
Pandas中如何实现SQL中的窗口函数?
2023-09-11 14:16:24 时间
窗口函数概念
窗口函数:被称为联机分析函数(OLAP,Online Anallytical Processing)或者分析函数(Analytic Function)
窗口函数允许用户根据数据行与所谓窗口【so-called window】中的当前行之间的某种关系对数据行执行计算,并对每一行数据返回分析结果,所以使用窗口函数时,必须始终记住当前行。

常用的窗口函数
- 聚合函数:sum()、count()、max()、min()、avg()
- 排序函数:row_number()、rank()、dense_rank()
- 分布函数:percent_rank()、cume_dist()
- 平移函数:lead()、lag()
- 首尾函数:first_val()、last_val()
主要概念
- 分区(partition by):partition by类似group by对数据进行分区,此时,窗口函数会对每个分区单独进行分析,如果不指定partition by将会对整体数据进行分析。
- 排序(order by):order by对分区內的数据进行排序,默认为升序
- 窗口大小(frame_clause):frame_clause指对分区集合指定一个移动窗口,当指定了窗口大小后函数就不会在分区上进行计算,而是基于窗口大小內的数据进行计算。窗口大小的格式如下:
- rows between UNBOUNDED PRECEDING AND CURRENT ROW,表示统计从第一行至当前记录行。
- rows between 1 PRECEDING AND 1 FOLLOWING,表示当前行和前一行及后面一行聚合,多用于针对最近一段时间的数据进行统计
- rows between current row and UNBOUNDED FOLLOWING,表示当前行及后面所有行。
使用示例
聚合函数使用示例
支持在Windows上应用所有的标准聚合函数,如min, max, avg等
select deptName, employeeName, salary,
sum(salary) over(partition by deptName) as sum_salary,
avg(salary) over(partition by deptName) as avg_salary,
min(salary) over(partition by deptName) as min_salary,
max(salary) over(partition by deptName) as max_salary
from data order by deptName
import pandas as pd
import numpy as np
pd.set_option('display.float_format', lambda x: '{:.0f}'.format(x))
data=pd.DataFrame({
"deptName":["研发部","研发部","产品部","产品部","项目部","项目部","研发部","产品部"],
"employeeName":["张三","李四","王五","赵六","李明","赵亮","张凯","赵敏"],
"salary":[10000,13000,12000,9000,12500,8500,8900,12000]
}
)
windowDF = data.groupby('deptName')['salary'];
data['sum_salary'] = windowDF.transform('sum')
data['min_salary'] = windowDF.transform('min')
data['mean_salary'] = windowDF.transform('mean')
data['max_salary'] = windowDF.transform('max')
data.sort_values('deptName')

排序函数使用示例
排序函数常用于对分组集或者整体数据进行排名:
- row_number:对分组內的数据进行"同分不同级"方式排序,不存在序号并列的现象,即使同分时排序也会不同。
- rank:对分组內的数据进行"同分同级且不紧密"方式排序,当同分时序号相同,其它排序按正常排名进行排序,即1,2,2,4,5。
- dense_rank:对分组內的数据进行"同分同级且紧密"方式排序,当同分时序号相同,其它排序按下一排名进行排序,即1,2,2,3,4。
select deptName, employeeName, salary,
row_number(salary) over(partition by deptName order by salary desc) as row_number,
rank(salary) over(partition by deptName order by salary desc) as rank,
dense_rank(salary) over(partition by deptName order by salary desc) as dense_rank
from data order by employeeName,salary
data=pd.DataFrame({
"deptName":["研发部","研发部","产品部","产品部","项目部","项目部","研发部","产品部"],
"employeeName":["张三","李四","王五","赵六","李明","赵亮","张凯","赵敏"],
"salary":[10000,13000,12000,9000,12500,8500,8900,12000]
}
)
windowDF = data.groupby('deptName')['salary'];
data['row_number'] = windowDF.rank(ascending=False,method='first')
data['rank'] = windowDF.rank(ascending=False,method='min')
data['dense_rank'] = windowDF.rank(ascending=False,method='dense')
data.sort_values(['deptName','salary'])

