,我们先来看看一个合理的运用设计模式设计出来的软件架构应该是怎么样的,这也是面向接口编程的设计方式
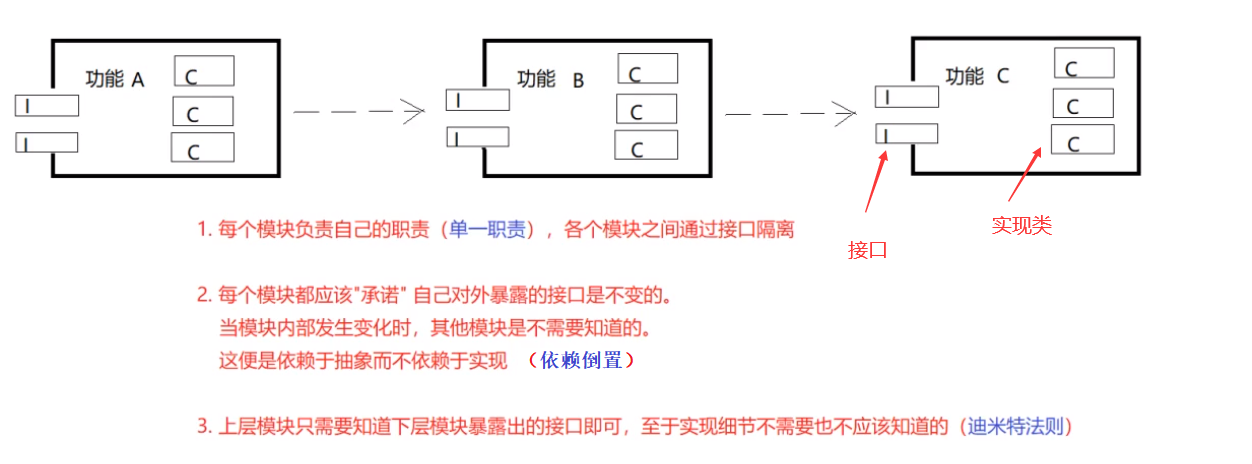
我们在面向接口编程中,模块和模块之间不能直接调用具体实现类,而是调用模块提供的接口,我们仔细想想在平时的编码中,有直接service层调用dao层的xxxDaoImpl的吗?显然没有,如果直接调用了也差不多该换下一份工作了,一般都是注入接口,让容器注入一个实现类
工厂模式的核心也是隐藏内部实现,对外暴露接口实现具体逻辑,我们来看看工厂模式中的几个重要概念:
- 产品:就是具体的产品,例如下面代码中的
Hamburger - 抽象产品:产品的抽象,例如
Food - 产品簇:这个概念在抽象工厂中在场景中再解释
- 产品等级:同上
我们来看一个简单的例子,来理解上面的几个概念,另外在学习设计模式的时候一定要清醒的认识到,为什么要有设计模式,为了应对变化,以不变应万变,这里还有两个概念,就是我们习惯于把功能提供者称为作者,把我们这些API调用工厂师叫做用户
// 作者做的抽象产品
interface Food{
void eat();
}
// 作者做的具体产品
class Hamburger implements Food{
@Override
public void eat() {
System.out.println("吃汉堡包...");
}
}
// 用户的业务逻辑
public class AppTest {
public static void main(String[] args) {
Food food = new hamburger();
food.eat();
}
}
本来没有什么问题的,但是我一开始就提过,我们要应对这个不断变化的世界,现在变化来了,由于某些原因,作者把原来提供的类名改了,例如把hamburger改为hamburger2,这时候怎么办,是不是我们也要跟着改!!!
跟我说,什么叫耦合?一个改了另一个也要改,这就叫耦合;什么叫解耦?一个改了另一个不需要改,这就叫解耦!
有人说怎么可能,作者好好地没事会去该类名,闲得慌??你别说,笔者在项目中还经常遇到一些作者瞎改类名又不提示用户的,hutool包是我们常用的工具包,但是有一些类名在包升级的时候直接修改,而且完全没有做兼容处理,有一次团队项目打包失败了,最后定位问题发现,这个作者之前类名单词拼写错误了,然后升级版本的时候直接改了类名,导致我们升级版本导入一个不存在的类,导致项目出现问题,记得当时我们都说这个作者是个坑爹玩意,一看就是设计模式没学好

读者可以看看这个作者违反了什么原则?违反了开闭原则,正确的做法应该是给错误的类加过时的标记,重新写一个
我们来总结一下:
- 这样的设计非常的脆弱,为什么呢?只要作者修改了具体产品的类名,那么客户端就要一起修改,这样的代码就是耦合的
- 我们希望的效果是,无论服务端客户端如何修改,客户端代码都应该
无感知,而不用去进行修改
那么我们如何进行改进呢?针对服务端代码一旦修改,客户端代码也要修改的问题,我们直接使用简单工厂设计模式
2.1.1 简单工厂模式
工厂模式(Factory Pattern)
这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。它的本质就是通过传入不同的参数达到多态的目的
优点:
- 一个调用者想创建一个对象,只要知道其名称就可以了。
- 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
- 屏蔽产品的具体实现,调用者只关心产品的接口。
缺点:
- 用户需要去记忆具体产品和常量之间的映射关系,例如:
FoodNumberEnum.HAMBURGER -> hamburger- 如果具体产品非常多,在简单工厂里面映射关系会非常多
- 最重要的是,当用户需要拓展新产品时,就需要在作者的工厂源码中添加映射关系,违反
开闭原则
首先我们要弄清楚一个问题,简单工厂设计模式是谁进行具体编码的?是我们(用户)去写吗?还是作者去写,其实是应该由作者去写
假设我们现在是这个作者,我们发现之前的设计确实不太合理,现在要进行优化,我们就可以这样写:
// 作者做的抽象产品
interface Food {
void eat();
}
// 作者做的具体产品
class hamburger implements Food {
@Override
public void eat() {
System.out.println("吃汉堡包...");
}
}
class hamburger2 implements Food {
@Override
public void eat() {
System.out.println("这是作者修改后的汉堡包...");
}
}
class FoodFactory {
public enum FoodNumberEnum {
HAMBURGER(1001, "汉堡包"),
HAMBURGER2(1002, "修改后的汉堡包"),
;
private final Integer foodNumber;
private final String describe;
FoodNumberEnum(Integer foodNumber, String describe) {
this.foodNumber = foodNumber;
this.describe = describe;
}
public Integer getFoodNumber() {
return foodNumber;
}
public String getDescribe() {
return describe;
}
public static FoodNumberEnum getByType(int type) {
for (FoodNumberEnum constants : values()) {
if (constants.getFoodNumber() == type) {
return constants;
}
}
return null;
}
}
public static Food getFood(FoodNumberEnum foodNumberEnum) {
Food food = null;
switch (FoodNumberEnum.getByType(foodNumberEnum.getFoodNumber())) {
case HAMBURGER :
food = new hamburger();
break;
case HAMBURGER2 :
food = new hamburger2();
break;
default:
break;
}
return food;
}
}
// 用户的业务逻辑
public class AppTest {
public static void main(String[] args) {
Food food = FoodFactory.getFood(FoodFactory.FoodNumberEnum.HAMBURGER);
food.eat(); // 输出吃汉堡包...
}
}
我们来看这样做的好处是什么:
- 之前是我们直接创建对象,依赖于作者的代码;现在是依赖于工厂,由工厂创建对象
- 如果作者对原来的实现类做出了修改,也必须修改工厂里面的代码,注意,这里是
作者进行修改,而不是用户修改,这样就做到了依赖倒置,完成了解耦,这样用户代码不用做出任何修改 - 之前由于作者修改代码导致用户也要修改其实还违背了
迪米特法则,因为我们被迫去了解了作者的实现,其实我们是不关心如何实现的,我们只需要一个接口实现我们想要的功能即可!!!
可能有又有杠精要问了,要是作者把枚举也改了怎么办?这不是还是要改客户端代吗,我我我???直接好家伙

请杠精看看Spring中的工厂模式是怎么做的,后面笔者也会分析源码,我们在Spring中,不是一直写这样的代码吗???
@Component
public class XXX {
@Autowired(required = false)
private XXXBean xxxBean;
}
请问,这样做不管实现类怎么修改,只要注入IOC容器,我难道不能直接注入接口中吗?这就叫解耦,面向接口编程
我们总结一下简单工厂的优点:
- 把具体产品的类名,从客户端代码中解构出来了,服务端如果修改了服务端类名,客户端也不知道
- 这便符合了面向接口编程的思想,这里注意,这里的接口并不特指
interface,而是指下层给上层暴露的东西,可以是一个方法、一个接口、甚至是一个工厂,并且这些接口必须稳定,绝对不能改变
**那么缺点呢?**好像也没啥缺点感觉,又解耦了,又隐藏细节了,这里又不得不提一直提到的变字了,学习设计模式,我们要将变字贯穿整个学习过程
- 客户端不得不死记硬背那些枚举类和产品之间的映射关系,比如
FoodNumberEnum.HAMBURGER -> hamburger - 如果有成千上万个产品,那么
简单工厂就会变得十分的臃肿,造成映射关系爆炸 - 最重要的是如果变化来了,如果客户端需要拓展产品,首先我们不能改源代码(违反开闭原则),我们只能搞一个实现类实现自己的逻辑,但是工厂中又没有映射关系让我们创建这个实例,我们又得去修改工厂的源码,又违背了开闭原则,同时最重要的是,你这是去改别人提供的jar包呀我的天,你觉得你能看到被人的源代码吗?你能修改吗?????显然不能,那怎么解决呢?这就引出第二个工厂模式:
工厂方法设计模式 - 有的同学可能会觉得自己拓展的类,自己new一个不就好了,还改什么源代码?讲的有道理,但是如果你也是作者呢?你写的拓展是要给别人使用的呢?难道让读者去new一个你的实现类,这不违背
迪米特法则了吗?用户只想要一个具体的实现,你现在要让用户去找你的实现类,这合理吗?这不合理,我们直接看工厂方法设计模式是怎么解决的
最后来画一下类图,我们学设计模式,一定要能熟练画出类图
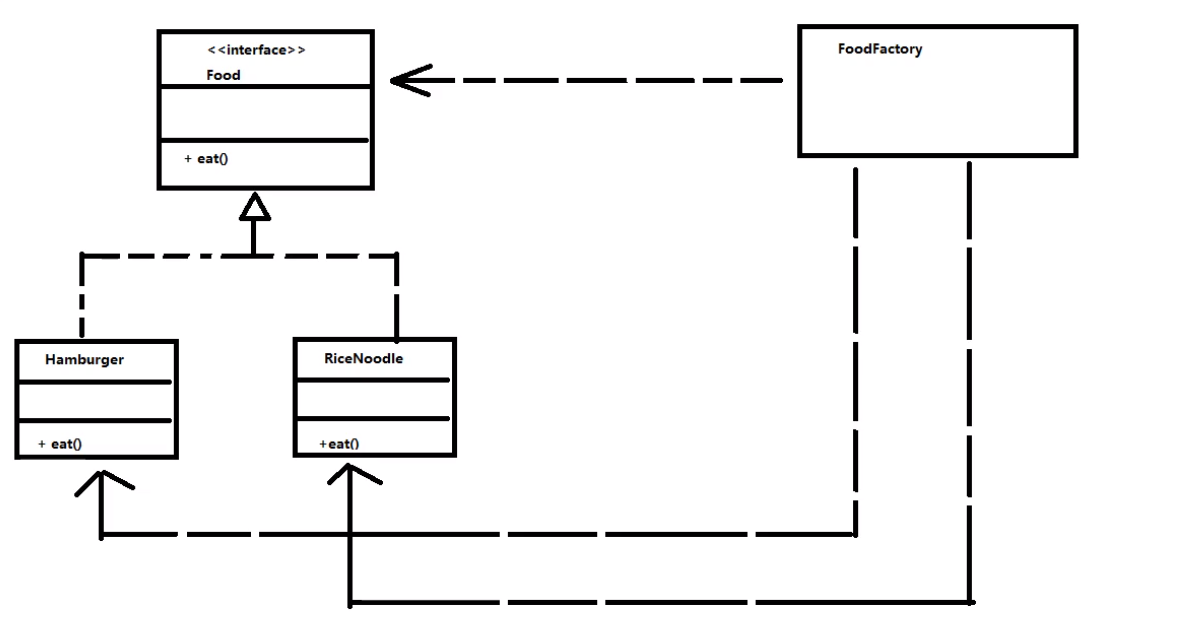
总结:

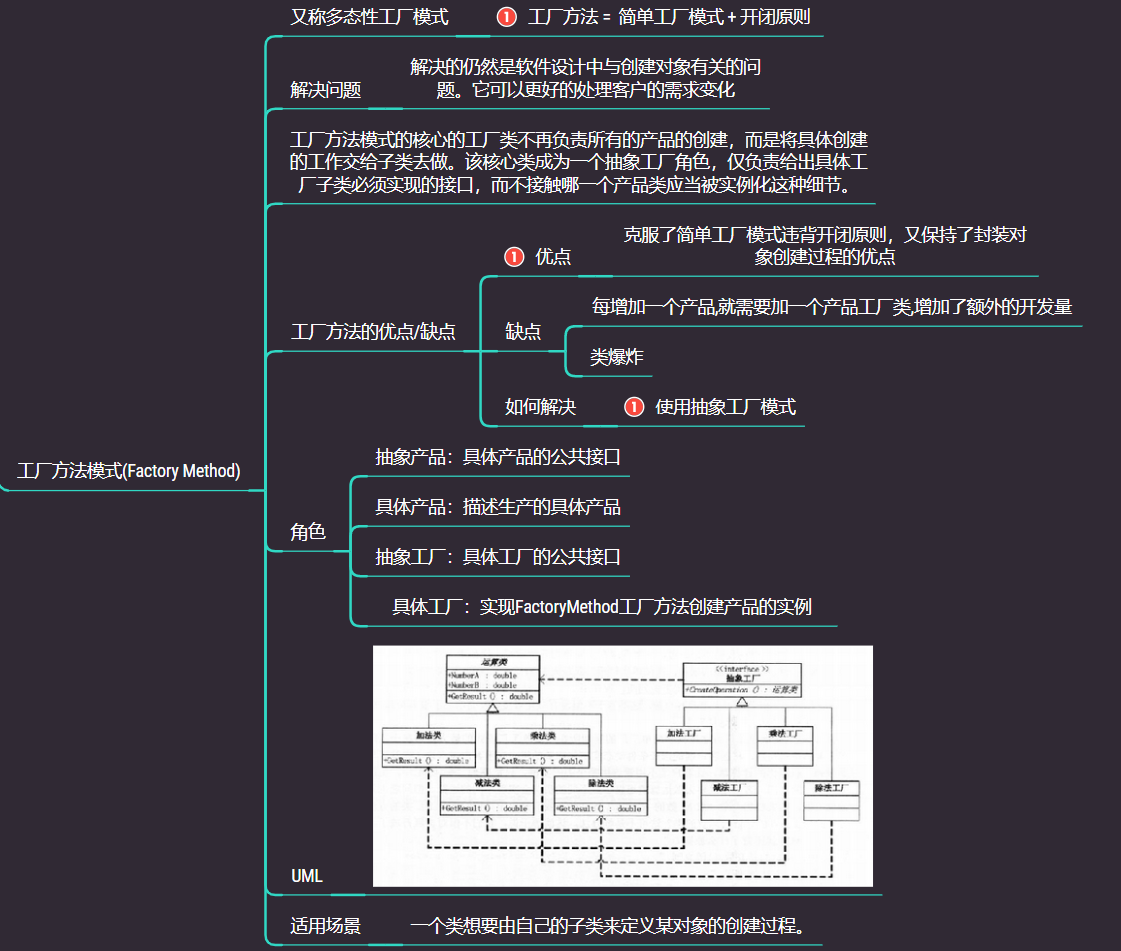
2.1.2 工厂方法模式
我们回顾一下上面简单工厂产生的问题,就是简单工厂只能提供作者提供好的产品,我们无法对产品进行拓展
工厂方法
定义一个用于创建产品的接口,由子类决定生产什么产品
- 坏处: 加一个类,需要加一个工厂,类的个数成倍增加,增加维护成本,增加系统抽象性和理解难度
- 好处: 符合开闭原则
总结:简单工厂模式 + 开闭原则 = 工厂方法
我们来改造一下上面有问题的代码,我们现在不将工厂写死,而是面向抽象编程,将工厂定义为一个接口,在作者的代码中提供一些基本的实现,例如创建Hamburger、RichNoodle的实现
// 作者做的抽象产品
interface Food {
void eat();
}
// 作者做的具体产品
class Hamburger implements Food {
@Override
public void eat() {
System.out.println("吃汉堡包...");
}
}
class RichNoodle implements Food {
@Override
public void eat() {
System.out.println("过桥米线");
}
}
/** 定义工厂的接口 **/
interface FoodFactory {
Food getFood();
}
class HamburgerFactory implements FoodFactory {
@Override
public Food getFood() {
return new Hamburger();
}
}
class RichNoodleFactory implements FoodFactory {
@Override
public Food getFood() {
return new RichNoodle();
}
}
public class App {
public static void main(String[] args) {
// 拿到产生产品的工厂
FoodFactory foodFactory = new HamburgerFactory();
// 创建对应的产品
Food food = foodFactory.getFood();
food.eat();
}
}
我们会发现我们将工厂作为接口暴露之后就有一个好处,如果我们想要新增加一个产品,我们不需要去修改原来的产品,而是通过继承Food创建产品类,再通过暴露的工厂接口创建工厂,再来实例化我们需要的产品,具体实现为:
/** 新的产品 **/
class PorkFeetRice implements Food{
@Override
public void eat() {
