
基于Java+MySQL 实现(Web)动态人脸识别的认证识别系统【100010315】
摘 要
在人脸识别领域,主要涉及到两项技术,一项为人脸检测技术,另一项为人脸识别技术。其中,人脸检测技术主要解决存不存在人脸的问题,而人脸识别技术主要解决此人是谁的问题。除此以外,还有人脸对齐、人脸关键点定位等重要技术。
随着社会的高速发展、技术的革新突破以及安全意识的提高,作为生物特征识别技术之一的人脸识别技术,因其具有人脸易采集、多特征、非接触等优点而备受重视,成为国际的重点课题,时下热门的研究点。
本系统的设计基于Dlib 19.10库和Opencv 340库,选取B/S模式,采用Myeclipse 2016为主要开发工具。
本文主要介绍用Javaweb实现的基于动态人脸识别的身份认证系统的核心算法和重要功能模块,其中,核心算法包括Viola&Jones检测算法和PHash感知哈希算法,重要功能模块包括人脸检测、动态校验、人脸对齐和匹配识别。
Viola&Jones检测算法用于人脸检测,它基于改进的Adaboost算法,具有极快的检测速率和不错的检测率。本文就Haar特征、积分图和Adaboost算法等作了详细介绍,以及分析它的检测结果。
动态校验即张嘴和眨眼的判断以及人脸对齐的实现借助于Dlib库的人脸关键点定位模块,本文就这两个功能的实现原理做了简要介绍。
PHash算法用于人脸识别,利用图像的整体架构计算两张图片的相似度,它运算简单,效率极高,对图像大小不敏感。本文将详细介绍该算法流程,并做测试和分析。
最后,本文介绍了前后端技术,并对系统的运行情况以贴图形式进行描述和展示。
关键字:人脸检测,人脸识别,人脸关键点,Viola&Jones,感知哈希算法
1.绪论
1.1背景现状
人脸识别技术,主要包含两项技术,一项是人脸检测技术,它借助图像处理和计算机视觉相关算法,判断图像或视频是否存在人脸;另一项是人脸识别技术,解决人脸是谁的问题,即通过脸与脸的匹配确定该人的真实身份。
在人脸识别技术以惊人的速度推陈出新日臻完善和动态人脸校验技术不断革新换代的今天,人脸识别领域的前景十分广阔。目前人脸识别技术主要应用于两个领域:一个是金融领域,一个是安保领域。在金融行业中,既有传统银行的自助开卡服务,也有互联网方向的支付宝刷脸支付服务和腾讯微众银行的刷脸开户等;在安保行业,有写字楼和高铁站等的刷脸通行,也有安防领域的安全监控等。人脸识别技术并非完美无瑕,但安全性在不断提高。未来的刷脸识别技术将更为完善,更加火热。
人脸识别发展至今,其识别方式依然分为配合式识别和非配合式识别。所谓配合式识别,就是通过文字或者声音来提示用户做出相应的动作,以方便系统采集数据,比如信用卡自助激活服务,需要提醒用户眨眼校验等。所谓非配合式识别,就是不需要用户配合做出指定性动作,系统随机采集图片,进行分析比对,适合应用于抓捕犯罪嫌疑人场景。非配合式识别的效果会差一些,但是识别的时效性更高。
因人脸识别具有人脸易采集、多特征、非接触等优越性,国内外均开展了有关人脸识别的研究。在国外,领跑人脸识别技术的国家以美国、欧洲部分国家和日本等发达国家为主。美国率先开创了人脸识别。位于美国的享誉世界的麻省理工学院媒体实验室等著名研究机构致力于人脸识别的研究,其研究水平处于国际领先地位。在国内,人脸识别技术的研究虽然兴起不久,但发展也十分迅猛。当前,我国人脸识别领域主要有三股力量。被誉为中国人脸识别之父的苏光大教授,是其中一股力量。第二股力量是中科院的李教授,专攻人脸识别。每年学术界人脸识别比赛最高记录保持者汤晓鸥教授团队,是人脸识别领域中第三股力量。
未来人脸识别技术的发展,在能够快速准确截取人脸区域的基础上,还要实现角度矫正、补偿修正、滤掉干扰等效果,这要求:(1) 多特征融合、多分类器融合以及脸面局部整体结合,力求覆盖所有人脸模式分布;(2) 融合人脸识别、语音识别、指纹识别、虹膜识别等各项技术以提高校验的可信度;(3)完善并突破三维人脸识别算法。
1.2 研究意义
不管在理论上还是在实践中,人脸识别技术,尤其是动态人脸识别技术的研究都有着重大意义。
从学科领域层面上看,人脸识别技术涵盖了心理学科、数字图像处理学科、模式识别学科、生理学科、计算机视觉学科以及人工智能学科等许多方面的知识内容,是推动各个学科领域和社会快速发展的不可忽视的动力。
从实际生活应用层面看,人脸识别技术在单位考勤、信用卡自助激活、海关边检、高铁验票、智能门禁等领域,也起着举重若轻的作用。
从提高人脸识别准确率层面看,人脸五官分布大同小异,不同人脸区分度并不是很大,而外在条件比如光线的明暗、人脸的表情甚至是发型、妆容,会使得同一个人区分度变大,以上“一同一异”给人脸的正确识别带来不少干扰。因此,实时地、正确地识别大量人脸并且做出动态校验是目前研究人员急需解决的难题。从这方面看,深入研究人脸识别,意义颇大。
本课题对基于动态人脸识别的身份认证系统进行开发实现,在人脸识别方面有利于避免作弊行为的发生。本次设计,有助于我探索人脸识别领域,了解深度学习,锻炼并提升自我。
1.3人脸识别领域算法总概括
人脸识别领域涌现出的算法众多,总体水平处于不断进步之中。大体上,可以将人脸识别算法归为五类。
一、基于知识规则的方法。此类方法主要利用一些简单人脸规则来描述人脸面部特征(如:眼睛、鼻子、嘴巴等的分布)以及这些特征之间的关系。典型的算法有基于马赛克图人脸检测算法,镶嵌图算法等。
二、基于特征的方法。此类方法主要通过寻找在不同的姿态、视角下都不会发生改变的面部特征(如肤色、纹理等)来对待测图像进行检测。像基于轮廓检测[9]是比较经典的算法,当然还有基于肤色检测[10]等算法。
三、基于模板匹配的方法。此类方法用标准人脸模板来描述人脸面部特征。进行人脸检测时,将设定好的阈值与系统计算出来的待测图像与标准人脸模板之间的相关值进行比较,以此确定待测图像是否存在人脸。
四、基于统计模型的方法。此方法视人脸区域为一类模式,依托海量人脸数据作为样本训练出来的分类器,对待测图像进行人脸检测。典型的算法有Viola&Jones人脸检测算法、基于SVM的人脸检测、cnn人脸检测算法等。
五、基于三维模型的方法。此法以通用模型顶点为参考,在图像测出相应的特征点反过来对该模型进行调整,完成上述步骤后,就可以通过纹理映射3D人脸模型。
1.4本章小结
本章主要对人脸识别的研究背景和现状进行阐述和分析,方便读者了解人脸识别的概念及国内外发展情况,并讲解人脸识别的研究意义,包括但不限于人脸识别研究对其他学科领域的带动作用以及其在日常生活方面给我们带来的影响,最后概述了人脸检测相关算法的分类以及论文结构的安排。
2.图像处理与人脸检测
2.1图像处理
图像处理,指的是利用计算机对图像进行分析以达到所需结果的技术,该技术包括但不限于图片压缩、复原、增强等方法[13]。本系统的人脸检测模块,采用了图像缩放、图像灰度化和直方图均衡化。其中,图像缩放用于归一化图像大小,提高人脸检测速率;图像灰度化用于去除部分杂物干扰同时降低运算量,提高人脸检测准确率和检测速率;直方图均衡化用于智能调节图像的明暗程度,提高人脸图像可用率。
2.1.1图像缩放
图像缩放,顾名思义,就是对数字图像进行收缩和放大,以达到某种特定需求。常见的缩放方法有以下两种:
1、最近邻插值
最近邻插值就是令变换后像素的灰度值等于距离它最近的输入像素的灰度值。
设源图宽和高分别为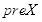
,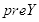
,缩放后图像宽和高为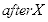
,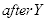
,则缩放后的图的每个像素坐标
的像素值等于坐标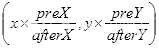
在x和y方向四舍五入后坐标对应的像素值。
假设有一幅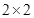
大小的图,其像素矩阵如下:
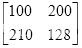
则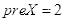
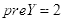
。
坐标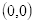
的像素为100,坐标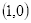
的像素为200,
坐标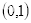
的像素为210,坐标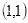
的像素为128。
现将其放大为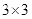
,即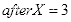
,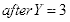
,且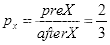
,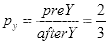
,则:
坐标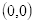
的像素值等于坐标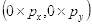
四舍五入后为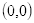
的像素值100,
坐标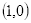
的像素值等于坐标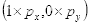
四舍五入后为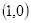
的像素值200,
坐标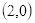
的像素值等于坐标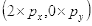
四舍五入为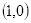
的像素值200,
坐标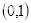
的像素值等于坐标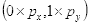
四舍五入为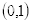
的像素值210,
坐标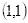
的像素值等于坐标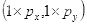
四舍五入为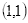
的像素值128,
坐标
的像素值等于坐标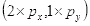
四舍五入为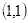
的像素值128,
坐标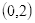
的像素值等于坐标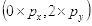
四舍五入为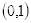
的像素值210,
坐标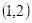
的像素值等于坐标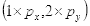
四舍五入为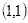
的像素值128,
坐标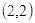
的像素值等于坐标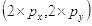
四舍五入为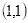
的像素值128。
缩放后图像的像素矩阵为:
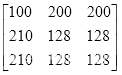

