
【计算机考研408数据结构】历年统考编程大题—线性表

🌈🌈大家好鸭,目前刚好在复习数据结构,考研数据结构的编程大题真是一个让人头大的问题🙃,从本篇开始我会收录历届编程大题的代码和思路,一起刷起来吧~😀
🚀完整代码已同步至Gitee码云代码仓库,需要的同学可自取🚀
Gitee代码仓库—408数据结构历年编程题代码(完整可运行)
2009统考真题
已知一个带有表头结点的单链表,结点结构
data link 假设该链表只给出了头指针list。在不改变链表的前提下,请设计一个尽可能高效的算法,查找链表中倒数第 k k k个位置上的结点( k k k为正整数)。若查找成功,算法输出该结点的data域的值,并返回1;否则,只返回0。要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++或Java语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
- 定义一对快慢指针p和q,初始时都指向头结点,q指针先向前移动到第k个结点,如果q在移动过程中指向NULL,说明查找失败,返回0;否则算法继续执行,p指针和q指针随后每次同时向前移动一个结点,当q指针移动到最后一个结点时,p指针所指向的结点即为倒数第k个结点(不算头结点的情况下)。
- C++代码如下:
typedef struct Lnode{ // 链表结点的结构定义 int data; struct Lnode *next; }Lnode, *LinkedList; int Search_k(LinkedList L, int k) { Lnode *p = L->next, *q = L->next; // q先移动到第k个结点 for (int i = 1; i < k; i++) { q = q->next; if (q == NULL) return 0; } // p和q同时向前移动,直到q移动到最后一个结点 while (q->next != NULL) { p = p->next; q = q->next; } cout << p->data << endl; return 1; } - 算法的时间复杂度为 O ( N ) O(N) O(N),空间复杂度为 O ( 1 ) O(1) O(1)。
2010统考真题
设将 n ( n > 1 ) n(n>1) n(n>1)个整数存放到一维数组R中。设计一个在时间和空间两方面都尽可能高效的算法,将R中保存的序列循环左移 p ( 0 < p < n ) p_{(0<p<n)} p(0<p<n)个位置,即将R中的数据由 ( X 0 , X 1 , . . . , X n − 1 ) (X_0,X_1,...,X_{n-1}) (X0,X1,...,Xn−1)变换为 ( X p , X p + 1 , . . . , X n − 1 , X 0 , X 1 , . . . , X p − 1 ) (X_p,X_{p+1},...,X_{n-1},X_0,X_1,...,X_{p-1}) (Xp,Xp+1,...,Xn−1,X0,X1,...,Xp−1)。要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++或Java语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
🍬题解:
- 对数组R,先将区间 [ 0 , p − 1 ] [0, p-1] [0,p−1]逆置,再将区间 [ p , n − 1 ] [p, n-1] [p,n−1]逆置,最后将整个数组,即区间 [ 0 , n − 1 ] [0, n-1] [0,n−1]逆置,最终结果就是数组循环左移了 p p p个位置。
- C++代码如下:
// 反转指定的区间,区间左闭右开 void reverse(int R[], int from, int to) { for (int i = 0; i < (to - from) / 2; i++) { int temp = R[from + i]; R[from + i] = R[to - i - 1]; R[to - i - 1] = temp; } } void converse(int R[], int n, int p) { reverse(R, 0, p); reverse(R, p, n); reverse(R, 0, n); } - 算法的时间复杂度为 O ( N ) O(N) O(N),空间复杂度为 O ( 1 ) O(1) O(1)。
2011统考真题
