
哈工大2022软件构造Lab2
说明
此博客内容为哈工大2022春季学期软件构造Lab2:ADT and OOP,文章为个人记录,不保证正确性,仅供练习和思路参考,请勿抄袭。实验所需文件可以从这里获取(若打不开可以复制到浏览器)。
实验环境:IntelliJ IDEA 2022.1(Ultimate Edition)
注:由于博客主要为思路提示,部分实验要求没有提及,请以实验指导书的要求为准。
一、Poetic Walks
原实验为MIT实验。
Problem 1
这一阶段要求编写test文件夹中GraphInstanceTest.java和GraphStaticTest.java中的测试单元,但并不真正地测试,在之后的阶段再来实现它们。
GraphStaticTest
这里一开始只给了一个如下的测试单元:
@Test
public void testEmptyVerticesEmpty() {
assertEquals("expected empty() graph to have no vertices",
Collections.emptySet(), Graph.empty().vertices());
}
它调用了Graph接口中的empty这个静态方法。由于接口无法实例化,需要在以后实现子类之后再来测试它。
GraphInstanceTest
这个文件比较特殊:它是一个abstract的JUnit测试。写成这样的原因如下:由于我们以后要实现两个实现类ConcreteEdgesGraph和ConcreteVerticesGraph,它们的方法行为在一定范围内应当是一致的。直觉上我们要为它们分别编写两个文件ConcreteEdgesGraphTest和ConcreteVerticesGraphTest。抽象的JUnit测试解决了这种重复性:把二者共同的测试单元放在抽象的JUnit测试文件中(本实验中为GraphInstanceTest),将一个newInstance方法留待子测试类来实现,在测试单元内用Graph引用之,就可以(在子类中)用实例化的实现类对象来测试了。更具体地,应该调用如下:
//GraphInstanceTest.java
...
public abstract Graph<String> emptyInstance();
...
/*
* Constructs a graph with 5 vertices named A,B,C,D,E and no edge
*/
@Test
public void testAdd() {
Graph<String> graph = emptyInstance();//正常测试graph即可
assertEquals(true, graph.add("A"));
assertEquals(true, graph.add("B"));
assertEquals(true, graph.add("C"));
assertEquals(true, graph.add("D"));
assertEquals(true, graph.add("E"));
assertEquals(false,graph.add("A"));
assertEquals("([A, B, C, D, E],[])", graph.toString());
}
//ConcreteEdgesGraph.java
@Override public Graph<String> emptyInstance() {
return new ConcreteEdgesGraph();
}
注意上面的代码块是两个文件的内容。这样,我们就可以在一个文件中测试两个子类的共同部分,在GraphInstanceTest调用graph的实例方法时,调用的实际上是子类中实现的方法。测试时需要在两个子类中run测试用例(在IDEA中如果选择run GraphInstanceTest时会提示选择测试哪个子类,如下图)
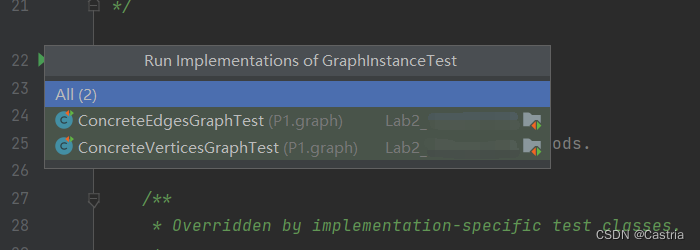
这一部分要求所有测试Graph所有的实例方法,上面给出了一个add方法的测试示例。其他部分可以类似地编写。
Problem 2
这一部分要求实现两个继承Graph的子类。
注:示例代码为了方便阅读没有加入checkRep.