分布函数使用示例
分布函数主要分为两类:percent_rank()和cume_dist():
- percent_rank():指按照排名计算百分比,即该排名位于区间[0,1]的位置,其中区间内第一名为值0,最后一名值为1。其具体公式为:
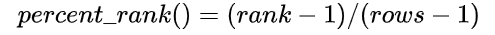
- cume_dist():指区间內大于等于当前排名的行数占区间内总函数的比例。多用于判断比当前薪资、得分高的用户比例为多少。
select deptName, employeeName, salary,
percent_rank(salary) over(partition by deptName order by salary desc) as percent_rank,
cume_dist(salary) over(partition by deptName order by salary desc) as cume_dist
from data order by employeeName,salary
pd.set_option('display.float_format', lambda x: '{:.2f}'.format(x))
data=pd.DataFrame({
"deptName":["研发部","研发部","产品部","产品部","项目部","项目部","研发部","产品部"],
"employeeName":["张三","李四","王五","赵六","李明","赵亮","张凯","赵敏"],
"salary":[10000,13000,12000,9000,12500,8500,8900,12000]
}
)
windowDF = data.groupby('deptName')['salary'];
data['rank'] = windowDF.rank(ascending=False,method='min')
data['count'] = windowDF.transform('size')
data['percent_rank'] = (windowDF.rank(ascending=False,method='min')-1) / (windowDF.transform('count')-1) #如果分组只有一个记录则数据为na
data['cume_dist'] = windowDF.rank(ascending=False,method='first',pct=True) #可以结合排序函数的方法使用
data.sort_values(['deptName','salary'])

平移函数使用示例
平移函数主要分为两类:lead(列名,n)和lag(列名,n),此函数多用于计算指标同比、环比:
- lead(列名,n):获取分区內向下平移n行数据。
- lag(列名,n):获取分区內向上平移n行数据。
select deptName, employeeName, salary,
lead(salary,1) over(partition by deptName order by salary desc ) as lead,
lag(salary,1) over(partition by deptName order by salary desc) as lag
from data order by deptName,salary desc
pd.set_option('display.float_format', lambda x: '{:.0f}'.format(x))
data=pd.DataFrame({
"deptName":["研发部","研发部","产品部","产品部","项目部","项目部","研发部","产品部"],
"employeeName":["张三","李四","王五","赵六","李明","赵亮","张凯","赵敏"],
"salary":[10000,13000,12000,9000,12500,8500,8900,12000]
}
)
data['lead'] = data.sort_values(['deptName','salary'],ascending=False).groupby('deptName')['salary'].shift(-1) # 分区內向下平移一个单位
data['lag'] = data.sort_values(['deptName','salary'],ascending=False).groupby('deptName')['salary'].shift(1) # 分区內向上平移一个单位
data.sort_values(['deptName','salary'],ascending=False)

首尾函数使用示例
首尾函数主要分为两类:first_val()和last_val():
- first_val():获取分区內第一行数据。
- last_val():获取分区內最后一行数据。
select deptName, employeeName, salary,
first_val(salary) over(partition by deptName order by salary desc ) as first_val,
# 由于窗口函数默认的是第一行至当前行,所以在使用last_val()函数时,会出现分区内最后一行和当前行大小一致的情况,因此我们需要将分区偏移量改为第一行至最后一行。
last_val(salary) over(partition by deptName order by salary desc rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING) as last_val
from data order by deptName,salary
data=pd.DataFrame({
"deptName":["研发部","研发部","产品部","产品部","项目部","项目部","研发部","产品部"],
"employeeName":["张三","李四","王五","赵六","李明","赵亮","张凯","赵敏"],
"salary":[10000,13000,12000,9000,12500,8500,8900,12000]
}
)
data['first_val'] = data.groupby('deptName')['salary'].transform('min')
data['last_val'] = data.groupby('deptName')['salary'].transform('max')
data.sort_values(['deptName','salary'],ascending=True)

