
如何捕捉冗长讨论里的目标信息?谷歌推出最大标注数据集
信息爆炸时代,如何在浩瀚如海的网络中找到自己的需求?谷歌研究团队推出了 Coarse Discourse 数据集,可以将一段文字中“废话”剔除,精准识别用户所需要的目标信息。作为一名雷锋网(公众号:雷锋网)编辑,信息搜集和分类是日常工作中极为耗时的一件事。谷歌推出的新方法能否解决这一问题?
每一天,社区中的活跃者都在发送和分享他们的意见,经验,建议以及来社交,其中大部分是自由表达,没有太多的约束。这些网上讨论的往往是许多重要的主题下的关键信息资源,如养育,健身,旅游等等。不过,这些讨论中往往还夹杂着乱七八糟的分歧,幽默,争论和铺垫,要求读者在寻找他们要的信息之前先过滤内容。信息检索领域正在积极探索可以让用户能够更有效地找到,浏览内容的方式,在论坛讨论缺乏共享的数据集可以帮助更好地理解这些讨论。
在这个空间中为了帮助研究人员,谷歌发布了 Coarse Discourse dataset,是最大的有注释的数据集。 Coarse Discourse dataset包含超过10万条人可在线讨论的公开注解,这些是从reddit.com网站中的130个社区,超过9000个主题中随机抽取的。
为了创建这个数据集,我们通过一小部分的论坛线程开发了论坛注解的话语分类系统。通俗的说就是阅读每一个评论,并判断评论在讨论中扮演什么角色。我们用众包的人工编辑再重复和修正这种练习来验证话语类型分类的重现性,包括:公告,问题,答案,协议,分歧,阐述和幽默。从这个数据,超过10万条的评论由众包编辑单独注释其话语类型和关系。连同众包编辑的原注释,我们还提供标注任务指南,供编辑们使用帮助他们从其他论坛收集数据和对任务进一步细化。
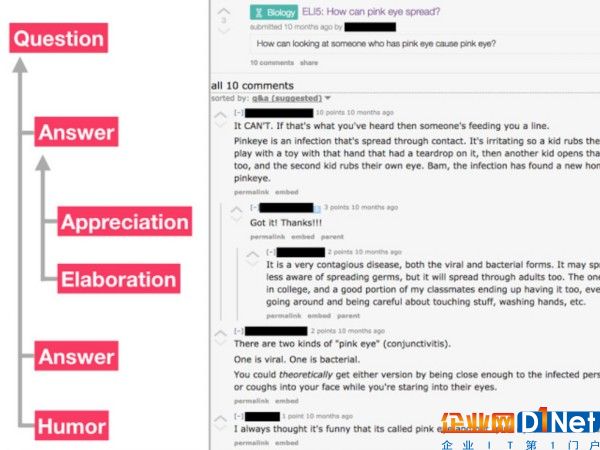
图中为用话语类型和关系来注释的示例线程。早期的研究结果表明,问和答模式在大多数社区是一个突出的运用,有的社区会话更集中,来回的相互作用。
论文摘要
在这项工作中,我们提出了一种新的方法将在线讨论中的评论分类成一些粗糙语料,是为了在一定规模上更好理解讨论这个目标的实现。为了促进这项研究,我们设计了一个粗糙语料的分类,旨在围绕一般在线讨论,并允许工作人员简单注释。使用我们的语料库,我们演示了如何分析话语行为,可以描述不同类型的讨论,包括话语序列,如问答配对,分歧链,以及不同的社区中的表现。
最后,我们进行实验,使用我们的语料库预测话语行为,发现结构化预测模型,如在条件随机场合下可以实现F1得分75%。我们还演示了如何扩大话语行为,从单一的问和答到更丰富的类别。可以提高Q A抽取的召回性能。
实验结论
使用了一种新的话语行为的分类,我们推出一个从Reddit上数千个社区采样,最大的人工标注的数据集的讨论,在每个线程上的每个评论根据话语行为和关系注释。从我们的数据集,我们观察到常见的话语序列模式,包括问答和参数,并使用这些信号来表征社区。最后,我们用结构化CRF模型进行了分类的话语行为实验,实现了75% F1得分。此外,我们演示了如何使用我们的9个话语行为在只标签了问题和答案的模型,整体提高Q A抽取的召回性能。
本文转自d1net(转载)
一文尽览!弱监督语义/实例/全景分割全面调研(2022最新综述)(上) 今天分享一篇上交投稿TPAMI的文章,论文很全面的调研了广义上的弱监督分割算法,又涵盖了语义、实例和全景三个主流的分割任务。特别是基于目标框的弱监督分割算法,未来有很大的研究价值和落地价值,相关算法如BoxInst、DiscoBox和ECCV2022的BoxLevelset已经证明了,只用目标框可以实现可靠的分割性能。论文很赞,内容很扎实,分割方向的同学一定不要错过!