System.out.println("吃猪角饭...");
}
}
/** 生产猪角饭的工厂 **/
class PorkFeetRiceFactory implements FoodFactory{
@Override
public Food getFood() {
return new PorkFeetRice();
}
}
public class App {
public static void main(String[] args) {
// 拿到产生产品的工厂
FoodFactory foodFactory = new PorkFeetRiceFactory();
Food food = foodFactory.getFood();
food.eat();
}
}
我们可以看到,我们通过提供的工厂接口,并没有修改之前的工厂逻辑,又进行了拓展,并且新的产品和工厂实现类都是我们自己创建的,符合开闭原则
我们来总结一下工厂方法模式的优点:
- 仍然具有简单工厂的优点,服务端修改了生产产品的逻辑时,用户端无感知
- 因为产品和工厂都是拓展出来的,所以不需要修改原来的代码,只需要创建一个新的产品和工厂即可
但是我们也有发现这样好像怪怪的,感觉就是暴露了个接口而已,读者可能会有以下的疑问:
- 虽然说好像不管是简单工厂也好,工厂方法也罢,虽然都做到了和具体实现解耦,用户不用关注实现是否发生了改变,但是,反观我们现在的代码,好像还在依赖于具体的工厂,说的就是上面的
PorkFeetRiceFactory,如果我们每生产一种产品,都要去知道这种产品对应的工厂,这又违反了迪米特法则,并且如果如果作者如果把工厂名字写错了,又会出现上面的问题 - 感觉折腾了一圈,又回到了原点,之前是依赖于具体的实现,现在是依赖具体的工厂,还是耦合的关系
我们来解释一下上面的两个问题:
- 首先,既然作者已经对外暴露了接口,那么作者有义务保存接口的稳定,不能出现改接口名的行为(或弃用)
- 其次工厂模式还可以隐藏一个实例创建的过程,学过spring等框架的同学就会知道,
在框架中一个实例的创建并不只是简简单单new那么简单,可能还会牵涉到容器生命周期以及一些解析bean的操作,显然会复杂很多,所以工厂模式还帮我们隐藏了细节、封装了代码,至于具体要使用那个工厂,是我们应该去了解的,毕竟每个工厂提供产品都会不同 - 很多问题现在简单的业务下并不是问题,但是请不要忘记
变这个字,我们的代码为什么要分一层又一层,就是为了能够在之后改变后的业务场景依旧能够使用,如果读者还有问题,请复习复习Spring IOC容器的设计,如果没有工厂,IOC容器如果做到解析那么多注解,如何完成依赖注入,如果完成各种Spring预留的拓展接口,如果完成Bean的声明周期
总结一下缺点:
-
每一个层级的产品的产品都需要对应一个产品,不仅增加了编码的负担,还可能产生
类爆炸的现象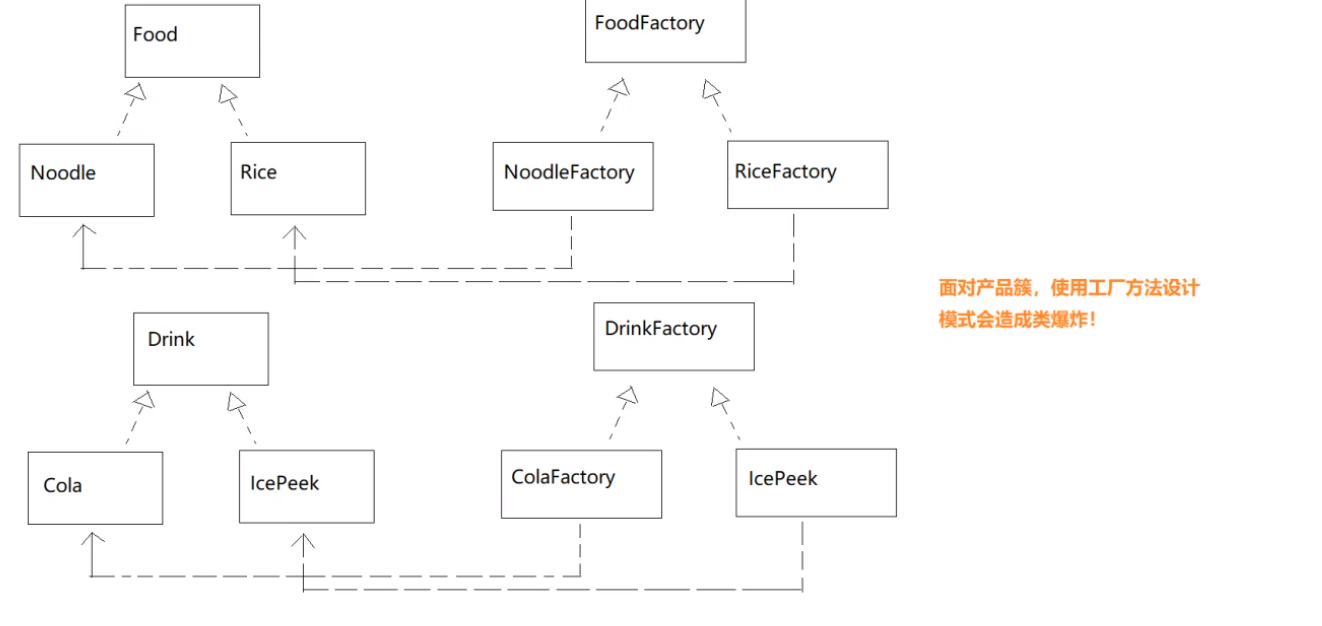
我们现在来画一下工厂方法模式的UML类图:
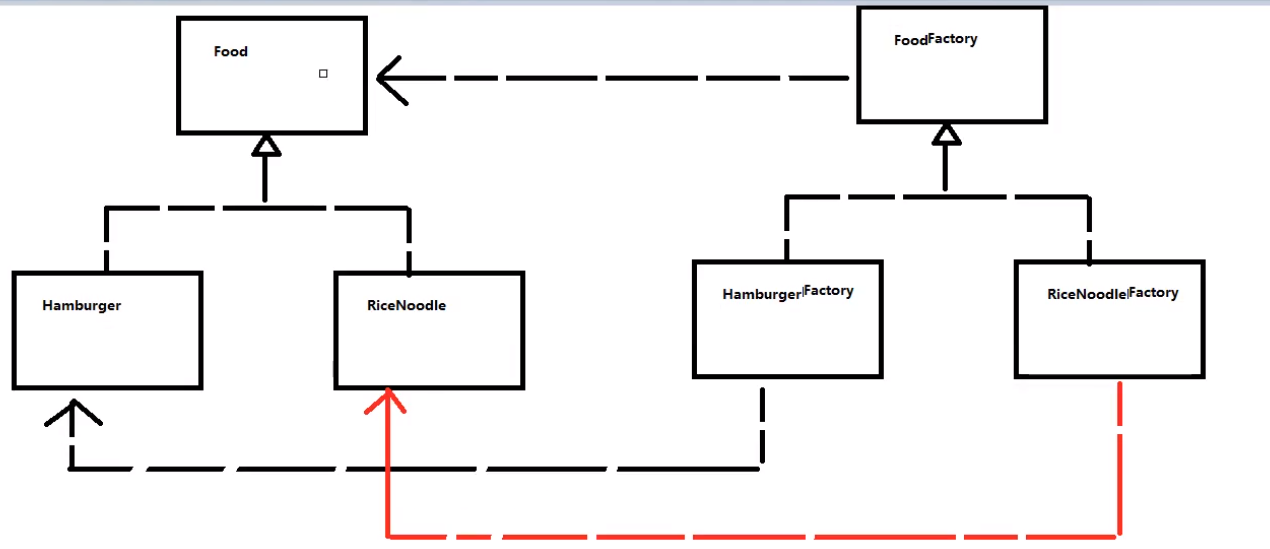
最后总结一下:
2.1.3 抽象工厂
抽象工厂模式
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象
优点:解决了工厂方法模式中类爆炸的问题,同时拥有其可拓展性的优点
缺点:产品族扩展非常困难,要
增加或删除一个系列的某一产品,既要在抽象的工厂里加代码,又要在具体的里面产品加代码,违背开闭原则
我们来后顾一下前面的两种工厂模式的缺点
- 简单工厂:耦合与具体的工厂实现,没有良好的拓展性
- 工厂方法:会产生类爆炸的问题,每一个产品类都需要对应的工厂,代码臃肿
我们现在要通过工厂方法设计量类产品的生产,分别是食物Food、饮料Drink,其中食物有三种,饮料有两种,我们会发现食物需要定义一个接口,三个具体产品类,一个抽象工厂类,三个具体工厂类;饮料需要定义一个接口,两个具体产品类,一个抽象工厂类,两个具体工厂类,一共14个类,我就想要产生五种类,好家伙,按照工厂方法的写法,直接写出14个类了
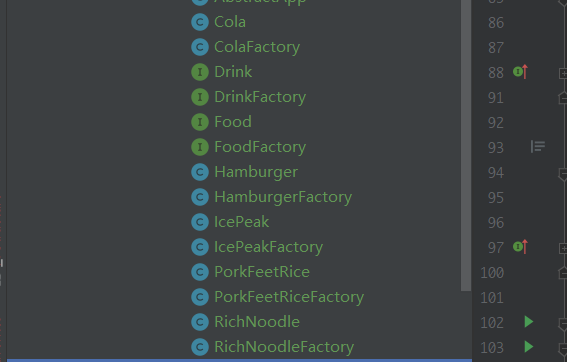
/****************** 抽象产品 *********************/
// 食物抽象类
interface Food {
void eat();
}
// 饮料抽象类
interface Drink{
void drink();
}
/****************** 具体产品 *********************/
// 食物的具体产品
class Hamburger implements Food {
@Override
public void eat() {
System.out.println("吃汉堡包...");
}
}
class RichNoodle implements Food {
@Override
public void eat() {
System.out.println("过桥米线");
}
}
class Cola implements Drink{
@Override
public void drink() {
System.out.println("喝可口可乐...");
}
}
class IcePeak implements Drink{
@Override
public void drink() {
System.out.println("喝冰峰...");
}
}
/****************** 抽象工厂类 *********************/
interface FoodFactory {
Food getFood();
}
interface DrinkFactory{
Drink getDrink();
}
/****************** 实例工厂类 *********************/
class HamburgerFactory implements FoodFactory {
@Override
public Food getFood() {
return new Hamburger();
}
}
class RichNoodleFactory implements FoodFactory {
@Override
public Food getFood() {
return new RichNoodle();
}
}
class ColaFactory implements DrinkFactory{
@Override
public Drink getDrink() {
return new Cola();
}
}
class IcePeakFactory implements DrinkFactory{
@Override
public Drink getDrink() {
return new IcePeak();
}
}
/*************** 新拓展的产品和工厂 **********************/
class PorkFeetRice implements Food{
@Override
public void eat() {
System.out.println("吃猪角饭...");
}
}
/** 生产猪角饭的工厂 **/
class PorkFeetRiceFactory implements FoodFactory{
@Override
public Food getFood() {
return new PorkFeetRice();
}
}
public class AbstractApp {
public static void main(String[] args) {
// 拿到产生产品的工厂
FoodFactory foodFactory = new PorkFeetRiceFactory();
Food food = foodFactory.getFood();
food.eat();
}
}
上面的代码就是工厂设计模式,其实工厂设计模式到抽象工厂只有一步之遥,我们会发现上面导致类爆炸的原因就在于太多工厂类的接口了,那我们就将工厂类的接口再进行抽象,例如食物和饮料的工厂接口统一进行抽象,再将各自的实例工厂也进行合并
/****************** 抽象工厂类 *********************/
interface AbstractFactory {
Food getFood();
Drink getDrink();
}
/****************** 实例工厂类 *********************/
class KFCFactory implements AbstractFactory {
@Override
public Food getFood() {
return new Hamburger();
}
@Override
public Drink getDrink() {
return new Cola();
}
}
显然这样通过抽象 + 组合的方式,这样就可以减少一些类的产生
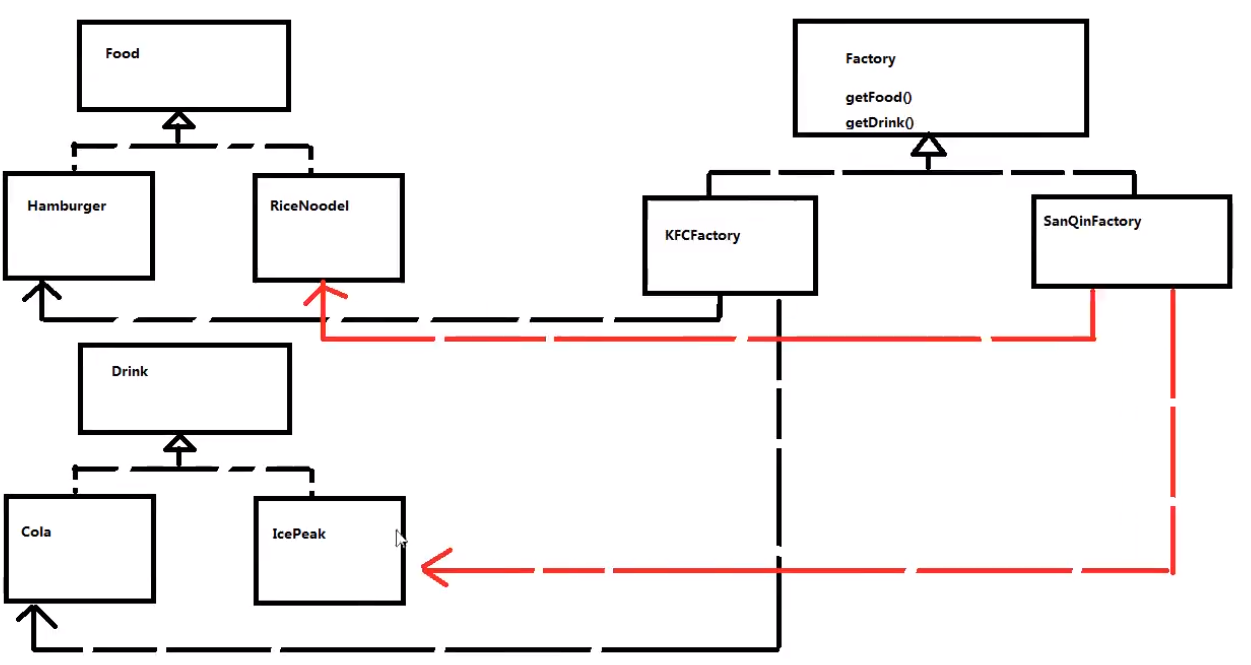
这样做的优点是就是在拥有工厂方法模式的优点下可以有效减少类的产生
缺点是好像在一个工厂类绑定死了具体的产品,例如KFCFactory -> Hamburger + Cola,我们为什么在这个工厂生成这两种产品
现在我们补充一下上面没有提到的两个概念:
-
产品簇:多个有内在联系或有逻辑关系的产品,例如上面的KFC套餐就固定为
Hamburger + Cola,这里就组成一个产品簇 -
产品等级:其实要弄清楚产品的等级我们可以看下面的图,
产品等级就是指由一个接口或者父类泛化的子类,例如各种饮料、各种电冰箱,而产品簇就是指由一个工厂生产的产品,看下图中美的生产的产品,这些就组成一个产品簇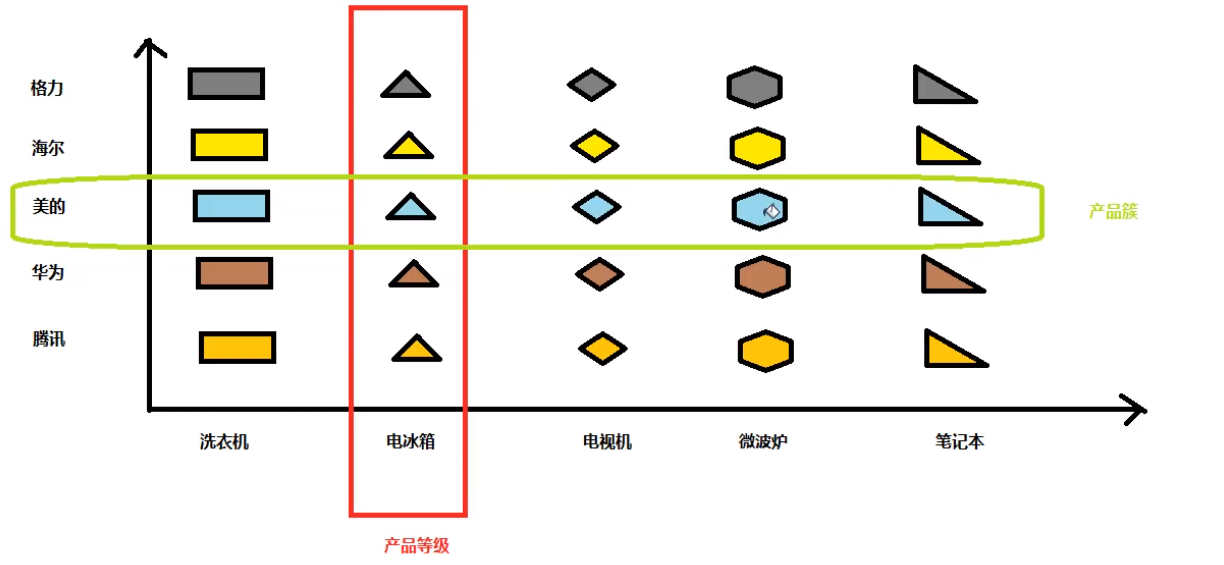
我们可以看到如果要生产上面的25个具体产品,一共需要多少个抽象产品,多少个抽象工厂?都是五个;如果是工厂方法则需要25个类,可以看到通过不断组合的方式,可以大大减少抽象产品类和抽象工厂类的创建
👀👀👀 现在让我们想一想这样的设计有什么问题没有?我们好好想一想
-
新增产品簇:产品如果现在新增了一个工厂
京东,那么我们只需要写一个京东的抽象工厂类,在写五个产品类分别继承上图中的抽象产品类,再加到自己的工厂类中,符合开闭原则 -
新增产品等级:如果我们需要新加一个手机的
产品等级呢?想想我们该如何添加,首先写一个抽象产品类,然后写??等等,好像发现写不下去了叭,怎么好像又需要在其他的工厂里面添加自己的产品类??又违反了开闭原则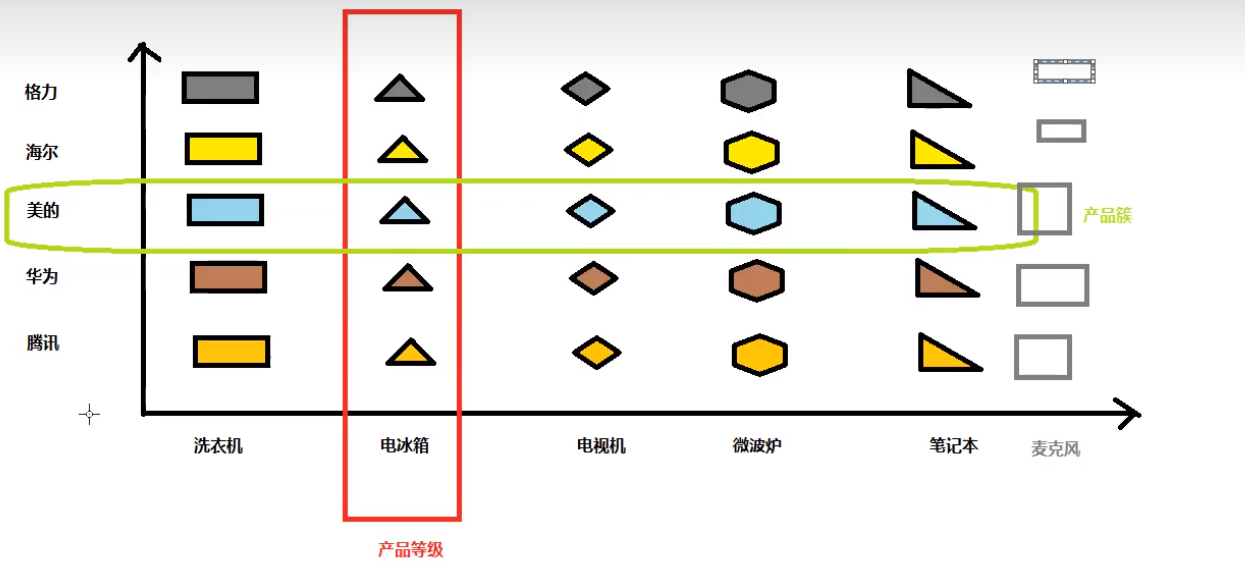
🎯总结抽象工厂的缺点:
- 当产品等级发生改变时(增加、减少),都会引起之前工厂代码的修改,违背开闭原则
所以设计模式有优点的同时也一定都有自己的局限性,我们要看场景来使用具体的工厂模式,笔者在下一节总结中进行分析
抽象工厂总结:
2.1.4 工厂模式总结
| 工厂方法 | 优点 | 缺点 |
|---|---|---|
| 简单工厂 | 隐藏了类创建的细节,只需要类的标识就能创建一个类(多态) | 产生很多映射关系;当添加产品时违反开闭原则 |
| 工厂方法 | 符合开闭原则(简单工厂模式 + 开闭原则 = 工厂方法) | 加一个类,需要加一个工厂,类的个数成倍增加,增加维护成本,增加系统抽象性和理解难度 |
| 抽象工厂 | 解决了工厂方法模式中类爆炸的问题,同时拥有其可拓展性的优点 | 产品等级扩展非常困难,会违反开闭原则 |
| 工厂方法 | 适用场景 |
|---|---|
| 简单工厂 | 产品不扩充,简单工厂最好 |
| 工厂方法 | 产品经常要拓展(产品簇与产品等级) |
| 抽象工厂 | 当产品等级固定,且产品簇需要拓展时 |
看了这么多好像这些工厂模式都不是我们心中最想要的结果,我们要的是既想马儿跑,又不想马儿吃草,即又不想多写代码,又想拥有良好的拓展性,那么这样的方法有吗?当然有。Spring就帮我们解决了,想想Spring是如何帮我们解决这个问题的,这将在下一节中揭晓谜底
2.1.5 Spring中的工厂模式
上面分析了这么久,还是不能满足我们好吃懒做既想马儿跑,又不想马儿吃草的需求,我们的目标是,既不能写过多的代码,就像工厂方法中类爆炸一样,又想要极致的拓展性,不能像抽象工厂一样不能添加产品等级
接下来让我们看看Spring中是如何解决的叭,可能很多同学平时框架用的爽,却根本不知道框架导致帮我们解决了什么问题,也不知道怎么解决的,这就导致一看源码就表示看不懂,很多面试题看了很多遍又会忘记,其实归根结底还是不理解,不会用,文章一开始我就讲过,最厉害的武功应该是忘记招式,无招胜有招!