图2.1 最近邻插值缩放图
图2.1是最近邻插值缩放图的示例,实现缩放的代码为:
Mat image=Imgcodecs.imread(“E:/FaceOfUser/linzelong.jpg”);
Mat suoImage = new Mat();
Mat kuoImage = new Mat();
Imgproc.resize(image, suoImage, new Size(image.cols()/4,image.rows()/4), 0, 0, Imgproc.INTER_NEAREST);
Imgproc.resize(image, kuoImage, new Size(image.cols()*2,image.rows()*2), 0, 0, Imgproc.INTER_NEAREST);
2、双线性插值
双线性插值,是有两个变量的插值函数的线性插值扩展,即在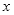
和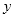
方向分别进行一次线性插值。
先讨论单线性插值。
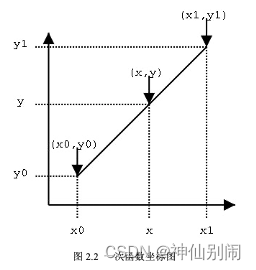
如图2.2,若已知坐标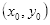
与 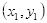
,欲得到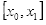
区间内某一位置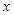
在直线上的值。根据初中所学知识,易得:
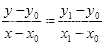
(2.1)
式(2.1)变换格式为:

(2.2)
再讨论双线性插值。如图2.3,已知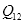
,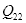
,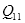
,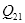
,设要插值的点为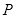
点。在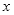
轴方向上,对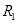
和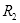
两个点进行插值,类比式(2.2),可得:

(2.3)
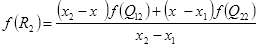
(2.4)
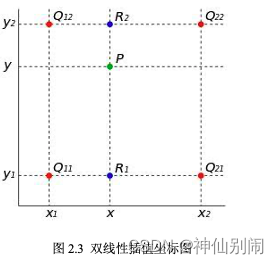
图2.3 双线性插值坐标图
在y轴方向上,对P点进行插值,可得:

(2.5)