一文尽览!弱监督语义/实例/全景分割全面调研(2022最新综述)(下) 今天分享一篇上交投稿TPAMI的文章,论文很全面的调研了广义上的弱监督分割算法,又涵盖了语义、实例和全景三个主流的分割任务。特别是基于目标框的弱监督分割算法,未来有很大的研究价值和落地价值,相关算法如BoxInst、DiscoBox和ECCV2022的BoxLevelset已经证明了,只用目标框可以实现可靠的分割性能。论文很赞,内容很扎实,分割方向的同学一定不要错过!
一文尽览 | 开放世界目标检测的近期工作及简析!(基于Captioning/CLIP/伪标签/Prompt)(上) 人类通过自然监督,即探索视觉世界和倾听他人描述情况,学会了毫不费力地识别和定位物体。我们人类对视觉模式的终身学习,并将其与口语词汇联系起来,从而形成了丰富的视觉和语义词汇,不仅可以用于检测物体,还可以用于其他任务,如描述物体和推理其属性和可见性。人类的这种学习模式为我们实现开放世界的目标检测提供了一个可以学习的角度。
一文尽览 | 开放世界目标检测的近期工作及简析!(基于Captioning/CLIP/伪标签/Prompt)(下) 人类通过自然监督,即探索视觉世界和倾听他人描述情况,学会了毫不费力地识别和定位物体。我们人类对视觉模式的终身学习,并将其与口语词汇联系起来,从而形成了丰富的视觉和语义词汇,不仅可以用于检测物体,还可以用于其他任务,如描述物体和推理其属性和可见性。人类的这种学习模式为我们实现开放世界的目标检测提供了一个可以学习的角度。
Meta AI 全面开放 1750 亿参数大模型:首次毫无保留公开训练代码及使用代码、日志记录 Meta AI 的 OPT-175B 具有 1750 亿个参数,与 OpenAI 的 GPT-3 等商业语言模型相当。近日,Meta AI 宣布将全面开放 OPT-175B。这意味着大规模语言模型迎来大众化。
「人类高质量数据」从标注指南开始!Google 发布数据分析工具Know Your Data 由于标注人员的社会背景不同,所标注的数据也可能存在着固有偏见,从而导致训练的模型继承了这种偏见。Google 对于这个问题发布了一个数据分析平台Know Your Data,能做三件事,让数据变得公平、公平、还是公平!
融合多视图行为信息的多任务查询补全推荐方法 | KDD 论文解读 本工作提出了一种融合多视图用户行为序列信息的多任务个性化查询补全推荐框架:通过同时建模和利用多视图用户行为序列中丰富的个性化信息,使QAC模型能够更准确地预测用户当前的搜索意图;通过候选排序与查询生成的多任务学习,同时利用多种学习目标与训练数据进行模型训练,实现了不同任务间的优势互补。整体框架在离线和在线的实验中均取得了不错的效果,为淘宝搜索引擎的查询补全推荐业务带来了显著的增益。
相关文章
- DAMA|2021城市数据化治理需求日益剧增,如何抓住机会?
- 数据存储之属性列表Plist
- EasyNVR网页摄像机无插件H5、谷歌Chrome直播方案之使用ffmpeg保存快照数据方法与代码
- 大数据基础之Logstash(3)应用之http(in和out)
- 南大《探索数据的奥秘》课件示例代码笔记01
- ArcGIS读取dem格式数据
- 如何利用Google谷歌浏览器来查看GET或POST请求以及传递的数据
- TF之LSTM/GRU:基于tensorflow框架对boston房价数据集分别利用LSTM、GRU算法(batch_size调优对比)实现房价回归预测案例
- Dataset之谷歌地图数据集:谷歌地图数据集的简介、安装、使用方法之详细攻略
- 混合样本数据增强(Mixed Sample Data Augmentation,MSDA)
- 【Android 逆向】修改运行中的 Android 进程的内存数据 ( Android 系统中调试器进程内存流程 | 编译内存调试动态库以及调试程序 )
- 小样本学习,阿里做得比较早,但是效果未知——小样本有3类解决方法(算法维度):迁移学习、元学习(模型基础上学习模型)、度量学习(相似度衡量,也就是搜索思路),数据维度还有GAN
- TGCA数据的标准化以及差异分析