直接揭晓答案叭,既想马儿跑,又不想马儿吃草的方案是:动态工厂 + 反射
当然并不是Spring中没有用其他的工厂,当然也用到了,像静态工厂(简单工厂)也运用到了,并且更多的不是一种设计模式使用,而是多种,例如:策略设计模式 + 工厂模式 + 模板方法模式
首先从
BeanFactory这个顶层工厂接口说起,BeanFactory定义的是IOC容器最基本的规范可以说
BeanFactory是 Spring 的心脏。它就是 Spring IoC 容器的真面目。Spring 使用 BeanFactory 来实例化、配置和管理 Bean。
相信被面试过BeanFactory面试题的同学对下面的张图一定很熟悉
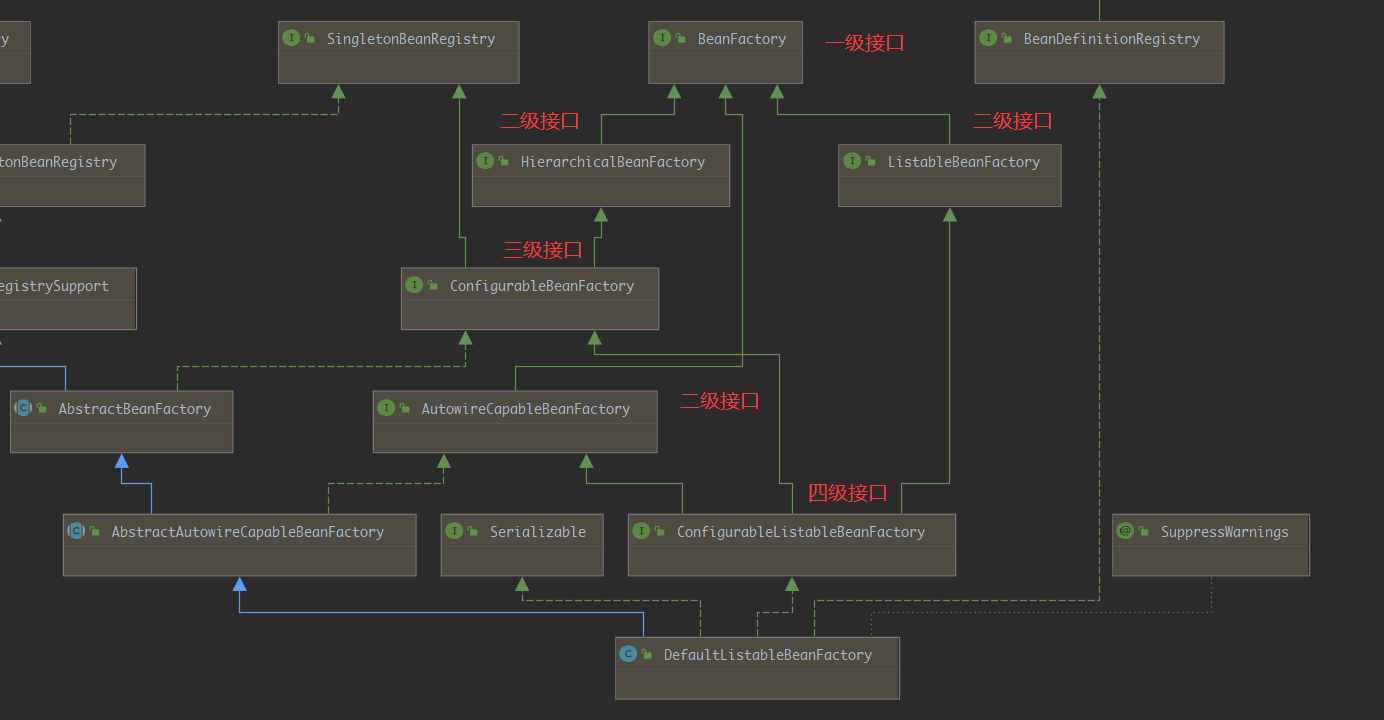
从上面我们可以看到BeanFactory有三个实现接口,分别是ListableBeanFactory、HierarchicalBeanFactory和AutowireCapableBeanFactory,并且井井有序,继承结构设计的非常优秀,其中:
-
BeanFactory作为一个主接口不继承任何接口,暂且称为一级接口
-
有3个子接口继承了它,进行功能上的增强。这3个子接口称为二级接口
-
ConfigurableBeanFactory可以被称为三级接口,对二级接口HierarchicalBeanFactory进行了再次增强,它还继承了另一个外来的接口SingletonBeanRegistry
-
ConfigurableListableBeanFactory是一个更强大的接口,继承了上述的所有接口,无所不包,称为四级接口(这4级接口是BeanFactory的基本接口体系。继续,下面是继承关系的2个抽象类和2个实现类:)
-
AbstractBeanFactory作为一个抽象类,实现了三级接口ConfigurableBeanFactory大部分功能
-
AbstractAutowireCapableBeanFactory同样是抽象类,继承自AbstractBeanFactory,并额外实现了二级接口AutowireCapableBeanFactory
-
DefaultListableBeanFactory继承自AbstractAutowireCapableBeanFactory,实现了最强大的四级接口ConfigurableListableBeanFactory,并实现了一个外来接口BeanDefinitionRegistry,它并非抽象类
-
最后是最强大的XmlBeanFactory,继承自DefaultListableBeanFactory,重写了一些功能,使自己更强大,但是这个类现在以及被标记为过期类,Spring官方建议使用:BeanFactory懒加载 或者
ApplicationContext中的逻辑来替换它
看看我们上面写的是什么玩意,跟玩具一样,就抽象了一层,不仅想解耦还想高拓展,实际的开发场景往往是十分复杂的,学习设计模式一定要把变字牢牢的记在心里。Spring中复杂的继承和抽象结构,就是为了满足尽可能多的应用场景
| 名字 | 作用 |
|---|---|
| (一级接口)BeanFactory | 定义的是IOC容器最基本的规范,核心方法getBean() |
| (二级接口)ListableBeanFactory | 实现对Bean实例的枚举,以及对默些公共特征Bean的管理(同一产品等级) |
| (二级接口)HierarchicalBeanFactory | 在BeanFactory定义的功能上增加了对父容器的定义,表示Bean继承关系 |
| (二级接口)AutowireCapableBeanFactory | Bean的创建注入并提供对Bean的初始化前后拓展性处理 |
| (三级接口)ConfigurableBeanFactory | 提供配置Factory的各种方式 |
| (四级接口)ConfigurableListableBeanFactory | 修改Bean定义信息和分析Bean的功能,实现了预实例化单例Bean以及冻结当前工厂配置的功能 |
| (抽象类)AbstractBeanFactory | Bean的创建和信息描述抽象方法,由继承者实现 |
| (抽象类)AbstractAutowireCapableBeanFactory | 实现Bean的创建并解决依赖注入问题,实现createBean()方法 |
| (实现类)DefaultListableBeanFactory | 对Bean容器完全成熟的默认实现,可对外使用 |
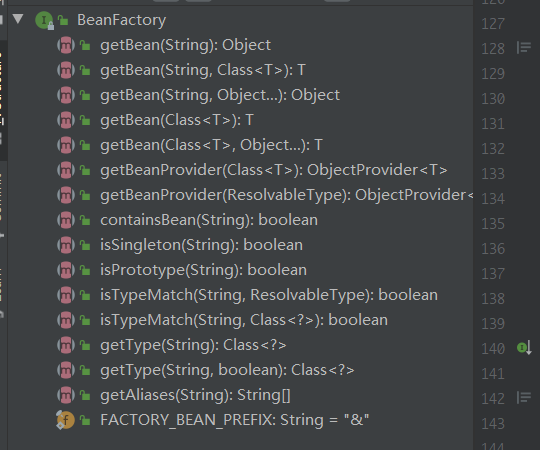
我们先来看(一级接口)BeanFactory,可以看到BeanFactory的核心方法就一个getBean(),还有一些获取Bean属性的方法
接下来就是(二级接口)HierarchicalBeanFactory,它的方法更少,核心就是getParentBeanFactory(),我们知道不同的Bean有不同的工厂加载,这个方法就是获取这个Bean工厂的父工厂的,主要是为了解决IOC容器循环依赖的问题,其中在IOC容器中定义一个Bean是否一样,不仅要判断Bean是否一样,还需要判断创建其的工厂是否一样,这里就不展开讲了
(二级接口)ListableBeanFactory
(二级接口)AutowireCapableBeanFactory:
(三级接口)ConfigurableBeanFactory主要是提供配置Factory的各种方法,主要的方法有:
- setConversionService():设置转换器
- addBeanPostProcess():添加Bean的后置处理器
- destoryBean():销毁Bean
(四级接口)ConfigurableListableBeanFactory:修改Bean定义信息和分析Bean的功能,实现了预实例化单例Bean以及冻结当前工厂配置的功能
(抽象类)AbstractBeanFactory,Bean的创建和信息描述抽象方法,定义createBean()方法,核心方法有:
- getBeanDefinition():BeanDefinition我们熟,Bean的定义,这个方法就是获取Bean的信息
- createBean():创建Bean,由继承者来实现
(抽象类)AbstractAutowireCapableBeanFactory:实现Bean的创建并解决依赖注入问题,实现createBean()方法
好重点来了兄弟们,看来这么多层的抽象,终于到了创建Bean的地方,让我们到源码里面看看Spring是如何优雅的
创建产品的
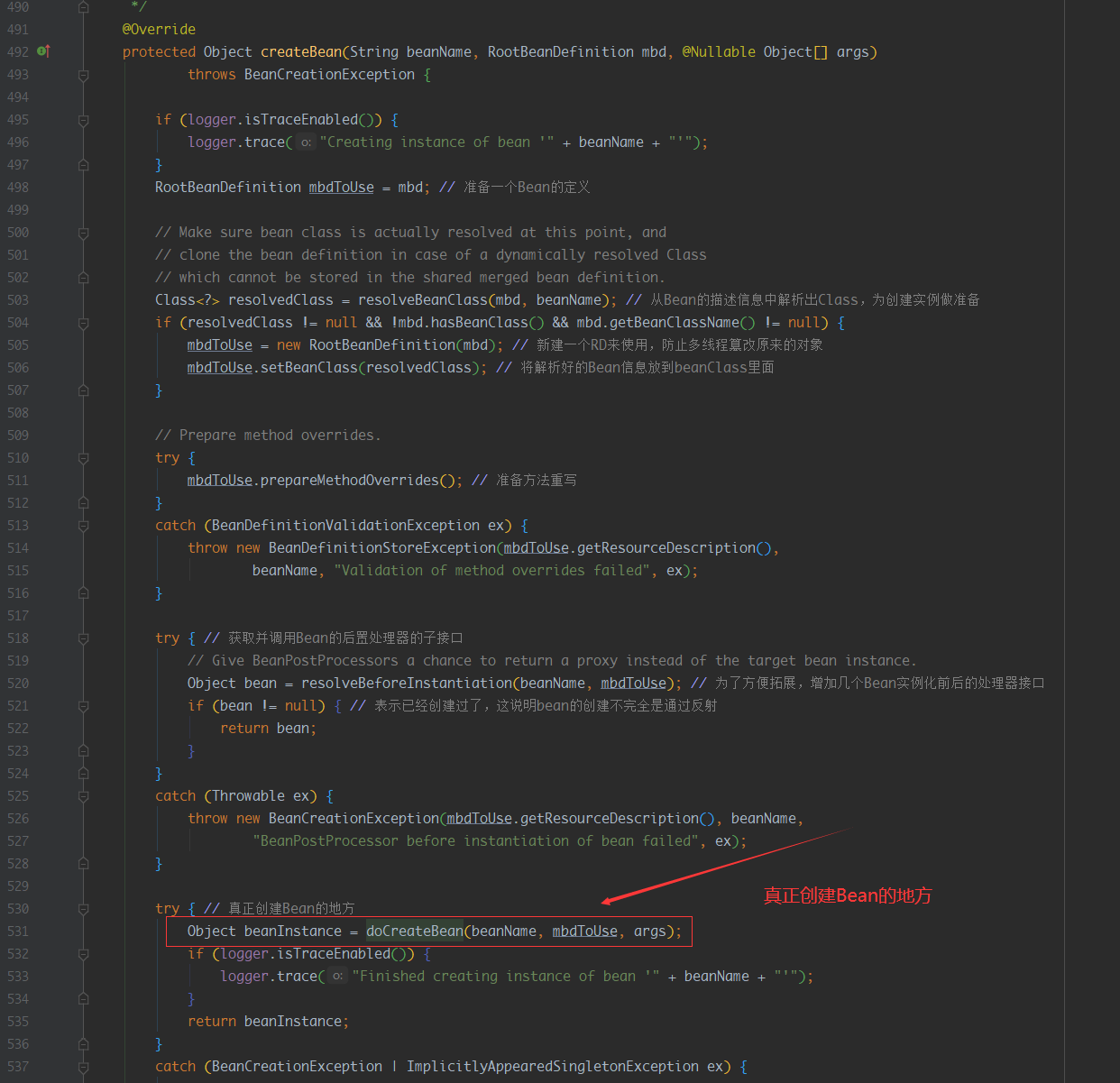
看来这么多,可能读者还是没明白在Spring中是如果动态创建产品的,其实过程很简单,我们想想在平时的编码中会干什么
首先我们会将项目分层,分为controller、service、dao等层次,我们使用SpringBoot的时候只需要加一个注解SpringBootApplication,就能自动扫描当前包及其子包下面被标记了@Component注解的类,然后加载到Spring的容器中,我们想想,我们需要管实现类的类名是什么吗?需要管实现内的代码改没改吗?都不需要,Spring会帮我们将其注册到IOC容器中,并且依靠强大的DI来进行注入,每次启动项目都会动态的去扫描,并且依靠各种工厂去创建产品
@Component
public class XXXService {
@Autowired(required = false)
private XXXDao xxxdao;
}
我们来思考到底比之前的工厂模式好在哪里
-
首先,用户添加
@Component后,这个Bean的定义就被注册到IOC容器了,相当于简单工程中做映射;Bean工厂在创建这个实例时不需要知道具体类型,因为是靠反射创建的实例,无论什么类型都可以创建,这样就消除了工厂类对接口实现类的依赖,当我们想要拓展产品时,只需要写实现类并将其交给IOC容器即可
总结:总而言之,言而总之,Spring是如何解决工厂模式问题的?