图2.4 双线性插值缩放图
图2.4 是双线性插值缩放图的示例,实现缩放的代码为:
Mat image=Imgcodecs.imread("E:/FaceOfUser/linzelong.jpg");
Mat suoImage = new Mat();
Mat kuoImage = new Mat();
Imgproc.resize(image, suoImage, new Size(image.cols()/4,image.rows()/4), 0, 0, Imgproc.INTER\_LINEAR);
Imgproc.resize(image, kuoImage, new Size(image.cols()\*2,image.rows()\*2), 0, 0, Imgproc.INTER\_LINEAR);
总结:(1)最近邻插值算法,是最简单的缩放算法同时效果也是最差的,主要因为其对缩放后坐标的处理过于粗糙;而双线性插值算法充分利用了源图中虚拟点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,因此缩放效果优于最近邻插值。(2)本系统采用的是双线性插值法。
2.1.2图像灰度化
在彩图中,每个像素的颜色由值为0-255的R、G、B三个分量确定,其可能的颜色高达1600多万种。当R=G=B时,称该特殊彩色图为灰度图,称该变化过程为灰度化。图像进行灰度化,不仅使得计算量变少,而且仍能反映图像的整体和局部的基本特征。
通常,对图像进行灰度化采用如下方法:
灰度化后的R =处理前的R * 0.3+处理前的G * 0.59 +处理前的B * 0.11;
灰度化后的G =处理前的R * 0.3+处理前的G * 0.59 +处理前的B * 0.11;
灰度化后的B =处理前的R * 0.3+处理前的G * 0.59 +处理前的B * 0.11。
图2.5 是图像灰度化的示例,实现图像灰度化的代码为:
Mat image=Imgcodecs.imread("E:/FaceOfUser/linzelong.jpg");
Mat grayImage = new Mat();
Imgproc.cvtColor(image, grayImage, Imgproc.COLOR\_RGB2GRAY);
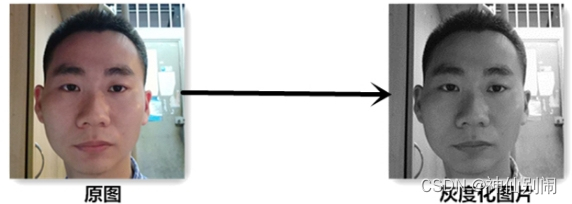
图2.5 图像灰度化
2.1.3直方图均衡化
直方图均衡化处理是把原始图像的灰度直方图从比较集中的某个灰度区间变成在全部灰度范围内的均匀分布,是对图像进行非线性拉伸[13]。
直方图均衡化的过程如图2.6所示,其基本思想是通过某种映射关系, 使图像灰度的概率密度均匀分布,与此同时,扩展了图像灰度的动态范围和增强了对比度。
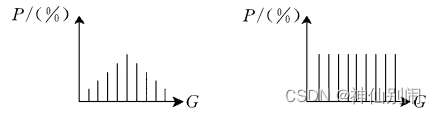
图2.6 直方图均衡化
用变量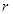
代表灰度级,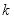
表示每一种灰度级的个数,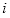
表示从小到大排列的不同种类灰度级的位置,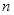
表示所有灰度级的个数。用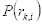
表示概率密度函数:
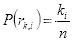
(2.6)
用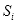
表示累积概率:
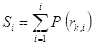
(2.7)
则经过直方图均衡化后,原灰度级变为:
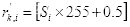
(2.8)
即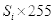
四舍五入后的值。
图2.7 是图像灰度化的示例,实现图像灰度化的代码为:
Mat afterImage = new Mat();
List<Mat> mv = new ArrayList<Mat>();
Core.split(grayImage, mv);
for (int i = 0; i < grayImage.channels(); i++){
` `Imgproc.equalizeHist(mv.get(i), mv.get(i));
}
Core.merge(mv, afterImage);

图2.7 直方图均衡化
2.2 Viola-Jones人脸检测算法
Viola-Jones是基于改进的Adaboost算法,其将Haar特征、Cascade算法和Adaboost算法相结合。
本系统选择Viola-Jones人脸检测算法,是因为其检测既快速又精准。主要思路为:(1)求待测图像积分图及Haar特征值,提取人脸的灰度分布特征;(2)训练弱分类器使之成为最优弱分类器,多个最优弱分类器组合形成强分类器;(3)级联强分类器,提高检测速度和准确率。
2.2.1 Haar特征
人脸分布着诸多对比鲜明的特征,比如鼻翼暗于鼻梁、人眼暗于脸面、嘴唇暗于四周等等,这些特征有利于我们捕捉人脸的信息。Haar特征(也称矩形特征),其对人脸边缘、线性等特征较为敏感,可用于上述特征即人脸区域灰度分布情况的描述[3]。
Haar特征模板通常分为三类,如表2.1所示。设白色矩形像素和为
,暗色矩形像素和为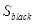
,则Haar特征的值为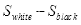
。
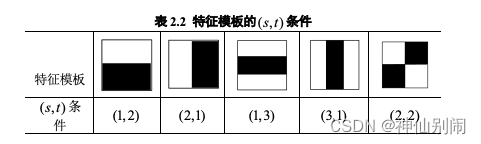
表2.1 Haar特征模板
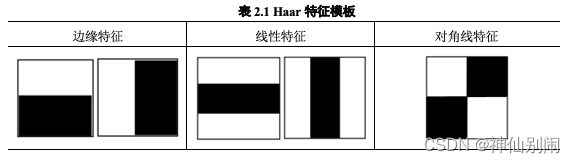
每个任意伸缩摆放在训练图像子窗口的模板特征,皆视为一种特征。因子窗口自身有尺寸大小的限制,故其包含的特征数是固定的,且对构成特征模板的长和宽有一定的条件限制。如图2.8所示,位于左上方的点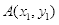
和位于右下方的点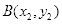
确定一个方框,称之为条件矩形。
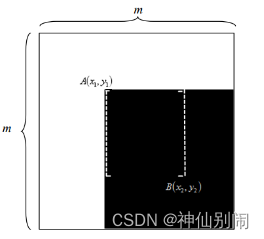
图2.8 
子窗口中条件矩形示意图
在
子窗口中,形成特征模板矩形的限制条件为:(1)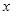
方向的长度能被整数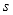
整除;(2)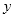
方向的宽度能被整数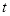
整除。由限制条件可知条件矩形最小尺寸为
,最大尺寸为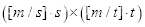
,式中方括号表示向下取整。
我们称该限制条件为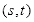
条件。于是,在确定点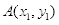
后,根据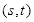
条件可以确定点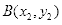
,得到条件矩形,步骤如下:
(1)确定左上方顶点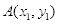
,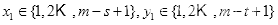
;
(2)确定点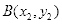
,由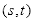
条件得:
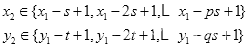
其中,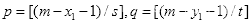
。
(3)求出满足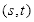
条件的矩形数量:
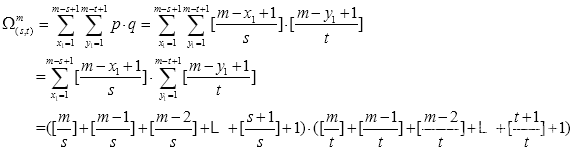
五种特征模板的限制条件如表2.2所示,其矩形(即特征)总数量为:
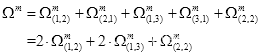