ConcreteEdgesGraph
这个类的所有方法需要基于以下不能变动的表示来实现:
private final Set<String> vertices = new HashSet<>();
private final List<Edge> edges = new ArrayList<>();
需要我们写的东西很多:RI(Representation invariant,表示不变量),AF(Abstraction Function,抽象函数),checkRep()即检查表示不变量的方法,为什么实现能防止表示泄露,以及实现包括toString的各种方法。为了实现方法,还得设计并实现Edge类。下面我们依次完成。
RI & AF
首先我们先回顾一下表示不变量是什么。按个人理解,表示不变量指的是ADT所具有的某种性质,如果某个实例不满足表示不变量(这种性质),它就不能映射到“用户观察到的对象”这一集合。举一个例子,如果我们需要用一个数组保存大的正整数,数组的第0位表示最高位:
public class BigInt {
private int length;
private int[] data = new int[100];
public BigInt() {
//...
}
public int getValue() {
int val = 0;
for(int i = 0; i < length; i++)
val = val * 10 + data[i];
return val;
}
}
直观上来讲,这个数字的长度一定要大于 0 0 0;此外,data数组中保存的每个数应该在 0 0 0到 9 9 9之间,并且数组的第一个数字不应当为 0 0 0,这样才可以解释成一个数字(通过getValue()方法)。如果一个数组为 1 , 2 , 3 {1,2,3} 1,2,3,它就可以被解释为数字 123 123 123;但如果一个数组为 20 , 2 , 3 {20,2,3} 20,2,3,就不好说它被解释成什么了,这时候说它不满足表示不变量。
还用上面的例子,AF即抽象函数
f
f
f就是内部表示到外部观察集合的一个映射。用例子来说(这里只是记号,并不是严格数学记号):
f
:
i
n
t
[
]
→
i
n
t
,
f
(
{
1
,
2
,
3
}
)
=
123.
f:int[]\rightarrow int,f(\{1,2,3\})=123.
f:int[]→int,f({1,2,3})=123.
只有具有表示不变量的实例才能被映射。上面这个例子的RI和AF可以表示如下:
设
x
x
x是BigInt的一个实例,那么
R
I
(
x
)
=
x
.
l
e
n
g
t
h
>
0
&
&
x
.
d
a
t
a
[
0
]
>
0
&
&
x
[
i
]
∈
[
0
,
9
]
;
RI(x) = x.length>0 \ \&\&\ x.data[0]>0 \ \&\&\ x[i]\in[0,9];
RI(x)=x.length>0 && x.data[0]>0 && x[i]∈[0,9];
A
F
(
x
)
=
∑
i
=
0
x
.
l
e
n
g
t
h
x
.
d
a
t
a
[
i
]
x
.
l
e
n
g
t
h
−
i
−
1
.
AF(x)=\sum_{i=0}^{x.length}x.data[i]^{x.length-i-1}.
AF(x)=∑i=0x.lengthx.data[i]x.length−i−1.
回到这个问题。我们的图的要求不算太多:每条边的边权需要大于0,且每条边的点都应该出现在点集中。如果我们不用形式化的数学表述而用文字表示,RI和AF可以阐述为:
R
I
(
G
)
=
G
RI(G)=G
RI(G)=G中所有边的边权均大于0,且每条边的点都应该出现在点集中;
A
F
(
G
)
=
AF(G)=
AF(G)= vertices中点组成的集合
V
V
V和edges中边组成的集合
E
E
E构成的图
(
V
,
E
)
.
(V,E).
(V,E).
图的实现
实现思路很清晰:图的形式化表示就是 ( V , E ) (V,E) (V,E),分别为边集和点集;既然已经把vertices和edges这两个容器给我们了,我们按部就班地实现各个方法即可。首先我们需要先确定好Edge的实现:
Edge类
一条边显然应该包含起点、终点以及边权。我们只是简单地将三个域写一下getter,构造方法,以及toString()和checkRep().下面是部分代码:
注1:Edge类要求是一个不可变类型,不应该在创建后修改其值。
注2:本实验中的所有自定义方法应当标明specification.()
private final int weight;
private final String source, target;
//...
public Edge(String source, String target, int weight) {
this.source = source;
this.target = target;
this.weight = weight;
checkRep();
}
//...
private void checkRep() {
assert this.weight > 0;
}
//...
public String getSource() {
return this.source;
}
//...