- 通过
动态工厂 + 反射,通过添加@Component注解动态获取Bean的定义,解决简单工厂中不能动态添加产品的问题 - 通过反射解决抽象工厂中无法拓展产品等级的问题;并且解决工厂方法中类爆炸的问题
- 通过强大的依赖注入,解决接口与实现类之间耦合的问题,并且可以进行自动装配,条件装配,真正面向接口编程
2.1.6 工作中工厂方法使用
没有实际业务场景,一切都是无源之水、无本之木,是空洞的,现在我们举一个笔者实际开发中配合IOC容器使用的工厂模式的例子
现在有一个场景,就是需要做登录,但是我们不确定现在移动端的同学做几端,可能会有手机号登录、账号密码登录、qq登录、微信登录、PC端登录、网页端登录。这些登录的具体实现肯定是不一样的,而且我们并不知道到底要做几种策略,并且之后一定会有所拓展
所以我们一般会用IOC容器 + 工厂模式 + 策略模式 + 模板方法模式来完成这些功能
首先我们要定义一个策略接口,用来动态获取Bean(产品)的定义,该接口继承InitializingBean,我们后面动态添加的策略只需要实现该接口,通过回调我们的注册方法,就能将自己添加到我们自己的工厂中
/**
* 策略接口
*
* @author Eureka
* @since 2022/9/25 11:59
*/
public interface LoginHandle extends InitializingBean {
/**
* 具体的登录逻辑
*/
void login(Map<String,String> params);
}
设计我们自己的登录工厂
public class LoginFactory {
private static Map<String, LoginHandle> loginStrategyFactoryMap = new ConcurrentHashMap<>();
public static LoginHandle getLoginStrategy(String loginSign) {
return loginStrategyFactoryMap.get(loginSign);
}
public static void register(String loginSign, LoginHandle loginHandle) {
if (StringUtils.isEmpty(loginSign) || Objects.isNull(loginHandle)) {
throw new RuntimeException("登录策略注册失败,参数错误");
}
// 将策略注册到工厂中
loginStrategyFactoryMap.put(loginSign, loginHandle);
}
}
例如我现在是手机号登录,我们就写一个具体的实现类,并实现我们的策略接口
/**
* 使用电话号码登录具体策略
*
* @author Eureka
* @since 2022/10/4 12:02
*/
@Slf4j
@Component
public class PhoneNumberLoginStrategy implements LoginHandle {
private static final String PHONE_NUMBER_LOGIN_STRATEGY = "PHONE_NUMBER_LOGIN_STRATEGY";
@Override
public void login(Map<String, String> params) {
// 放具体的登录策略
if (log.isDebugEnabled()) {
log.debug("用户通过手机号码登录,参数为:{}", params);
}
}
@Override
public void afterPropertiesSet() throws Exception {
// 将自己注册到我们自己定义的工厂中
LoginFactory.register(PHONE_NUMBER_LOGIN_STRATEGY, this);
}
}
我们来思考一下上面的策略模式 + 工厂模式解决了之前工厂模式的什么问题
- 首先,新增策略(产品),只需要实现
LoginHandle策略接口,通过将自己的映射关系注册到工厂中,解决了简单工厂中无法拓展的问题 - 其次,每个策略上用
@Component标记,表示这个Bean的实例交给Spring完成,通过反射解决抽象工厂无法拓展产品等级的问题
我们现在想要调用不同的执行策略,只需要让前端小哥哥在用户登录的时候传不同的标识,例如LoginSign = PHONE_NUMBER_LOGIN_STRATEGY,我们只需要
@Controller
public class LoginController {
@PostMapping("/user/login")
public ResponseEntity<Void> login(@RequestBody Map<String, String> params) {
// 调用对应的登录逻辑
LoginHandle loginHandle = LoginFactory.getLoginStrategy(params.get("LoginSign"));
loginHandle.login(params);
return ResponseEntity.ok().build();
}
}
这样如果下次需要新增加一种登录,我只需要写好具体的策略并实现策略接口,再和前端小哥沟通好标识就行了,上面这个Controller中的代码完全不用修改,这样既然解耦了,也能做到极致的拓展,并且完成不用写多余的代码,真正做到又想马儿跑,又不给马儿吃草
但是这样就ok了吗???笔者一再强调,开发讲究的就是一个变字,并且细心的小伙伴可能已经发现现在的类图好像看起来还是有点不太合理,现在的类图长这样
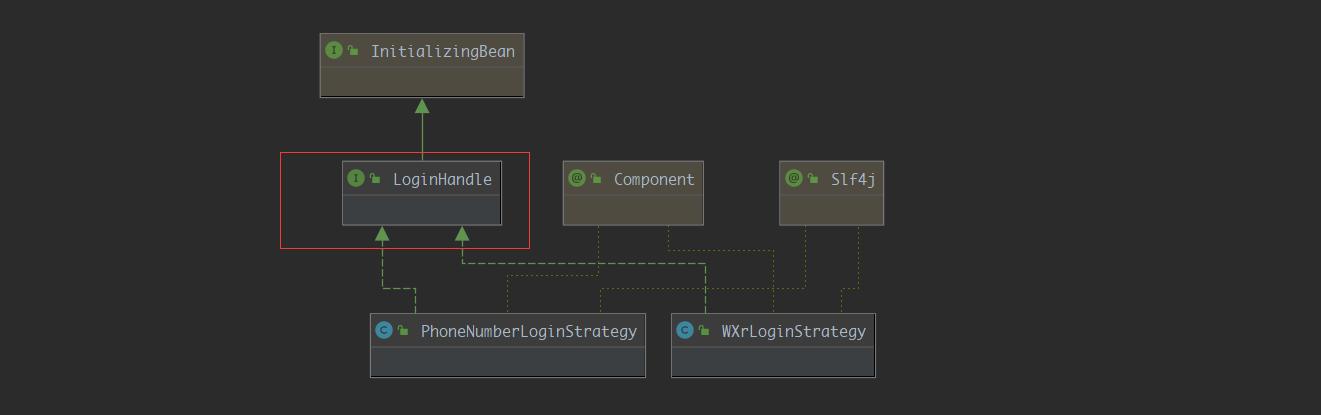
好像我们现在的实现类现在耦合接口LoginHandle了,有的同学会有疑问,什么叫耦合接口???不就应该面向接口编程吗?难道接口会变?对,接口就是会变,如果现在我们辛辛苦苦写了十种策略,马上要下班了,现在前端小哥说,还有一个下线的功能别忘记写了
好,现在BBQ了,我们得去该接口LoginHandle,新添加logout的接口,并且在十种策略里面都添加下线的实现,违反了开闭原则,并且我们假设,有的策略是不需要登出功能,而且又导致有些策略类不得不实现一个空方法,有的同学会问,难道不能在重新写一套工程和策略吗?当然不好,注册登录登出,本来就应该在一个体系里面
总结一下上面的问题:
- 依赖于
LoginHandle接口,并且实现类必须要实现里面的所有接口,如果实现类有不想实现的,也必须实现
这里我们再引入板方法模式,也就是在接口与实现类之前再套一层,看多了源码的同学肯定知道,那有接口下面直接就是实现的,一般都要再套一层抽象层进行解耦
我们现在再来捋一捋思路,首先我们现在接口里面新增加一个方法
public interface LoginHandle extends InitializingBean {
/**
* Bean实例化后回调该方法,将自己注册到自定义的工厂中
*/
void login(Map<String, String> params);
/**
* 登出功能
*/
void logout();
}
我们再创建一层抽象层AbstractLoginHandle,称为模板方法
/**
* 模板方法
*
* @author Eureka
* @since 2022/10/4 12:52
*/
public class AbstractLoginHandle implements LoginHandle {
@Override
public void login(Map<String, String> params) {
throw new UnsupportedOperationException();
}
@Override
public void logout() {
throw new UnsupportedOperationException();
}
/**
* 其中这个方法是必须要实现的,声明为抽象
*/
@Override
abstract public void afterPropertiesSet();
}
接下来修改我们具体的登录实现类,可以发现中间套了一层到好处是不用实现接口里面所有的方法,只需要有需要的实现即可,例如现在微信登录不需要登出功能,我们就可以这样写
/**
* 使用登录登录具体策略
*
* @author Eureka
* @since 2022/10/4 12:02
*/
@Slf4j
@Component
public class WXrLoginStrategy extends AbstractLoginHandle {
private static final String WX_LOGIN_STRATEGY = "WX_LOGIN_STRATEGY";
@Override
public void login(Map<String, String> params) {
// 放具体的登录策略
if (log.isDebugEnabled()) {
log.debug("用户微信登录,参数为:{}", params);
}
}
@Override
public void afterPropertiesSet() throws Exception {
// 将自己注册到我们自己定义的工厂中
LoginFactory.register(WX_LOGIN_STRATEGY, this);
}
}
我们开看一下现在的类图:
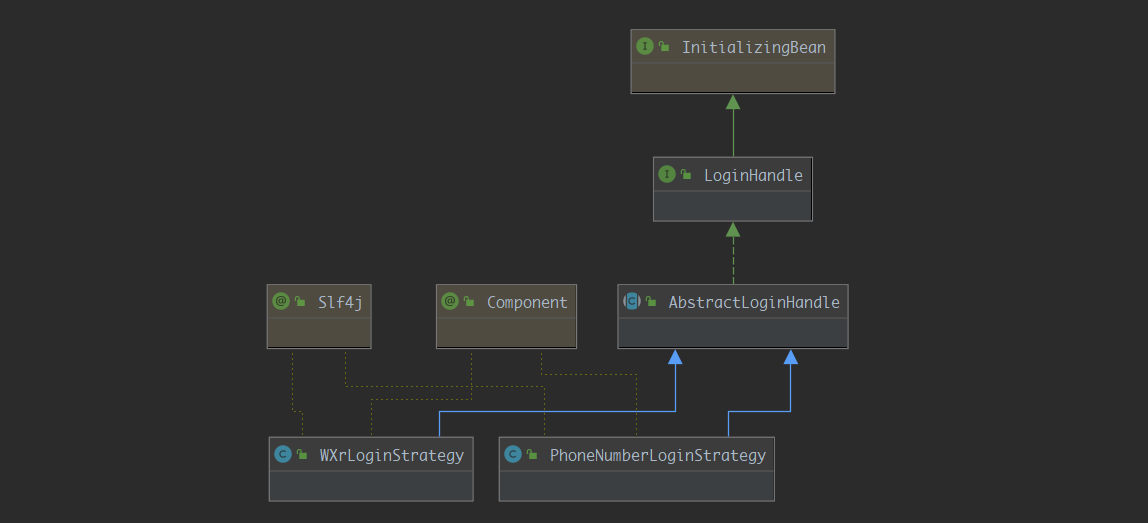
现在的这个结构就算比较合理的了,但是还可以拓展,这里就不展开了
最后再提一嘴,我们这里的工厂模式是不是不属于上面提到的任何一种设计模式,其实这上面的模板方法模式和严格意义上的也有区别,希望读者始终记住,请不要死板的套用设计模式,网上随便搞篇博客上来就是写各种接口抽象类,你会发现其实用起来不是特别的顺手,只有多总结多归纳多思考,当我们真正理解后,就不会局限于那种设计模式了,而是下意识就会去这样设计,一看类图就知道这里不合理,做到无招胜有招
2.2 原型模式
原型模式(Prototype Pattern)
原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用
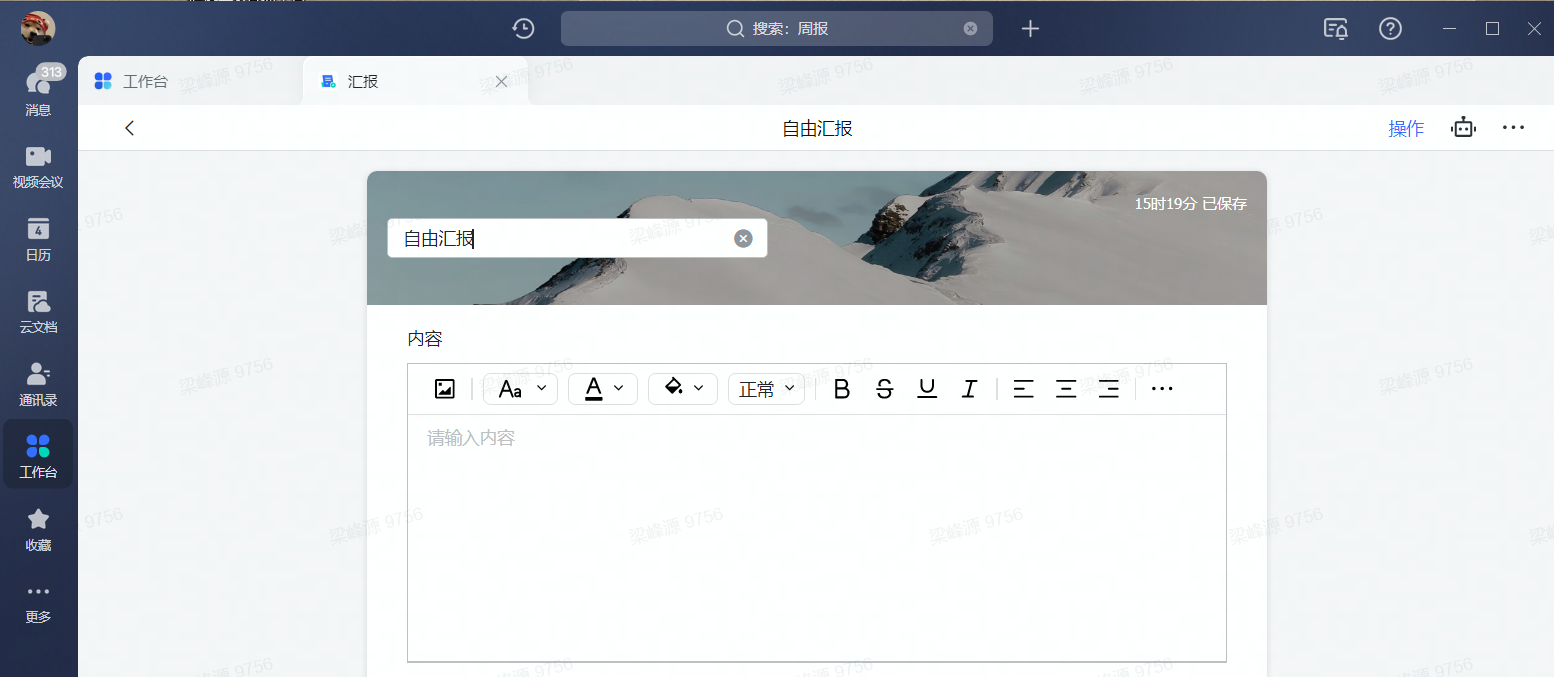
现在我们来想一个场景,例如我们现在要写周报,大家作为互联网打工人肯定每周都是要向老板反馈工作内容的,现在我们发现周报里面需要填很多信息,例如姓名、部门、职位等等,这些信息基本都不会变,但是每次填周报我们又需要填一遍,这样显然不合理,我们其实想的是,写周报只需要填汇报内容即可,如下图所示:
那我们应该怎么办呢?是不是希望能够保存一下上一次编辑的模板,下次直接修改内容就可以了,我们用一个类来表示一下
@Data // 自动生成getter setter 和 toString方法
@Accessors(chain = true) // 开启链式编程
class WeekReport{
private int id;
private String emp;
private String summary;
private String plain;
private String suggestion;
private String department;
private LocalDateTime submitDate;
}
public class AppTest {
public static void main(String[] args) {
WeekReport weekReport = new WeekReport();
weekReport.setEmp("奈李")
.setSummary("本周主要完成了七大设计原则和工厂模式的学习")
.setPlain("在下周的工作中完成原型模式学习")
.setDepartment("互联网事业部")
.setSubmitDate(LocalDateTime.now());
// 简单输出一下
System.out.println(weekReport);
// 第二周周报
WeekReport weekReport2 = new WeekReport();
weekReport2.setEmp("奈李")
.setSummary("本周主要完成了剩下设计模式的学习")
.setPlain("在下周会完成阿里巴巴开发手册学习")
.setDepartment("互联网事业部")
.setSubmitDate(LocalDateTime.now());
System.out.println(weekReport2);
}
}
我们会发现其实下一周要进行汇报时,我们只需要修改总结和下周计划的内容,但是现在我们却只能再新建一个对象重复上述代码
我们想要什么,想要的是直接克隆出一个对象来,将需要改变的填一下,不变的用之前的就好
我们现在通过克隆来实现上面的需求,在Java中只需要实现Cloneable,并重写克隆方法即可
@Data // 自动生成getter setter 和 toString方法
@Accessors(chain = true) // 开启链式编程
class WeekReport implements Cloneable {
private int id;
private String emp;
private String summary;
private String plain;
private String suggestion;
private String department;
private LocalDateTime submitDate;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class AppTest {
public static void main(String[] args) throws CloneNotSupportedException {
WeekReport weekReport = new WeekReport();
weekReport.setEmp("奈李")
.setSummary("本周主要完成了七大设计原则和工厂模式的学习")
.setPlain("在下周的工作中完成原型模式学习")
.setDepartment("互联网事业部")
.setSubmitDate(LocalDateTime.now());
// 简单输出一下
System.out.println(weekReport);
// 第二周周报 直接copy第一周的周报改改进行
WeekReport weekReport2 = (WeekReport) weekReport.clone();
weekReport2.setSummary("本周主要完成了剩下设计模式的学习")
.setPlain("在下周会完成阿里巴巴开发手册学习")
.setSubmitDate(LocalDateTime.now());
System.out.println(weekReport2);
}
}
这就是原型设计模式,是不是感觉挺简单的,这里还有几个点要注意一下
- 上面的克隆其实只是
浅拷贝 - 使用clone方法创建对象,并不会调用该对象的构造器
- 因为Object类的clone方法是一个本地方法,它直接操作内存中的二进制流,特别是复制大对象时,性能的差别非常明显。
2.2.1 深拷贝浅拷贝
| 类型 | 特点 |
|---|---|
| 浅拷贝 | Object类的clone方法只会拷贝对象中的基本的数据类型,对于数组、容器对象、引用对象等都不会拷贝,这就是浅拷贝 |
| 深拷贝 | 会将原本对象中的数组、容器对象、引用对象等另行拷贝(完全是新的对象) |
有的同学在这里总是傻傻分不清楚,就知道浅拷贝就是引用类型不拷贝,然后指向之前对象的堆空间,分不清成员变量中的引用是啥
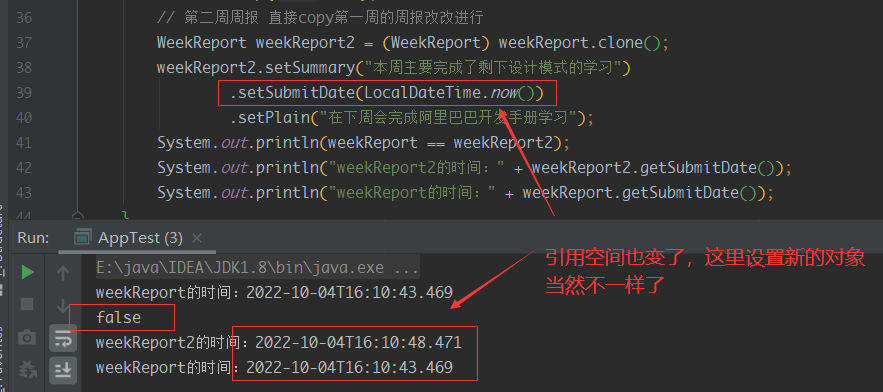
上面的可以把setSubmitDate看做一个指针,你弄了一个新对象给它,当然会在堆空间里面新申请一块内存,当然就不一样了
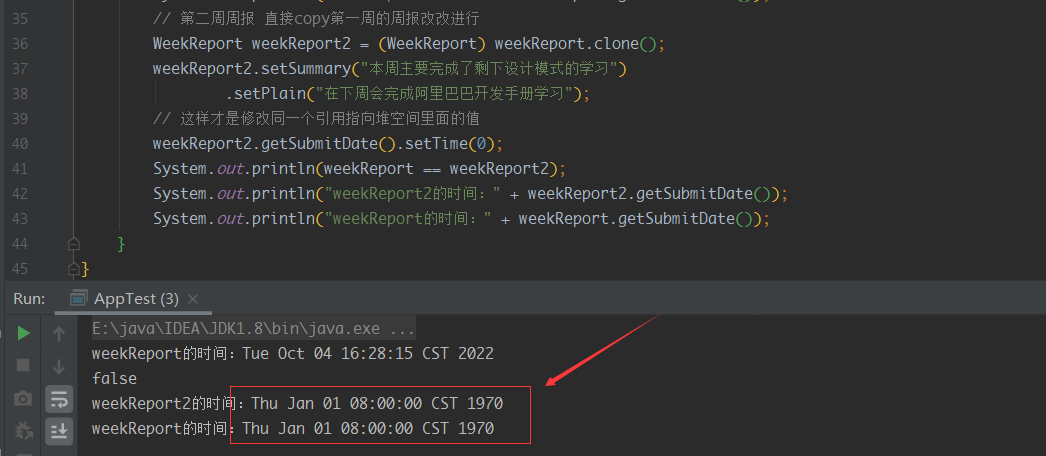
那我们如何深拷贝呢?其实也很简单,既然原来的Object.clone()方法无法克隆引用类型,那我们自己来克隆就好了
其中大部分类其实都是实现了clone方法的
@Override
protected Object clone() throws CloneNotSupportedException {
WeekReport cloneWeekReport = (WeekReport) super.clone();
// Date类型需要自己手动进行克隆
Date cloneSubmitDate = (Date) cloneWeekReport.getSubmitDate().clone();
cloneWeekReport.setSubmitDate(cloneSubmitDate);
return cloneWeekReport;
}
但是这样显然很麻烦,如果我们克隆的是自己定义的对象,或者是对象里面套对象,这样层层嵌套的形式,显然就有点麻烦了
2.2.2 封装深拷贝工具
所以我们一般是用序列化和反序列化来做的,并且会封装成一个工具,这个拷贝在开发中还是非常常见的,例如我们经常将一个PO转换为一个VO(就是拷贝对象),一般用Spring自带的BeanUtils,但是它只能浅拷贝,我们现在自己封装一个,可以选择继承Spring自带的BeanUtils,或者就放deepClone这一个方法就行
/**
* 拷贝Bean
*/
@Slf4j
public final class BeanUtil extends BeanUtils {
private BeanUtil() {
throw new UnsupportedOperationException();
}
/**
* 拷贝属性
*/
public static <T> T copyProperties(Object source, Class<T> targetClass) {
if (checkNull(source, targetClass)) {
return null;
}
try {
T newInstance = targetClass.newInstance();
copyProperties(source, newInstance);
return newInstance;
} catch (Exception e) {
log.error("error: ", e);
return null;
}
}
@SuppressWarnings("unchecked")
public static <T extends Serializable> T deepClone(T object) {
T cloneObject = null;
try {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
objectOutputStream.writeObject(object);
objectOutputStream.close();
ByteArrayInputStream inputStream = new ByteArrayInputStream(outputStream.toByteArray());
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
cloneObject = (T) objectInputStream.readObject();
objectInputStream.close();
} catch (ClassNotFoundException | IOException e) {
log.info("拷贝异常::", e);
}
return cloneObject;
}
public static <T> T copyProperties(Object source, Class<T> targetClass, String... ignoreProperties) {
if (checkNull(source, targetClass)) {
return null;
}
try {
T newInstance = targetClass.newInstance();
copyProperties(source, newInstance, ignoreProperties);
return newInstance;
} catch (Exception e) {
log.error("error: ", e);
return null;
}
}
/**
* 拷贝集合
*/
public static <T> List<T> copyProperties(List<?> sources, Class<T> targetClass) {
if (checkNull(sources, targetClass) || sources.isEmpty()) {
return new ArrayList<>();
}
return sources.stream().map(source -> copyProperties(source, targetClass)).collect(Collectors.toList());
}
private static <T> boolean checkNull(Object source, Class<T> targetClass) {
return Objects.isNull(source) || Objects.isNull(targetClass);
}
}
现在在来看看原来的拷贝,这里需要注意进行序列化的对象需要实现Serializable接口
@Data // 自动生成getter setter 和 toString方法
@Accessors(chain = true) // 开启链式编程
class WeekReport implements Serializable {
private static final long serialVersionUID = 4455534412412L;
private int id;
private String emp;
private String summary;
private String plain;
private String suggestion;
private String department;
private Date submitDate;
}
public class DeepCloneTest {
public static void main(String[] args) throws CloneNotSupportedException, InterruptedException {
WeekReport weekReport = new WeekReport();
weekReport.setEmp("奈李")
.setSummary("本周主要完成了七大设计原则和工厂模式的学习")
.setPlain("在下周的工作中完成原型模式学习")
.setDepartment("互联网事业部")
.setSubmitDate(new Date());
// 简单输出一下
System.out.println("weekReport的时间:" + weekReport.getSubmitDate());
// 第二周周报 直接copy第一周的周报改改进行
WeekReport weekReport2 = BeanUtil.deepClone(weekReport);
weekReport2.setSummary("本周主要完成了剩下设计模式的学习")
.setPlain("在下周会完成阿里巴巴开发手册学习");
// 这样才是修改同一个引用指向堆空间里面的值
weekReport2.getSubmitDate().setTime(0);
System.out.println(weekReport == weekReport2);
System.out.println("weekReport2的时间:" + weekReport2.getSubmitDate());
System.out.println("weekReport的时间:" + weekReport.getSubmitDate());
}
}

2.2.3 原型模式小结
是不是感觉其实原型模式也没啥,确实也没啥,所以23中设计模式其实有的模式其实还是挺简单的

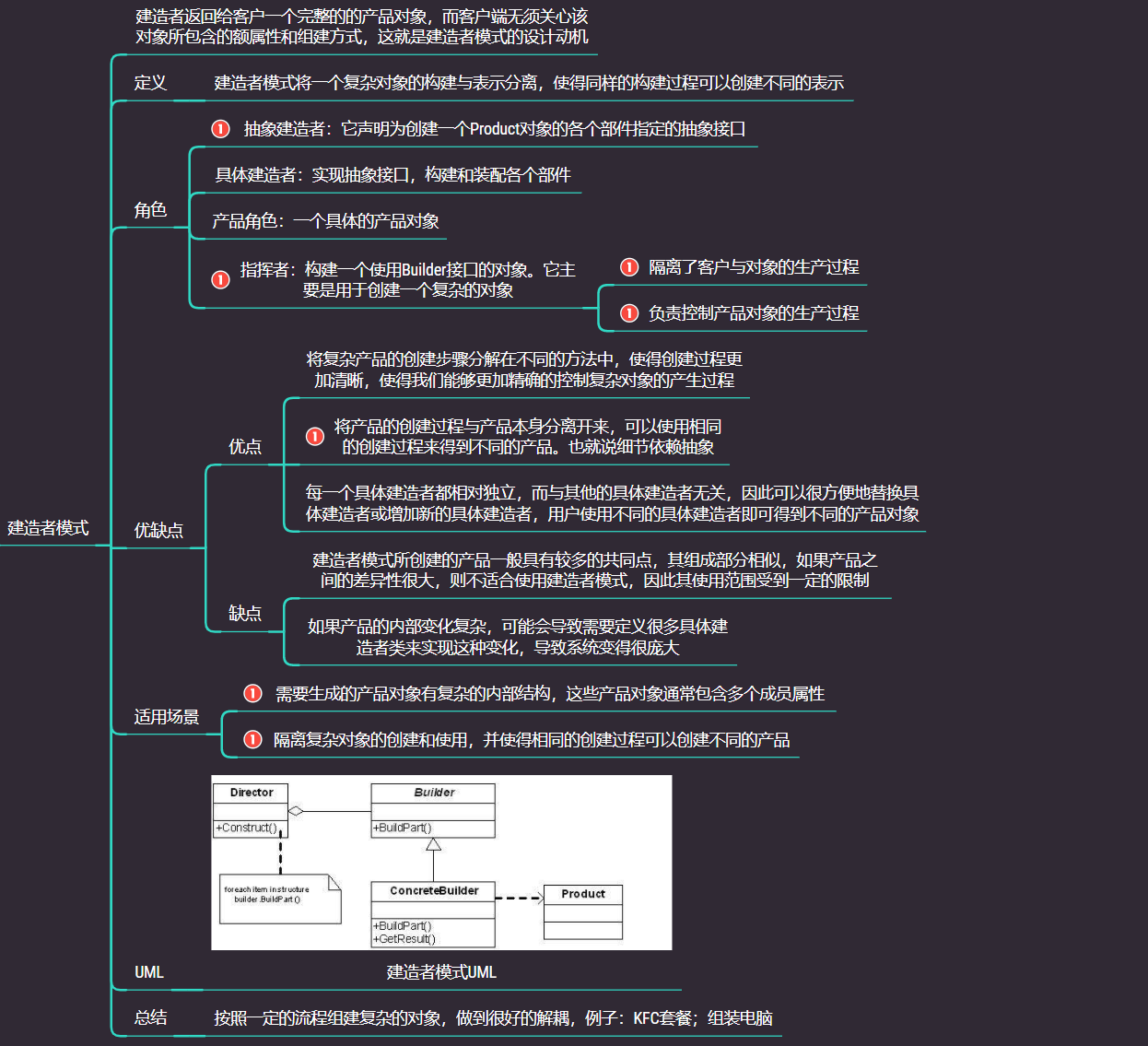
2.3 建造者模式
建造者模式(Builder Pattern)
建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。一个 Builder 类会一步一步构造最终的对象。该 Builder 类是独立于其他对象的。
- 优点: 1、建造者独立,易扩展。 2、便于控制细节风险。
- 缺点: 1、产品必须有共同点,范围有限制。 2、如内部变化复杂,会有很多的建造类。
例如我们现在有一个电脑类,里面有一些属性
@Data
@Accessors(chain = true)
class Compute {
private String cpu;
private String gpu;
private String memory;
private String hd;
}
public class BuilderTest {
public static void main(String[] args) {
Compute compute = new Compute()
.setCpu("i7-10700")
.setGpu("3080 Ti")
.setMemory("32G")
.setHd("1T");
System.out.println(compute);
}
}
这样其实也有些问题:
- 对象实例化的时候就必须要为每一个属性赋值,比较麻烦
- 对于使用者来说,相当于给你一堆零件,然后需要自己组装
现在来改进一下,这里作者需要专门创建一个ComputeBuilder类,来专门负责组装电脑的过程
@Data
@Accessors(chain = true)
class Compute {
private String cpu;
private String gpu;
private String memory;
private String hd;
}
// 电脑构建者类,并且必须关联一个产品
class ComputeBuilder {
private Compute compute = new Compute();
// 构建方法
public Compute builder() {
return compute.setCpu("i7-10700")
.setGpu("3080 Ti")
.setMemory("32G")
.setHd("1T");
}
}
public class BuilderTest {
public static void main(String[] args) {
// 创建一个建造者
ComputeBuilder computeBuilder = new ComputeBuilder();
// 创建电脑
Compute compute = computeBuilder.builder();
System.out.println(compute);
}
}
上述代码的好处是:
- 由建造者隐藏了创建对象的复杂过程
但是这样的缺点是什么?