如表2.3所示,在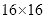
大小的子窗口中,特征模板的特征总数目高达三万之多,且该数目随子窗口尺寸增大而增大。数据量大会导致特征值计算速率明显降低。为此,Viola等人提出一种创新方法——积分图。
积分图与原图大小相同,图上各位置的取值等于原图左上方全部像素取值之和,即如图2.9所示的黑色方框所有像素之和。每个取值都以数组元素的形式存于内存中,当我们需要获取某区域的像素和时,无需重新计算该像素和,直接索引数组的元素即可,这极大地提高了运算速度。
在图2.9中,黑色方框所有像素之和即为点
处的积分值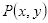
:
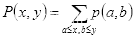
其中,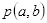
表示在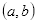
的像素值。
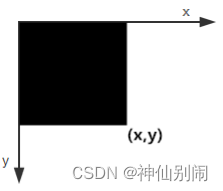
图2.9 积分图定义
有了积分图,欲求任一方框内的像素和,只需进行简单的加减运算,而无需重新计算像素累计值。如图2.10(a)所示,区域4像素值和:
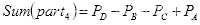
图2.10(b)所示的模板即表2.2中的模板(1,2)的特征值:

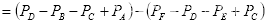
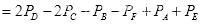
由上述实例的结果可知,特征值与图像坐标值无关,只与积分图的端点有关。任意位置和大小的模板的特征值只需经过简单的加减运算,极大降低复杂度,提高效率。
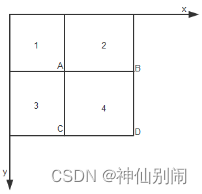
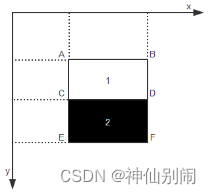
(a)区域D像素值计算示例 (b) 模板特征值计算示例
图2.10 积分图计算示例
2.2.2 Adaboost算法
Adaboost全称为Adaptive Boosting,是由Freund和Schapire在PAC模型基础上提出的一种自适应增强学习模型[2]。其基本思想为:(1)增大在前一个基本分类器(也称弱分类器)被错误分类的样本的权值,而减小被正确分类的样本的权值,用于下一个弱分类器的训练;(2)每一轮迭代中,增加一个新的弱分类器,直到达到预定的最大迭代次数或小于预期的错误率才确定最终的强分类器。
- 算法流程
设给定训练数据集为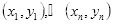
,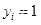
代表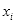
为正样本即人脸样本,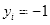
代表负样本即非人脸样本,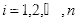
。
- 初始化训练数据的权值分布
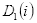
,设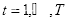
,第一次即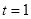
赋予相同权值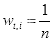
,则
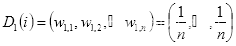
(2.16)
- 按
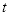
进行迭代:
(a)取当前最低错误率的弱分类器h作为第t个弱分类器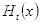
,其错误率(即被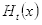
错误分类的样本的权值之和):
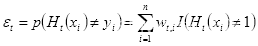
(2.17)
(b)第t个弱分类器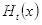
在最终分类器所占权重:
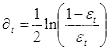
(2.18)
(c)更新样本的权重分布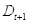
,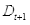
分为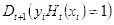
即被正确分类的样本的权值和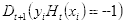
即被错误分类的样本的权值:
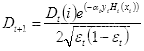
(2.19)
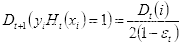
(2.20)
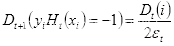
(2.21)
(d)将各个弱分类器按权重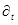
组合,形成分类函数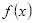
:
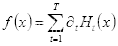
(2.22)
- 当错误率降低到我们预期的范围或者迭代次数达到我们预设的最大次数后,停止迭代,通过符号函数

的作用,构建一个强分类器:
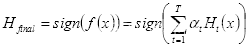
(2.23)
2、级联分类器
弱分类器根据从所有特征中找出的某个合适的阈值,区分开正负样本,其分类正确率只要求高于0.5。由上述算法流程可知,在训练过程中,错误分类样本的权值会被增大,正确分类样本的权值会被减少,因此在新一轮迭代就能加大对错误样本的训练。同时,错误率越低的弱分类器的权重会越高,错误率越高的弱分类器的权重会越低,权重越高,在强分类器起到的作用越大。当迭代次数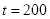
时,强分类器的错误率可以小于0.018[6]。也就是说,高准确率的强分类器可以由足够多的不同权重的弱分类器组成。
强分类器在保证高精准率的同时必须付出提高阈值的代价,进而降低了检测通过率。此外,高精准率也意味着需要大量的弱分类器,计算量的增加减慢了检测速率。因此,我们一般不单独采用一个包含众多弱分类器的强分类器,而是采用级联分类器。
级联分类器的设计,旨在解决精准率与检测通过率、精准率与检测速率之间的矛盾,它由多个强分类器构成,如图2.11所示。每个强分类的检测性能不同,越靠前的强分类器由越少弱分类器组成,主要用于去除非人脸图像,解决检测速度慢的问题;越往后的强分类器由更多的弱分类器构成,主要是为了平衡阈值设置和检测率高低,尽可能地提高检测率。检测过程中,从低尺寸子窗口开始,每轮检测完毕后,适当增大子窗口尺寸,继续检测。在任意层次的强分类中,若某个特定大小的子窗口被判定不包含人脸,则该尺寸大小的窗口的检测提前终止。经过各个强分类器的层层筛选,通过最后一个强分类器的检测才能最终判定为人脸区域。
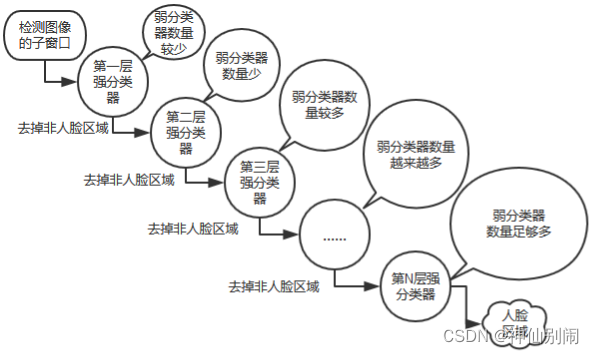
图2.11 级联分类器结构图
构建级联分类器的步骤:
- 最开始设置级联分类器的层数

