
《统计会犯错——如何避免数据分析中的统计陷阱》—第2章膨胀的真理
本节书摘来自异步社区《统计会犯错——如何避免数据分析中的统计陷阱》一书中的第2章膨胀的真理,作者【美】Alex Reinhart(亚历克斯·莱因哈特),更多章节内容可以访问云栖社区“异步社区”公众号查看。
膨胀的真理
假设相对于安慰剂,Fixitol能将症状减少20%。但你的试验样本可能太小,没有足够的统计功效可靠地检测到这种差异。我们知道,小试验常常产生更具有变异性的结果;你很可能恰恰找到10个幸运的患者,他们的感冒时间都较短,但找到10000个感冒时间都较短的患者的可能性基本上为0。
设想不停地重复以上试验。有时你的患者并不是那样幸运,因此你没有注意到你的药物具有明显的改善作用;有时你的患者恰好具有代表性,他们的症状减少了20%,但你没有足够的数据证明这种减少在统计上是显著的,因此你将其忽略;还有一些时候,你的患者非常幸运,他们的症状减少远超过20%,这时你停下试验说:“看,它是有效的!”你把所有的结果画在了图2-3中,显示了试验结果产生的概率。
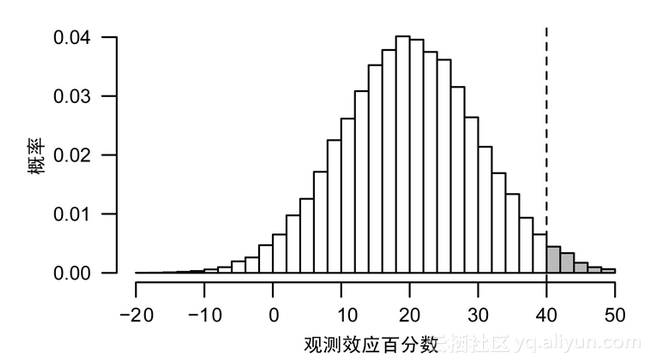
图2-3 试验结果产生的概率
(如果你重复进行试验,你将会看到试验结果的一个分布。垂直虚线是在统计上具有显著性的效应值。真正的效应值是20%,但你可以发现观测效应值分布在-10%~50%这样一个较宽区间里。只有少数幸运的试验结果是显著的,但是它们都夸大了效应的大小。)
你得到了正确的结论,即Fixitol是有效的。但因为试验是低功效的,所以你夸大了效果的大小。
以上现象被称为真理膨胀,或者M型错误、赢者灾难。这种现象经常发生,尤其在那些进行类似试验争相发表最激动人心结果的领域经常见到,例如药理学试验、流行病学研究、基因关联研究、心理学研究等。在那些引用最多的医学文献里以上现象也比较常见18,19。在快速发展的领域,比如基因研究,早期论文的结果常常比较极端,这是因为期刊很愿意发表这样新的、令人振奋的结果。相比较而言,后续研究的结果就不那么夸张了20。
就连《自然》和《科学》这样的顶级期刊,也喜欢发表具有开创性理论成果的研究论文。这些开创性成果一般意味着大的效应,往往是在鲜有人研究的、比较新奇的领域里产生的。这是慢性真理膨胀与顶级期刊的完美组合。已有证据表明,期刊影响因子和其发表的“激进”研究具有相关性。那些结论不怎么令人振奋的研究更接近于真理,但是大多数的期刊编辑却对其不感兴趣21,22。
当一项研究声称在小样本下,发现了一个大效应时,你的第一反应不应是:哇哦,他们发现了这么有趣的现象!而应是:他们的研究可能是低功效的23!来看一个例子。从2005年起,Satoshi Kanazawa发表了一系列关于性别比例的论文,最后一篇论文的题目是“漂亮父母会生更多的女儿”。他出版了一本书专门对此进行讨论,书中涉及其他一些他发现的“政治上不正确的真相”。这些研究在当时非常流行,尤其是因为Satoshi Kanazawa所得到的惊人结论:最漂亮父母生女儿的概率是52%,最不漂亮的父母生女儿的概率是44%。
对生物统计学家而言,一个微弱的效应——如一个或两个百分点,具有重要的含义。Trivers–Willard假设认为:如果父母有某些特点,更容易生出女孩,那么他们就会有更多的女孩,反之亦然。如果你认为漂亮的父母更容易生出女孩的话,那么平均而言,这些漂亮父母就会拥有更多的女儿。
但是Kanazawa得到的结论比较特殊,后来他也承认在分析中有些错误。基于他所收集的数据,修正之后的回归分析表明,漂亮父母拥有女儿的概率确实比平均水平高4.7%,但这只是一个点估计,这个差距的置信区间是(−3.9%, 13.3%),0在这个区间内部23。这说明,虽然Kanazawa采用了3000对父母的数据,但结果在统计上仍然是不显著的。
需要大量的数据才能可靠地识别出微小的差异。例如一个0.3%的差异,即使有3000对父母的数据,也不能将0.3%的观测差异与随机误差区分开来。在3000的样本容量下,只有5%的可能性得到在统计上显著的结果,而且这些显著性的结果已经将效应值(0.3%)夸大了至少20倍,并且约有40%的可能得到的显著性结论恰恰相反,即认为漂亮父母更有可能生男孩23。
因此,虽然Kanazawa进行了完美的统计分析,但他仍然高估了真实的效应。按照他的做法,他甚至还可以发表这样的论文:工程师会有更多的男孩,护士会有更多的女孩[3]。他的研究无法识别预想大小的效应。如果他在研究之前进行一个功效分析的话,可能就不会犯这种错误了。
微小的极端
因为小规模、低功效研究的结果变异性很大,所以产生了真理膨胀的问题。有时你非常幸运,得到一个在统计上显著却夸大其辞的估计结果。除了显著性检验分析,在其他分析中,较大的变异性也会带来麻烦。来看一个例子。假如你负责公立学校的改革,作为最优教学方法研究的一部分,你想分析学校规模大小对学生标准化测验分数的影响。小学校是否比大学校更好呢?应该建立为数众多的小学校还是建立若干所大学校?
