
【视频目标检测论文阅读笔记】Optimizing Video Object Detection via a Scale-Time Lattice
1.1 论文信息
| 标题 | Optimizing Video Object Detection via a Scale-Time Lattice |
|---|---|
| 会议 | CVPR 2018 |
| 原文链接 | Optimizing Video Object Detection via a Scale-Time Lattice (thecvf.com) |
| 领域 | 视频目标检测(提升速度) |
| 性能 | 79.6 mAP(20fps)以及 79.0 mAP(62 fps) |
1.2 创新点
本篇论文的基本思路是:
| 由于检测的计算开销比较大,因此只在一段视频选取比较少的关键帧去执行检测,并通过视频帧之间丰富的上下文联系,以比较轻量的网络在规模和时间上去传播关键帧的检测结果。 |
|---|
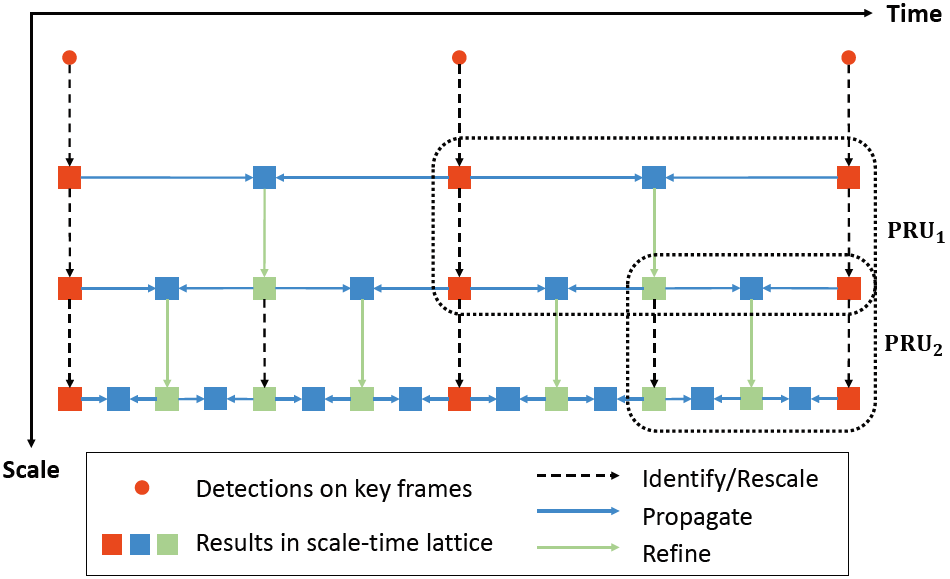
- 该论文提出了一个统一的框架叫 Scale-Time Lattice,此框架整合了基于图像的检测、时间上下文信息传播和跨尺度精细化**。如下图所示:
具体的创新点是:
创新点1:
本论文虽然没有提出新的模型,但是创新性地把目标检测各个步骤中的技术有机结合,构成了一个尺度/规模可调控的统一框架。从不同尺度,时间维度辅助非关键帧的检测,进行位置修正。可以轻松看到每一个步骤的贡献度和计算量的分布。
创新点2:
基于此框架,可以根据需求,自由设计不同尺度/规模的模型、重新分配计算资源,拥有极大的设计空间和灵活性。
创新点3:
与以往追求精度/速度的平衡不同,如空间金字塔或特征流,Scale-Time Lattice框架在时间上和空间上都是由粗到细的精细化操作。
1.3 实现步骤
1.3.1 框架整体流程

框架运行流程:
–> 视频
–> 基于稀疏自适应关键帧的目标检测 (红点)
–> 获得质量好的边界框 (红框) 传播给后面的非关键帧 (第1行蓝框)
–> 跨尺度精细化 (绿框)
