牛客Verilog题目(1)——超前进位加法器
题目 Verilog 牛客
2023-09-11 14:20:47 时间
今天起,开始统计一些做的比较难的或者可以扩展知识面的Verilog题目。
第一题来自牛客->verilog快速入门->第12题
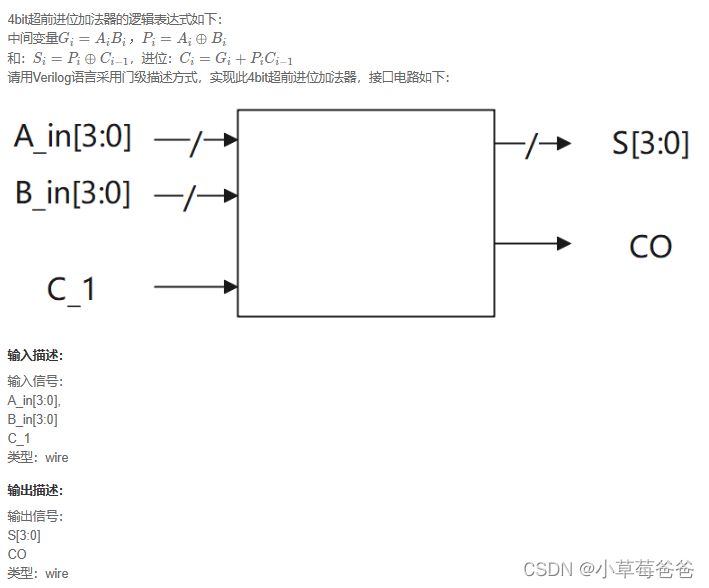
4个二进制全加器串联的四位加法器
在此之前需要了解全加器、4个1位二进制全加器串联的四位加法器。再了解为什么要用这种超前进位加法器。’
全加器很简单,直接写成最小二项式和异或门形式:
module my_mux2(
input in1,
input in2,
input cin,
output wire cout,
output wire out
);
assign cout = in1&in2 | in1&cin | in2&cin;
assign out = in1 ^ in2 ^ cin;
endmodule
然后将其串联起来,一开始我就reg了一位寄存器当相互的节点值,后来发现是不可以的,因为在电路中不符合理想。
错误过程如下:
module multi_sel(
input [3:0] A_in ,
input [3:0] B_in ,
input C_1 ,
output wire CO ,
output wire [3:0] S
);
parameter width = 4;
//方法一:四个1位全加器串联
genvar i;
for(i = 0; i<width; i=i+1) begin
my_mux2 m(.in1(A_in[i]),
.in2(B_in[i]),
.cin(C_1),
.cout(CO),
.out(S[i])
);
assign CIN = CO;
end
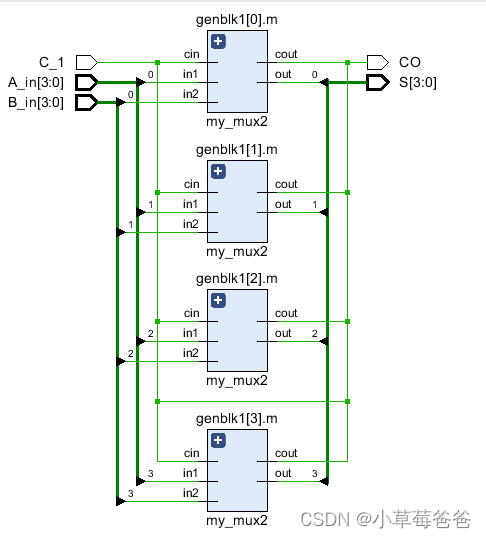
可以从图中看出是有明显问题的,不会像C一样顺序运算,而是根据逻辑将两节点直接相连
经过修改后,
module multi_sel(
input [3:0] A_in ,
input [3:0] B_in ,
input C_1 ,
output wire CO ,
output wire [3:0] S
);
wire [3:0] CIN;
wire [3:0] COUT;
parameter width = 4;
//方法一:四个1位全加器串联
genvar i;
for(i = 0; i<width; i=i+1) begin
my_mux2 m(.in1(A_in[i]),
.in2(B_in[i]),
.cin(CIN[i]),
.cout(COUT[i]),
.out(S[i])
);
end
assign CIN[0] = C_1;
assign CIN[1] = COUT[0];
assign CIN[2] = COUT[1];
assign CIN[3] = COUT[2];
assign CO = COUT[3];
整个逻辑还是很简单的,直接前一级进位输出连接后一位进位输入即可。电路图如:
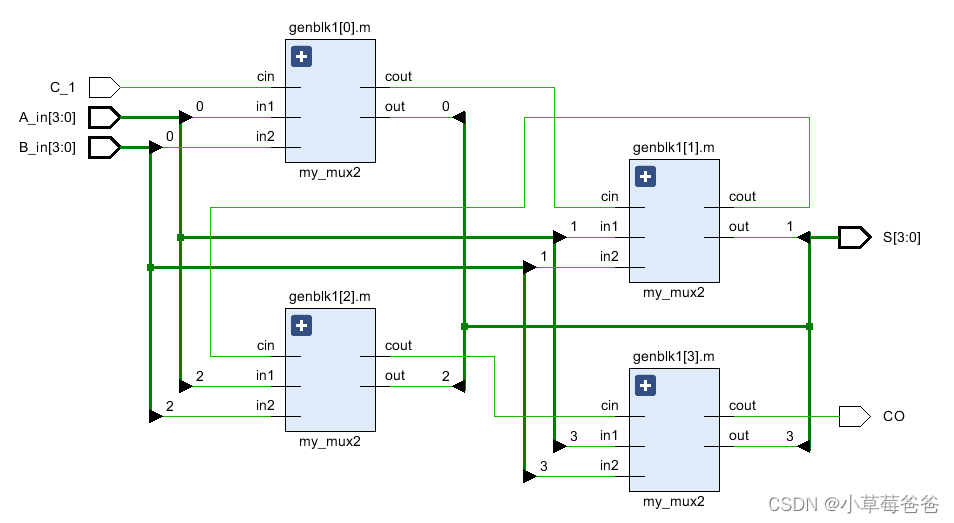
超前进位加法器
可以看出上面是将四位一位全加器串联,如果是多位相加,线路的延迟会更加明显,并且运行速度也会相对并行运算较慢。所以用题中的方法:
module multi_sel(
input [3:0] A_in ,
input [3:0] B_in ,
input C_1 ,
output wire CO ,
output wire [3:0] S
);
//方法二:超进位4位全加器,用面积换并行运算(运算速度)
wire [3:0] G;
wire [3:0] P;
wire [3:0] C;
genvar i;
for (i = 0; i<4; i=i+1) begin
assign G[i] = A_in[i] & B_in[i];
assign P[i] = A_in[i] ^ B_in[i];
end
assign C[0] = C_1;
assign C[1] = G[0] || ( C[0] & P[0] );
assign C[2] = G[1] || ( C[1] & P[1] );
assign C[3] = G[2] || ( C[2] & P[2] );
assign S[0] = P[0] ^ C[0];
assign S[1] = P[1] ^ C[1];
assign S[2] = P[2] ^ C[2];
assign S[3] = P[3] ^ C[3];
assign CO = G[3] || ( C[3] & P[3] );
endmodule
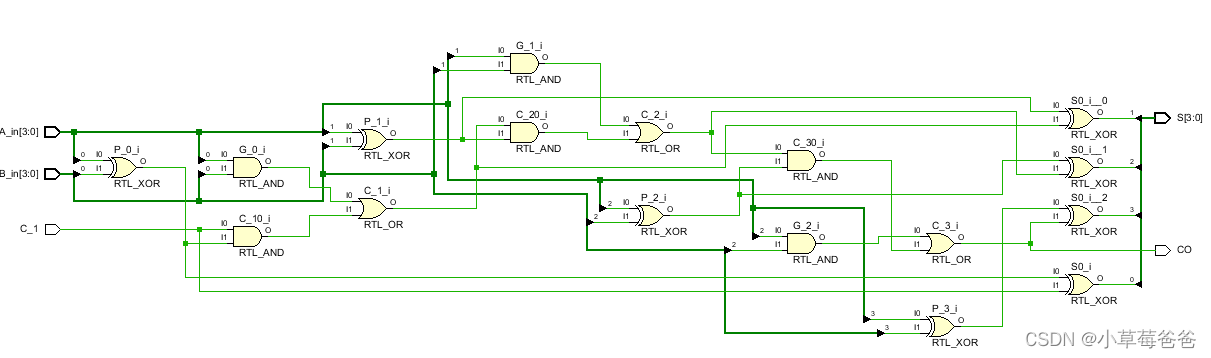
图看起来很吓人,这是由于上个方法,把1位二进制全加器封装起来了,相比于上种方法,面积还是减小很多。
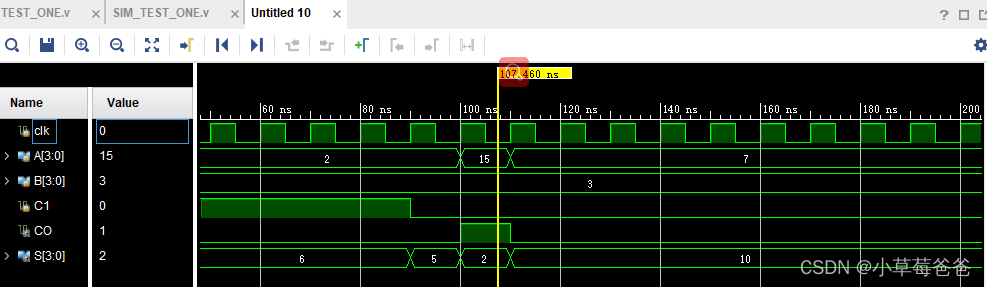
激励文件(顶层文件)
`timescale 1ns/1ns
module testbench();
reg clk = 1;
initial
begin
repeat (100)
#5 clk = ~clk;
end
reg [3:0] A;
reg [3:0] B;
reg C1;
wire CO;
wire [3:0]S;
multi_sel inst( .A_in(A),
.B_in(B),
.C_1(C1),
.CO(CO),
.S(S)
);
initial begin
A = 4'd2;
B = 4'd5;
C1 = 1'b1;
#10;
B = 4'd4;
#30;
B = 4'd3;
#50;
C1 = 1'b0;
#10;
A = 4'd12;
#10;
A = 4'd7;
#70;
end
// initial begin
// $dumpfile("out.vcd");
// // This will dump all signal, which may not be useful
// //$dumpvars;
// // dumping only this module
// //$dumpvars(1, testbench);
// // dumping only these variable
// // the first number (level) is actually useless
// $dumpvars(0, testbench);
//end
endmodule