- 好像封装的太厉害了,无论客户需要什么,返回都是一样的配置
我们再改造一下
@Data
@Accessors(chain = true)
class Compute {
private String cpu;
private String gpu;
private String memory;
private String hd;
}
interface IcomputeBuilder{
Compute builder();
}
// 高级配置
class HighComputeBuilder implements IcomputeBuilder{
private Compute compute = new Compute();
// 构建方法
public Compute builder() {
return compute.setCpu("i7-10700")
.setGpu("3080 Ti")
.setMemory("32G")
.setHd("1T");
}
}
class MiddleComputeBuilder implements IcomputeBuilder{
private Compute compute = new Compute();
// 构建方法
public Compute builder() {
return compute.setCpu("i5-9500")
.setGpu("2080 Ti")
.setMemory("16G")
.setHd("1T");
}
}
class LowComputeBuilder implements IcomputeBuilder{
private Compute compute = new Compute();
// 构建方法
public Compute builder() {
return compute.setCpu("i3-8500")
.setGpu("1080 Ti")
.setMemory("8G")
.setHd("500G");
}
}
public class BuilderTest {
public static void main(String[] args) {
// 创建一个建造者
IcomputeBuilder highBuilder = new HighComputeBuilder();
IcomputeBuilder middleBuilder = new MiddleComputeBuilder();
IcomputeBuilder lowBuilder = new LowComputeBuilder();
// 创建最厉害的电脑
Compute highCompute = highBuilder.builder();
System.out.println(highCompute);
// 中等的电脑
Compute middleCompute = middleBuilder.builder();
System.out.println(middleCompute);
// 一般的电脑
Compute lowCompute = lowBuilder.builder();
System.out.println(lowCompute);
}
}
这样以来用户可以通过选取不同的建造者,来生产不同的产品,但是这里还是有问题
- 我们发现在不同的构造者中,有重复的代码,既然有重复的代码,那就有
坏味道 - 构建的过程是不稳定的,如果某个建造者遗漏掉了哪一步,那么生产出来的产品就是不合格的,但是编译器却不会报错
我们得再进行改造
@Data
@Accessors(chain = true)
class Compute {
private String cpu;
private String gpu;
private String memory;
private String hd;
}
interface IcomputeBuilder {
IcomputeBuilder cpu();
IcomputeBuilder gpu();
IcomputeBuilder memory();
IcomputeBuilder hd();
Compute builder();
}
// 高级配置
class HighComputeBuilder implements IcomputeBuilder {
private Compute compute = new Compute();
@Override
public IcomputeBuilder cpu() {
compute.setCpu("i7-10700");
return this;
}
@Override
public IcomputeBuilder gpu() {
compute.setGpu("3080 Ti");
return this;
}
@Override
public IcomputeBuilder memory() {
compute.setMemory("32G");
return this;
}
@Override
public IcomputeBuilder hd() {
compute.setHd("1T");
return this;
}
// 构建方法
public Compute builder() {
return compute;
}
}
public class BuilderTest {
public static void main(String[] args) {
// 创建一个建造者
IcomputeBuilder highBuilder = new HighComputeBuilder();
// 创建最厉害的电脑
Compute highCompute = highBuilder.cpu().gpu().memory().hd().builder();
System.out.println(highCompute);
}
}
我们看这样进行构建的优点:
- 建造者类中的建造过程是稳定的。不会漏掉某一步!!这样当客户端想扩展建造者时,也不会漏掉某一步
缺点:
- 如果有多个建造者,代码任然会有重复
- 现在又变成了客户端自己配置电脑,又违反了
迪米特法则。(这相当于,你去电脑城配电脑,虽然不用你亲自组装电脑,但是你必须指挥那个装机boy,下一步该干啥,下一步该干啥,虽然隐藏细节,但是还是要指挥
我们想要的是连指挥过程也要隐藏起来
@Data
@Accessors(chain = true)
class Computer {
private String cpu;
private String gpu;
private String memory;
private String hd;
}
interface IComputerBuilder {
IComputerBuilder cpu();
IComputerBuilder gpu();
IComputerBuilder memory();
IComputerBuilder hd();
Computer builder();
}
// 隐藏指挥命令的细节
class Director {
public Computer build(IComputerBuilder computerBuilder) {
// 指挥builder进行组装
return computerBuilder.cpu().gpu().memory().hd().builder();
}
}
// 高级配置
class HighComputerBuilder implements IComputerBuilder {
private Computer computer = new Computer();
@Override
public IComputerBuilder cpu() {
computer.setCpu("i7-10700");
return this;
}
@Override
public IComputerBuilder gpu() {
computer.setGpu("3080 Ti");
return this;
}
@Override
public IComputerBuilder memory() {
computer.setMemory("32G");
return this;
}
@Override
public IComputerBuilder hd() {
computer.setHd("1T");
return this;
}
// 构建方法
public Computer builder() {
return computer;
}
}
public class BuilderTest {
public static void main(String[] args) {
// 创建一个建造者
IComputerBuilder highBuilder = new HighComputerBuilder();
// 创建指挥者
Director director = new Director();
// 由指挥者进行指挥
Computer highComputer = director.build(highBuilder);
System.out.println(highComputer);
}
}
- 建造者负责建造,指挥者负责指挥,创建对象的过程是稳定的(IComputerBuilder接口负责稳定),创建对象的过程也不会有重复代码(指挥者完成)
- 当需要拓展新的产品时,不需要修改原来的代码,只需要实现构建者接口,然后交给指挥者完成即可,这里就将构造和流程分别由构造者和指挥者进行解耦
- 建造者作为中间层,进行解耦
最后画一下UML类图:
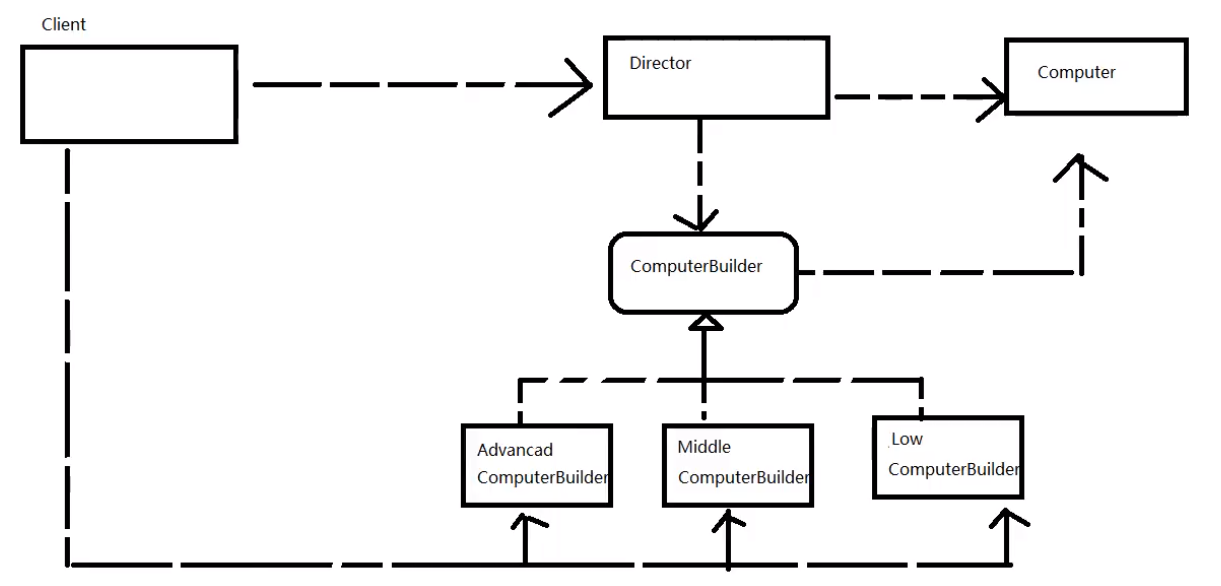
2.3.1 建造者与工程模式的区别
- 工厂模式只负责创建实例,并不关心里面的属性和构建的过程;建造者模式更加关注构建的过程,通过一些规范的流程、标准构建合格的产品
2.3.2建造者模式总结
3. 结构型模式
结构型模式
这些设计模式关注类和对象的组合。继承的概念被用来组合接口和定义组合对象获得新功能的方式

3.1 装饰器模式
装饰器模式(Decorator Pattern)
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。
这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。
3.1.1 装饰器模式案例
我们现在来看一个业务场景,星巴克卖咖啡,一开始只有四种咖啡,分别是:Decaf低咖咖啡、Espresso浓缩咖啡、DrakRoast焦糖咖啡、HouseBlend混合咖啡
由于这四种咖啡都有共性,所以很久之前的开发人员给他们上了一个父类Beverage,饮料类
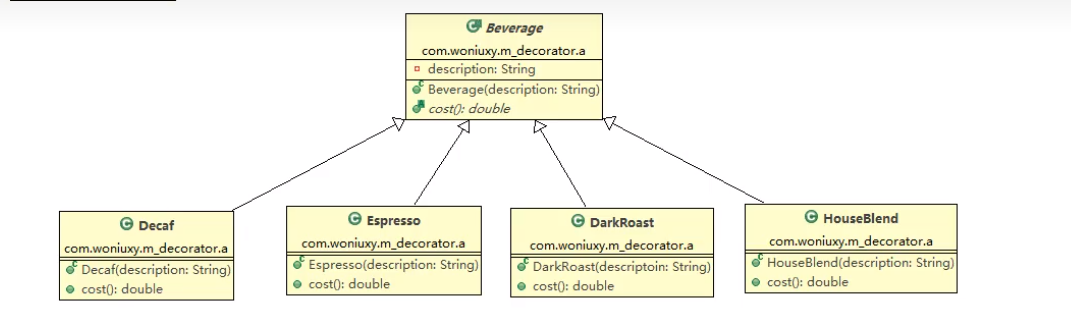
@Data
abstract class Beverage {
private String description;
public Beverage(String description) {
this.description = description;
}
// 花费
public abstract double cost();
}
class Decaf extends Beverage {
public Decaf() {
super("无糖咖啡");
}
@Override
public double cost() {
return 1;
}
}
class Espresso extends Beverage {
public Espresso() {
super("浓缩咖啡");
}
@Override
public double cost() {
return 5;
}
}
class DrakRoast extends Beverage {
public DrakRoast() {
super("焦糖咖啡");
}
@Override
public double cost() {
return 15;
}
}
class HouseBlend extends Beverage {
public HouseBlend() {
super("混合咖啡");
}
@Override
public double cost() {
return 10;
}
}
/// 请注意上述代码已经由作者写死了,无法改变 ///
public class AppTest {
public static void main(String[] args) {
Beverage decaf = new Decaf();
Beverage espresso = new Espresso();
Beverage drakRoast = new DrakRoast();
Beverage houseBlend = new HouseBlend();
System.out.println(String.format("咖啡描述:%s,咖啡价格:%.2f", decaf.getDescription(), decaf.cost()));
System.out.println(String.format("咖啡描述:%s,咖啡价格:%.2f", espresso.getDescription(), espresso.cost()));
System.out.println(String.format("咖啡描述:%s,咖啡价格:%.2f", drakRoast.getDescription(), drakRoast.cost()));
System.out.println(String.format("咖啡描述:%s,咖啡价格:%.2f", houseBlend.getDescription(), houseBlend.cost()));
}
}
这样看代码好像并没有什么问题,可是现在变化来了,现在星巴克老板为了提高竞争力,需要往咖啡里面加调料,我们假设之前的代码是作者写死了的,我们无法改变,那么现在如何
例如调料我们现在有摩卡、泡沫、白糖、牛奶,我们现在想要给上面写的四个类加上牛奶,但是由于我们不能修改源代码并且符合开闭原则,我们只能通过继承的方式
// 为牛奶的Decaf咖啡创建一个类
class DecafWithMilk{
}
// 为加牛奶的Espresso咖啡创建一个类
class EspressonWithMilk{
}
...
好像感觉到不对劲了叭,这才是一种调料的组合,如果我需要摩卡 + 白糖、摩卡 + 牛奶 。。。等等组合?还维护的下去吗?现在会造成类爆炸的问题,我们看一下会有多少类,结论是有多少组合就会产生多少类
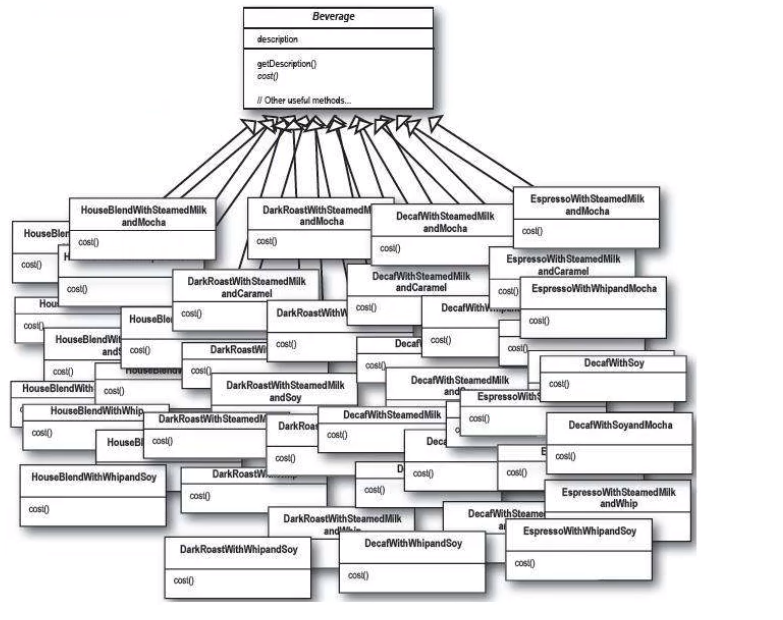
如果你非常强大,硬着头皮写完了所有类,现在老板说又要加一种调料,之前是四种,组合有15中组合,现在五种调料,有31中,六种调料有63种,这合理吗?老板说一句话的功夫,如果不懂设计模式,那就得通宵加班
其实我们并不需要为每一种调料都添加,我们用装饰器模式完成这个功能:
/// 请注意上述代码已经由作者写死了,无法改变 ///
/**
* 装饰器模式<br/>
* 这里我们让调料类继承自饮料类,显然违背了继承中的"is a"关系,但是在装饰器模式中这个原则就是需要违背<br/>
* 尽管调料不是饮料,但是为了解决问题,我们也只能让调料去继承饮料
*/
abstract class Condiment extends Beverage {
// 不仅需要继承饮料还需要关联饮料,让调料类关联饮料
protected Beverage beverage;
public Condiment(Beverage beverage) {
super("调料");
this.beverage = beverage;
}
}
class Milk extends Condiment {
public Milk(Beverage beverage) {
super(beverage);
}
@Override
public double cost() {
return beverage.cost() + 0.2;
}
@Override
public String getDescription() {
return beverage.getDescription() + " 牛奶";
}
}
class Mocha extends Condiment {
public Mocha(Beverage beverage) {
super(beverage);
}
@Override
public double cost() {
return beverage.cost() + 0.5;
}
@Override
public String getDescription() {
return beverage.getDescription() + " 摩卡";
}
}
public class AppTest {
public static void main(String[] args) {
Beverage decaf = new Decaf();
// 现在想要加牛奶
Milk milk = new Milk(decaf);
// 加摩卡
Mocha mocha = new Mocha(milk);
System.out.println(String.format("咖啡描述:%s,咖啡价格:%.2f", milk.getDescription(), milk.cost()));
System.out.println(String.format("咖啡描述:%s,咖啡价格:%.2f", mocha.getDescription(), mocha.cost()));
}
}
咖啡描述:无糖咖啡 牛奶,咖啡价格:1.20
咖啡描述:无糖咖啡 牛奶 摩卡,咖啡价格:1.70
可能读者看到上面的代码有点蒙蔽,请多看两遍,但是上述的代码确实在不改动源代码的前提下,完成了动态添加调料的功能!
