
ORACLE-SQL微妙之处
2023-09-11 14:20:35 时间
本文总结一下平时经常使用的SQL语句以及一些ORACLE函数的微妙之处。欢迎大家多多补充平时最常用的SQL语句,供大家学习参考。
span strong span 1、数据累加 /span /strong /span SQL SELECT NAME, sum(sorce) OVER(ORDER BY NAME) 2 FROM temp2 3 ORDER BY NAME; NAME SUM(SORCE)OVER(ORDERBYNAME) ---------- --------------------------- 1 43 2 66 3 108 4 195 5 207 span strong span 2、去掉最大值和最小值 /span /strong /span SQL SELECT NAME, 2 sorce, 3 LAG(sorce) over(order by sorce) Lag_List, 4 LEAD(sorce) over(order by sorce) Lead_List 5 FROM temp2; NAME SORCE Lag Lead ---------- ---------- ---------- ---------- 5 12 23 2 23 12 42 3 42 23 43 1 43 42 87 4 87 43
3 RANK() OVER(order by value) RANK_SORT, 4 DENSE_RANK() OVER(order by value) DENSE_SORT, 5 ROW_NUMBER() OVER(order by value) ROW_SORT 6 FROM sorce; NAME VALUE RANK_SORT DENSE_SORT ROW_SORT ---------- ------ ---------- ---------- ---------- wu 21 1 1 1 zhang 60 2 2 2 Li 70 3 3 3 xue 119 5 5 5 span wang 130 6 6 6 chen 130 6 6 7 sun 175 8 7 8 /span zhao 285 9 8 9 su 359 10 9 10 Li 480 11 10 11 br 可见三者的区别: br RANK()OVER():如果值相同,则两者顺序号相同,随机一个在另外一个的上边,而且顺序号会有间断,不是连续的; br DENSE_RANK():如果值相同,则两者顺序号相同,随机一个在另外一个的上边,而且顺序号仍然是连续的,不存在断层的现象; br ROW_NUMBER():如果值相同,则两种顺序号不同,安装顺序号依次排开,而且顺序号是连续的。 2、TRANSLATE()函数 translate函数与replace类似,但是又与replace不同,translate指定字符串string中出现的from_str,将from_str中各个字符替换成to_str中位置顺序与其相同的to_str中的字符。
SQL Reference中给的例子:SELECT TRANSLATE(SQL*Plus Users Guide, */, ___) FROM DUAL;
(1)判断一个字符串是数字
SELECT TRANSLATE(ABC123,#1234567890.,#) FROM DUAL;
(2)统计字符E出现的次数
SELECT LENGTHB(TRANSLATE(ABCDEFGEFGDBE,E||ABCDEFGEFGDBE,E)) FROM DUAL;
3、ROUND()函数
translate函数与replace类似,但是又与replace不同,translate指定字符串string中出现的from_str,将from_str中各个字符替换成to_str中位置顺序与其相同的to_str中的字符。
SQL Reference中给的例子:SELECT TRANSLATE(SQL*Plus Users Guide, */, ___) FROM DUAL;
(1)判断一个字符串是数字
SELECT TRANSLATE(ABC123,#1234567890.,#) FROM DUAL;
(2)统计字符E出现的次数
SELECT LENGTHB(TRANSLATE(ABCDEFGEFGDBE,E||ABCDEFGEFGDBE,E)) FROM DUAL;
3、ROUND()函数
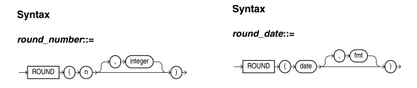 我们平时用得最多的是第一种,用ROUND()函数作为数据四舍五入运算,其实ROUND函数还有第二种形式,对日期进行格式化操作,与TRUNC()函数类似。
如:SELECT ROUND(SYSDATE,yyyy) FROM DUAL;
SELECT ROUND(SYSDATE,MM) FROM DUAL;
SELECT ROUND(SYSDATE,HH24) FROM DUAL;
4、NVL相关函数
NVL相关的函数有:NVL(expr1,expr2),NVL2(expr1,expr2,expr3),NULLIF(expr1,expr2),DECODE(expr1,expr2,value1,expr3,value2...,default)
(1) NVL(expr1,expr2) :如果expr1为空,则用expr2来替换。
(2) NVL2(expr1,expr2,expr3) :如果expr1非空,则返回expr2,否则返回expr3。
(3) NULLIF(expr1,expr2):将expr1和expr2做比较,如果想等,则返回null,否则返回expr1。