@Override
public String toString() {
return String.format("(%s,%s,%d)",source.toString(), target.toString(), weight);
}
这里稍微解释一下checkRep方法的用法:它是一个私有方法,在对象内部数据被修改时应该被(实现的程序员)调用,以检查其表示不变量RI。用java的assert语句(后接一个真值表达式,不需要加括号)可以在条件不满足时报错,提醒程序员ADT的内部结构不满足要求了。在Edge类中,每条边都应该有大于零的边权,即其表示不变量。
add
原型如下(取自Graph接口中的specification):
public boolean add(String vertex);
实现功能为把点加入图中。这个实现没什么好说的,直接给出代码。加入之前需要判断一下是否已经存在该点。
@Override public boolean add(String vertex) {
if(vertices.contains(vertex)) {
return false;
}
return vertices.add(vertex);
}
set
函数原型:
public int set(String source, String target, int weight);
它的逻辑如下:
(1)若weight不为0,当存在(source, target)这条边时,将其边权修改为weight;否则当这条边不存在,加入这条边,边权为weight。
(2)若weight为0,当存在这条边时,删除这条边;否则什么也不做。
(3)返回值为操作前该边的权值。若不存在该边,返回0.
方法的核心代码如下:
Iterator<Edge> iterator = edges.iterator();
while(iterator.hasNext()) {
Edge e = iterator.next();
if(e.getSource().equals(source) && e.getTarget().equals(target)) {
int previousValue = e.getWeight();
iterator.remove();
//Since Edge class is immutable, we must delete the edge firstly,then re-add it.
if(weight > 0) this.set(source, target, weight);
return previousValue;
}
}
//new edge
if(weight != 0) {
if(!vertices.contains(source)) vertices.add(source);
if(!vertices.contains(target)) vertices.add(target);
edges.add(new Edge(source, target, weight));
}
需要注意的地方是,由于限定Edge是Immutable的,在修改边权时我们需要先将其删除再加回去,而不能用一个setter直接修改它的值。
remove
函数原型:
public boolean remove(String vertex);
移除一个点以及与之相关联的所有边。如果该点不在图中,返回false;否则返回true。需要解释的地方也不多,其中删除点部分的代码如下:
boolean flag = false;
Iterator<String> stringIterator = vertices.iterator();
//find vertex in vertices and remove it(if it exists). flag = vertices.contains(vertex).
while(stringIterator.hasNext()) {
String label = stringIterator.next();
if(label.equals(vertex)) {
flag = true;
stringIterator.remove();
break;
}
}
删去相连的边也很简单,遍历边列表,若其source或target为参数vertex,直接删去它。最后返回flag即可。
vertices
原型:
public Set<String> vertices();
这里需要注意的是不能图方便直接把vertices集合返回,会导致表示泄露。要通过防御性拷贝返回一个新的副本给用户,避免用户拿到内部表示的引用。
public Set<String> vertices() {
return new HashSet<>(vertices);
}
sources,target
原型:
public Map<String, Integer> sources(String target);
public Map<String, Integer> targets(String source);
以targets为例,它返回一个Map,键集合为参数source能到达的所有点;值为source到该点的边权。实现也很简单,遍历边集即可。
Map<String, Integer> map = new HashMap<>();
for(Edge e: edges) {
if(e.getSource().equals(source)) {
map.put(e.getTarget(), e.getWeight());
}
}
return map;
sources的实现很类似,不再给出。
toString
返回字符串的格式是自己规定的,由于我想让toString对于同一个图返回相同的结果(无论加入点、边的顺序如何),我把边和点分别按字典序排了一下序(TreeSet)。
Set<String> V = new TreeSet<>();
Set<String> E = new TreeSet<>();
for(String s: vertices) V.add(s.toString());
for(Edge e:edges) E.add(e.toString());
return String.format("(%s,%s)",V.toString(), E.toString());
//2022/5/19:余下内容明天补全
ConcreteVerticesGraph
这部分要求我们基于如下的容器实现:
private final List<Vertex> vertices = new ArrayList<>();