我们重点看这几行代码:
// 现在想要加牛奶
Milk milk = new Milk(decaf);
// 加摩卡
Mocha mocha = new Mocha(milk);
这几行就是精华了,我们称之为想要添加什么功能就用对应的类装饰就行了!,我们把这种类称为ConcreteDecorator(具体装饰类)
我们不能用传统的继承关系看上面的代码,认为 Milk是不能继承Condiment的,我们仔细看 Milk到底做了啥
class Milk extends Condiment {
public Milk(Beverage beverage) {
super(beverage);
}
。。。
}
可以看到Milk不仅继承了Beverage饮料类,还关联了饮料类,关联是想要获取想要装饰的对象,继承是为了在原有的基础上对装饰对象的装饰
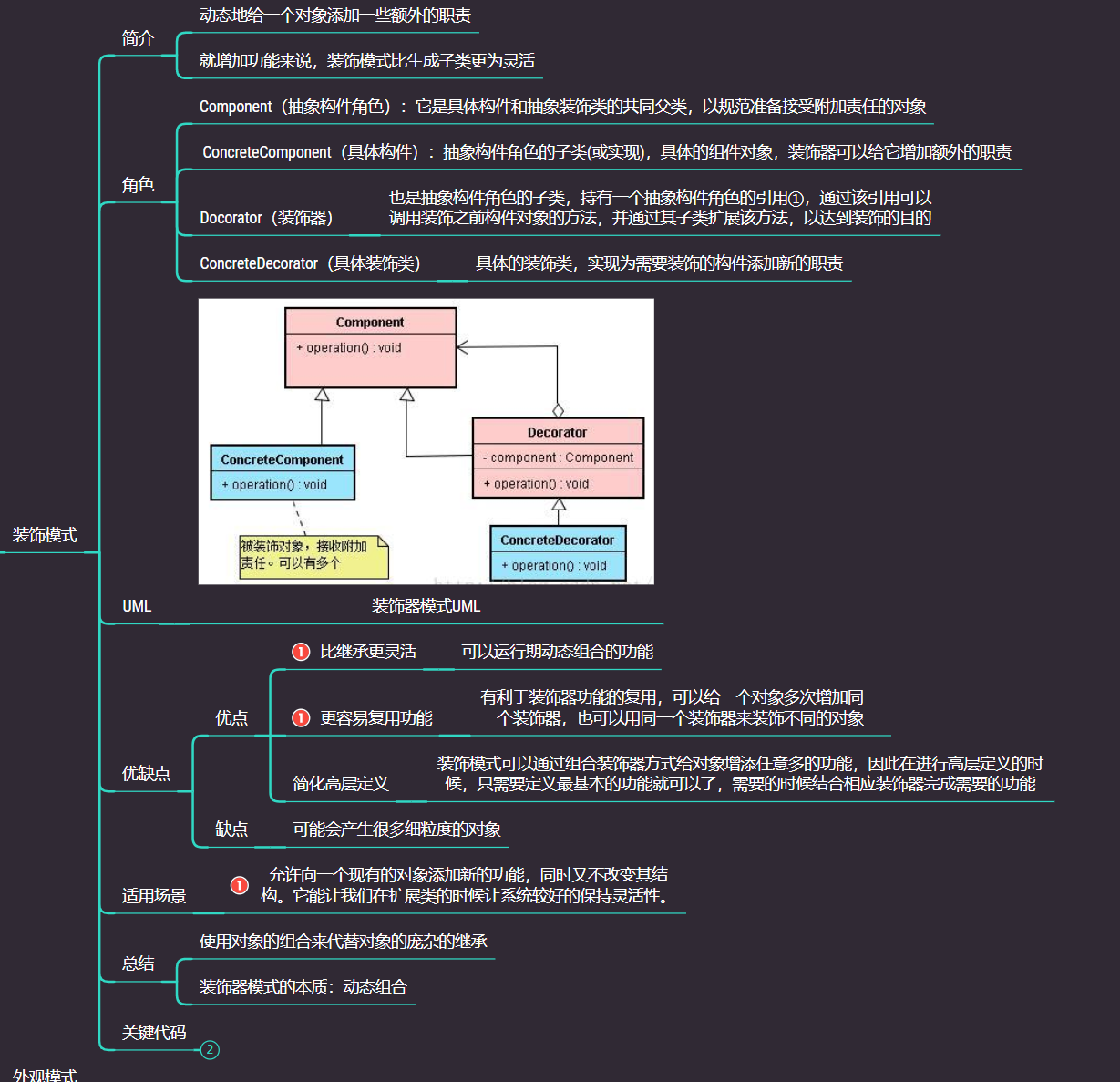
好好理解,多看几遍上面的代码,总结一下装饰器模式的几个角色
- Component(抽象构件角色):它是具体构件和抽象装饰类的共同父类,以规范准备接受附加责任的对象(Beverage)
- ConcreteComponent(具体构件):抽象构件角色的子类(或实现),具体的组件对象,装饰器可以给它增加额外的职责(decaf、Espresso、DrakRoast、HouseBlend)
- Docorator(装饰器):也是抽象构件角色的子类,持有一个抽象构件角色的引用,通过该引用可以调用装饰之前构件对象的方法,并通过其子类扩展该方法,以达到装饰的目的(Condiment)
- ConcreteDecorator(具体装饰类):具体的装饰类,实现为需要装饰的构件添加新的职责(Milk、Mocha)
记住关键步骤:
- 继承 + 依赖:继承需要装饰的类的父类,拥有共性;组合想要装饰的类,用于装饰(加强)
- 无限套娃:通过套娃,对需要装饰的类进行装饰、加强
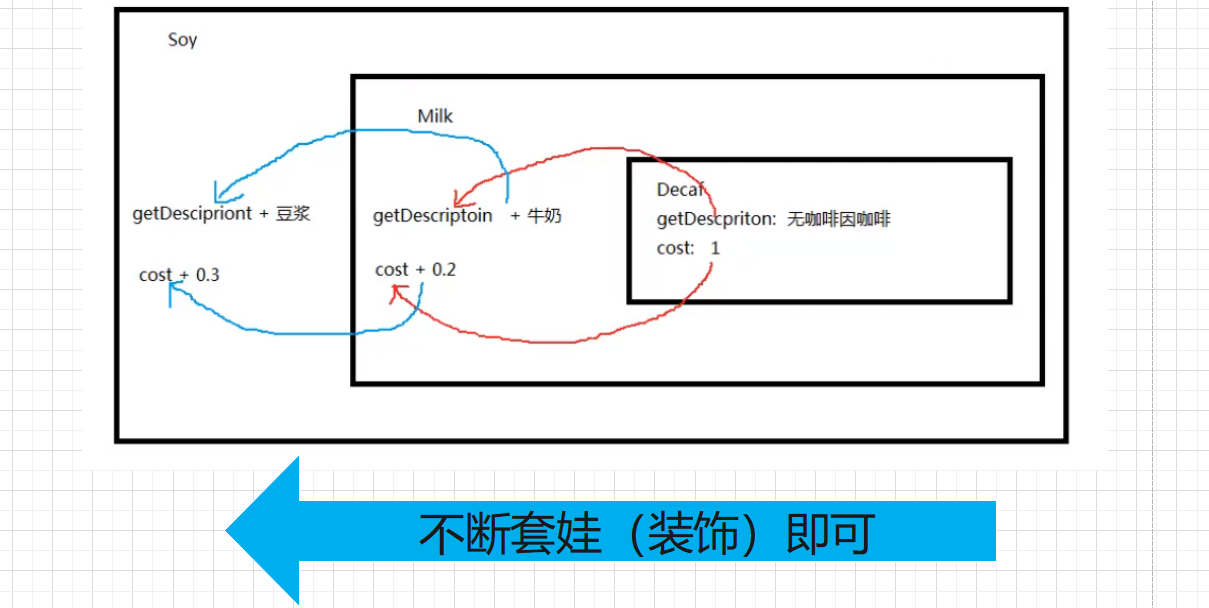
小结一下装饰器模式的优缺点:
优点:
- 装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能
- 多层装饰比较复杂
3.1.2 jdk中的装饰器模式
jdk中用到了很多装饰器模式,例如流里面就有很多的装饰类,所以我们在学校Java流的时候一定会觉得为什么流这么多
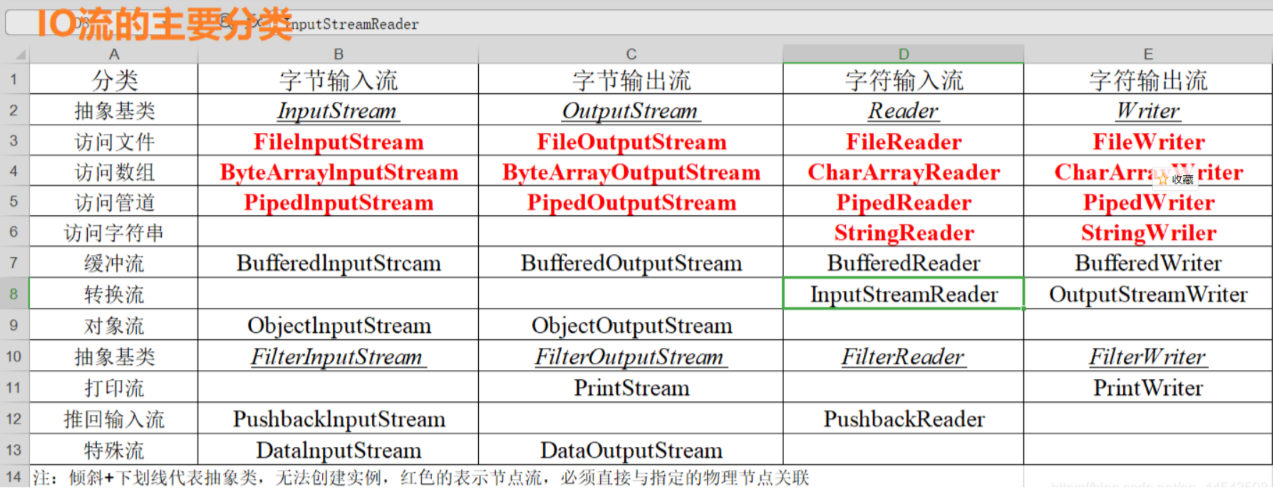
我们随便写一段流的代码:
// 字节流
InputStream in = new FileInputStream("xxx.txt");
// 包装为缓冲流,减少来回次数提升读写速度
BufferedInputStream bis = new BufferedInputStream(in);
// 包装为字符流
InputStreamReader inputStreamReader = new InputStreamReader(bis, StandardCharsets.UTF_8);
// 关闭流
inputStreamReader.close();
我们看其实流为了应对不同的场景,也是一层一层的包装下来的,我们看看继承结构
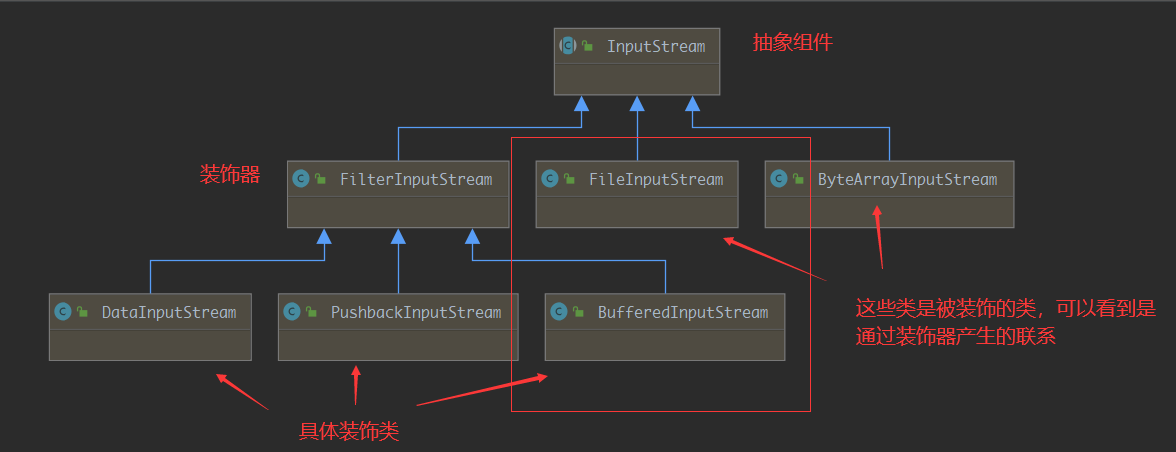 可以看到我们通过装饰器
可以看到我们通过装饰器FilterInputStream,让本来没有联系的两个流FileInputStream与BufferedInputStream产生了关联,这种关联及时继承 + 关联/依赖,从而达到可以装饰(套娃)的效果,我们来看看FilterInputStream的源码
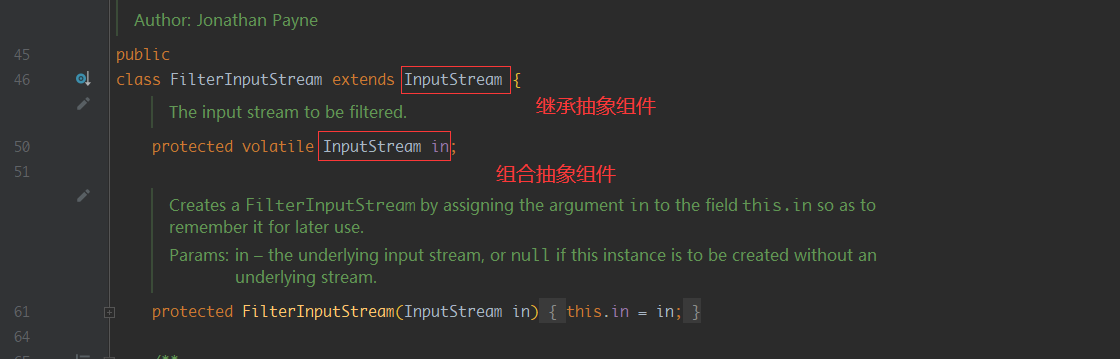
好好看你就会发现,作者又是写Stack的那个水货(无意冒犯🤣),好那么如果现在我也想写一个装饰类该怎么办呢,该继承谁呢?装饰类当然要继承装饰类(FilterInputStream),并组合想要装饰的类
其实Reader也有装饰类叫FilterReader,我们通过装饰器模式写一个BufferReader来自己实现一次读一行的能力
class MyBufferedReader extends Reader {
private final Reader in;
public MyBufferedReader(Reader in) {
this.in = in;
}
public String readLine() throws IOException {
StringBuilder sb = new StringBuilder();
while (true) {
int n = in.read();
if (n == '\n') {
break;
}
sb.append((char) n);
}
return sb.toString();
}
@Override
public int read(char[] cbuf, int off, int len) throws IOException {
return 0;
}
@Override
public void close() throws IOException {
in.close();
}
}
public class StreamTest {
public static void main(String[] args) throws IOException {
Reader fileReader = new FileReader("F:\\1.txt");
MyBufferedReader myBufferedReader = new MyBufferedReader(fileReader);
String line = myBufferedReader.readLine();
System.out.println(line);
String line2 = myBufferedReader.readLine();
System.out.println(line2);
}
}
可以看到我并没有改变原来的代码FileReader,但是在它的基础上添加了新的能力
3.1.3 装饰器模式总结
装饰器模式我们一定要记住:装饰器不但要继承需要装饰类的抽象类,还要关联它
3.2 适配器模式
适配器模式
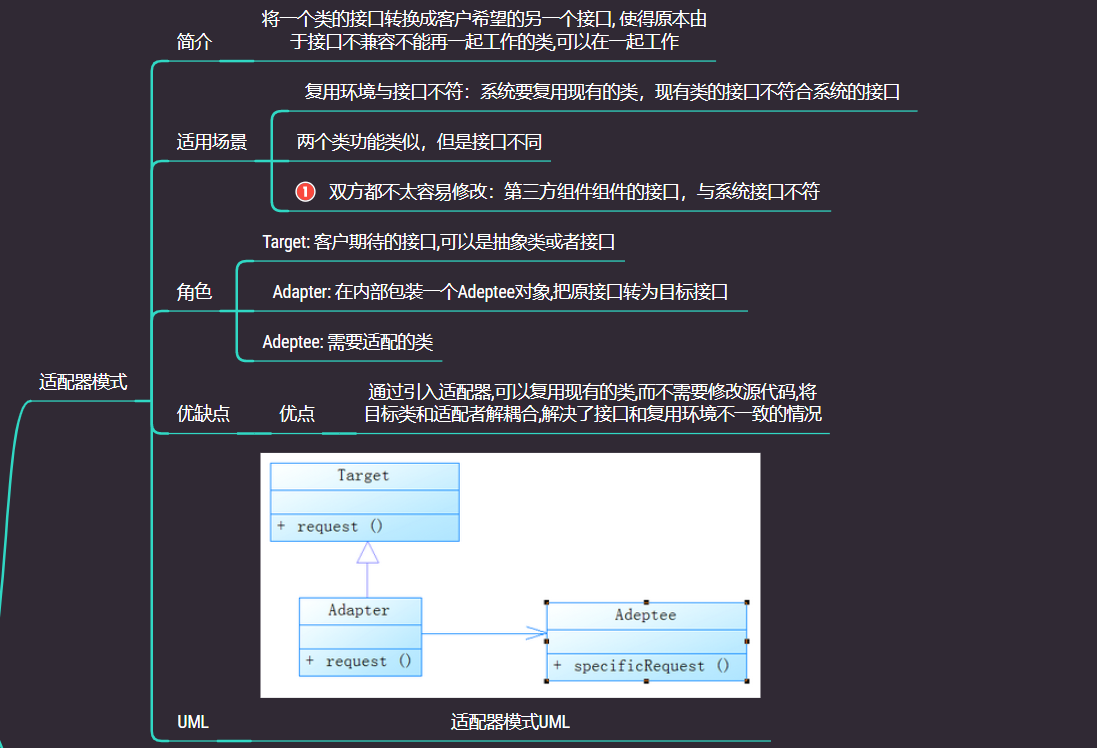
适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁,将一个类的接口转换成客户希望的另一个接口, 使得原本由于接口不兼容不能再一起工作的类,可以在一起工作
主要分为三类:类适配器模式、对象适配器模式、接口适配器模式
适配器我们在生活中经常使用,例如很多油车上面,没有给手机充电的usb口,我们只能去买一个车载充电器

那么代码中的适配器是什么样子的呢?假设我们这里现在有一段祖传的代码,能实现两数相加的功能
class Calc {
public int add(int a, int b) {
return a + b;
}
}
public class AppTest {
public static void main(String[] args) {
Calc calc = new Calc();
System.out.println(calc.add(1,4));
}
}
现在变化来了,客户想要计算三个数的和?该怎么办呢?使用适配器模式我们直接
class CalcAdapter {
// 注意组合优于继承
private final Calc calc;
public CalcAdapter(Calc calc) {
this.calc = calc;
}
public int add(int a, int b, int c) {
return calc.add(calc.add(a, b), c);
}
}
public class AppTest {
public static void main(String[] args) {
CalcAdapter calcAdapter = new CalcAdapter(new Calc());
System.out.println(calcAdapter.add(1, 4, 8));
}
}
好,适配器模式我们就讲完了
开玩笑开玩笑,上面的场景也太简单了,就算是不会设计模式的同学硬想也能想出来,我们看看生产中的适配器是如何操作的
3.2.1 jdk中的适配器模式
基础扎实的同学应该知道其实在java线程里面的Runnable和Callable两个接口也是通过适配转换的
我们随便写一段代码:
public class ThreadTest {
// 线程池,线程任务提交给线程池执行
public static ExecutorService executorService = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 线程池运行Runnable方式
FutureTask<Class<?>> futureTask01 = new FutureTask<>(new Runnable() {
@Override
@SneakyThrows
public void run() {
System.out.println("线程池运行Runnable方式");
Thread.sleep(3000);
}
}, String.class);
executorService.submit(futureTask01);
// 线程池运行Callable方式
FutureTask<String> futureTask02 = new FutureTask<>(new Callable<String>() {
@Override
public String call() throws Exception {
Thread.sleep(3000);
System.out.println("线程池运行Callable方式");
// 返回一句话
return "线程池运行Callable方式返回:" + Thread.currentThread().getName();
}
});
executorService.submit(futureTask02);
System.out.println(futureTask02.get());
}
}
我们看到创建了两种不同类型的任务,一种是基于Runnable接口,是无返回值的任务;一种基于Callable接口,是有返回值类型的任务,但是,请看,居然都可以通过executorService#submit()方法提交到线程池中运行?难道这个方法是一个重载方法吗?