–> 更高尺度上,传播给非关键帧 (第2行蓝框)
–> 重新调节尺度精细化 (虚线箭头后的绿框)
–> 更高尺度上,传播给非关键帧 (第3行蓝框)
1.3.2 提升检测速度的原因
原因1:
只在稀疏的关键帧调用计算开销大的目标检测器,而不是逐帧检测。极大地降低了计算量。并且通过计算量小的传播网络保持了不错的检测精度。
原因2:
提出了2个新组件:更高效的时间上下文信息传播网络、自适应关键帧选择方案。
1.3.3 Scale-Time Lattice
Scale-Time Lattice框架流程图:每一行与上一幅图的一行对应。
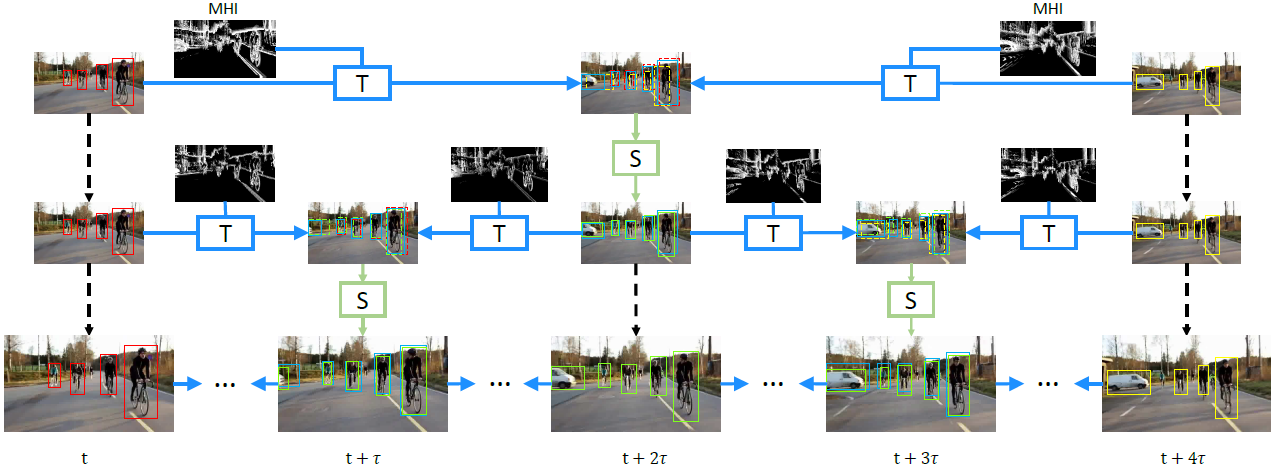
从横向来看,从左到右是时间轴。从纵向来看,从上到下是尺度规模逐渐增大。这个过程主要包括两个主要操作:时间上下文信息传播和空间精细化。上图的水平箭头代表时间上下文信息传播;而竖直箭头代表空间精细化。检测结果在最底部的一行获得,最底部的一行的检查结果是最精细的,并覆盖了每一个非关键帧。
1.4 实验结果
1.4.1 实验条件
| 目标检测模型 | Faster R-CNN |
|---|---|
| 主干网络 | ResNet-101 |
| 迭代次数 | 200,000 |
| 显卡数量(张) | 8 |
| 数据集 | ImageNet VID 和 ImageNet DET |
1.4.2 精度-帧率图

该方法达到了 79.6 79.6 79.6 mAP( 20 20 20 fps)以及 79.0 79.0 79.0 mAP( 62 62 62 fps)。检测速度提高3倍的情况下,精度只下降了 0.6 0.6 0.6,可以说是非常具有竞争力了。
1.4.3 实际检测Demo
可以把下图实际检测与框架流程图对比着看:每行视频帧都对应框架流程图中的一行。

虽然第一行只有2帧调用了目标检测器,但从纵向来看,经过多次的 传播 --> 精细化 循环,就可以把关键帧的检测结果传送到两个关键帧中间的每一个非关键帧。这样即提升了检测速度,又维持了较好的检测精度。
1.4.4 计算量分布