,误检率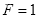
,最终误检率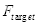
;
(2)根据自身需要预设每层强分类器最大误检率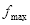
,最小检测率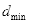
;
(3)在样本训练中求出强分类器的误检率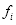
和检测率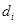
,找出满足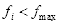
和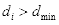
的强分类器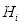
,将其作为级联分类器的第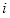
层,并更新
,
;
(4)若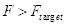
,继续步骤(3),此时训练样本为上一强分类筛掉非人脸样本后剩下的(疑似)人脸样本;若误检率
,则训练完毕,退出循环。
2.2.3 训练Haar分类器
1、采集样本
在neg文件夹放入负样本,即不包含人脸区域的灰度图,如图2.12,在pos文件夹放入正样本,即包含人脸区域的灰度图,如图2.13。在本系统中,正样本4000张,负样本10000张,图片大小为20x20,正负样本所在的neg文件夹和pos文件夹存放于F:/face目录下。
图2.12 负样本
图2.13 正样本
- 添加需要的文件
把opencv_createsamples.exe和opencv_traincascade.exe从opencv安装目录复制一份放在F:/face目录下,并在F:/face目录下建立空的xml文件夹,如图2.14所示,其中,opencv_traincascade.exe封装了haar特征提取以及adaboost分类器训练过程,opencv_createsamples.exe用于创建后缀名为.vec的正样本描述文件,xml文件夹用于存放训练好的分类器。
图2.14 文件存放位置,
- 建立正负样本描述文件
启动Windows命令行窗口,进入pos目录,输入如图2.15所示的指令后,在当前pos目录下生成一个pos.txt,里边记录所有图片的名称。打开pos.txt,删除最后一行,再将所有jpg替换成jpg 1 0 0 20 20,如图2.16,其中,1表示当前图片只出现一次,0 0 20 20表示目标图片大小是矩形框从(0,0)到(20,20)。接下来进入neg文件夹,生成neg.txt,步骤与生成pos.txt步骤类似,但生成的neg.txt文件不用做其他修改。

图2.15 生成正样本描述文件指令
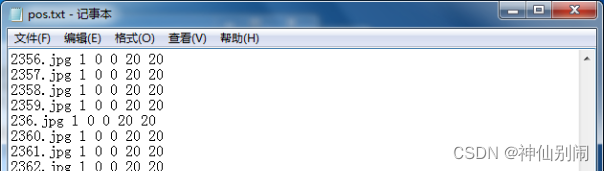
图2.16 文件pos.txt内容,
4、使用opencv_createsamples.exe生成正样本参数文件
在命令窗退回到face目录,输入如图2.17的指令后,生成如图2.18所示的pos.vec。其中,-vec pos.vec为指定生成的文件,最终生成的就是pos.vec;-info pos\pos.txt为目标图片描述文件,在pos文件夹里;-bg neg\neg.txt为背景图片描述文件;-w 20为输出样本的宽度;-h 20为输出样本的高度;-num 4000为要产生的正样本数量。

图2.17 文件存放位置
图2.18 pos.vec所在位置
5、训练模型
在命令窗口输入如图2.19的指令,进行分类器的训练。其中,-data xml表示生成的数据保存着xml文件夹;-numPos 4000表示需要训练的正样本为4000,负样本同理;-w 20 -h 20 表示图片的尺寸;-numStage 15表示训练到15层,在正负样本充足的情况下通常设置为14-25;-minhitrate每阶段都应该保持的最小命中率;-maxfalsealarm 每阶段的最大错误预警值,如果非常高的错误预警值,意味着这是一个性能差的检测系统,默认为0.5。

图2.19 训练模型指令
6、等待训练完毕
本次训练中,到第10级就结束了。如图2.20所示,xml文件夹中的cascade.xml就是我们所需要的分类器。
图2.20 分类器生成详情
2.2.4检测结果对比分析
- 人脸检测流程
通常而言,进行人脸检测前,需要对图像进行预处理,包括调节大小、灰度化处理等,具体流程如图2.21所示。

图2.21 人脸检测流程
图像预处理虽然不是必需的环节,但这个环节,对整个人脸检测过程是有益的,因为图像缩放可归一化图像大小以提高人脸检测速率,图像灰度化可去除部分杂物干扰和降低运算量以提高人脸检测准确率和检测速率,直方图均衡化可智能调节图像的明暗程度以提高人脸图像可用率。例如,如图2.22所示,在同一个人脸分类器下,将没有经过灰度化的图像进行人脸检测时,出现了误检情况,而灰度化后的图片,没有出现误检。因此,本系统在人脸检测前会对图像进行预处理。

图2.22 灰度化前后检测对比图
- 自训练分类器与opencv自带分类器比较
本系统设计中,自己训练了一个人脸分类器,现将其与opencv自带的人脸Haar分类器(文件名为haarcascade_frontalface_alt.xml)进行初步比较,单人的比较结果如图2.23所示,多人的比较结果如图2.24所示。
从单人检测情况来看,自训练的分类器和opencv自带的分类器都能检出人脸,也都存在误检,如图2.23(a)所示。由于测试的样本较少,在单人检测中,两个分类器看不出性能的好坏。

(a) 本人的单人检测图

(b) 朋友的单人检测图

© 明星刘亦菲的单人检测图

(d) 明星范冰冰的单人检测图
注:单人检测图左边为原图,中间为自训练分类器检测结果,右边为opencv自带分类检测结果
图2.23 单人检测图
从多人检测情况来看,如图2.24(b)所示,自训练的分类器和opencv自带的分类器均存在漏检。但自训练的分类器的漏检率高于opencv自带的分类器的漏检率,如图2.24©所示,且自训练的分类器在多人检测中存在误检,如图2.24(a)所示。由此可知,自训练的分类器性能差于opencv自带的分类器。

