
《Python数据科学指南》——2.4 使用scikit-learn进行机器学习
本节书摘来自异步社区《Python数据科学指南》一书中的第2章,第2.4节,作者[印度] Gopi Subramanian ,方延风 刘丹 译,更多章节内容可以访问云栖社区“异步社区”公众号查看。
2.4 使用scikit-learn进行机器学习scikit-learn是Python中的一个全能的机器学习库,我们在本书中会大量使用它。我们使用的版本为0.15.2。你可以在命令行里调用_version_属性来检查版本,如图2-17所示。

2.4.1 准备工作
本节里,我们会演示一些scikit-learn包的功能,学习它的一些API架构,为后续章节的学习打下基础。
2.4.2 操作方法scikit-learn提供了一个内置数据集,我们看看如何访问和使用它。
#Recipe_3a.py from sklearn.datasets import load_iris,load_boston,make_classification make_circles, make_moons # Iris数据集 data = load_iris() x = data[data] y = data[target] y_labels = data[target_names] x_labels = data[feature_names] print print x.shape print y.shape print x_labels print y_labels # Boston数据集 data = load_boston() x = data[data] y = data[target] x_labels = data[feature_names] print print x.shape print y.shape print x_labels # 制作一些分类数据集 x,y = make_classification(n_samples=50,n_features=5, n_classes=2) print print x.shape print y.shape print x[1,:] print y[1] # 一些非线性数据集 x,y = make_circles() import numpy as np import matplotlib.pyplot as plt plt.close(all) plt.figure(1) plt.scatter(x[:,0],x[:,1],c=y) x,y = make_moons() import numpy as np import matplotlib.pyplot as plt plt.figure(2) plt.scatter(x[:,0],x[:,1],c=y) plt.show()
我们来看看如何调用scikit-learn里的这些机器学习函数。
#Recipe_3b.py import numpy as np from sklearn.preprocessing import PolynomialFeatures # 数据预处理 x = np.asmatrix([[1,2],[2,4]]) poly = PolynomialFeatures(degree = 2) poly.fit(x) x_poly = poly.transform(x) print "Original x variable shape",x.shape print x print print "Transformed x variables",x_poly.shape print x_poly # 另一种写法 x_poly = poly.fit_transform(x) from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris data = load_iris() x = data[data] y = data[target] estimator = DecisionTreeClassifier() estimator.fit(x,y) predicted_y = estimator.predict(x) predicted_y_prob = estimator.predict_proba(x) predicted_y_lprob = estimator.predict_log_proba(x) from sklearn.pipeline import Pipeline poly = PolynomialFeatures(n=3) tree_estimator = DecisionTreeClassifier() steps = [(poly,poly),(tree,tree_estimator)] estimator = Pipeline(steps=steps) estimator.fit(x,y) predicted_y = estimator.predict(x)2.4.3 工作原理
为了使用内置的数据集,我们得先加载scikit-learn库,库的模块里包含着各种各样的函数。
from sklearn.datasets import load_iris,load_boston,make_classification
第1个数据集是iris,请参见以下地址来获取更多细节信息。
https://en.wikipedia.org/wiki/Iris_flower_data_set。
这是一个由Donald Fisher先生引入的分类问题的经典数据集。
data = load_iris() x = data[data] y = data[target] y_labels = data[target_names] x_labels = data[feature_names]
我们调用的load_iris函数返回一个字典。使用合适的键,可以从这个字典对象中查询获取到自变器x、因变量y、因变量名、各个特征属性名等信息。
我们将这些信息打印出来看看它们的值,结果如图2-18所示。
print print x.shape print y.shape print x_labels print y_labels

如你所见,预测器里有150个实例和4种属性,因变量有150个实例,每个预测集合里的记录都有一个类别标签。我们接着打印输出属性名:花瓣、花萼的宽度和长度,以及类别标签。在后续章节里,我们还会多次使用这个数据集。
我们接着要看的是另一个数据集:Boston住房数据集,它属于回归问题。
# Boston数据集 data = load_boston() x = data[data] y = data[target] x_labels = data[feature_names]
这个数据集的加载过程和iris基本一样,从字典的各个键也可以查询到数据的各个组成部分,包括预测器和因变量。我们打印输出这些变量来看一下,如图2-19所示。

如你所见,预测器集合里有506个实例和13种属性,因变量有506个条目。最后,我们也打印输出属性名。
scikit-learn也给我们提供了一些函数来产生随机分类的数据集,并可以指定一些需要的属性。
# 产生一些分类数据集 x,y = make_classification(n_samples=50,n_features=5, n_classes=2)
make_classification函数用来产生分类数据集。本例中,我们指定n_samples参数生成50个实例,n_features参数生成5个属性,n_classes参数生成两个类集合。请看这个函数的输出,如图2-20所示。
print x.shape print y.shape print x[1,:] print y[1]