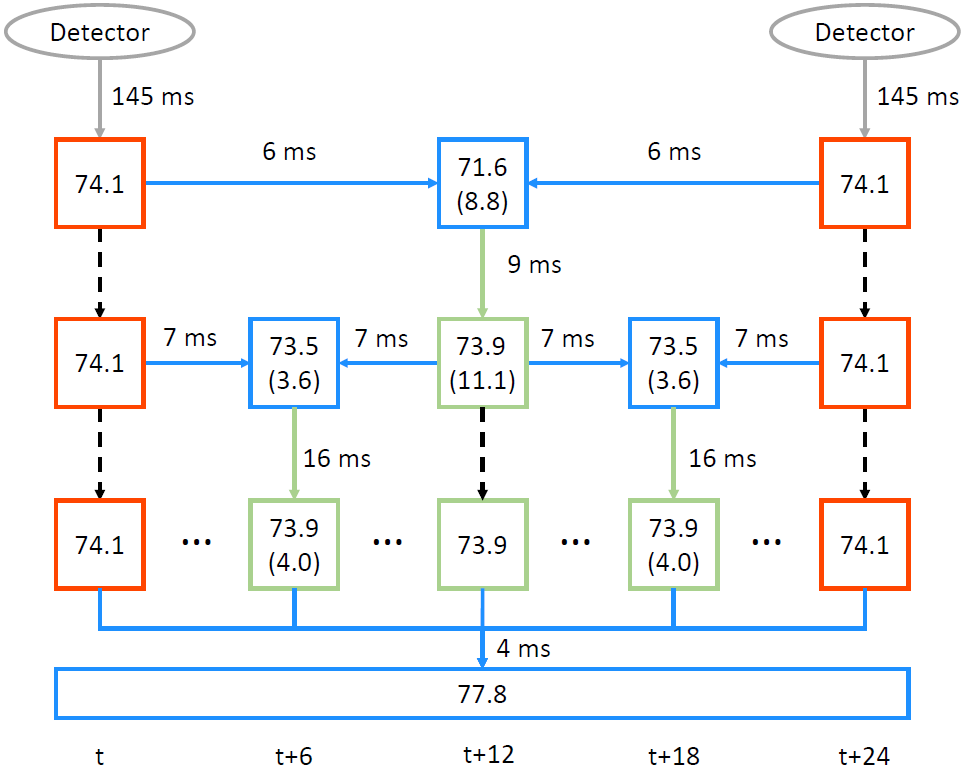
可见目标检测消耗的计算量比传播高2个数量级、比精细化高1个数量级。因此,应该尽可能选择检测的关键帧稀疏一点。
相关文章
- 论文笔记(7):Constrained Convolutional Neural Networks for Weakly Supervised Segmentation
- 论文笔记(5):Fully Convolutional Multi-Class Multiple Instance Learning
- Paper:可解释性之SHAP之《A Unified Approach to Interpreting Model Predictions—解释模型预测的统一方法》论文解读与翻译
- 计算机毕设 SSM Vue的药品管理系统(含源码+论文)
- 论文解读(Moco v3)《An Empirical Study of Training Self-Supervised Vision Transformers》
- 论文解读《Cross-Domain Few-Shot Graph Classification》
- 论文解读(Survey)《Principal Neighbourhood Aggregation for Graph Nets》
- NLP模型笔记2022-18:GCN/GNN模型在nlp中的使用【论文+源码】
- NLP模型笔记2022-15:深度机器学习模型原理与源码复现(lstm模型+论文+源码)
- NLP模型笔记2022-12:Deep Biaffine Attention for Neural Dependency Parsing【论文+源码】
- 论文投稿指南——中文核心期刊推荐(工业经济)
- 论文投稿指南——中文核心期刊推荐(金融)
- 论文投稿指南——中文核心期刊推荐(新闻事业)
- 论文投稿指南——中文核心期刊推荐(综合性经济科学 2)
- 论文投稿指南——中文核心期刊推荐(园艺)
- 论文笔记系列:经典主干网络(一)-- VGG
- 论文笔记:基于复合滑动窗的CUSUM暂态事件检测算法