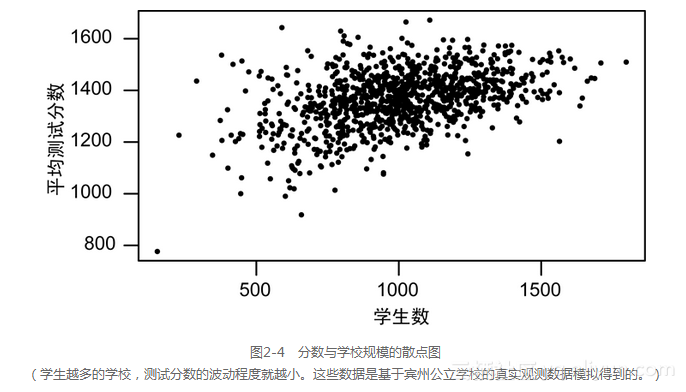
为了回答以上问题,你整理了表现良好的学校的一个列表。普通学校平均有1000名学生,你发现最好的10所学校学生的数目均少于1000。这似乎意味着,小学校做的最好,原因可能是因为学生少,老师可以深入了解每个学生并有针对性地帮助他们。
然后你又看了一下表现最差的学校,这些学校都是一些拥有成千上万学生、超负荷工作老师的大学校,与你的预想恰恰相反,这些最差的学校也是一些小学校。
为什么?现在,看一下测试分数与学校规模的散点图,如图2-4所示。小学校学生少,所以他们的测试得分有很大的变异性。学生越少,就越难估计出一个学校的真实平均水平,甚至少数几个异常的分数就会使一个学校的平均水平发生大的偏差。当学校的规模变大时,测试分数的波动变小,平均分数有上升趋势24。
来看另外一个例子:在美国,肾癌发生率最低的县往往位于中西部、南部和西部的农村地区。为什么这样?也许是因为农民干农活锻炼了身体,或者是因为他们一直呼吸免受污染的空气,还可能是因为他们生活压力很小。
但是,我们发现那些具有极高肾癌发生率的县也往往位于中西部、南部和西部的农村地区。
为什么这样?这是因为,农村地区的县人口特别少。如果一个县有10个居民,而其中有一位患有肾癌,那么该县的肾癌发生率就是最高的。由于人口特别少,这些县的肾癌发生率具有很大的波动性,其置信区间往往也会很宽25。
应对以上问题的常用方法是压缩估计。对于那些人口很少的县,你可以将他们的癌症发生率与全国水平做一个加权平均,从而使得过高或过低的癌症发生率向全国平均水平收缩。如果一个县的居民特别少,那么在加权平均时应该为全国水平赋一个较大的权重,而如果一个县的居民较多,那就为该县的癌症发生率设定较大的权重。在癌症发生率地图的绘制以及其他一些应用中,压缩估计是一种普遍的做法[4]。不过,压缩估计会不加选择地改变结果:如果一个县的人口较少,但是其癌症发生率确实很高,压缩估计往往会使得最后的估计结果接近全国水平,完全掩盖了这个县的真实情况。
处理以上问题并没有万全之策。最好的做法就是完全回避它:不按照县的划分来估计发生率,而是按照国会选区进行计算,这是因为在美国每个国会选区的人口都大致相当,而且远远多于一个普通县域的人口。不过,国会选区在地图上的形状往往奇形怪状,不如县域那么规则,所以基于国会选区得到的癌症发生率地图,虽然估计比较准确,但却难以解释。
而且,让各个单元都有相同样本大小的做法并不总是奏效。例如,在线购物网站在对商品进行排序时,其依据是顾客的评分,但此时并不能保证参与各种商品评分的顾客数目都是一样的。又如,在像reddit这样的论坛网站上,一般会按照网友的评价对帖子进行排序,但是有的帖子有很多人评价,而有的帖子评论人寥寥可数,这与帖子发布的时间、地点和楼主有很大的关系。压缩估计就可以应对以上情况。购物网站可以将每个产品的评分与总体水平进行加权平均。这样,鲜有人评分的产品默认是平均水平,而有大量顾客评分的产品可以按照它们各自的平均评分进行 排序。
另外,reddit网站上的帖子并没有评分机制,跟帖的人只能表示赞成或反对。为了对帖子进行排序,一般会求得这个帖子支持率的置信区间。当帖子的跟帖很少时,置信区间会很宽,随着跟帖的人越来越多,置信区间就会越来越窄,最后集中到一个确定的值(例如,70%的跟帖喜欢这个帖子)。新帖子的排名往往垫底,但随着跟帖人越来越多,其中质量较高的帖子置信区间变得越来越窄,不久就会上升到前面。并且,由于帖子是依据支持率而不是跟帖数目进行排序的,所以新帖子也完全可以和具有大量跟帖的帖子竞争26,27。
注意事项