(a) 多人检测图

(b) 多人检测图

© 多人检测图
注:图片来自网络;左(或上)边为原图,中间为自训练分类器检测结果,
右(或下)边为opencv自带分类检测结果。
图2.24 多人检测图
以上是对自训练的分类器与opencv自带的分类器进行初步对比所得到的结论。为了进一步探讨自训练分类器和opencv自带的分类器各自的表现,在本系统测试中,在尽量剔除主观情感且客观选择脸部各个方向倾斜程度不超过45°的前提下,于网络上随机选取了200张含单人的图像、50张含双人的图像以及20张含多人的图像共计434张人脸进行实验分析,结合表2.4所示的结果可得到如表2.5所示的结论。
表2.4 自训练分类器和opencv自带分类器的检测结果
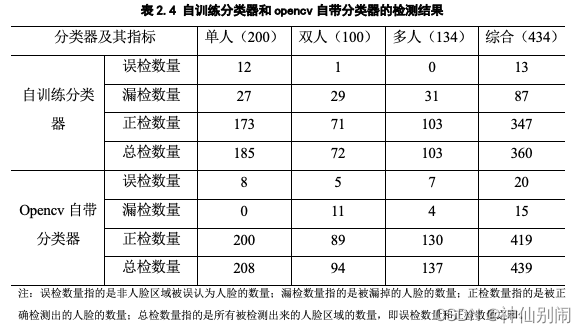
表2.5 自训练分类器和opencv自带分类器的性能
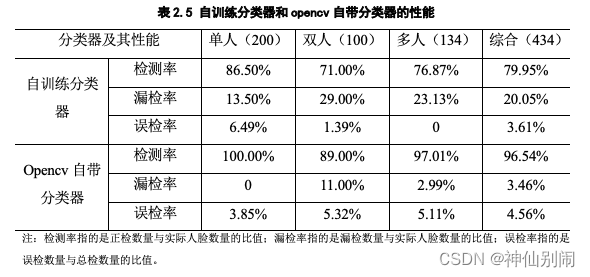
因此,在基于大量数据的实验中,我们能够知道:opencv自带的分类器,在单人图像检测、双人图像检测和多人图像检测中,都取得了相对较高的检测率和相对较低的漏检率,综合来看,其检测率高达96.54%,漏检率低至3.46%。无论是在单人图像的表现、双人图像的表现、多人图像的表现还是综合所有类型图像的表现中,opencv自带的分类器的检测率远高于自训练分类器的检测率,相应地,其漏检率远低于自训练分类器的漏检率。尽管自训练分类器的误检率略低于opencv自带分类器的误检率,但这在opencv自带分类器检测率呈压倒性胜利的前提下,不值一提。
总结:(1)自训练的分类器和opencv自带的分类器均出现误检、漏检的情况,但opencv自带的分类器明显优于自训练的分类器。除去算法本身的局限性外,出现漏检的原因有:①用于训练的正样本(包含人脸的样本)不够丰富;②正样本掺杂了负样本(不包含人脸的样本);③脸部倾斜或扭转幅度过大;④图片模糊或者光线暗淡等。出现误检的原因有:①负样本掺杂了正样本;②非人脸区域与人脸相似导致误判。自训练分类器表现不如opencv自带分类器的原因有:①自己收集的样本质量参差不齐;②自己收集的样本数量不够多;③不能很好地确定正样本所需要涵盖的人脸范围。(2)由于opencv自带的分类器优于本人自训练的分类器,故在系统的设计中,人脸检测的分类器采用opencv自带的分类器。虽然opencv自带分类器的误检率略高,但是在本系统的刷脸或注册过程中,摄像头前往往只有用户一人,而由表2.5可知,opencv自带分类器在单人图像中误检率最低检测率最高,且在系统设计里,人脸占据画面较大的范围,故我们只提取opencv检测出来的最大人脸区域,并对该区域进行二次校验,即后文提到的人脸关键点定位分析。理论上,在双重检验下,误检率为趋于0。
2.3 本章小结
本章主要介绍了人脸检测前所需要的图像处理以及Viola-Jones人脸检测算法。
图像处理包含缩放、灰度化和直方图均衡化。图像缩放用于归一化图像大小,提高人脸检测的速率;图像灰度化用于去除杂物干扰,提高人脸检测的准确率;直方图均衡化用于调节图像的明暗程度,提高人脸图像的可用率。
在介绍Viola-Jones算法时,着重介绍了Haar特征、Adaboost算法,同时也对Haar分类器的训练做了介绍,最后给出了自己训练的分类器与opencv官方自带的分类器的检测结果的对比分析。其中,Haar特征用于描述人脸的灰度分布情况,Adaboost算法作为弱分类器、强分类器和级联分类器的指导思想。检测结果的对比分析主要以检测率、漏检率和误检率为指标,分别在单人和多人的情况下进行对比分析。
3动态校验与匹配识别
3.1 动态校验
身份认证(即刷脸登录)过程中,为了避免用户利用照片等非本人且非活体来欺骗系统蒙混过关的现象发生,本系统在设计时联合前后端技术对人脸进行动态校验。具体表现为:在刷脸登录时,提示用户做出张嘴和眨眼动作,系统每隔一秒截取实时录像内容进行关键点定位,同时完成张嘴和眨眼动作的判断,前者是为了防止用户切换照片或人体(一秒的时间很短,用户很难进行切换操作,尽管来得及切换,也会因为图像模糊导致关键点定位失败),后者是为了完成活体的校验。
3.1.1人脸关键点定位
Dlib库是一个机器学习的开源库,它提供了丰富的功能模块,包括人脸检测模块、人脸识别模块和人脸关键点定位模块等。其提供的人脸关键点所使用的算法为ERT(ensemble of regression trees)级联回归,也就是基于梯度提高学习的回归树方法[1]。人脸关键点定位可以应用于疲劳检测等领域以及3D姿态估计等。
人脸关键点的定位顺序如图3.1所示。本设计主要分析眨眼状态和张嘴状态,由图可知眼睛部分的关键点序号为36-47,嘴巴部分的关键点序号为48-67。

