
数据结构——树Ⅰ
2023-09-11 14:22:32 时间
1.概述
树: 由n(n>=1)个有限结点组成一个具有层次关系的集合。
特点:
- 每个结点有零个或多个子结点;
- 没有父结点的结点为根结点;
- 每一个非根结点只有一个父结点;
- 每个结点及其后代结点整体上可以看做是一棵树,称为当前结点的父结点的一个子树;
相关术语:
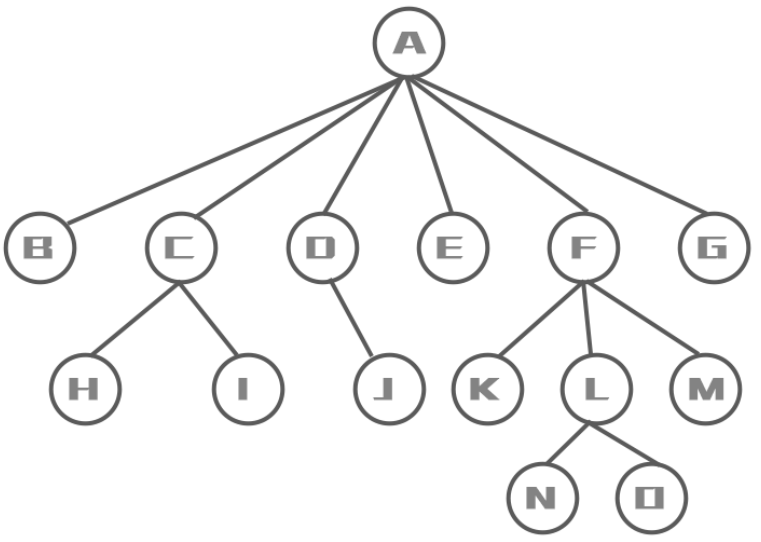
- 结点的度:
一个结点含有的子树的个数
A结点的度为6 - 叶结点(终端结点):
度为0的结点
如:B、H、I、J、K、N、O、M - 分支结点(非终端结点):
度不为0的结点 - 结点的层次:
从根结点开始,根结点的层次为1,之后每一层+1
如:A的层次为1,N的层次为4 - 结点的层序编号:
将树中的结点,按照从上层到下层,同层从左到右的次序排成一个线性序列,把他们编成连续的自然数
如:A:0、B:1、H:8 - 树的度:
树中所有结点的度的最大值
此树中A结点的度最大为6,故树的度为6 - 树的高度(深度):
树中结点的最大层次
此树中N、O结点层次最大,为4,故树的高度为4 - 森林:
多个互不相交的树的集合。将一个非空树的根节点去掉就形成了森林,给一个森林加一个统一的根节点即形成树
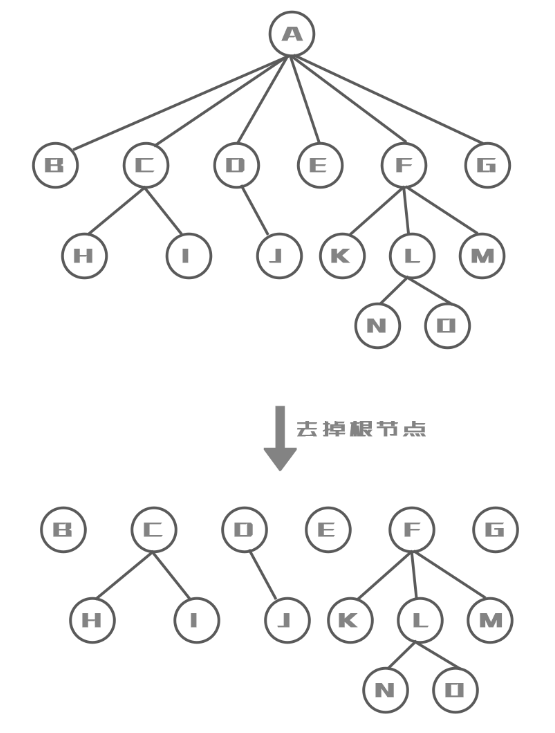
- 孩子结点:
一个结点的直接后继结点
如:I、H都是C的孩子结点 - 双亲结点(父结点):
一个结点的直接前驱
如:C是H、I的双亲结点 - 兄弟结点:
同一双亲结点的孩子结点
如:I、H是兄弟结点
2.二叉树
2.1 概述
二叉树: 度不超过2的树
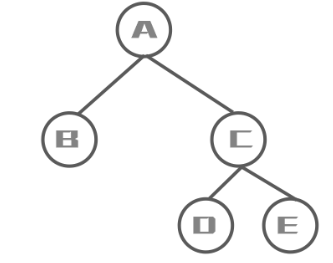
满二叉树: 一个二叉树,如果每一个层的结点的度都达到最大值,则这个二叉树就是满二叉树
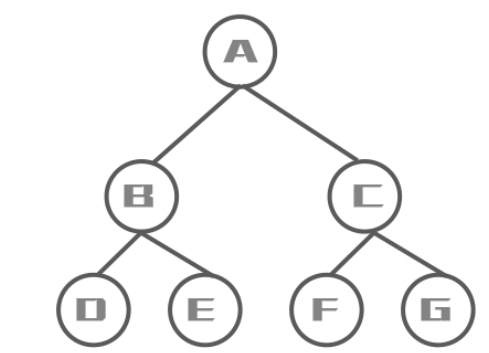
完全二叉树: 叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