其实我们点进源码里面进行参看,发现居然是同一个方法

看来是FutureTask这个类搞得鬼,接下来我们看FutureTask类的两个构造器
// 使用 Callable 进行初始化
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
// 使用 Runnable 初始化,并传入 result 作为返回结果。
// Runnable 是没有返回值的,所以 result 一般没有用,置为 null 就好了
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
我们看这一行代码Executors.callable(runnable, result),明明写的是Executors#callable,但是传进去的确是一个Runnable,有猫腻,我们进去看看
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
// 在这里进行了适配,将Runnable -> Callable
return new RunnableAdapter<T>(task, result);
}
//RunnableAdapter类
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
发现没有这个类,长得像什么,像适配器,首先它实现了Callable接口,又组合了Runnable接口,并且通过写了一个和Callable同名的call方法将Runnable#run
- 这是非常典型的适配模型,想要把 Runnable 适配成 Callable,首先要实现 Callable 的接口,接着在 Callable 的 call 方法里面调用被适配对象(Runnable)的方法
- 当然也可以将Callable适配成Runnable类,那为什么不呢?因为Callable可以提供更多的方法,例如获取返回值
可能有同学觉得,好像还是很简单,我只要记住适配器类继承要适配对象的抽象类,并组合适配对象就行了,这也不难嘛
确实关键点就是这两步,但是这种解耦、开闭的思想我们一定要融入平时的编码中,不要一上来就去改源代码
3.2.2 Spring中的适配器模式
鉴于有的读者可能觉得上面的栗子还是太简单的原因,这里来看一个稍微复杂一些的适配器模式
Spring中适配器运用的地方也有很多,这里分析两个
- 当SpringMVC处理请求到DispatcherServlet时,会通过HandlerAdapter处理器适配器调用具体的处理器
- AOP中的
AdvisorAdapter,它有三个实现AfterReturningAdviceAdapter、ThrowsAdviceAdapter、MethodBeforeAdviceAdapter
首先第一个SpringMVC中DispatcherServlet类下有一个获得处理器适配器的方法:
protected HandlerAdapter getHandlerAdapter(Object handler) throws ServletException {
if (this.handlerAdapters != null) {
//遍历所有的处理器适配器,找到支持处理当前handler的处理器适配器(HandlerAdapter是一个接口,其实返回的是一个实现HandlerAdapter的子类)
for (HandlerAdapter adapter : this.handlerAdapters) {
if (adapter.supports(handler)) {
return adapter;
}
}
}
throw new ServletException("No adapter for handler [" + handler +
"]: The DispatcherServlet configuration needs to include a HandlerAdapter that supports this handler");
}
public interface HandlerAdapter {
// 判断是否支持当前的适配器
boolean supports(Object handler);
@Nullable
ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception;
long getLastModified(HttpServletRequest request, Object handler);
}
HandlerAdapter适配器的子类有:
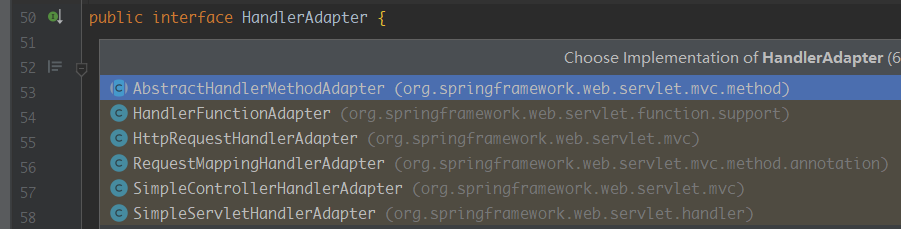
为什么需要这些适配器呢,因为如果处理器的类型不同,有多重实现方式,那么调用方式就不是确定的,如果直接调用 Controller 方法,就得不断使用 if else 来进行判断是哪一种子类然后执行。那么如果后面要扩展 Controller,就得修改原来的代码,这样违背了开闭原则;
- Spring定义了一个适配接口,使得每一种Controller有一种对应的适配器实现类;
- 适配器代替 controller执行相应的方法;
- 扩展Controller时,只需要增加一个适配器类就完成了SpringMVC的扩展
接下来就是切面里的适配器了,我们知道在Spring AOP里面切面一共有五种增强(Advice),分别是:
- 前置通知(前置增强) - before() 执行方法前通知
- 返回通知(返回增强) - afterReturn 方法正常结束返回后的通知
- 异常抛出通知(异常抛出增强)一afetrThrow()
- 最终通知一after无论方法是否发生异常,均会执行该通知。
- 环绕通知——around包围一一个连接点(join point)的通知,如方法调用。这是最强大的一种通知类型。环绕通知可以在方法调用前后完成自定义的行为。它也会选择是否继续执行连接点或直接返回它们自己的返回值或
我们想想这些Advice难道全部是不一样的逻辑吗?其实不是,我们其实只需要写一个总的钩子函数,分别在上述的五个地方进行拦截,当预留五个适配器,分别调用总的钩子函数对应位置的逻辑即可,总的思想类似于线程池有七个参数,但是我们可以通过其内置函数调用少于七个参数的方法,间接调用最大的那个方法
这里不展开看源码了,我们看一看适配器的部分就行
public interface AdvisorAdapter {
//判断通知类是否匹配
boolean supportsAdvice(Advice advice);
//传入通知类,返回对应的拦截类
MethodInterceptor getInterceptor(Advisor advisor);
}
class MethodBeforeAdviceAdapter implements AdvisorAdapter, Serializable {
//判断是否匹配MethodBeforeAdvice通知类
@Override
public boolean supportsAdvice(Advice advice) {
return (advice instanceof MethodBeforeAdvice);
}
//传入MethodBeforeAdvice,转换为MethodBeforeAdviceInterceptor拦截类
@Override
public MethodInterceptor getInterceptor(Advisor advisor) {
MethodBeforeAdvice advice = (MethodBeforeAdvice) advisor.getAdvice();
return new MethodBeforeAdviceInterceptor(advice);
}
}
public class MethodBeforeAdviceInterceptor implements MethodInterceptor, Serializable {
//成员变量,通知类
private MethodBeforeAdvice advice;
//定义了有参构造器,外部通过有参构造器创建MethodBeforeAdviceInterceptor
public MethodBeforeAdviceInterceptor(MethodBeforeAdvice advice) {
Assert.notNull(advice, "Advice must not be null");
this.advice = advice;
}
//当调用拦截器的invoke方法时,就调用通知类的before()方法,实现前置通知
@Override
public Object invoke(MethodInvocation mi) throws Throwable {
//调用通知类的before()方法,实现前置通知
this.advice.before(mi.getMethod(), mi.getArguments(), mi.getThis() );
return mi.proceed();
}
}
3.2.3 适配器模式总结
3.3 代理模式
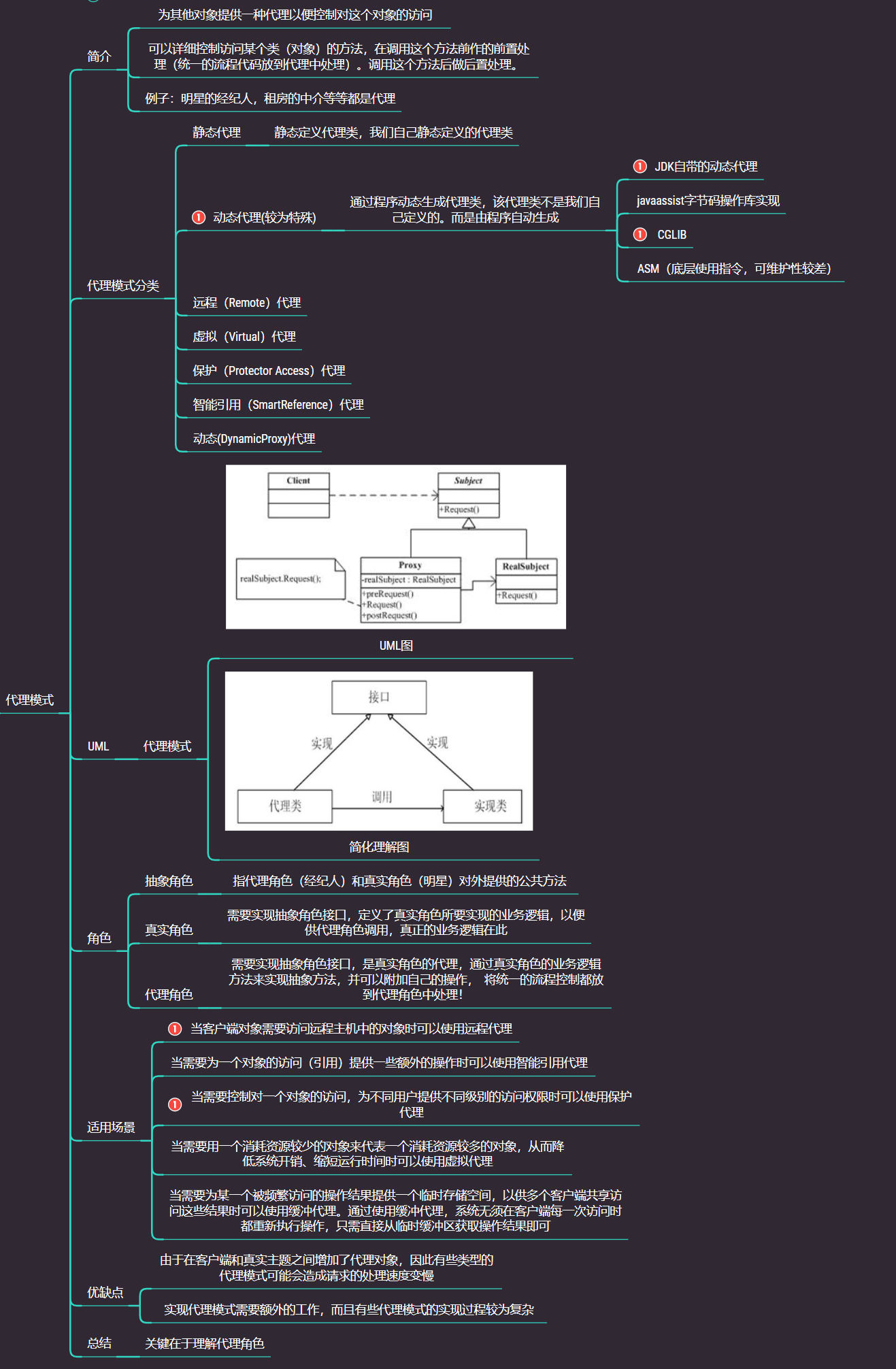
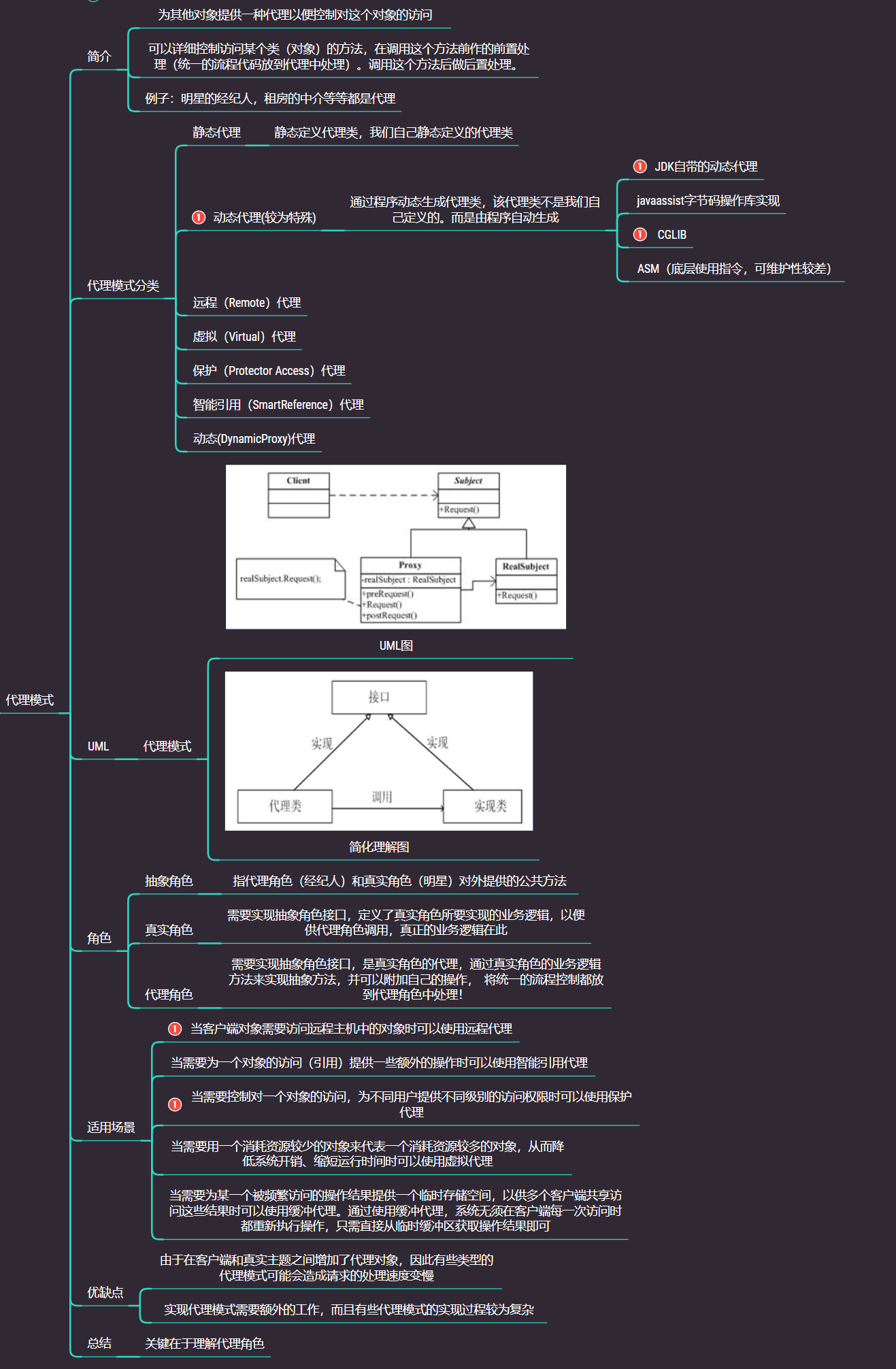
代理模式
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这种类型的设计模式属于结构型模式。
在代理模式中,我们创建具有现有对象的对象,以便向外界提供功能接口
代理模式真的用的太多了,我愿称之为框架中的模式NO1
3.3.1 问题引入
现在我们手上有一个计算器类,一共有四个方法:
interface Calculate {
int add(int x, int y);
int reduce(int x, int y);
int multiply(int x, int y);
double divide(int x, int y);
}
class CalculateImpl implements Calculate {
public int add(int x, int y) {
return (x + y);
}
public int reduce(int x, int y) {
return (x - y);
}
public int multiply(int x, int y) {
return x * y;
}
@Override
public double divide(int x, int y) {
return x / y;
}
}
public class AppTest {
public static void main(String[] args) {
Calculate calculate = new CalculateImpl();
System.out.println(calculate.add(1, 4));
System.out.println(calculate.reduce(1, 4));
System.out.println(calculate.multiply(1, 4));
System.out.println(calculate.divide(1, 4));
}
}
假设我们现在想要统计这四个方法的耗时情况,该怎么做?
- 通过适配器模式装换接口,并在新的适配类中统一记录耗时情况
- 多写一些子类来完成
我只能说上面的方法也可以,但是不够优雅,这里才四个方法,如果有四千个呢?有的同学会问怎么可能有四千个方法,我只能说too young to simple,一个商业项目里面的接口有个小几万个太正常不过了,如果想对这些方法做增强,用我们之前学的所有设计模式都完不成,必须要用动态代理,物理上完不成,我们就得用魔法——动态代理 + 发射
3.3.2 jdk动态代理
我们先学一下jdk中动态代理的api,看如何使用动态代理,先别问为什么,先把api记住,我们可以通过Proxy类创建一个代理类
Proxy.newProxyInstance()
有三个参数,分别是:

- 类加载器:要创建一个类的实例(在类构造器被执行之前),需要通过类加载器将这个类的字节码文件加载到JVM中(也可以说是从磁盘加载到内存中)
- 传入要代理类的接口的字节码文件,因为可以通过传入不同的字节码生成不同的对象,所以称之为动态代理
- 我们传入的是接口的字节码文件,生成的代理类势必需要实现接口里面的方法,那么这些方法被实现的方法体具体是什么内容呢?这恰恰就是由第三个参数决定的
可能有点蒙,我们看下面具体的代码
class MyHandle implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("呵呵哒");
return 0;
}
}
public class AppTest {
public static void main(String[] args) {
// 创建代理对象
Class<?>[] interfaceClass = {ICalculate.class};
ICalculate proxy = (ICalculate) Proxy.newProxyInstance(AppTest.class.getClassLoader(), interfaceClass, new MyHandle());
System.out.println(proxy.add(1, 3));
}
}
我们现在来思考,这样创建的代理对象在执行proxy.add(1, 3)时,是会执行ICalculate接口里面的add方法吗?还是MyHandle#invoke方法,我们运行一下就可以知道,是执行MyHandle#invoke里面的方法
proxy.add(1, 3);
proxy.reduce(1, 3);
proxy.multiply(1, 3);
proxy.divide(1, 3);
// 输出
呵呵哒
呵呵哒
呵呵哒
呵呵哒
小结一下这个api的使用,Proxy#newProxyInstance()一共有三个参数,分别是类加载器,用来加载接口类的字节码;接口类数组的字节码,用来动态代理生成不同的对象;接口中方法的实现方法体,即执行代理类的方法时,会调用传入的InvocationHandler
接下来我们看InvocationHandler的参数,这个参数就简单多了,例如我执行方法是proxy.add(1, 2),那么对应的就是:
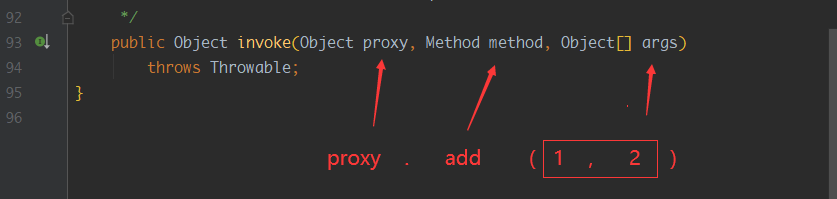
证明一下:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(String.format("方法名为:%s,参数为:%s", method.getName(), Arrays.toString(args)));
return 0;
}
// 输出
方法名为:add,参数为:[1, 3]
方法名为:reduce,参数为:[1, 3]
方法名为:multiply,参数为:[1, 3]
方法名为:divide,参数为:[1, 3]
是不是感觉很简单!动态代理不过如此,我们可以通过反射调用方法,并且加入我们计算耗时的逻辑
class MyHandle implements InvocationHandler {
private final Object target;
public MyHandle(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(String.format("方法名为:%s,参数为:%s", method.getName(), Arrays.toString(args)));
long start = System.currentTimeMillis();
// 利用反射调用真实方法
Object result = method.invoke(target, args);
System.out.println(String.format("耗时:%s ms", System.currentTimeMillis() - start));
// 返回到代理对象的方法调用处
return result;
}
}
public class AppTest {
public static void main(String[] args) {
ICalculate iCalculate = new CalculateImpl();
// 创建代理对象,需要三个参数,分别是
Class<?>[] interfaceClass = {ICalculate.class};
ICalculate proxy = (ICalculate) Proxy.newProxyInstance(AppTest.class.getClassLoader(), interfaceClass, new MyHandle(iCalculate));
System.out.println(proxy.add(1, 3));
System.out.println(proxy.reduce(1, 3));
System.out.println(proxy.multiply(1, 3));
System.out.println(proxy.divide(1, 3));
}
}
输出:
方法名为:add,参数为:[1, 3]
耗时:0 ms
4
方法名为:reduce,参数为:[1, 3]
耗时:0 ms
-2
方法名为:multiply,参数为:[1, 3]
耗时:0 ms
3
方法名为:divide,参数为:[1, 3]
耗时:0 ms
0.0
好代理模式讲完了

怎么可能,就学了一个api就完了???这搞得比工厂模式还简单了。当然不是,这才学了一个API,这都还没到模式的这一步,这才哪到哪,六分之一的内容都还没到
我们来想想这样的缺点是什么?