如你所见,预测器里有150个实例和5种属性,因变量有150个实例,每个预测集合里的记录都有一个类别标签。
我们将预测器集合x里的第2条记录打印出来,你会看到这是一个五维的向量,与5个我们所需的特征相关联。最后,我们把因变量y也打印出来。预测器里的第2条记录的类别标签是1。
scikit-learn也给我们提供了一些函数来产生非线性关系。
# 一些非线性数据集 x,y = make_circles() import numpy as np import matplotlib.pyplot as plt plt.close(all) plt.figure(1) plt.scatter(x[:,0],x[:,1],c=y)
你应该已经从前面的章节中了解了pyplot,现在通过它绘制的图来帮助我们理解非线性关系。
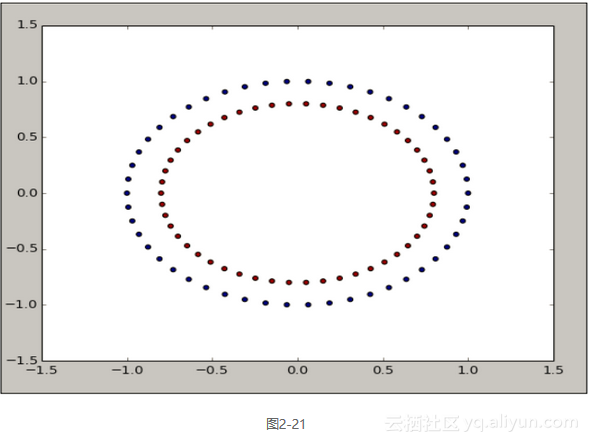
如图2-21所示,我们的分类结果产生了两个同心圆。x是两个变量的数据集,变量y是类标签。这两个同心圆说明了预测器里两个变量的关系是非线性的。
scikit-learn里还有一个有趣的函数make_moons也能产生非线性关系。
x,y = make_moons() import numpy as np import matplotlib.pyplot as plt plt.figure(2) plt.scatter(x[:,0],x[:,1],c=y)
我们看一下它生成的图2-22来理解非线性关系。
新月图形说明了预测器集合x里的属性之间的关系是非线性的。
接下来我们要来讨论scikit-learn的API架构,使用API架构的主要优势在于它十分简洁。所有源于BaseEstimator的数据模型必须严格实现fit和transform函数。我们将从一些示例中详细了解。
我们先从scikit-learn的预处理模块开始。
import numpy as np from sklearn.preprocessing import PolynomialFeatures
我们使用PolynomialFeatures类来演示使用scikit-learn的SDK的方便快捷之处。要了解PolynomialFeatures的更多信息,请参见:
https://en.wikipedia.org/wiki/Polynomial。
有时我们需要往预测器变量集合中增加新的变量,以判断模型精度是否提高。我们可以将已有特征的多项式作为新特证,PolynomialFeatures帮助我们实现这一目标。
# 数据预处理 x = np.asmatrix([[1,2],[2,4]])
首先,我们要创建一个数据集。本例中,数据集有两个实例和两个属性。
poly = PolynomialFeatures(degree = 2)
然后,我们将采用所需的多项式阶数来实例化PolynomialFeatures类。本例中,阶数为2。
poly.fit(x) x_poly = poly.transform(x)
接着要介绍的是fit和transform函数。fit函数用来在数据转换时做必需的计算。本例中它是多余的,不过在本节后面部分我们会遇到一些如何使用它的示例。
transform函数接收输入数据,并基于fit函数的计算结果将输入数据进行转换。
# 换一种方式 x_poly = poly.fit_transform(x)
本例还有另外一种方式,在一个操作中调用fit和transform。我们来看看变量x初始和转换之后的数值和形态,如图2-23所示。