(3) DECODE(expr1,expr2,value1,expr3,value2...,default):如果expr1与expr2相等,则返回value1,如果expr1与expr3相等,则返回value2,...否则,返回default。
5、收集表的统计信息
收集表的统计信息方法有很多种: (1) ANALYZE (2) DBMS_STATS
我们平时用得最多的是第一种,用ROUND()函数作为数据四舍五入运算,其实ROUND函数还有第二种形式,对日期进行格式化操作,与TRUNC()函数类似。
如:SELECT ROUND(SYSDATE,yyyy) FROM DUAL;
SELECT ROUND(SYSDATE,MM) FROM DUAL;
SELECT ROUND(SYSDATE,HH24) FROM DUAL;
4、NVL相关函数
NVL相关的函数有:NVL(expr1,expr2),NVL2(expr1,expr2,expr3),NULLIF(expr1,expr2),DECODE(expr1,expr2,value1,expr3,value2...,default)
(1) NVL(expr1,expr2) :如果expr1为空,则用expr2来替换。
(2) NVL2(expr1,expr2,expr3) :如果expr1非空,则返回expr2,否则返回expr3。
(3) NULLIF(expr1,expr2):将expr1和expr2做比较,如果想等,则返回null,否则返回expr1。
(3) DECODE(expr1,expr2,value1,expr3,value2...,default):如果expr1与expr2相等,则返回value1,如果expr1与expr3相等,则返回value2,...否则,返回default。
5、收集表的统计信息
收集表的统计信息方法有很多种: (1) ANALYZE (2) DBMS_STATS
 看起来很繁琐,其实用起来挺简单的。
如对某张表进行分析:
ANALYZE TABLE TABLE_NAME COMPUTE STATISTICS;
目前,ORACLE官方推荐第二种方法。在DBMS_STATS包里有很多过程和方法,对SCHEMA、TABLE和INDEX进行收集统计信息相关的操作。
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME= SCOTT,TABNAME= EMP,DEGREE= 4,CASCADE= TRUE);
最新内容请见作者的GitHub页:http://qaseven.github.io/
看起来很繁琐,其实用起来挺简单的。
如对某张表进行分析:
ANALYZE TABLE TABLE_NAME COMPUTE STATISTICS;
目前,ORACLE官方推荐第二种方法。在DBMS_STATS包里有很多过程和方法,对SCHEMA、TABLE和INDEX进行收集统计信息相关的操作。
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME= SCOTT,TABNAME= EMP,DEGREE= 4,CASCADE= TRUE);
最新内容请见作者的GitHub页:http://qaseven.github.io/
Oracle SQL语句优化方法总结 1、SQL语句尽量用大写的 因为oracle总是先解析SQL语句,把小写的字母转换成大写的再执行。 2、使用表的别名 当在SQL语句中连接多个表时, 尽量使用表的别名并把别名前缀于每个列上。这样一来, 就可以减少解析的时间并减少那些由列歧义引起的语法错误。 3、选择最有效率的表名顺序(只在基于规则的优化器(RBO)中有效)
span strong span 1、数据累加 /span /strong /span SQL SELECT NAME, sum(sorce) OVER(ORDER BY NAME) 2 FROM temp2 3 ORDER BY NAME; NAME SUM(SORCE)OVER(ORDERBYNAME) ---------- --------------------------- 1 43 2 66 3 108 4 195 5 207 span strong span 2、去掉最大值和最小值 /span /strong /span SQL SELECT NAME, 2 sorce, 3 LAG(sorce) over(order by sorce) Lag_List, 4 LEAD(sorce) over(order by sorce) Lead_List 5 FROM temp2; NAME SORCE Lag Lead ---------- ---------- ---------- ---------- 5 12 23 2 23 12 42 3 42 23 43 1 43 42 87 4 87 43
3 RANK() OVER(order by value) RANK_SORT, 4 DENSE_RANK() OVER(order by value) DENSE_SORT, 5 ROW_NUMBER() OVER(order by value) ROW_SORT 6 FROM sorce; NAME VALUE RANK_SORT DENSE_SORT ROW_SORT ---------- ------ ---------- ---------- ---------- wu 21 1 1 1 zhang 60 2 2 2 Li 70 3 3 3 xue 119 5 5 5 span wang 130 6 6 6 chen 130 6 6 7 sun 175 8 7 8 /span zhao 285 9 8 9 su 359 10 9 10 Li 480 11 10 11 br 可见三者的区别: br RANK()OVER():如果值相同,则两者顺序号相同,随机一个在另外一个的上边,而且顺序号会有间断,不是连续的; br DENSE_RANK():如果值相同,则两者顺序号相同,随机一个在另外一个的上边,而且顺序号仍然是连续的,不存在断层的现象; br ROW_NUMBER():如果值相同,则两种顺序号不同,安装顺序号依次排开,而且顺序号是连续的。 2、TRANSLATE()函数