其它函数使用示例
Top n rows per group 每组取topN
基于餐厅消费数据,按天统计给消费最高的2笔记录
SELECT * FROM (
SELECT
t.*,
ROW_NUMBER() OVER(PARTITION BY day ORDER BY total_bill DESC) AS rn
FROM tips t
)
WHERE rn < 3
ORDER BY day, rn;
url = (
"https://raw.github.com/pandas-dev/pandas/main/pandas/tests/io/data/csv/tips.csv"
)
tips = pd.read_csv(url)
# 如果tips.csv已经下载到本地,可以使用如下语句读取数据
# tips = pd.read_csv("data/tips.csv")
## 方式1
tips.assign(
rn=tips.sort_values(["total_bill"], ascending=False)
.groupby(["day"])
.cumcount()
+ 1
).query("rn < 3").sort_values(["day", "rn"])
## 方式2
tips.assign(
rnk=tips.groupby(["day"])["total_bill"].rank(
method="first", ascending=False
)
).query("rnk < 3").sort_values(["day", "rnk"])

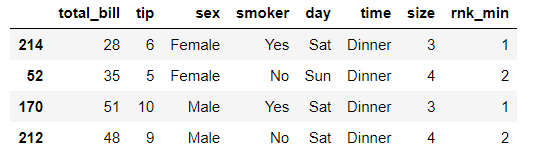
按性别统计给小费最高的2笔记录
SELECT * FROM (
SELECT
t.*,
RANK() OVER(PARTITION BY sex ORDER BY tip desc) AS rnk
FROM tips t
WHERE tip < 2
)
WHERE rnk < 3
ORDER BY sex, rnk;
(
tips
.assign(rnk_min=tips.groupby(["sex"])["tip"].rank(method="min",ascending=False))
.query("rnk_min < 3")
.sort_values(["sex", "rnk_min"],ascending=True)
)
nlargest的使用示例
SELECT * FROM tips ORDER BY tip DESC LIMIT 10 OFFSET 5;
tips.nlargest(10 + 5, columns="tip").tail(10)

参考
pandas comparison_with_sql
clickhouse–Window Functions 窗口函数概念讲解及实际使用示例
相关文章
- 【Python实战】Pandas:让你像写SQL一样做数据分析(一)
- pandas之表格样式
- SQL Tune Report–sqltrpt.sql
- 整理 pandas 常用函数
- pandas所占内存释放
- numpy中np.nan(pandas中NAN)
- [SQL] sql server中如何查看执行效率不高的语句
- pandas的使用方法
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- Sql Server中sql语句自动换行
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- Atitit 读取数据库的api orm SQL Builder sql对比 目录 1.1. 提高生产效率的 ORM 和 SQL Builder1 1.2. SQL Builder 在 SQL
- Database之SQL:自定义创建数据库的各种表demo集合(以方便理解和分析sql的各种增删改查语法的具体用法)
- Database之SQL:自定义创建数据库的各种表demo集合(以方便理解和分析sql的各种增删改查语法的具体用法)
- Python之Pandas:pandas.read_csv()函数的简介、具体案例、使用方法详细攻略
- Py之Pandas:Python的pandas库简介、安装、使用方法详细攻略
- 【sql优化】(大表小技巧)有时候 2 小时的 SQL 操作,可能只要 1 分钟
- 100天精通Python(数据分析篇)——第62天:pandas常用统计方法大全(含案例)
- 数据处理,Pandas vs SQL 你会选择哪一个?
- 010-Hadoop Hive sql语法详解5-HiveQL与SQL区别
- sql 精读(四) 标准 SQL 中聚合分析功能示例
- SQL——Sql_Server中如何判断表中某字段、判断表、判断存储过程以及判断函数是否存在
- SQL注入 Sqli-labs-Less-21(笔记)——还是回显注入 使用union select即可 但是要注意sql括号闭合 也可以报错注入
- 已解决mysql shell 中 没有numpy & pandas module
- Pandas数据处理——通过value_counts提取某一列出现次数最高的元素
- 如何在 Pandas DataFrame 列中搜索值?