一个长度为 L ( L > = 1 ) L(L >= 1) L(L>=1)的升序序列 S S S,处在第 [ L / 2 ] [L/2] [L/2]个位置的数称为 S S S的中位数。例如,若序列 S 1 = ( 11 , 13 , 15 , 17 , 19 ) S_1=(11,13,15,17,19) S1=(11,13,15,17,19),则 S 1 S_1 S1的中位数是 15 15 15,两个序列的中位数是它们所有元素的升序序列的中位数。例如,若 S 2 = ( 2 , 4 , 6 , 8 , 20 ) S_2=(2,4,6,8,20) S2=(2,4,6,8,20),则 S 1 S_1 S1和 S 2 S_2 S2的中位数时 11 11 11。现在有两个等长升序序列 A A A和 B B B,设计一个在时间和空间两方面都尽可能高效的算法,找出两个序列 A A A和 B B B的中位数。要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++或Java语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
🍬题解:
-
分别求两个升序序列A和B的中位数,设为a,b,求序列A、B的中位数过程如下:
- 若a=b,则a或b即为所求。
- 若a<b,则舍弃A中较小的一半,同时舍弃B中较大的一半。
- 若a>b,则舍弃A中较大的一半,同时舍弃B中较小的一半。
在保留的两个升序序列中,重复步骤1,2,3直到序列中均只含有一个元素,较小者即为所求。
-
C++代码如下:
int SearchMedian(int A[], int B[], int n) { int left1 = 0, right1 = n - 1; int left2 = 0, right2 = n - 1; while (left1 + 1 < right1 || left2 + 1 < right2) { int mid1 = (left1 + right1) >> 1; int mid2 = (left2 + right2) >> 1; if (A[mid1] == B[mid2]) return A[mid1]; if (A[mid1] > B[mid2]) { right1 = mid1; left2 = mid2; } else { left1 = mid1; right2 = mid2; } } if (A[left1] > B[left2]) { return min(A[left1], B[right2]); } else { return min(A[right1], B[left2]); } } -
时间复杂度为 O ( l o g 2 N ) O(log_2N) O(log2N),空间复杂度为 O ( 1 ) O(1) O(1)。
2012统考真题
假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,可共享相同的后缀存储空间,例如,“loading”和”being“的存储映像如下图所示。
设str1和str2分别指向两个单词所在单链表的头结点,链表结点结构为|data| |next|,请设计一个时间上尽可能高效的算法,找出由str1和str2所指向的两个链表共同后缀的起始位置(如图中字符i所在结点的位置p)。要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++或Java语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
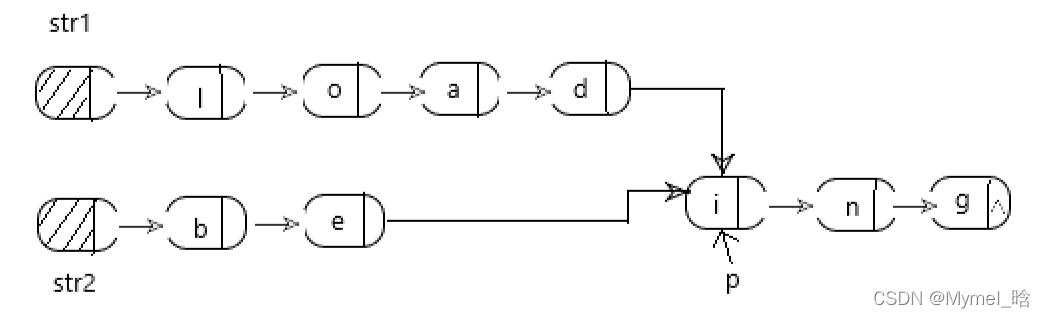
- 先分别求出str1与str2两个链表的长度n,m。设置两个指针p,q分别指向str1与str2的头结点,若n>=m,则指针p先走到链表的第n-m个结点;反之,q先走到链表的第m-n个结点。随后p,q同时向后移动,当p、q指向同一位置时停止,即为共同后缀的起始位置,算法结束。
- C++代码如下:
typedef struct LNode { char data; struct LNode *next; }LNode, *LinkedList; int Length(LinkedList L) { LNode *p = L; int count = 0; while (p->next != NULL) { p = p->next; count++; } return count; } LNode* find_addr(LinkedList str1, LinkedList str2) { int n = Length(str1), m = Length(str2); LNode *p = str1, *q = str2; if (n > m) for (int i = 0; i < (n - m); i++) p = p->next; else for (int i = 0; i < (m - n); i++) q = q->next; while (p->next != NULL && q->next != NULL) { p = p->next; q = q->next; if (p == q) return p; } return NULL; } - 时间复杂度为 O ( l e n 1 + l e n 2 ) O(len1+len2) O(len1+len2),其中len1、len2分别为两个链表的长度。
2013统考真题