translate函数与replace类似,但是又与replace不同,translate指定字符串string中出现的from_str,将from_str中各个字符替换成to_str中位置顺序与其相同的to_str中的字符。
SQL Reference中给的例子:SELECT TRANSLATE(SQL*Plus Users Guide, */, ___) FROM DUAL;
(1)判断一个字符串是数字
SELECT TRANSLATE(ABC123,#1234567890.,#) FROM DUAL;
(2)统计字符E出现的次数
SELECT LENGTHB(TRANSLATE(ABCDEFGEFGDBE,E||ABCDEFGEFGDBE,E)) FROM DUAL;
3、ROUND()函数
我们平时用得最多的是第一种,用ROUND()函数作为数据四舍五入运算,其实ROUND函数还有第二种形式,对日期进行格式化操作,与TRUNC()函数类似。
如:SELECT ROUND(SYSDATE,yyyy) FROM DUAL;
SELECT ROUND(SYSDATE,MM) FROM DUAL;
SELECT ROUND(SYSDATE,HH24) FROM DUAL;
4、NVL相关函数
NVL相关的函数有:NVL(expr1,expr2),NVL2(expr1,expr2,expr3),NULLIF(expr1,expr2),DECODE(expr1,expr2,value1,expr3,value2...,default)
(1) NVL(expr1,expr2) :如果expr1为空,则用expr2来替换。
(2) NVL2(expr1,expr2,expr3) :如果expr1非空,则返回expr2,否则返回expr3。
(3) NULLIF(expr1,expr2):将expr1和expr2做比较,如果想等,则返回null,否则返回expr1。
(3) DECODE(expr1,expr2,value1,expr3,value2...,default):如果expr1与expr2相等,则返回value1,如果expr1与expr3相等,则返回value2,...否则,返回default。
5、收集表的统计信息
收集表的统计信息方法有很多种: (1) ANALYZE (2) DBMS_STATS
看起来很繁琐,其实用起来挺简单的。
如对某张表进行分析:
ANALYZE TABLE TABLE_NAME COMPUTE STATISTICS;
目前,ORACLE官方推荐第二种方法。在DBMS_STATS包里有很多过程和方法,对SCHEMA、TABLE和INDEX进行收集统计信息相关的操作。
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME= SCOTT,TABNAME= EMP,DEGREE= 4,CASCADE= TRUE);
最新内容请见作者的GitHub页:http://qaseven.github.io/
Oracle SQL语句优化方法总结 1、SQL语句尽量用大写的 因为oracle总是先解析SQL语句,把小写的字母转换成大写的再执行。 2、使用表的别名 当在SQL语句中连接多个表时, 尽量使用表的别名并把别名前缀于每个列上。这样一来, 就可以减少解析的时间并减少那些由列歧义引起的语法错误。 3、选择最有效率的表名顺序(只在基于规则的优化器(RBO)中有效)
相关文章
- Oracle-查看oracle是否有表被锁
- ORACLE SQL调优案例一则
- ORACLE——Instant Client配置SQL*LDR、EXP等命令工具
- Oracle初级性能优化总结
- Oracle中查询某字段不为空或者为空的SQL语句怎么写
- 【学习总结】SQL的学习-1-初识数据库与sql
- Oracle 10g 到11g的数据迁移 导入导出 顺序步骤 expdp/impdp
- 查看oracle归档日志路径2
- 更改oracle集群中的的公用/互联IP子网配置
- Oracle v$sql,v$sqlarea,v$sqltext区别
- Oracle 标准审计
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- Oracle 取出多个字段列中的最大值和最小值
- oracle exp 问题
- Oracle或者Pl/Sql中001与1一样吗?
- C# Oracle 连接与修改
- Oracle 11g安装步骤
- Oracle的登陆问题和初级学习增删改查(省略安装和卸载)
- ORACLE 11G 怎样改动 awr 的保留期限小于8天
- 3.数据库操作相关术语,Oracle认证,insert into,批量插入,update tablename set,delete和truncate的差别,sql文件导入
- Oracle的学习心得和知识总结(十九)|Oracle数据库Real Application Testing之SQL Performance Analyzer实操(二)
- 【大数据开发运维解决方案】Ogg For Bigdata 同步Oracle数据到KAFKA(包括初始化历史数据)