scikit-learn中所有实现机器学习方法的类都来自BaseEstimator,请参见:http://scikit-learn.org/stable/modules/ generated/sklearn.base.BaseEstimator.html。
BaseEstimator要求用以实现的类提供fit和transform两种方法,这样才能保持API简洁清晰。
我们再看另一个示例,从tree模块中引入Decision TreeClassifier类,它实现了决策树算法。
from sklearn.tree import DecisionTreeClassifier
我们把这个类放到实践操作中。
from sklearn.datasets import load_iris data = load_iris() x = data[data] y = data[target] estimator = DecisionTreeClassifier() estimator.fit(x,y) predicted_y = estimator.predict(x) predicted_y_prob = estimator.predict_proba(x) predicted_y_lprob = estimator.predict_log_proba(x)
我们使用iris数据集来看来怎样使用树算法。先把iris数据集加载到变量x和y中,然后把DecisionTreeClassifier实例化,接着调用fit函数,传递预测器x和因变量y来建立模型。这样就建立了一个树模型,我们现在可以用它来进行预测。我们用predict函数对给定的输入预测其类标签。如你所见,和在PolynomialFeatures里一样,我们也使用了相同的fit和predict方法。还有另外两个方法:predict_proba和predict_log_proba。前者给出预测的概率,后者给出预测概率的对数。
现在来看另一个有趣的功能pipe lining,使用这个功能,不同的机器学习方法可以被链接在一起。
from sklearn.pipeline import Pipeline poly = PolynomialFeatures(3) tree_estimator = DecisionTreeClassifier()
我们从实例化PolynomialFeatures和DecisionTreeClassifier数据处理规范开始。
steps = [(poly,poly),(tree,tree_estimator)]
我们先定义一个元组列表来标示我们的链接顺序。运行多项式特征生成器之后,再执行决策树。
estimator = Pipeline(steps=steps) estimator.fit(x,y) predicted_y = estimator.predict(x)
我们通过steps变量声明的列表将Pipeline对象实例化。现在就能像以往那样调用fit和predict方法了。
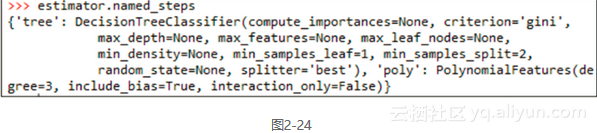
我们可以调用named_steps属性来查看模型在pipeline里的不用阶段的情况,如图2-24所示。
2.4.4 更多内容
scikit-learn里还有更多的数据集生成函数,请参见:
http://scikit-learn.org/stable/datasets/。
在使用make_circle和make_moons函数的时候,我们曾经提到可以给数据集加入许多想要的属性,如果包含了不正确的类标签,数据可能会受到轻微的损坏。下面的链接列出了许多描述这些细微差别的选项,请参见:
http://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_circles.html和
http://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_moons.html。
2.4.5 参考资料第2章“Python环境”中“绘图技巧”的相关内容。
本文仅用于学习和交流目的,不代表异步社区观点。非商业转载请注明作译者、出处,并保留本文的原始链接。
机器学习数学基础五:数据科学的一些基本分布 每一次尝试都是独立的,因为前一次投掷的结果不能决定或影响当前投掷的结果。只有两个可能的结果并且重复n次的实验叫做项式。二项分布的参数是n和p,其中n是试验的总数,p是每次试验成功的概率。
边玩边学!交互式可视化图解!快收藏这18个机器学习和数据科学网站!⛵ 机器学习算法理论比较枯燥乏味,但有许多有趣且有用的网站,您可以像游戏一样交互式操作,并同时学习机器学习概念、模型和应用知识。以下是 ShowMeAI 为大家整理的18个交互式机器学习网站,学起来!
五个给机器学习和数据科学入门者的学习建议 我从没写过代码。 当人们发现我的作品,他们通常会私信并提问。我不一定知道所有的答案,但我会尽量回复。人们最常问的问题是:「该从哪开始?」,其次是:「我需要多少数学基础?」
异步社区 异步社区(www.epubit.com)是人民邮电出版社旗下IT专业图书旗舰社区,也是国内领先的IT专业图书社区,致力于优质学习内容的出版和分享,实现了纸书电子书的同步上架,于2015年8月上线运营。公众号【异步图书】,每日赠送异步新书。
相关文章
- 软件——机器学习与Python,输入输出的用法
- 机器学习-kmeans(实现步骤、sklearn实现、python自实现、优缺点)
- 地球引擎初级教程——Python API 语法(内涵JavaScript转python工具包介绍)
- 2023版python安装教程奉上,Python永久使用 超详细版,一看就会【小白友好】
- Python 调用snmp自定义OID实现监控
- gyp ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.
- 《NLTK基础教程——用NLTK和Python库构建机器学习应用》——1.2 先从Python开始吧
- 《NLTK基础教程——用NLTK和Python库构建机器学习应用》——2.6 词形还原
- 《Python机器学习——预测分析核心算法》——1.6 各章内容及其依赖关系
- Python数据处理Tips机器学习英文数据集8种算法应用
- Python机器学习零基础理解PCA主成分分析
- Python机器学习零基础理解决策树分析
- Python教程大全之如何使用 Python 轻松构建您的第一个机器学习 Web 应用程序(教程含项目源码)
- Python 基础 之 python 进程知识点整理,实现一个简单使用进程池的多进程文件夹文件copy器
- python进行机器学习(三)之模型选择与构建
- Python用python-docx读写word文档
- 【python百度智能云】:Python — 三种获取__VIEWSTATE、__VIEWSTATEGENERATOR、__EVENTVALIDATION方法。
- 机器学习——人工神经网络之BP算法编程(python二分类数据集:马疝病数据集)
- python笔记(十八)机器量化分析—数据采集、预处理与建模