在设计试验时,先计算统计功效,以此来决定所需样本的大小。不要跳过这一步。如果你对统计功效不甚了解,可以阅读Cohen’s的经典教材《行为科学的统计功效分析》或者向统计专家进行咨询。如果试验样本大小不切实际,最后结论的可靠性就会大打折扣。
如果你想精确地度量某种效应,请不要单纯地进行显著性检验,更好的做法是设计满足置信度的试验,这样就能以理想的精度度量某种效应。
请铭记“统计上不显著”并非意味着“0”。即使你的结果是不显著的,该结果也代表基于你所收集的数据所得到的估计。“不显著”与“不存在”并不等价。
持质疑态度看待那些低功效研究的结论,这些结论可能夸大真实情况。
请使用置信区间作为最后的答案,不要过分关注统计上的显著性。
当比较规模不同的组时,请计算置信区间。置信区间可以反映估计的精确程度:规模较大的组置信区间较窄,估计更精确。
[1] 如果两个试验组之间具有0.5个标准差大小的差异,Cohen就把这种差异称为中等大小的效应。
[2] 需要注意的是,由于红灯右转带来的交通事故所造成的人员伤亡总数是很少的。红灯右转带来了更多的交通事故,但是从整个美国来看,增加的伤亡人数不超过100人15。尽管如此,因为统计上的错误,红灯右转这项政策每年仍会使数十人丧生。
[3] Kanazawa在2005年的《Journal of Theoretical Biology》上确实发表了这篇文章。
[4] 当然,“压缩估计”不等于简单地加权平均,在统计分析中,有更为复杂的压缩估计方法。
本文仅用于学习和交流目的,不代表异步社区观点。非商业转载请注明作译者、出处,并保留本文的原始链接。
【python数据分析】数据的分组,遍历,统计 数据的分组,遍历,统计 俗话说:“人与类聚,物以群分”,到这里我们将学习数据的分组以及分组后统计。Pandas的分组相对于Excel会更加简单和灵活。
Python数据分析 | 统计与科学计算工具库Numpy介绍 n维数组是NumPy的核心概念,大部分数据的操作都是基于n维数组完成的。本系列内容覆盖到1维数组操作、2维数组操作、3维数组操作方法,本篇为系列导入文章,讲解数组的特点、与列表的对比等。
用python统计数据分析PAT甲乙级算法的考试和训练策略,附加横向设计图 python是做统计数据的好工具,在学习程序设计时,我们发现算法是一个难点,我们从’简单模拟’, ‘查找元素’, ‘图形输出’, ‘进制转换’, ‘字符串处理’,‘排序’,‘散列’,‘贪心’,‘二分’,‘two pointers’,‘其他’,‘数学’,‘链表’,几个角度分析算法的考试和训练策略,下一篇文章,分析数据结构的算法的考试和训练策略,如果你正在准备PAT甲乙级算法的考试和训练,会大有帮助,祝早日金榜题名。
异步社区 异步社区(www.epubit.com)是人民邮电出版社旗下IT专业图书旗舰社区,也是国内领先的IT专业图书社区,致力于优质学习内容的出版和分享,实现了纸书电子书的同步上架,于2015年8月上线运营。公众号【异步图书】,每日赠送异步新书。
相关文章
- Java实现蓝桥杯日志统计
- LeetCode-1814. 统计一个数组中好对子的数目【哈希表】
- Python英文词频统计(哈姆雷特)程序示例
- L1-003 个位数统计 (15 分)—团体程序设计天梯赛
- ZZNUOJ_用C语言编写程序实现1180:成绩统计(结构体专题)(附完整源码)
- 100天精通Python(数据分析篇)——第51天:numpy模块常用函数大全(字符串/数学/算术/统计/排序/搜索函数)
- 4-11流量统计项目需求分析
- 【阶段二】Python数据分析数据可视化工具使用05篇:统计直方图、面积图与箱型图
- Python数据分析之路(一)查询和统计
- Lesson6——Pandas Pandas描述性统计
- 华为交换机检查主机丢包流量统计配置