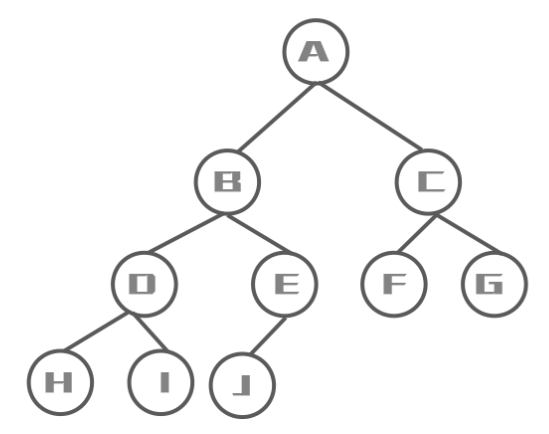
2.2 写一个二叉树
二叉树本质就是由一个一个的结点及其之间的关系组成
二叉查找树(链表实现)
二叉查找树: 小的放在左边,大的放在右边
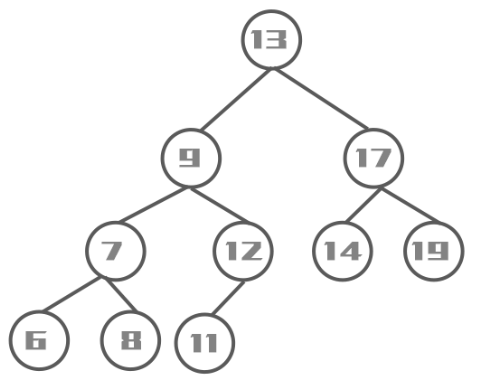
方法图示:
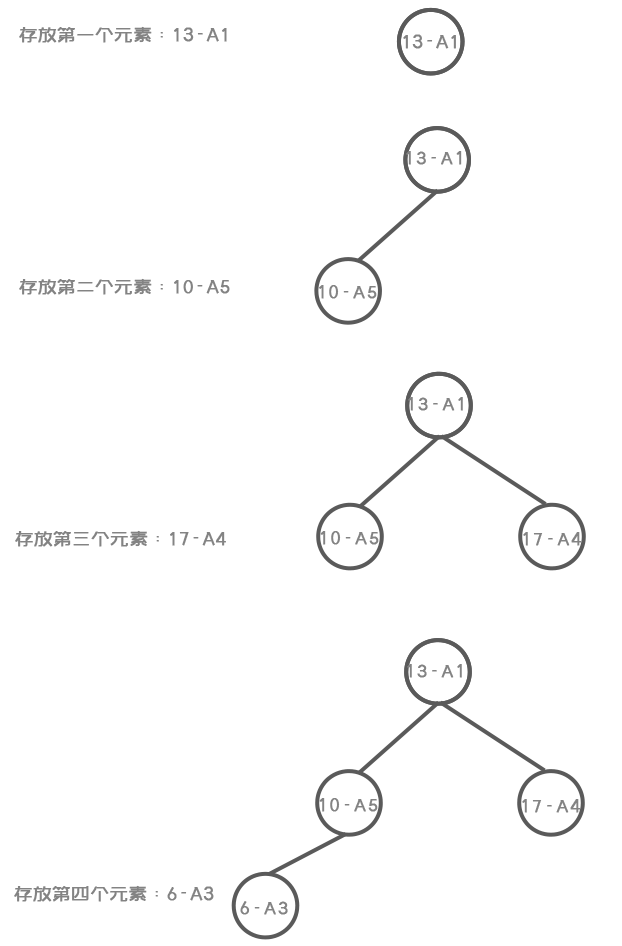
- put()
-
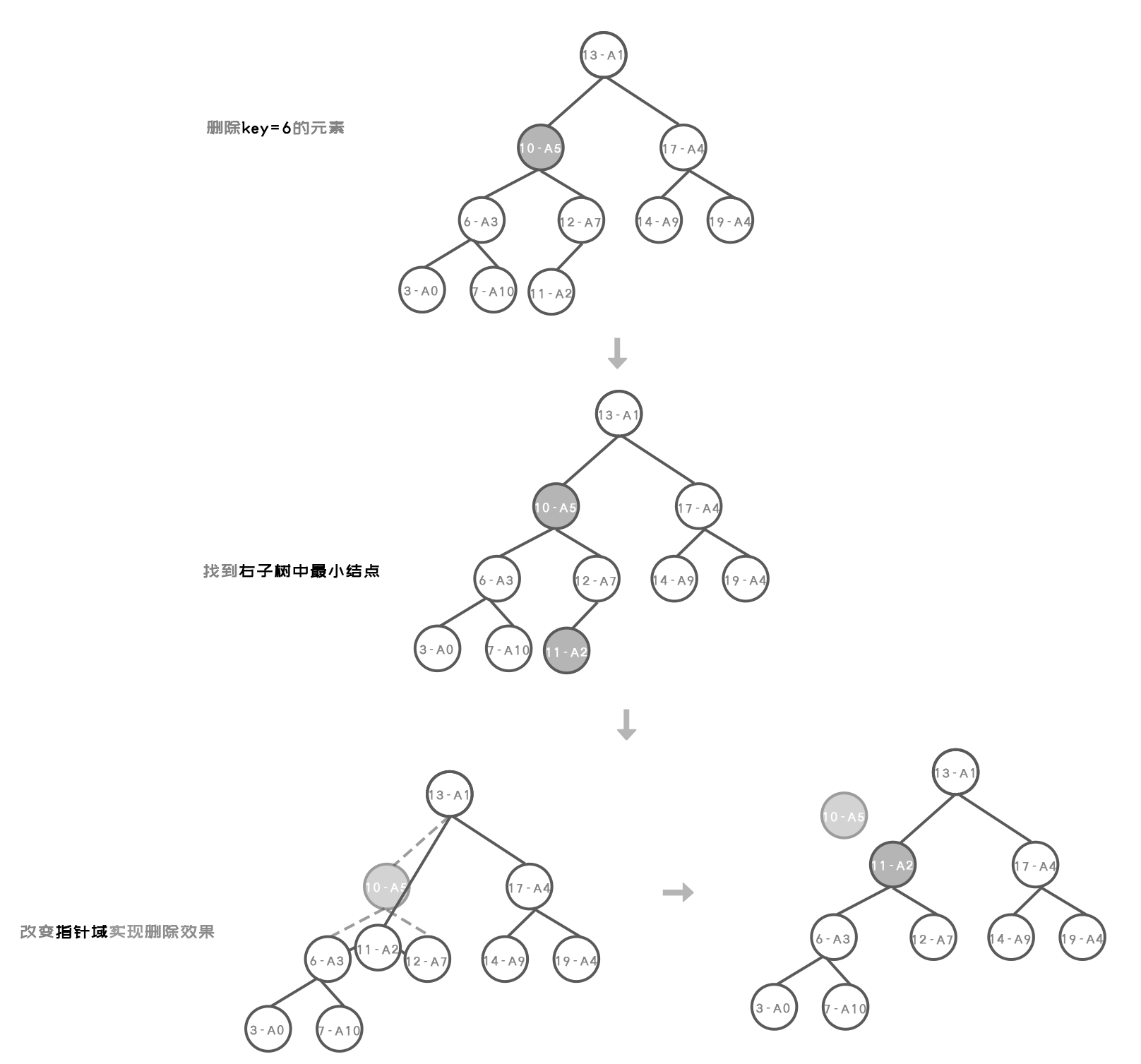
delete()
-
get()
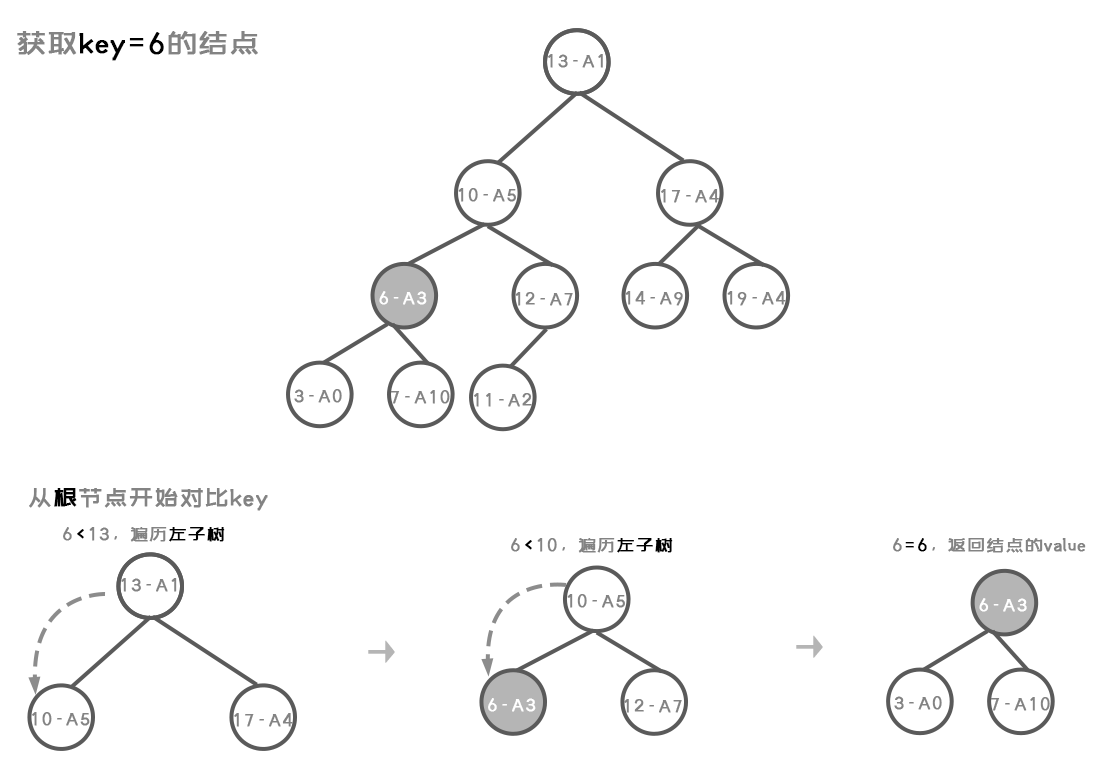
代码实现:
- 定义一个节点类
/**
* 二叉树节点类
* @param <Key>
* @param <Node>
*/
public class Node<Key,Value> {
//存储键
private Key key;
//存储值
private Value value;
//记录左子节点
private Node left;
//记录右子节点
private Node right;
public Node(Key key, Value value, Node left, Node right) {
this.key = key;
this.value = value;
this.left = left;
this.right = right;
}
}
- 顺序二叉树的实现
package tree;
//通过Key实现foreach
public class BinaryTree <Key extends Comparable<Key>,Value>{
//内部结点类
private class Node{
//键
public Key key;
//值
public Value value;
//左子节点
public Node left;
//右子结点
public Node right;
public Node(Key key, Value value, Node left, Node right) {