Vertex类
由于只给我们了一个点集,我们只能把边的信息附在每个点上。很容易想到,对于一个点的实例,将它所有的出边及其边权用一个Map保存:
private String label; //该点的标签
final private Map<String, Integer> targets = new HashMap<>(); // 出边集合
为了方便ConcreteVerticesGraph的具体实现,我们在类中添加一些辅助方法:
set:
public int set(String target, int weight);
这个方法的逻辑与Graph接口中定义的相同,只是其中的source参数默认为该实例的标签。由于用Map存边,修改也变得简单很多:
if(!targets.containsKey(target)) {
if(weight > 0) {
targets.put(target, weight);
return 0;
}
}
else {
int val = targets.get(target);
if(weight == 0) targets.remove(target);
else if(weight > 0) targets.put(target, weight);
return val;
}
getWeightTo:
public int getWeightTo(String target);
这个方法返回该实例到target的边权。如果没有到target的边,返回0。用Map实现很简单,代码就不给出了。
targets:
public Map<String, Integer> targets();
用防御性拷贝返回一个targets的副本即可。
toString:
我们还需要重写一下Vertex的toString方法。这里我也用TreeSet把结果按字典序排了一下序。由于ConcreteVerticesGraph也需要重写toString方法,需要查询每个点的所有边,我还加了一个返回排好序的边集的方法edgeSet:
Set<String> set = new TreeSet<>();
for(String target: targets.keySet()) {
set.add(String.format("(%s,%s,%s)", label.toString(), target, targets.get(target)));
}
return set;
这样实现的toString方法只需要简单地调用一下edgeSet返回值的toString方法即可。
图的实现
add
函数原型在上面已经给出一遍,逻辑也解释过了,不重复说明了。
这个函数也很简单,遍历一次点列表查找是否有重复点,若有返回false;否则直接加入新点即可。
for(Vertex v: vertices) {
if(v.getLabel().equals(vertex))
return false;
}
return vertices.add(new Vertex(vertex));
set
这个方法实现的有点丑,主要是逻辑判断太繁杂了。这部分代码就不放了,提供一组测试数据,可以根据自己的toString输出方式改写一下对于toString方法testEquals的格式(或者直接删掉)。主要注意加入不存在的点的情况,其中还有起点和终点是同一个点而不在图中的情况。
/*
* (1) Constructs a cycle with 4 vertices A,B,C,D, then test set(A, G, 0)(It should have no effect)
* (2) Delete edge (D, A, 1);
* (3) Try to delete an edge from A to C(which does not exist);
* (4) Set the weight of (A, B, 1) to 2;
* (5) Add edge (A, E, 2) and (F, A, 2);
* (6) Add edge (G, G, 0) and (G, G, 1).(The latter will be added)
*/
@Test
public void testSet() {
Graph<String> graph = emptyInstance();
//(1) Constructs a cycle with 4 vertices A,B,C,D, then test set(A, G, 0)(It should have no effect)
graph.add("A");
graph.add("B");
graph.add("C");
graph.add("D");
assertEquals(0, graph.set("A","B",1));
assertEquals(0, graph.set("B","C",1));
assertEquals(0, graph.set("C","D",1));
assertEquals(0, graph.set("D","A",1));
assertEquals(0, graph.set("G","A",0));
assertEquals("([A, B, C, D],[(A,B,1), (B,C,1), (C,D,1), (D,A,1)])",graph.toString());
assertEquals(4, graph.vertices().size());
//(2) Delete edge (D, A, 1);
assertEquals(1, graph.set("D", "A", 0));
assertEquals("([A, B, C, D],[(A,B,1), (B,C,1), (C,D,1)])",graph.toString());
assertEquals(4, graph.vertices().size());
//(3) Try to delete an edge from A to C(which does not exist);
assertEquals(0, graph.set("A", "C", 0));
assertEquals("([A, B, C, D],[(A,B,1), (B,C,1), (C,D,1)])",graph.toString());
assertEquals(4, graph.vertices().size());
//(4) Set the weight of (A, B, 1) to 2.
