
《Learning Structured Sparsity in Deep Neural Networks》论文笔记
1. 概述
这篇文章提出了结构系数学习(Structured Sparsity Learning,SSL)的方法去正则网络的结构(filter,channel,filter shape,网络的深度),SSL的特点是:
- 1)从大的DNN网络去学习一个的紧密结构,减少计算花销;
- 2)获得一个硬件友好的DNN稀疏结构去加速网络。在实验中使用SSL方法对AlexNet在CPU与GPU上分别加速了5.1与3.1倍。精度降低大约为1%;
- 3)使用SSL方法之后给网络带来了正则的作用,提升了网络的性能。实验中将20层的ResNet裁剪成为了18层的,同时还提升了网络的精度。
论文地址:Learning Structured Sparsity in Deep Neural Networks
论文代码:Caffe for Sparse and Low-rank Deep Neural Networks
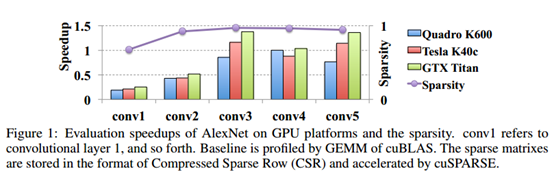
下面这幅图中展示的是AlexNet前面5个卷积层使用L1范数进行non-structurally剪裁的结果,可以看到网络已经很稀疏了(大于95%),但是加速的幅度确实很小的。
在最近提出的低秩近似方法中,首先对DNN进行训练,然后对每个训练的权值张量进行分解,并用较小因子的乘积进行近似。最后,通过finetune来恢复模型的精度。低秩逼近在稠密矩阵中协调模型参数,避免了非结构化稀疏正则化的局部性问题,能够实现实际的加速。然而,低秩近似只能得到各层内部的紧凑结构,并且在微调过程中,各层的结构是固定的,需要花费大量的时间进行分解和微调,才能找到最优的权值近似,从而提高性能和保持精度。
在文章中基于这样的事实:
- 1)在filter与channel上存在冗余;
- 2)过滤器的形状通常固定为长方体,但启用任意形状可以潜在地消除这种固定带来的不必要的计算;
- 3)一般来讲网络越深分类效果越好,但是会存在梯度问题。
对此,这篇文章提出了SSL方法通过在训练中使用group Lasso回归来压缩网络的结构,这里包括了filter、channel、filter的形状与网络的深度。SSL方法将结构正则化(网络的分类精度)与本地最优化(内存访问的计算效率),最后结果并不只是正则化之后提升精度的原始网络,而且还加速了计算过程。
2. Structured Sparsity Learning Method for DNNs
2.1 Structured Sparsity Learning的通用结构
在CNN网络中对于第
l
,
l
∈
1
≤
l
≤
L
l, l\in1\le l \le L
l,l∈1≤l≤L层的卷积参数为
W
(
l
)
∈
R
N
l
∗
C
l
∗
M
l
∗
K
l
W^{(l)}\in R^{N_l*C_l*M_l*K_l}
W(l)∈RNl∗Cl∗Ml∗Kl,这写权重的不同维度就可以代表filter、channel和spatial上了,因而得到了网络的空间结构正则化通用优化目标,可以将其表示为:
E
(
W
)
=
E
D
(
W
)
+
λ
R
(
W
)
+
λ
g
∑
l
=
1
L
R
g
(
W
(
l
)
)
E(W)=E_D(W)+\lambda R(W)+\lambda_g \sum_{l=1}^LR_g(W^{(l)})
E(W)=ED(W)+λR(W)+λgl=1∑LRg(W(l))
其中,
W
W
W代表DNN网络中的权重集合;
E
D
(
W
)
E_D(W)
ED(W)代表对应数据产生的损失;
R
(
⋅
)
R(\cdot)
R(⋅)代表在每个权重上使用非结构正则,例如L2范数;
R
g
(
⋅
)
R_g(\cdot)
Rg(⋅)代表每层上的稀疏正则化。对于权重集合
w
w
w使用group Lasso正则可以表示为
R
g
(
w
)
=
∑
g
=
1
G
∣
∣
w
(
g
)
∣
∣
g
R_g(w)=\sum_{g=1}^G||w^{(g)}||_g
Rg(w)=∑g=1G∣∣w(g)∣∣g,
w
(
g
)
w^{(g)}
w(g)代表一个group的部分权重,
G
G
G代表group的总数。不同的group之间可能会存在重叠的。
∣
∣
⋅
∣
∣
||\cdot||
∣∣⋅∣∣是group Lasso,
∣
∣
w
(
g
)
∣
∣
g
=
∑
i
=
1
∣
w
(
g
)
∣
(
w
i
(
g
)
)
2
||w^{(g)}||_g=\sqrt{\sum_{i=1}^{|w^{(g)}|}(w_i^{(g)})^2}
∣∣w(g)∣∣g=∑i=1∣w(g)∣(wi(g))2,
∣
w
(
g
)
∣
|w^{(g)}|
∣w(g)∣是
w
(
g
)
w^{(g)}
w(g)中权重的个数。
2.2 filters, channels, filter shapes and depth上的稀疏学习
论文中说到的三个层面的wise其图形描述如下所示:

惩罚不重要的filter和channel 这个对应上面图中的第一个部分,在filter层面与channel层面的结构稀疏可以使用下面的目标函数进行优化:
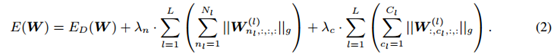
学习任意形状的filter 这个对应上面图中的第二个部分,在优化的过程中一些filter会被置为0,那么就可以使得一些非0的filter变为非方形,那么其优化的目标函数可以表述为:
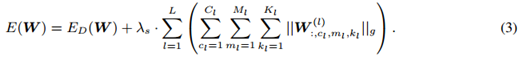
网络深度正则化 也就是上面的第三个部分了,当一个卷积层中所有的filter都被置为0之后那么这个卷积层就可以被剪除掉了,但是全部置为0就会使得网络无法继续传递下去,在文章中使用了ResNet的结构,使得网络可以跨过一些卷积层,最后再判定那些层是否是需要的,文章中对这一部分的目标函数为:
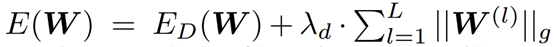
2.3 Structured sparsity learning for computationally efficient structures
在上面一节中的说到的策略可以用来得到压缩之后的模型,论文在此基础上提出了两种计算规则:
- 1)2D-filter-wise sparsity for convolution 卷积层中的3D卷积可以看做是2D卷积的组合(做卷积的时候spatial和channel是不相交的)。这种结构化稀疏是将该卷积层中的每个2D的filter, W n l , c l , : , : ( l ) W_{n_l,c_l,:,:}^{(l)} Wnl,cl,:,:(l),看做一个group,做group LASSO。这相当于是上述filter-wise和channel-wise的组合。
- 2)Combination of filter-wise and shape-wise sparsity for GEMM 在Caffe中,3D的权重tensor是reshape成了一个行向量,然后 N N N个filter的行向量堆叠在一起,就成了一个2D的矩阵。这个矩阵的每一列对应的是 W : , c l , m l , k l ( l ) W_{:,c_l,m_l,k_l}^{(l)} W:,cl,ml,kl(l),称为shape sparsity。两者组合,矩阵的零行和零列可以被抽去,相当于GEMM的矩阵行列数少了,起到了加速的效果。
3. 实验结果
论文分别在MNIST,CIFAR10和ImageNet上做了实验,使用现有的网络作为baseline,以此来使用SSL来压缩网络。论文在LeNet上使用文章中的方法进行压缩得到的结果:

将网络conv1的filter可视化如下。可以看到,对于LeNet2来说,大多数filter都被稀疏掉了。

相关文章
- 论文阅读:Bootstrapping Humanoid Robot Skills by Extracting Semantic Representations of Human-like Activities from Virtual Reality
- 论文阅读:One-Shot Imitation Learning
- 【毕业设计_课程设计】在线免费小说微信小程序的设计与实现(源码+论文)
- 读论文《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》
- 计算机视觉经典论文阅读---AlexNet论文阅读笔记
- Fast-BEV:A Fast and Strong Bird’s-Eye View Perception Baseline——论文笔记
- 《Unsupervised Monocular Depth Learning in Dynamic Scenes》论文笔记
- 《ReDet:A Rotation-equivariant Detector for Aerial Object Detection》论文笔记
- 《Sparse R-CNN:End-to-End Object Detection with Learnable Proposals》论文笔记
- 《YOLACT++ Better Real-time Instance Segmentation》论文笔记
- 《Matrix Nets:A New Deep Architecture for Object Detection》论文笔记
- 《Imbalance Problems in Object Detection:A Review》论文笔记
- 《SCA-CNN:Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning》论文笔记
- 《Receptive Field Block Net for Accurate and Fast Object Detection》论文笔记
- 《Inception V3-Rethinking the Inception Architecture for Computer Vision》论文笔记
- 《Cascade R-CNN: Delving into High Quality Object Detection》论文笔记
- 《An Analysis of Scale Invariance in Object Detection – SNIP》论文笔记
- Light-Head R-CNN论文笔记
- 《ContextNet:Context-Aware Image Matting for Simultaneous Foreground and Alpha Estimation》论文笔记
- 《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》论文笔记
- 《LEDNet:A Lightweight Encoder-Decoder Network For Real-Time Semantic Segmentation》论文笔记
- 《Learning to Prune Filters in Convolutional Neural Networks》论文笔记
- 论文阅读笔记exploiting spatial dimensions of latenr in GAN for real-time image editing