this.key = key;
this.value = value;
this.left = left;
this.right = right;
}
}
//根节点
private Node root;
//元素个数
private int N;
//获取元素个数
public int size(){
return N;
}
//向树中存储键值对
public void put(Key key,Value value){
root = put(root,key,value);
}
/**
* 使用 递归 实现向指定位置的结点(树)插入数据
* 树根据key的大小排序插入数据,大的在右,小的在左
* @param x 树的结点(从根节点开始),用于遍历
* @param key 待插入数据的key
* @param value 待插入数据的value
* @return 返回实现插入的结点x给上一个put方法
*/
public Node put(Node x,Key key,Value value) {
if (x == null){
N++;
return new Node(key,value,null,null);
}
int cmp = key.compareTo(x.key);
if (cmp > 0){
//往右子树遍历
x.right = put(x.right,key,value);
}else if (cmp < 0){
//往左子树遍历
x.left = put(x.left,key,value);
}else {
//覆盖结点数据
x.value = value;
}
return x;
}
//查询树中指定key对应的value
public Value get(Key key){
return get(root,key);
}
//从指定的结点(树)中查找key对应的value
public Value get(Node x,Key key){
if (x == null){
return null;
}
int cmp = key.compareTo(x.key);
if (cmp > 0){
//往右子树遍历
return get(x.right,key);
}
if (cmp < 0){
//往左子树遍历
return get(x.left,key);
}else {
return x.value;
}
}
//删除指定key对应的结点
public void delete(Key key){
root = delete(root,key);
}
/**
* 通过递归实现树删除指定key的结点(改变指针域)
*
* @param x 树的结点(从根节点开始),用于遍历寻找目的结点,并实现指针域更改
* @param key 目标结点对应的key
* @return 返回新树给上一个delete方法
*/
public Node delete(Node x,Key key){
if (x == null){
return null;
}
//寻找目标结点
int cmp = key.compareTo(x.key);
if (cmp > 0){
//往右子树遍历
return delete(x.right,key);
}else if (cmp < 0){
return delete(x.left,key);
}else {
/*
目标结点的key等于当前结点的key,当前结点就是要删除的结点
1.当前结点右子树不存在,直接返回左子树
2.当前结点左子树不在,直接返回右子树
3.当前结点左右子树都在
3.1 找到右子树中key最小的结点
3.2 删除右子树中key最小的节点
*/
if (x.right == null){
return x.left;
}
if (x.left == null){
return x.right;
}
//从右子树中找到key最小的结点
Node minNode = x.right;
while (minNode.left != null){
minNode = minNode.left;
}
/*
删除右子树中最小的结点:
1.首先往右子树的左子树遍历找到右子树中的最小节点node
2.交换结点之间的指针域,实现删除
*/
Node node = x.right;