已知一个整数序列 A = ( a 0 , a 1 , . . . , a n − 1 ) A=(a_0,a_1,...,a{n-1}) A=(a0,a1,...,an−1),其中 0 < = a i < n ( 0 < = i < n ) 0<=a_i<n_{(0<=i<n)} 0<=ai<n(0<=i<n)。若存在 a p 1 = a p 2 = . . . = a p m = x a_{p1}=a_{p2}=...=a_{pm}=x ap1=ap2=...=apm=x且 m > n / 2 ( 0 < = p k < n , 1 < = k < = m ) m>n/2_{(0<=p_k<n,1<=k<=m)} m>n/2(0<=pk<n,1<=k<=m),则称 x x x为 A A A的主元素。例如 A = ( 0 , 5 , 5 , 3 , 5 , 7 , 5 , 5 ) A=(0,5,5,3,5,7,5,5) A=(0,5,5,3,5,7,5,5),则 5 5 5为主元素;又如 A = ( 0 , 5 , 3 , 5 , 1 , 5 , 7 ) A=(0,5,3,5,1,5,7) A=(0,5,3,5,1,5,7),则 A A A中唯有主元素。假设 A A A中的 n n n个元素保存在一个一维数组中,请设计一个尽可能高效的算法,找出 A A A中的主元素。若存在主元素,则输出该元素;否则输出 − 1 -1 −1。要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++或Java语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
- 依次扫描数组中的每个整数,将第一个遇到的整数num保存在c中,记录num出现1次;若遇到的下一个整数仍等于num,则计数加1,否则计数减1;当计数减到0时,将遇到的下一个整数保存到c中,计数重新记为1,开始新一轮计数,知道扫描完全部数组。
最后还需要一次扫描判断c中的元素是否时真正的主元素,统计c中元素的个数,若大于n/2则为主元素,否则不存在主元素。 - C++代码如下:
using namespace std; int Majority(int A[], int n) { int c = A[0], count = 1; for (int i = 1; i < n; i++) { if (A[i] == c) count++; else { count--; if (count == 0) { c = A[i]; count = 1; } } } count = 0; for (int i = 0; i < n; i++) if (A[i] == c) count++; if (count > n / 2) return c; return -1; } - 本程序的时间复杂度为 O ( N ) O(N) O(N),空间复杂度 O ( 1 ) O(1) O(1)。
2015统考真题
用单链表保存m个整数,结点的结构为
[data][link],且|data|<=n(n为正整数)。现在要求设计一个时间复杂度尽可能高效的算法,对于链表中data的绝对值相等的结点,仅保留第一次出现的结点而删除其余绝对值相等的结点。例如,若给定的单链表head如下:
head->21->-15->-15->-7->15->^
则删除结点后的head为
head->21->-15->-7->^
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
- 可以采取用空间换时间的策略,使用一个辅助数组记录链表中已出现的数值,只需对链表进行一趟扫描。
定位|data|<=n,故辅助数组q的大小为n+1,各元素的初值均为0。依次扫描链表中的各结点,同时检查q[|data|]的值,若为0则保留该结点,并令q[|data|] = 1;否则将该结点从链表中删除。 - C++代码如下:
typedef struct LNode { char data; struct LNode *next; }LNode, *LinkedList; void func(LinkedList &L, int n) { int table[n + 1]; memset(table, 0, sizeof(int) * (n + 1)); LNode *p = L->next; LNode *pre = L; while (p != NULL) { if (table[abs(p->data)] == 0) { table[abs(p->data)] = 1; p = p->next; pre = pre->next; } else { LNode *q = p; pre->next = q->next; p = p->next; free(q); } } } - 算法的时间复杂度为 O ( N ) O(N) O(N),空间复杂度为 O ( N ) O(N) O(N)。
2018统考真题