assertEquals(1, graph.set("A", "B", 2));
assertEquals("([A, B, C, D],[(A,B,2), (B,C,1), (C,D,1)])",graph.toString());
assertEquals(4, graph.vertices().size());
//(5) Add edge (A, E, 2) and (F, A, 2);
assertEquals(0, graph.set("A", "E", 2));
assertEquals("([A, B, C, D, E],[(A,B,2), (A,E,2), (B,C,1), (C,D,1)])",graph.toString());
assertEquals(5, graph.vertices().size());
assertEquals(0, graph.set("F", "A", 2));
assertEquals("([A, B, C, D, E, F],[(A,B,2), (A,E,2), (B,C,1), (C,D,1), (F,A,2)])",graph.toString());
assertEquals(6, graph.vertices().size());
//(6) Add edge (G, G, 0) and (G, G, 1).(The latter will be added)
assertEquals(0, graph.set("G", "G", 0));
assertEquals("([A, B, C, D, E, F],[(A,B,2), (A,E,2), (B,C,1), (C,D,1), (F,A,2)])",graph.toString());
assertEquals(6, graph.vertices().size());
assertEquals(0, graph.set("G", "G", 1));
assertEquals("([A, B, C, D, E, F, G],[(A,B,2), (A,E,2), (B,C,1), (C,D,1), (F,A,2), (G,G,1)])",graph.toString());
assertEquals(7, graph.vertices().size());
}
remove
思想与之前的实现一致:遍历点集,期间移除所有指向参数vertex的边,如过遇到vertex,直接将它从点集中移除。注意要用迭代器遍历,用下标访问删除的时候容易错位。下面是部分代码:
boolean flag = false;
Iterator<Vertex> vertexIterator = vertices.iterator();
while(vertexIterator.hasNext()) {
Vertex now = vertexIterator.next();
if(now.getLabel().equals(vertex)) {
vertexIterator.remove();
flag = true;
}
else now.set(vertex, 0);
}
return flag;
vertices
这个实现起来很简单,把所有点的标签放到Set中返回即可。
Set<String> ret = new HashSet<String>();
for(Vertex v: vertices)
ret.add(v.getLabel());
return ret;
sources , targets
实现起来也不难,对于targets,直接找到对应的点调用之前实现的targets方法即可;对于sources,遍历每个点v,调用其getWeightTo方法,当返回值>0时,将v加入Map中。下面是targets的实现:
Map<String, Integer> map = new HashMap<>();
for(int i = 0; i < vertices.size(); i++) {
Vertex v = vertices.get(i);
if(v.getLabel().equals(source)) {
map = v.targets();
break;
}
}
return map;
测试Edge和Vertex
这两个测试单元分别放在ConcreteEdgesGraphTest和ConcreteVerticesGraphTest中。由于Edge和Vertex在src的包中是默认权限,所以在test的包中我们无法访问。因为这两个类也不依赖其他类,我选择直接把Edge/Vertex的声明复制到测试文件里,这样就可以用了。
Problem 3
这一部分要求我们将前面实现的两种图泛型化。不需要做过多改动,只需要将作为图标签的String替换为<L>.Edge和Vertex也应该替换为泛型,如下图:
这部分还要求我们实现前面没完成的Graph中的empty()方法,它应该返回一个图的实例,这里随意选择一个实现类即可。
注:对Java的静态方法应用泛型时需要在返回值前面加上一个声明。(即下面static后面的<L>)
public static <L> Graph<L> empty() {
return new ConcreteEdgesGraph<L>();
}
Problem 4
这一部分要求完成GraphPoet类。简单解释一下题意:
GraphPoet有一个域,为Graph的一个实例(调用前面的empty静态方法得来);两个方法(可以自己声明辅助方法):构造方法和poem方法。
public GraphPoet(File corpus);//throws IOException
构造方法的参数是一个文件corpus(语料库),它应当按照以下规则建图:语料库中每出现一次 w 1 w 2 w_1\ w_2 w1 w2,就将 w 1 w_1 w1到 w 2 w_2 w2的有向边边权加 1 1 1(忽视大小写).如:
To be or not to be,this is a question.
