
Andrew Ng-机器学习基础笔记-聚类
目录
14 降维(Dimensionality Reduction)
13 聚类(Clustering)
13.1 无监督学习:简介
无监督学习是让机器学习无标签的数据,而不是我们之前实验的有标签的数据
我们拿到没有标签的数据是这样的

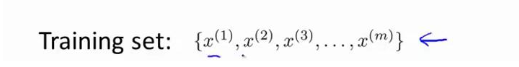
在非监督学习中,我们需要将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个 算法,快去为我们找找这个数据的内在结构给定数据.
图上的数据看起来可以分成两个分开的点集 (称为簇) , 一个能够找到我圈出的 这些点集的算法,就被称为聚类算法

当然, 此后我们还将提到其他类型的非监督 学习算法,它们可以为我们找到其他类型的结构或者其他的一些模式,而不只是簇。
聚类算法一般用于做什么呢?

与第一章提到的一样如图。
13.2 K-均值算法
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的 组。
K-均值是一个迭代算法,假设我们想要将数据聚类成 n 个组,其方法为
- 首先选择 k 个随机的点,称为聚类中心
- 对于数据集中的每一个数据, 按照距离 K 个中心点的距离, 将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。
(通俗的来说,我们每一次都重复这个族的中心为位置--质心)
下面是一个聚类示例:


用 ![]() 来表示聚类中心, 用
来表示聚类中心, 用 ![]() 来存储与第i个实例数据最近的聚 类中心的索引,K-均值算法的伪代码如下:
来存储与第i个实例数据最近的聚 类中心的索引,K-均值算法的伪代码如下:

算法分为两个步:
第一个for循环是赋值步骤,即:对于每一个样例i,计算其应该属 于的类。
第二个for循环是聚类中心的移动,即:对于每一个类k,重新计算该类的质心。
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在没有非常明显区分的组 群的情况下也可以
用于帮助确定将要生产的T-恤衫的三种尺寸:
13.3 优化目标
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和, 因此 K-均值的代价函数(又称畸变函数 Distortion function)为: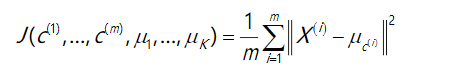

K-均值迭代算法,我们知道,第一个循环是用于减小c(i)引起的代价,而第二个循环则 是用于减小 u(i)引起的代价
13.4 随机初始化
在运行 K-均值算法的之前,我们首先要随机初始化所有的聚类中心点:
1. 我们应该选择 K<m,即聚类中心点的个数要小于所有训练集实例的数量
2. 随机选择 K 个训练实例,然后令 K 个聚类中心分别与这 K 个训练实例相等
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。

为了解决这个问题,我们通常需要多次运行K-均值算法,每一次都重新进行随机初始化,多次运行比较K均值结果,选择代价函数最小的结果。这种方法在 k 较小的时候(2--10)还是可行的,但是如果 k 较大,这么做也可能不会有明显地改善。
13.6 选择聚类数
通常根据不同的情况人工选择,通过作图分析我们可以采用一种叫做“肘部法则,”然后计算成本 函数或者计算畸变函数 J

好像有一个很清楚的肘在那儿,那个点是曲线的肘点,畸变值下降得很快。当你应用“肘部法则”的时候,如果你得到了一个像上面这样的图,那么这将是一种 用来选择聚类个数的合理方法
14 降维(Dimensionality Reduction)
14.1 动机一:数据压缩
开始谈论第二种类型的无监督学习问题,称为降维。
作用:使用较少的计算机内存或磁盘空间,但它也让我们加快我们的学习算法

x1 :长度:用厘米表示; x2 :是用英寸表示同一物体的长度。其实现实生活中也是这样很多时候,很多数据都是冗余的,因此有了降纬这种说法。
一千多个特征都在一起,它实际上会变得非常困难,去跟踪你知道的那些特征,你从那些工程队得到的。 其实不想有高度冗余的特征一样。

比如飞行员测试调查:: x1 , 也许是他们的技能 (直升机飞行员) , 也许 x2 可能是飞行员的爱好。也许这两个特征值高度高度相关

其实同理,我们有时可以也可将三维数据降到二维

处理过程可以被用于把任何维度的数据降到任何想要的维度, 例如将 1000 维的 特征降至 100
14.2 动机二:数据可视化
我们能将数据可视,降纬是一个好办法

要将这个50维的数据可视化是不可能的,我们需要将他降到2纬,便可以将其可视化了

降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了。
14.3 主成分分析问题
主成分分析(PCA)是最常见的降维算法。
在PCA中,我们要找到的是一方向向量(Vector direction),当我们的数据投射到该向量的时候,希望投射平均均方误差能尽可能地小。方向向量经过原点,而投射误差是从特征向量向该方向向量作垂线的长度