给定一个含 n ( n > = 1 ) n(n>=1) n(n>=1)个整数的数组,请设计一个在时间上尽可能高效的算法,找出数组中未出现的最小正整数。例如,数组 { − 5 , 3 , 2 , 3 } \{-5,3,2,3\} {−5,3,2,3}中未出现的最小正整数是1;数组 { 1 , 2 , 3 } \{1,2,3\} {1,2,3}中未出现的最小正整数是 4 4 4。要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
- 对于有 n n n个元素的数组 A A A,分配一个 B [ n + 1 ] B[n+1] B[n+1]数组用来标记A数组中每个元素是否出现, B [ i ] B[i] B[i]对应正整数i。从 A [ 0 ] A[0] A[0]开始扫描A数组,若 0 < A [ i ] < = n 0<A[i]<=n 0<A[i]<=n,则令 B [ A [ i ] ] = 1 B[A[i]] = 1 B[A[i]]=1,否则不进行操作。扫描结束后遍历数组 B B B,找到第一个满足 B [ i ] = 0 B[i]=0 B[i]=0的下标 i i i, i i i即为所求,若 B [ i ] B[i] B[i]均不为 0 0 0,则返回 n + 1 n+1 n+1。
- C++代码如下:
int findMissMin(int A[], int n) { int B[n + 1]; memset(B, 0, sizeof(int) * (n + 1)); for (int i = 0; i < n; i++) if (A[i] > 0) B[A[i]] = 1; for (int i = 1; i < n + 1; i++) if (B[i] == 0) return i; return n + 1; } - 时间复杂度为 O ( N ) O(N) O(N),空间复杂度为 O ( N ) O(N) O(N)。
2019统考真题
设线性表L=( a 1 a_1 a1, a 2 a_2 a2, a 3 a_3 a3,…, a n − 2 a_{n-2} an−2, a n − 1 a_{n-1} an−1, a n a_n an)采用带头结点的单链表保存,链表中的结点定义如下:
typedef struct node { int data; struct node*next; }NODE;请设计一个空间复杂度为 O ( 1 ) O(1) O(1)且时间是尽可能高效的算法,重新排列L中的各个结点,得到线性表L’=( a 1 a_1 a1, a n a_n an, a 2 a_2 a2, a n − 1 a_{n-1} an−1, a 3 a_{3} a3, a n − 2 a_{n-2} an−2…)。要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
- 观察L=(
a
1
a_1
a1,
a
2
a_2
a2,
a
3
a_3
a3,…,
a
n
−
2
a_{n-2}
an−2,
a
n
−
1
a_{n-1}
an−1,
a
n
a_n
an)和L’=(
a
1
a_1
a1,
a
n
a_n
an,
a
2
a_2
a2,
a
n
−
1
a_{n-1}
an−1,
a
3
a_{3}
a3,
a
n
−
2
a_{n-2}
an−2…),发现L’是由L摘取第一个元素,再摘取倒数第一个元素…依次合并而成的。可以将链表的后半部分原地逆置,再分别从链表的前后两段中依次各取一个结点,按要求重排。
其中,原地逆置链表的后半段需要找到链表的中间结点,可以设置一对快慢指针,满指针每次走一步,快指针每次走两步,当快指针到达链表末尾时,慢指针指向的即为链表的中间结点。 - C++代码如下:
typedef struct LNode { int data; struct LNode *next; }LNode, *LinkedList; void ChangeList(LinkedList &L) { LNode *slow = L; LNode *fast = L; while (fast->next != NULL) { // 寻找中间结点 slow = slow->next; fast = fast->next; if (fast->next != NULL) fast = fast->next; } LNode *p = slow->next; // slow所指结点为中间结点,p为链表后半段的首结点 slow->next = NULL; slow = slow->next; while (p != NULL) { // 将链表的后半段逆置 LNode *r = p->next; p->next = slow; slow = p; p = r; } // 此时slow指向链表的后半段逆置后的首结点 // 令P指向链表前半段的首结点 p = L->next; // 将链表的后半段插入指定位置 while (slow != NULL) { LNode *r = slow->next; slow->next = p->next; p->next = slow; p = slow->next; slow = r; } } - 时间复杂度为 O ( N ) O(N) O(N)。