while (node.left != null){
if (node.left.left == null){
node.left = null;
}else {
node = node.left;
}
}
minNode.left = x.left;
minNode.right = x.right;
x = minNode;
//个数-1
N--;
}
return x;
}
}
2.3 二叉树的遍历
前序遍历
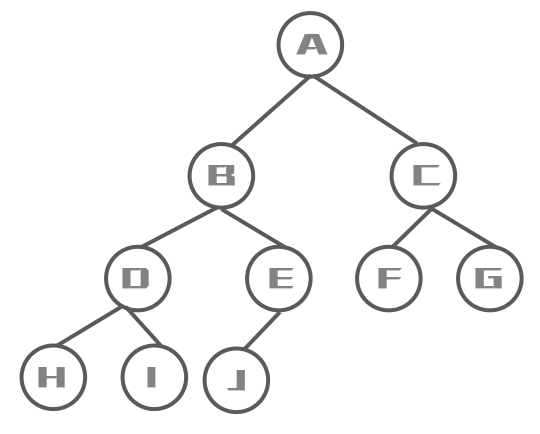
先访问根结点,然后再访问左子树,最后访问右子树
遍历结果:A B D H I E J C F G
代码实现:
在二叉树类中添加方法
private void preErgodic(Node node,List<Key> list){
if (node == null){
return;
}
//将当前结点的key放入链表
list.add(node.key);
//先遍历左子树
if (node.left != null){
preErgodic(node.left,list);
}
//再遍历左子树
if (node.right != null){
preErgodic(node.right,list);
}
}
测试代码:
public static void main(String[] args) {
BinaryTree<Integer,String > tree = new BinaryTree<>();
tree.put(7,"张三");
tree.put(4,"李四");
tree.put(3,"王五");
tree.put(5,"熊二");
tree.put(9,"光头强");
tree.put(6,"熊大");
tree.put(8,"翠花");
List<Integer> list = tree.preErgodic();
for (int i:list){
System.out.println(i + ":" + tree.get(i));
}
}
中序遍历
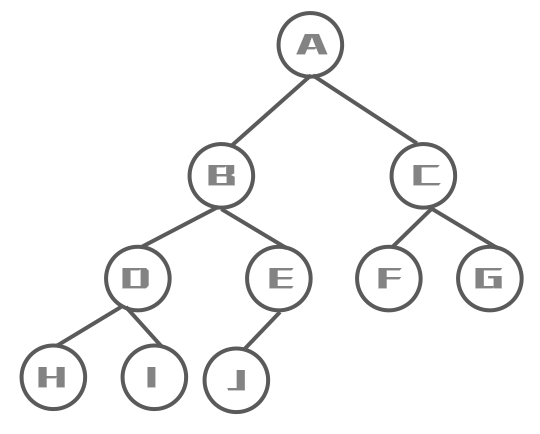