- 太复杂了,有的用户不会使用动态代理
- 代码耦合了,每次需要去修改代理类里面的处理逻辑
那我们再封装封装,让用户开箱即用
3.3.3 封装jdk动态代理帮助类
我们来封装封装上面的代码
我们定义一个接口,用来描述代理类对应方法执行前后需要拓展执行的方法,其实这种接口我们喜欢将其称之为:切面,也可以定义为Interceptor拦截器
interface Aspect {
void before(Object target, Method method, Object[] args);
void after(Object target, Method method, Object[] args, Object returnVal);
}
在我们的handle上添加切面
class MyHandle implements InvocationHandler {
private final Object target;
private final Aspect aspect;
public MyHandle(Object target, Aspect aspect) {
this.target = target;
this.aspect = aspect;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 方法执行前的钩子函数
aspect.before(target, method, args);
Object result = method.invoke(target, args);
// 方法执行后的钩子函数
aspect.after(target, method, args, result);
// 返回到代理对象的方法调用处
return result;
}
}
代理类:
class MyProxy {
public static Object getProxy(Object cls, Aspect aspect) {
// 拿到代理对象实现的所有接口字节码
Class<?>[] interfaceClass = cls.getClass().getInterfaces();
return Proxy.newProxyInstance(cls.getClass().getClassLoader(), interfaceClass, new MyHandle(cls, aspect));
}
}
使用:
public class AppTest {
public static void main(String[] args) {
ICalculate iCalculate = new CalculateImpl();
// 创建代理对象,需要三个参数,分别是
ICalculate proxy = (ICalculate) MyProxy.getProxy(iCalculate, new Aspect() {
@Override
public void before(Object target, Method method, Object[] args) {
System.out.println(String.format("方法名为:%s,参数为:%s", method.getName(), Arrays.toString(args)));
}
@Override
public void after(Object target, Method method, Object[] args, Object returnVal) {
System.out.println(String.format("返回结果为:%s", returnVal.toString()));
}
});
System.out.println(proxy.add(1, 3));
System.out.println(proxy.reduce(1, 3));
System.out.println(proxy.multiply(1, 3));
System.out.println(proxy.divide(1, 3));
}
}
// 输出
方法名为:add,参数为:[1, 3]
返回结果为:4
4
方法名为:reduce,参数为:[1, 3]
返回结果为:-2
-2
方法名为:multiply,参数为:[1, 3]
返回结果为:3
3
方法名为:divide,参数为:[1, 3]
返回结果为:0.0
0.0
可以看到这样就简单了很多,应对不同的需求我们就去定制不同的代理类和切面类,实现不同的需求。有兴趣的同学可以去看hutool工具包下面封装的代理工具类,那个工具类封装更多的方法,而且中文注释,挺好理解的
好代理模式讲完了(梅开二度😜),上面只是简单的封装,其实还没有到代理模式的核心,我们来看看上面代理模式的缺点:
- 首先jdk动态代理基于
接口,如果想要代理的对象没有并没有实现接口,就无法代理 - 你会发现,代理类的所有方法都被加强了,也就是说任何一个方法执行都会调用
Aspect里面的逻辑,没有选择的余地了
首先第二个问题,读者可以将MyHandle也单独拆出来,如果只想要执行一个或多个方法,通过打标记的方式,例如传入add方法后拿着执行方法比较一下,再执行,或者使用适配器模式做适配类,再或者在Aspect里面做判断,这些都比较简单,这里不演示了,需要注意的是:
- 一般框架中切面都是将职责进行细分了的,并用集合存起来,实现某个接口就能拿到这个集合,再将自己的切面或者说拦截器放进去,就能执行响应的功能
但是其实无论怎么做,还是会依赖于具体类里面具体的方法,还不是不够理想,读者写别急,解决方案其实是SpringAOP里面的Spring动态代理,通过用注解给需要执行的方法做标记的方式执行代理,有点类似于简单工厂中Spring解决的问题
我们来看第一个问题如何解决
3.3.4 Cglib动态代理
其实没有实现接口就无法代理的问题,也是jdk动态代理的问题,解决方法就是换成cglib动态代理,cglib是基于类的动态代理,它的原理是对指定的目标类生成一个子类, 并覆盖其中方法实现增强,但因为采用的是继承,所 以不能对final修饰的类进行代理。
在pom.xml文件中引入cglib的相关依赖
<!-- https://mvnrepository.com/artifact/cglib/cglib -->
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>2.2.2</version>
</dependency>
定义类
public class CglibInterceptor implements MethodInterceptor {
//目标对象
private Object target;
//通过构造器传入目标对象
public CglibInterceptor(Object target) {
this.target = target;
}
/**
* 获得代理对象
* @return 返回一个代理对象
*/
public Object getProxy(){
//1. 通过Enhancer对象中的create()方法生成一个类,用于生成代理对象
Enhancer enhancer=new Enhancer();
//2. 设置父类(将目标类作为代理类的父类)
enhancer.setSuperclass(target.getClass());
//3. 设置拦截器,回调对象为本身对象
enhancer.setCallback(this);
//4. 生成代理类对象,并返回给调用者
return enhancer.create();
}
/**
* 拦截器:
* 1. 目标对象的方法调用
* 2. 行为增强
* @param o cglib生成的动态代理类的实例
* @param method 实体类被调用的被代理的方法的应用
* @param objects 参数列表
* @param methodProxy 生成的代理类,对方法的代理应用
* @return 返回行为增强后的代理对象
* @throws Throwable 抛出异常给系统
*/
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
//增强行为
System.out.println("intercept方法执行前的增强行为");
//调用目标类中的方法
Object object = methodProxy.invoke(target, objects);
//增强行为
System.out.println("intercept方法执行后的增强行为");
return object;
}
}
可以看到其实都只是API的调用,多看几遍就能够理解清楚
3.3.5 JDK动态代理和CGLIB代理的区别
- JDK动态代理实现接口,Cglib动态代理继承思想
- JDK动态代理( 目标对象存在接口时)执行效率高于Ciglib
- 如果目标对象有接口实现,选择JDK代理, 如果没有接口实现选择Cglib代理
最优选择:如果目标对象存在接口实现,优先选择JDK动态代理,反之这选择cglib动态代理
3.3.6 Spring中的代理模式
TODO
3.3.7 Dubbo中的代理模式
TODO
3.3.8 代理模式总结
3.4 桥接模式
桥接模式
桥接(Bridge)是用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。
4. 行为型模式
行为型模式
行为型模式设计模式特别关注对象之间的通信
4.1 策略模式
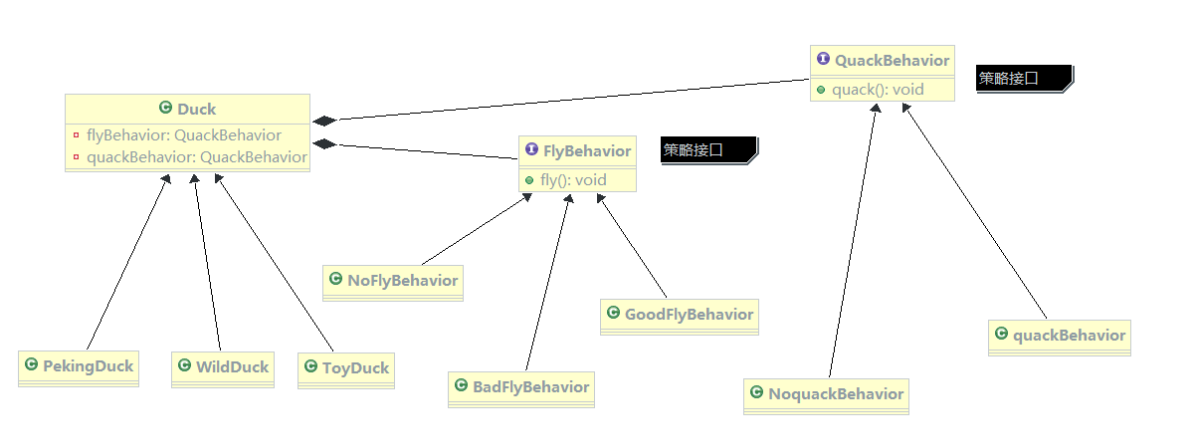
策略模式
策略模式(Strategy Pattern)中,定义算法族,分别封装起来,让他们之间可以互相替换,此模式让算法的变化独立于使用算法的客户
4.1.1 问题引入
现在我们有一个Duck抽象类,它有四个方法:
public abstract void display();// 抽象方法
public void quack() {
System.out.println("鸭子嘎嘎叫~~");
}
public void swim() {
System.out.println("鸭子会游泳~~");
}
public void fly() {
System.out.println("鸭子会飞翔~~");
}
现在我们给其添加三个子类
- WildDuck 野鸭
- PekingDuck 北京鸭
- ToyDuck 玩具鸭
现在问题产生了:
- 野鸭不需要重写父类的方法
- 北京鸭需要重写父类的fly方法,因为北京鸭不会飞
- ToyDuck需要重写父类的所有方法,这跟我们想要通过继承来复用代码的想法背道相驰
问题总结:由于继承带来的问题,对类的局部改动,尤其是超类的改动,会影响其他部分。会有溢出效应
4.1.2 策略模式解决问题的核心
通过将继承改成组合+聚和的方式,来减少溢出效应
- 把变化的代码从不变的代码中分离出来
- 针对接口编程而不是具体类(定义
策略接口) - 多用组合/聚和,少用继承(客户通过组合方式使用策略)
4.1.3 策略模式原理
从下面的类图可以看到,客户context有成员便令strategy或者其他的策略接口,至于需要使用到哪个策略,我们可以在构造器中指定
栗子代码:
public abstract class Duck {
FlyBehavior flyBehavior;// 定义策略接口
// 其他属性也可以声明为策略接口
public Duck() {
}
public void setFlyBehavior(FlyBehavior flyBehavior) {
this.flyBehavior = flyBehavior;
}
public abstract void display();
public void quack() {
System.out.println("鸭子嘎嘎叫~~");
}
public void swim() {
System.out.println("鸭子会游泳~~");
}
public void fly() {
// 改进
if (flyBehavior != null) {
flyBehavior.fly();
}
}
public class PekingDuck extends Duck {
public PekingDuck() {
flyBehavior = new NoFlyBehavior();
}
@Override
public void display() {
System.out.println("北京鸭~~");
}
}
测试类:
public class Client {
public static void main(String[] args) {
new WildDuck().fly();
PekingDuck pekingDuck = new PekingDuck();
pekingDuck.fly();
// 动态改变其行为
pekingDuck.setFlyBehavior(new BadFlyBehavior());
pekingDuck.fly();
new ToyDuck().fly();
}
}
打印结果:
飞翔技术很好
不能飞翔
飞翔技术不好
不能飞翔
4.1.4 策略模式在JDK中的应用
- JDK的Arrays的Comparator就使用了策略模式
- 代码分析+Debug源码+模式角色分析
- 在JDK中的Comparator中运用到了策略接口(策略模式)
Integer[] data={9,1,2,8,4,3};
//需求,实现升序排列,返回-1放左边,1放右边,0保持不变
//实现了策略接口的对象
Comparator<Integer> comparator= (o1, o2) -> {
if(o1 > o2) {
return 1;//自定义策略
}else if(o1 < o2){
return -1;
}else {
return 0;
}
};
4.1.5 策略模式总结

I的调用,多看几遍就能够理解清楚
3.3.5 JDK动态代理和CGLIB代理的区别
- JDK动态代理实现接口,Cglib动态代理继承思想
- JDK动态代理( 目标对象存在接口时)执行效率高于Ciglib
- 如果目标对象有接口实现,选择JDK代理, 如果没有接口实现选择Cglib代理
最优选择:如果目标对象存在接口实现,优先选择JDK动态代理,反之这选择cglib动态代理
3.3.6 Spring中的代理模式
TODO
3.3.7 Dubbo中的代理模式
TODO
3.3.8 代理模式总结
3.4 桥接模式
桥接模式
桥接(Bridge)是用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。
4. 行为型模式
行为型模式
行为型模式设计模式特别关注对象之间的通信
4.1 策略模式
策略模式
策略模式(Strategy Pattern)中,定义算法族,分别封装起来,让他们之间可以互相替换,此模式让算法的变化独立于使用算法的客户
4.1.1 问题引入
现在我们有一个Duck抽象类,它有四个方法:
public abstract void display();// 抽象方法
public void quack() {
System.out.println("鸭子嘎嘎叫~~");
}
public void swim() {
System.out.println("鸭子会游泳~~");
}
public void fly() {
System.out.println("鸭子会飞翔~~");
}
现在我们给其添加三个子类
- WildDuck 野鸭
- PekingDuck 北京鸭
- ToyDuck 玩具鸭
现在问题产生了:
- 野鸭不需要重写父类的方法
- 北京鸭需要重写父类的fly方法,因为北京鸭不会飞
- ToyDuck需要重写父类的所有方法,这跟我们想要通过继承来复用代码的想法背道相驰
问题总结:由于继承带来的问题,对类的局部改动,尤其是超类的改动,会影响其他部分。会有溢出效应
4.1.2 策略模式解决问题的核心
通过将继承改成组合+聚和的方式,来减少溢出效应
- 把变化的代码从不变的代码中分离出来
- 针对接口编程而不是具体类(定义
策略接口) - 多用组合/聚和,少用继承(客户通过组合方式使用策略)
4.1.3 策略模式原理
从下面的类图可以看到,客户context有成员便令strategy或者其他的策略接口,至于需要使用到哪个策略,我们可以在构造器中指定
我们可以在构造器中指定
栗子代码:
public abstract class Duck {
FlyBehavior flyBehavior;// 定义策略接口
// 其他属性也可以声明为策略接口
public Duck() {
}
public void setFlyBehavior(FlyBehavior flyBehavior) {
this.flyBehavior = flyBehavior;
}
public abstract void display();
public void quack() {
System.out.println("鸭子嘎嘎叫~~");
}
public void swim() {
System.out.println("鸭子会游泳~~");
}
public void fly() {
// 改进
if (flyBehavior != null) {
flyBehavior.fly();
}
}
public class PekingDuck extends Duck {
public PekingDuck() {
flyBehavior = new NoFlyBehavior();
}
@Override
public void display() {
System.out.println("北京鸭~~");
}
}
测试类:
public class Client {
public static void main(String[] args) {
new WildDuck().fly();
PekingDuck pekingDuck = new PekingDuck();
pekingDuck.fly();
// 动态改变其行为
pekingDuck.setFlyBehavior(new BadFlyBehavior());
pekingDuck.fly();
new ToyDuck().fly();
}
}
打印结果:
飞翔技术很好
不能飞翔
飞翔技术不好
不能飞翔
4.1.4 策略模式在JDK中的应用
- JDK的Arrays的Comparator就使用了策略模式
- 代码分析+Debug源码+模式角色分析
- 在JDK中的Comparator中运用到了策略接口(策略模式)
Integer[] data={9,1,2,8,4,3};
//需求,实现升序排列,返回-1放左边,1放右边,0保持不变
//实现了策略接口的对象
Comparator<Integer> comparator= (o1, o2) -> {
if(o1 > o2) {
return 1;//自定义策略
}else if(o1 < o2){
return -1;
}else {
return 0;
}
};
4.1.5 策略模式总结
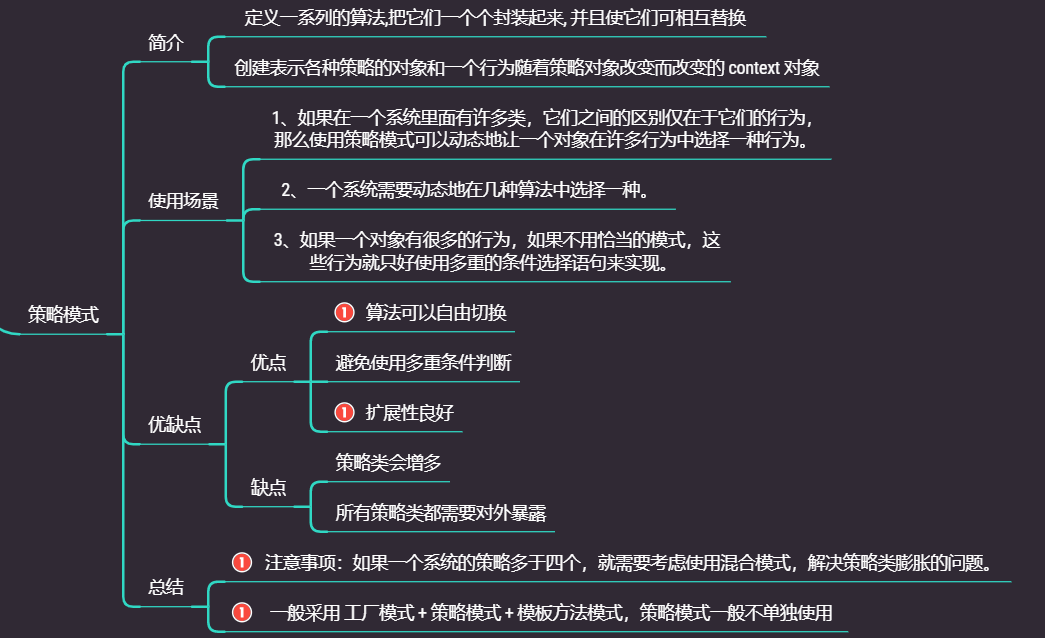
相关文章
- vue—你必须知道的 js数据类型 前端学习 CSS 居中 事件委托和this 让js调试更简单—console AMD && CMD 模式识别课程笔记(一) web攻击 web安全之XSS JSONP && CORS css 定位 react小结
- (《机器学习》完整版系列)第6章 支持向量机SVM——6.2 核函数型支持向量机SVM(方法:与基本型比较来学习)
- 【学习笔记22】JavaScript数组的练习题
- 内行,阿里大牛离职带出内部“高并发系统设计”学习手册
- Java23种设计模式学习笔记【目录总贴】
- 学习笔记——进程间通信之管道详解
- Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息
- NVIDIA公司推出的GPU运行环境下的机器人仿真环境(NVIDIA Isaac Gym)的安装要求——强化学习的仿真训练环境
- Linux学习进阶示意图
- 【机器学习面试】百面机器学习笔记和问题总结+扩展面试题
- Python学习---重点模块之logging
- 【八天成为红帽工程师】第八天 学习编写playbook
- 跟屌丝大哥学习设计模式--生成器模式(Builder)
- 跟屌丝大哥学习设计模式---代理模式
- 《Head First 设计模式》学习笔记——观察者模式 + 装饰者模式
- 机器学习——支持向量机SVM实例(兵王问题,SVM求解步骤以及思路,不求解不编程)