图3.1 人脸关键点序号图
3.1.2眨眼和张嘴判定
1、眨眼判定
为避免人脸跟摄像头的距离远近带来的不良影响,本系统采用右眼眉毛最高点(关键点是24)到上眼睑最高点(关键点是44)的距离即3.2图中实线部分占右眼眉毛最高点(关键点是24)到下眼睑最低点(关键点是46)的距离即3.2图中虚线部分的百分比的变化来作为是否眨眼的依据。
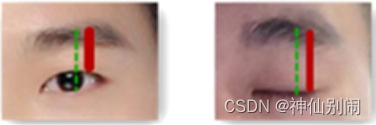
图3.2 睁眼和闭眼时的标记示意图
设关键点24为
,关键点44为
,关键点46为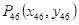
,则:
实线的长度即眉毛最高点
到上眼睑最高点
的距离为
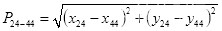
(3.1)
虚线的长度即眉毛最高点
到下眼睑最低点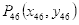
的距离为
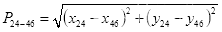
(3.2)
图中直线长度占虚线长度的百分比为
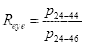
(3.3)
如表3.1,当眼睛处于睁开状态,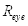
的平均值为0.732;当眼睛处于闭合状态,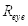
的平均值为0.888。两者相差0.156。在本系统中,两者相差超过0.1则可以判断用户眨过眼,即设置眨眼阈值为0.1。
2、张嘴判定
与眨眼判断同理,本系统采用下嘴唇中线最低点(关键点是57)到下巴中线最低点(关键点是8)的距离即图3.3中实线部分占上嘴唇中线最高点(关键点是51)到下巴中线最低点(关键点是8)的距离即图3.3中虚线部分的百分比的变化来作为是否张嘴的依据。
设关键点57为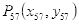
,关键点8为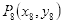
,关键点51为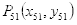
,则:
直线长度即下嘴唇中线最低点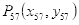
到下巴中线最低点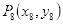
的距离为
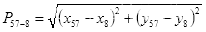
(3.4)
虚线长度即上嘴唇中线最高点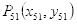
到下巴中线最低点
的距离为
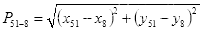
(3.5)
图中直线长度占虚线长度的百分比为
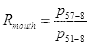
(3.6)
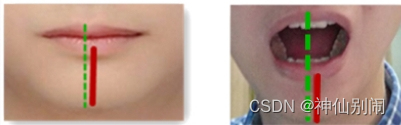
图3.3 闭嘴和张嘴时的标记示意图
如表3.2,当嘴巴处于张开状态,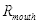
的平均值为0.381;当嘴巴处于闭合状态,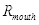
的平均值为0.617。两者相差0.236。在本系统中,两者相差超过0.2则可以判断用户张过嘴,即设置张嘴阈值为0.2。
表3.1 睁眼和闭眼时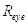
取值状况

表3.2 张嘴和闭嘴时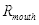
取值状况
总结:同一个人的睁闭眼或者张合嘴的图片难以收集,且睁眼力度和张嘴力度非常容易受主观因素影响(通常认为,用户在知道需要认真配合检测的情况下,会有意增强睁眼力度和张嘴力度)。基于上述两个原因,本实验无法通过大量的数据求得一个客观的阈值。鉴于此,本系统设置了相对低的眨眼阈值和张嘴阈值,且用户只需满足眨眼判断或张嘴判断的条件之一。理论上,一个拥有正常睁眨眼和张合嘴功能的用户,只要他积极配合,是足以通过系统的动态校验的。
3.1.3 人脸对齐
人脸对齐,顾名思义,即为矫正图像中倾斜的人脸以实现人脸居正。用户在注册或者登录的时候,由于自身习惯等原因,其人脸未必能够居正。而统一对齐方式,有利于后边的人脸匹配识别。因此,人脸对齐的意义非凡。尽管该功能不属于动态校验的一部分,但其与人脸关键点定位息息相关,且该过程是在动态校验的过程中顺便实现,故放于此节介绍。
人脸对齐的原理:根据眼睛所在的直线与x轴正方向的夹角的角度进行图像旋转。由图3.1可知,左眼下眼睑最低点的关键点是40,设为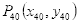
,右眼下眼睑最低点的关键点是46,设为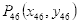
。设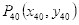
和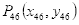
两点的连线与x轴正方向的夹角为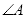
,则正切函数为
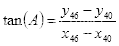
(3.7)
由反正切函数可得夹角的角度
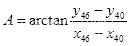
(3.8)
根据角度A,利用Java语言中有关图像操作的函数对图像进行旋转,即可完成人脸的矫正,效果如图3.4所示。
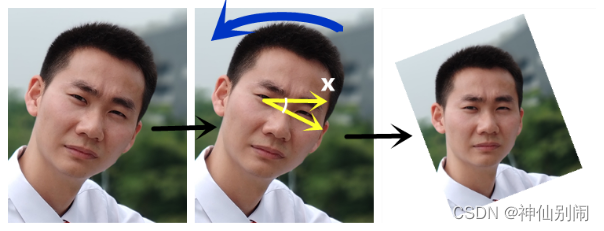
图3.4 人脸对齐示意图
3.2 匹配识别
3.2.1 PHash匹配算法
1、简介
本系统进行人脸匹配识别所采用的算法是PHash,即感知哈希算法,其具有高检测速率,对图像缩放不敏感的优点[8]。
通常而言,每张图片都包含高频成分和低频成分,高频成分提供图片详细的信息,而低频成分展示了图片的整体架构。PHash主要利用图片的低频成分,滤掉细节,对每张图片生成一串特定的二进制数字。图与图的匹配,相当于二进制数字与二进制数字的简单比较,即统计相同位置数字相同的次数占总比较次数的百分比情况,百分比越高,则图像越相似。
- 流程
人脸匹配识别的流程如图3.5所示。