先访问左子树,再访问根节点,最后访问右子树
遍历结果:H D I B J E A F C G
代码实现:
public List<Key> midErgodic(){
List<Key> list = new LinkedList<>();
midErgodic(root,list);
return list;
}
private void midErgodic(Node node,List<Key> list){
if (node == null){
return;
}
//先遍历左子树
if (node.left != null){
midErgodic(node.left,list);
}
//将当前结点的key放入链表
list.add(node.key);
//再遍历右子树
if (node.right != null){
midErgodic(node.right,list);
}
}
后序遍历
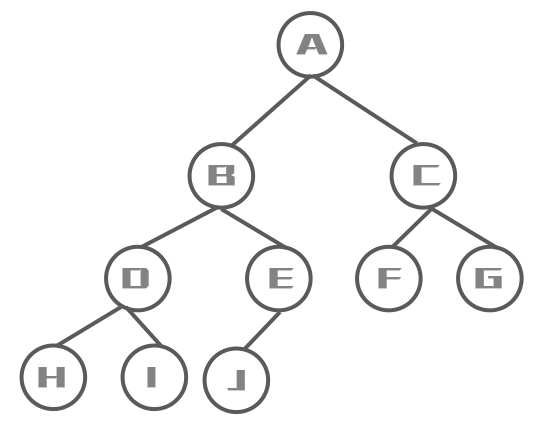
先访问左子树,再访问右子树,最后访问根节点
遍历结果: H I D J E B F G C A
代码实现:
public List<Key> afterErgodic(){
List<Key> list = new LinkedList<>();
afterErgodic(root,list);
return list;
}
private void afterErgodic(Node node,List<Key> list){
if (node == null){
return;
}
//先遍历左子树
if (node.left != null){
afterErgodic(node.left,list);
}
//再遍历右子树
if (node.right != null){
afterErgodic(node.right,list);
}
//将key插入链表
list.add(node.key);
}
层序遍历
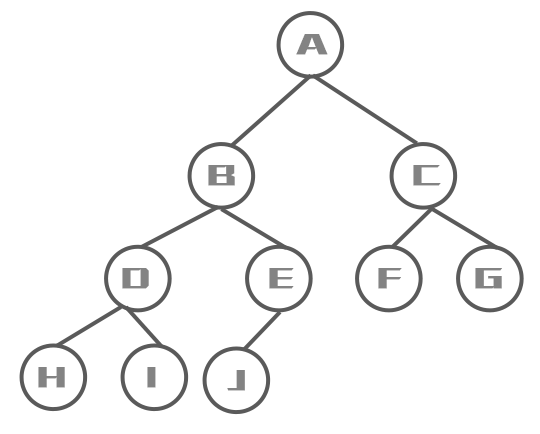