分析问题的描述:
将 n 维数据降至 k 维,注意主成分分析与线性回顾的比较:
主成分分析与线性回归是两种不同的算法。
主成分分析最小化的是投射误差(Projected Erro),而线性回归尝试的是最小化预测误
线性回归的目的是预测结果,而主成分分析不作任何预测。

左边的是线性回归的误差(垂直于横轴投影) 右边则是主要成分分析的误差 (垂直于红线投影)
PCA 将 n 个特征降维到 k 个, 可以用来进行数据压缩, 如果 100 维的向量最后可以用 10 维来表示,那么压缩率为 90%
同样图像处理领域的 KL 变换使用 PCA 做图像压缩。但 PCA 要保证降维后,还要保证数据的特性损失
PCA 技术的一大好处是对数据进行降维的处理。
我们可以对新求出的 “主元” 向量的重 要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化 模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
PCA 技术的一个很大的优点是,它是完全无参数限制的。在 PCA 的计算过程中完全不 需要人为的设定参数或是根据任何经验模型对计算进行干预, 最后的结果只与数据相关, 与 用户是独立的。
一点同时也可以看作是缺点。却无法通过参数化等方法对处理过程进行干预, 可能会得不到预期的效果, 效率也不高。
14.4 主成分分析算法
PCA 减少n维到k维

这一部分学得比较闷后面通过课后作业补上!
14.5 选择主成分的数量
主要成分分析是减少投射的平均均方误差
训练集的方差为: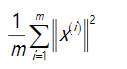
希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的k值。
直到找到可以使得比例小于1%的最小k值(原因 是各个特征之间通常情况存在某种相关性)
还有一些更好的方式来选择k,我们在Octave中调用“svd”函数的时候,我们获得三
个参数:[U, S, V] = svd(sigma)。(后期作用python在补充)
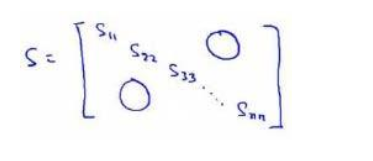
S是一个n×n的矩阵,只有对角线上有值,而其它单元都是0,我们可以使用这 个矩阵来计算平均均方误差与训练集方差的比例
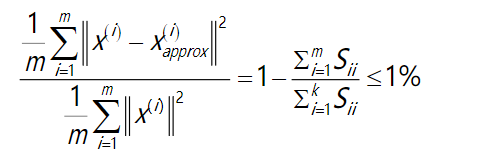
也就是: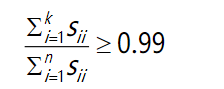
压缩过数据后,我们可以采用如下方法来近似地获得原有的特征
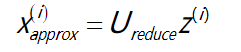
(这部分讲得这是抽象。。。)
14.6 重建的压缩表示
当我们压缩后我们希望重新回到压缩前,又叫做重建的压缩

回到原始的二维空间: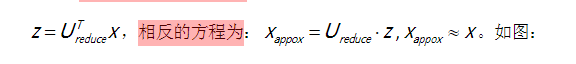

如图, 这是一个漂亮的与原始数据相当。我们也把这个过程称为重建原始 数据。
重建从压缩表示 x 的初始值,现在也知道 如何采取这些低维表示 z,映射到备份到一个近似你原有的高维数据。
通过课后作业进行完善。
课后学习笔记:
相关文章
- 机器学习-文本聚类实例-kmeans
- (《机器学习》完整版系列)第12章 计算学习理论——12.2 学习算法的能力(多项式成本是可以接受的,而指数成本是不可接受的)
- 常用机器学习面试基础概念题汇总
- 大疆笔试——机器学习提前批
- 深度学习机器学习笔试面试题——初始化方法
- 机器学习笔记之狄利克雷过程(六)预测任务求解
- 机器学习笔记之概率图模型(八)信念传播(Belief Propagation,BP)(基于树结构)
- 《面向机器智能的TensorFlow实践》一1.7 TensorFlow的优势
- 【机器学习】24个终极项目提升您的机器学习知识和技能
- 《Python机器学习——预测分析核心算法》——小结
- 入行数据分析要知道什么是机器学习优化思想
- Python机器学习零基础理解随机森林算法
- Python机器学习零基础理解DBSCAN聚类
- Python机器学习零基础理解K-means聚类
- Python机器学习零基础理解支持向量机
- Python机器学习零基础理解线性回归分析
- 如何用ip代替机器名访问sharepoint site
- 《Scala机器学习》一一1.6 相关性的基础
- 毕业设计 机器视觉验证码识别系统
- 机器学习的数学基础-(一、高等数学)(转)
- 机器学习--线性代数基础