在这个例子中,to be出现了两次,因此"to"到"be"的边权应该为2。此外按个人理解,"be"和"this"之间不应该有边,因为它们是两句话中的单词。其他边应该包括(“be”,“or”,1),(“a”,“question”,1)等,不一一列举了。
poem方法原型如下:
public String poem(String input);
给定一个String类型的input,返回一句“诗”。产生这句诗的规则如下:对于input中每句的每对相邻单词 s o u r c e t a r g e t source\ \ target source target,考察图中是否存在 s o u r c e → b r i d g e → t a r g e t source\rightarrow bridge \rightarrow target source→bridge→target这样一条包含2条边的路径。如果存在这样的路径,将边权和最大的(对应该词组在语料库中出现的次数多,也就更“地道”)路径的中间点 b r i d g e bridge bridge插入 s o u r c e source source和 t a r g e t target target的中间。举MIT实验指导书的例子,给定input为
Seek to explore new and exciting synergies!
根据语料库建好的图如下:
// 这是产生下面图的语料库
To explore strange new worlds
To seek out new life and new civilizations
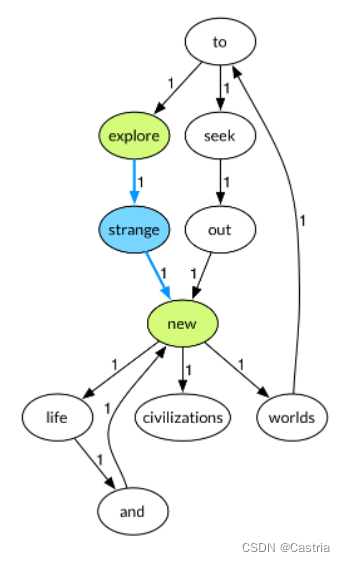
现在考察input中"explore"和"new"这两个词。显然图中存在
e
x
p
l
o
r
e
→
s
t
r
a
n
g
e
→
n
e
w
explore\rightarrow strange \rightarrow new
explore→strange→new这一条长为
2
2
2条边的路径(注意这里不考虑边权,只考虑边的条数),而且它是唯一一条。因此选择strange插入到explore和new中间。同理new和and之间应该插入一个life:
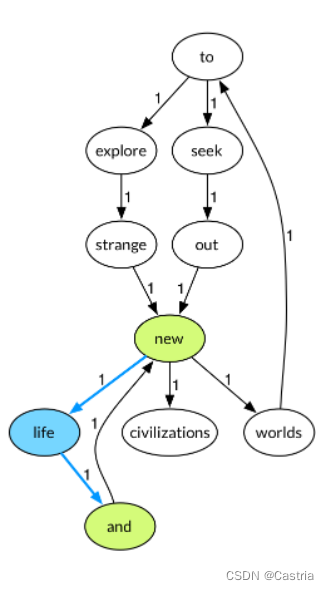
最终得到的输出应为
Seek to explore strange new life and exciting synergies!
输出的格式(包括大小写,标点,但插入的词应当始终为小写)应当保持原样。
测试单元
这里仅提供一组测试存在多条路径,取最大边权的数据。由于没有具体规定多条路径边权相等时的返回,这时随意返回一个连接词应该就可以。
//corpus.txt
four years
for four years
for six years
I have studied English for six years.
//GraphPoetTest.java
//...
assertEquals("I study in HIT for six years.",graphPoet.poem("I study in HIT for years."));
//...
建出来的图应当如下:
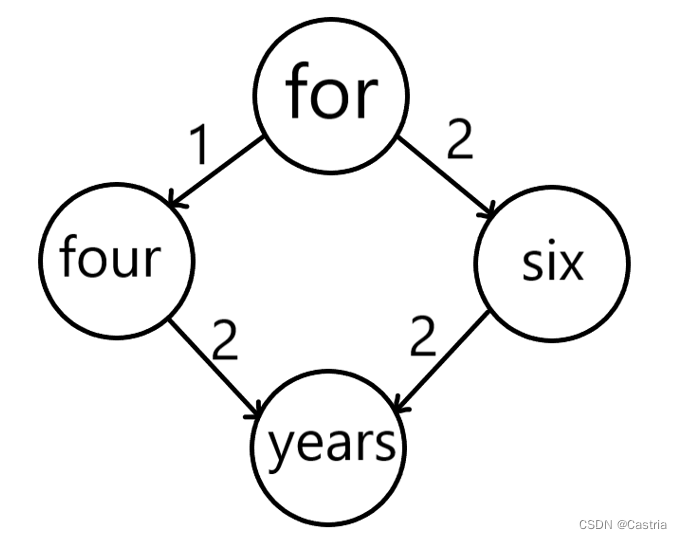
由于
f
o
r
→
s
i
x
→
y
e
a
r
s
for\rightarrow six \rightarrow years
for→six→years边权和为
4
4
4,更高,因此连接词应该选择
s
i
x
.
six.
six.