从根节点(第一层)开始,依次向下,获取每一层所有结点的值
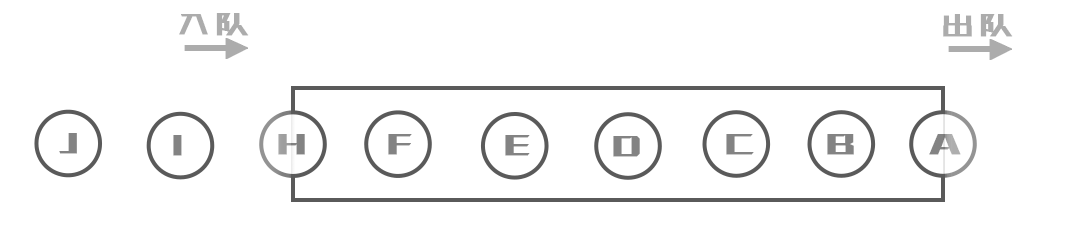
遍历结果:A B C D E F G H I J
代码实现:
采用队列存取结点,先进先出,实现层序遍历
LinkedList实现了队列Queue接口,依旧使用队列存取结点
//层序遍历
public Queue<Key> layerErgodic(){
//遍历树,将key存入nodes
Queue<Node> nodes = new LinkedList<>();
//队列nodes中的数据出队存入keys
Queue<Key> keys = new LinkedList<>();
//入队
nodes.offer(root);
while (!nodes.isEmpty()){
//node作为遍历树的结点,从根节点开始
Node node = nodes.poll();
//key存入队列
keys.offer(node.key);
if (node.left != null){
//左节点入队
nodes.offer(node.left);
}
if (node.right != null){
//右结点入队
nodes.offer(node.right);
}
}
return keys;
}
相关文章
- 数据结构习题之多维数组和广义表
- 图数据结构,图的统一数据结构和非标准图的转化算法
- 数据结构 Redo or Undo (模拟)
- javascript数据结构与算法:数组
- 十大经典排序算法【算法思想+图解+代码】【数据结构与算法笔记】
- 《数据结构与算法 C语言版》—— 第1章 绪论
- 数据结构 | 顺序表、链表和数组是逻辑结构还是物理(存储)结构?
- 数据结构与算法书籍汇总(从小白到大神)
- 【计算机考研408数据结构】历年统考编程大题—线性表
- 【转】Java学习---Java核心数据结构(List,Map,Set)使用技巧与优化
- 简单数据结构
- 数据结构(二):线性表的使用原则以及链表的应用-稀疏矩阵的三元组表示
- 数据结构基础(3)---C语言实现单链表