2020统考真题
定义三元组 ( a , b , c ) (a,b,c) (a,b,c)(a、b、c均为正数)的距离 D = ∣ a − b ∣ + ∣ b − c ∣ + ∣ c − a ∣ D=|a-b|+|b-c|+|c-a| D=∣a−b∣+∣b−c∣+∣c−a∣。给定3个非空整数集合 S 1 、 S 2 和 S 3 S_1、S_2和S_3 S1、S2和S3,按升序分别存储在3个数组中。请设计一个尽可能高效的算法,计算并输出所有可能的三元组 ( a , b , c ) ( a ⊆ S 1 , b ⊆ S 2 , c ⊆ S 3 ) (a,b,c)(a\subseteq{S_1},b\subseteq{S_2},c\subseteq{S_3}) (a,b,c)(a⊆S1,b⊆S2,c⊆S3)中的最小距离。例如 S 1 = { − 1 , 0 , 9 } S_1=\{-1,0,9\} S1={−1,0,9}, S 2 = { − 25 , − 10 , 10 , 11 } S_2=\{-25,-10,10,11\} S2={−25,−10,10,11}, S 3 = { 2 , 9 , 17 , 30 , 41 } S_3=\{2,9,17,30,41\} S3={2,9,17,30,41},则最小的距离为2,相应的三元组为 ( 9 , 10 , 9 ) (9,10,9) (9,10,9)。要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
- 使用 D m i n D_{min} Dmin记录最小距离,初始值为一个足够大的整数。循环取 S 1 , S 2 S_1,S_2 S1,S2和 S 3 S_3 S3中的最小值进行枚举:计算距离D,将D与 D m i n D_{min} Dmin进行比较,更新 D m i n D_{min} Dmin,并将 S 1 [ i ] , S 2 [ j ] , S 3 [ k ] S_1[i],S_2[j],S_3[k] S1[i],S2[j],S3[k]中的最小值下标+1。
- C++代码如下:
int findMinofTrip(int A[], int n, int B[], int m, int C[], int p) { int i = 0, j = 0, k = 0, D_min = int_max; // D_min如果等于0,那么肯定是最终结果,可以直接结束循环 while (i < n && j < m && k < p && D_min > 0) { int D = abs(A[i] - B[j]) + abs(B[j] - C[k]) + abs(C[k] - A[i]); if (D < D_min) D_min = D; if (A[i] == min(min(A[i], B[j]), C[k])) i++; else if (B[j] == min(min(A[i], B[j]), C[k])) j++; else k++; } return D_min; } - 时间复杂度为 O ( N ) O(N) O(N),空间复杂度为 O ( 1 ) O(1) O(1)。
相关文章
- scala泛函编程是怎样被选中的
- 【华为云技术分享】Python大神编程常用4大工具,你用过几个?
- iOS开发之网络编程--使用NSURLConnection实现大文件断点续传下载+使用输出流代替文件句柄
- 关于多线程编程您不知道的 5 件事 有关高性能线程处理的微妙之处
- java学习笔记15--多线程编程基础2
- android 编程时,如何在Eclipse中查看Android源码或者第三方组件包源码
- 并发编程 – Concurrent 用户指南--转
- 大叔经验分享(17)编程实践对比Java vs Scala
- 计算机视觉 基于CUDA编程的入门与实践 线程及同步一
- 网络编程三要素
- Atitit 函数式编程与命令式编程的区别attilax总结 qbf
- Atitit..组件化事件化的编程模型--(2)---------Web datagridview 服务器端控件的实现原理and总结
- IT计算机编程:到底是学前端开发好?还是后端(Java、Python 和 PHP 等)好?
- Interview:人工智能岗位—校招真题—算法工程师(计算机视觉方向)选择题——C++语言、sql语言编程相关习题的部分笔记
- 为什么现代系统需要一个新的编程模型?
- Github 的一个免费编程书籍列表
- Python编程:Coroutine协程之生产者消费者模型
- Python编程:Python2和Python3环境下re正则匹配中文
- LabVIEW编程LabVIEW开发如何选择外协服务
- Java:计算机编程语言Java的简介、安装(编程环境/工具)、学习路线(如何学习Java以及几十项代码编程案例分析)之详细攻略