实现
表示不变量等部分没有什么变化,不重复说明了。
构造方法
由于Graph接口没有提供增加边权这一方法,我们需要增加一个辅助方法,获取两点之间的边权,用targets方法很容易实现:
private int getCountBetween(String source, String target) {
Map<String, Integer> map = graph.targets(source);
if(!map.containsKey(target)) return 0;
return map.get(target);
}
之后我们就可以实现构造方法了。核心代码如下:
while(scanner.hasNextLine()) {
/*
* Words in two sentences shouldn't be a word pair,split the file by marks firstly.
* For example, in sentence "To be or not to be,this is a question.",
* "be" and "this" shouldn't be a pair.
*/
String[] sentences = scanner.nextLine().split("\\.|\\?|,|;|:|!");
for(String sentence: sentences) {
String[] words = sentence.split(" ");
for(int i = 0; i < words.length - 1; i++) {
int count = getCountBetween(words[i], words[i + 1]);
graph.set(words[i].toLowerCase(), words[i + 1].toLowerCase(), count + 1);
}
}
}
当split的参数用"|"连接时,表示多种分隔符都将切分该字符串。这里的分隔符为常见的标点符号:句号、问号、逗号、分号、冒号和感叹号。由于’.‘和’?'在正则表达式中都有特殊含义,需要用双斜线转义。
poem方法
这里我的实现比较别扭,如果有更巧妙的实现方法欢迎提出。
首先按序保存所有的标点符号,这样我们在切分之可以将它们还原:
LinkedList<Character> marks = new LinkedList<>();
for(int i = 0; i < input.length(); i++) {
if(isMark(input.charAt(i)))
marks.add(input.charAt(i));
}
isMark是一个小的辅助方法,就是判断一个字符是否是前面提到的标点符号。之后我们还按照句子切分,然后考察句子中每个单词对,找出它们的(如果有的话)连接词。
String[] sentences = input.split("\\.|\\?|,|;|:|!");
for(String sentence: sentences) {
String[] words = sentence.split(" ");
//for each word pair
for(int i = 0; i < words.length - 1; i++) {
//get bridge word; returns null if there isn't such a word.
String bridge = getBridgeWord(words[i].toLowerCase(), words[i + 1].toLowerCase());
if(bridge != null) {
poem.append(words[i] + " " + bridge + " ");
}
else poem.append(words[i] + " ");
}
//append the last word
poem.append(words[words.length - 1]);
//append punctuation mark
if(!marks.isEmpty())
poem.append(marks.removeFirst());
}
这里poem是一个StringBuilder类,在动态构建字符串时效率更高,具体用法参见此处。
我们还差中间的一个辅助方法没有实现:getBridgeWord.这个方法应该返回source和target的连接词;如果没有,返回null。由于要尽可能复用Graph中的方法,我们采用targets()方法实现,部分代码如下:
Map<String, Integer> toBridge = graph.targets(former);
for(String bridge: toBridge.keySet()) {
//weight: the weight from former to this bridge
int weight = toBridge.get(bridge);
Map<String, Integer> toLatter = graph.targets(bridge);
if(toLatter.containsKey(latter)) {
//weight + (the weight from this bridge to latter) > maxWeight, then update maxWeight and the String
if(weight + toLatter.get(latter) > maxWeight) {
maxWeight = weight + toLatter.get(latter);
maximumBridge = bridge;
}
}
}
稍微解释一下:bridge是source到达target的所有可能的“跳板”,之后调用bridge的targets方法,若bridge能到达target,更新这个最大的边权值(以及返回的串)。至此,我们实现了GraphPoet类。
二、Re-implement the Social Network in Lab1
这个任务要求我们用Graph类重新实现Lab1的P3.
Person类
这个相较Lab1变化应当不太大。不过要注意Person类应该是不可变的(根据Graph的规约),如果之前实现为可变需要做适当修改。
FriendshipGraph类
由于有了Graph这个类,我们实现的压力小了很多。我一开始考虑用继承还是组合(即,将一个现有对象作为新对象的域)方式实现这个类。在《Java编程思想》(第4版)中有关于这一部分的论述(P137,7.5节,在组合与继承之间选择):
组合技术通常用于想在新类中使用现有类的功能而非它的接口这种情形。即,在新类中嵌入某个对象,让其实现所需要的功能,但新类的用户看到的只是为新类所定义的接口,而非所嵌入对象的接口。为取得此效果,需要在新类中嵌入一个现有类的private对象。
有了这段话的提示,结论就很明显了:FriendshipGraph类只需要我们实现三个方法,而不需要Graph中其他的public方法。因此我们选择组合方式实现。
final private ConcreteEdgesGraph<Person> graph = new ConcreteEdgesGraph<>();
接下来依次实现这三个方法:
addVertex
原型:
public void addVertex(Person person);
这一部分很简单,只需要调用Graph的方法即可。
public void addVertex(Person person) {
if(!graph.add(person)) {
System.out.println("There is already a person named " + person.getName() + "!");
}
}
addEdge
原型:
public void addEdge(Person source, Person target);
只需要调用set方法即可。注意要先判断一下图中是否包含这两个人。如:
Set<Person> personSet = graph.vertices();
if(!personSet.contains(source)) {
System.out.println("There is no person named " + source.getName() + "!");
return;
}
getDistance
这个实现本质还是一个广搜。但由于实验要求我们尽可能复用Graph的方法,需要稍微修改一下实现。我们初始化当前点集合为 { s o u r c e } , \{source\}, {source},当前步数为 0. 0. 0.每次循环让当前点集合中的所有点朝它们的后继点走一步(要求后继点没有访问过)。若当前点集合中包含target,当前的步数即为两点之间的距离。这个过程有点像NFA的匹配过程。伪代码如下:
getDistance(source, target):
if source == target
return 0
step ← 0
S ← {source}
while(S 非空)
tmpSet ← {}
for vertex in S
访问 vertex
for nextVertex in vertex.targets()
if(未访问过 nextVertex)
if(nextVertex == target)
return step + 1;
向 tmpSet 中加入 nextVertex
S ← tmpSet
step ← step + 1
具体实现没有伪代码清晰,就不放了。测试单元、main方法中的代码应当与Lab1中一致。至此,任务2的主体部分已经完成。
相关文章
- 2022年度软件质量保障行业调查报告
- 电子电气架构——是软件定义汽车关键
- 【华为OD机试真题 python】 获取最大软件版本号【2022 Q4 | 100分】
- 正是岳麓好风景,软件逢君正当时
- openwrt环境中某个运行在host端的软件如何安装到openwrt的$(STAGING_DIR_HOST)/bin下
- 《个体软件过程》—第1章1.1节什么是软件工程
- 哈工大2022软件构造Lab1
- 企业级软件协作,没有数据怎么人工智能?
- 软件设计师--其他高频考点总结
- 2022年--软件设计师下午题高频考点技巧总结
- 2022软件设计师----数据库系统考点总结
- 2022软件设计师-计算机网络高频考点总结
- 【正点原子FPGA连载】第五章Modelsim软件的安装和使用 -摘自【正点原子】新起点之FPGA开发指南_V2.1
- Qt项目为程序添加软件图标
- 关于HarmonyOs系统的一些软件分析报告
- 【最佳实践】filezilla软件用bat自动化ftp传输文件
- Modbus调试软件--ModbusPoll、ModbusSlave使用详解
- 南澳州政府拒绝更换DOS病历软件:称为患者安全着想
- 建筑CAD软件导出图纸时如何默认保留墙基线?
- 就业寒潮,三年Java——《我亲身经历的2022年软件质量工作》