图3.5 PHash算法流程图
(1)步骤一,缩小人脸灰度图像的尺寸。
将图像缩小为16×16,即归一化大小,缩小后的图像总共包含256个像素。该步骤的目的是保留人脸图像结构、明暗等基本信息,剔除细节,避免不同尺寸或比例造成的差异,同时提高识别速度。
(2)步骤二,色彩简化。
将步骤一得到的缩小后的图片,转为256级灰度。由于本系统人脸识别部分得到的人脸图像本身是灰度图像,故该步骤跳过。
(3)步骤三,将步骤而得到的图像二值化。
计算上述256个像素的灰度平均值,然后比较各个像素的灰度值与平均值。若灰度值小于平均值,记为0;否则记为1。
(4)步骤四,计算图像的哈希值。
将步骤三各个像素得到的结果组合在一起(组合次序不重要,但要保证所有图片都采用相同次序),这样就构成了一个256位的二进制数。
(5)步骤五,图像匹配。
得到哈希值后,就可以对比两张不同图片对应的二进制数,根据同一位置数字相同出现的次数占总比对数目的百分比来判断两张图片是否相似。本系统预设的匹配阈值为0.78,如果相同的次数超过200(即相似度大于0.78),则认为两张图片很相似;否则,认为两张图片不同。
3.2.2 人脸匹配结果分析
在本系统中,进行人脸匹配的图像,是包含尽可能无表情且居正的人脸的原始图像经过人脸检测(流程在第二章已介绍)后截取的人脸区域,此为实验的大前提。
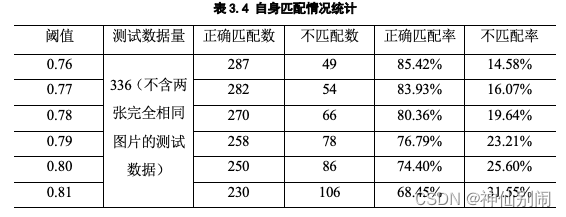
在人脸自身匹配测试中,采用ORL人脸库、Yale人脸库和本人总计56个人作为样本,每人有4张照片,在除去两张完全相同的人脸图像的测试数据的前提下,可以产生336条有效测试数据。自身匹配的示例如表3.3所示,总共有56张类似的表,由于篇幅有限,这里不一一展示。自身匹配的情况统计如表3.4所示,从中我们可以知道,阈值越高,自身的匹配率越低。
表3.3 自身匹配实际情况示例

表3.4 自身匹配情况统计
在自己与除了自己以外的其他人匹配测试中,采用来自网络的、进行一定筛选的并且通过人脸检测截取出的人脸区域图像作为样本,总量为110张,在除去自身匹配的测试数据的前提下,可以产生4950条有效测试数据。自己与除了自己以外的其他人匹配的示例如表3.5所示,由于篇幅有限,这里无法完全展开。自己与除了自己以外的其他人匹配的情况统计如表3.4所示,从中我们可以知道,阈值越高,错误匹配率越低。
表3.5 自己与除了自己以外的其他人匹配情况示例

表3.6 自己与除了自己以外的其他人匹配情况统计
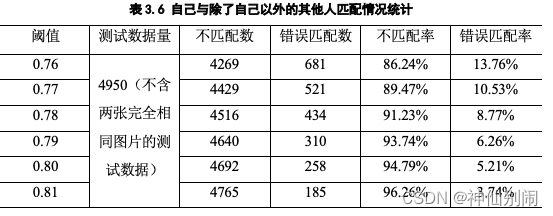
结合人脸自身匹配测试和自己与除了自己以外的其他人匹配测试情况、表3.4和表3.6的实验结果,我们得出:自身的正确匹配率和与他人的错误匹配率呈正比关系,低阈值能提高自身的正确匹配率,但同时也提高了与他人的错误匹配率。因此,我们需要寻找一个合适的阈值(即相似度),使得自身匹配率尽可能高,同时使得与他人的错误匹配率尽可能低。由表3.4和表3.6可知,将阈值设为0.78,自身的正确匹配率能达到80%多,同时与他人的错误匹配率能降低到10%以下。
总结:(1)匹配率与准确率成反比关系,高匹配率意味着低阈值,而低阈值意味着低准确性。影响匹配率的因素,表面上是阈值的设定,深层原因是光线、脸部摆正情况、妆容、表情、图片清晰度等。显然,在同一环境、表情、角度等情况下,两张完全相同的图片的相似度为1,即表3.3和表3.5中用斜线代替的部分。但现实中并不存在该理想条件,我们可以适当降低阈值来提高匹配率,或者考虑更优算法以取得满意的效果。(2)本系统将截取的人脸图像与数据库储存的信息逐个比对,选取最大相似度,当其达到预设的阈值,即认为该最大相似度所关联的账户信息为当前用户的账户信息。
3.3 本章小结
本章主要介绍了人脸动态校验功能、人脸对齐功能以及PHash感知哈希算法。
人脸动态校验借助Dlib库的人脸关键点定位,对张嘴和眨眼进行判断,即分别设置合适的阈值。睁闭眼之间或张闭嘴之间产生一个差值,当差值高于预设阈值则认为用户眨过眼或张过嘴。该判定通过前台连续截取实时录像内容发往后台校验。
人脸对齐同样借助关键点定位,用于矫正人脸图像。
PHash算法用于比较图像的相似度,算法简单高效,适合用于本系统的人脸匹配。
4系统软件设计
4.1系统架构
基于动态人脸识别的身份认证系统主要由Java语言和Web相关语言开发,其架构如图4.1所示,主要分为四个模块:
刷脸登录模块:每隔一秒截取摄像头画面进行人脸关键点定位和人脸检测,同时进行张嘴眨眼的判断以及人脸对齐(前者是为了防止用户切换照片或人体,后者是为了完成活体的校验并且矫正人脸),通过动态检验后,将截取的矫正后的人脸区域与数据库的数据进行匹配,匹配成功则显示欢迎界面,失败则弹出提示。
账号登录备用模块:当光线不好时,刷脸登录的功能可能无法使用,这时可以通过账号登录。
人脸账号注册模块:用户可以注册账号,同时绑定人脸,注册过程中需要对人脸图像进行人脸检测、关键点定位,前者是为了检测人脸并截取人脸区域,后者是对获取的人脸真假与否进行二次校验和人脸对齐;通过二次校验后,将截取的矫正后的人脸区域利用PHash算法转换成特定的二进制数字串写进数据库。
管理员界面模块:主要实现用户信息的分页展示。管理员可以查询、修改和删除用户信息。
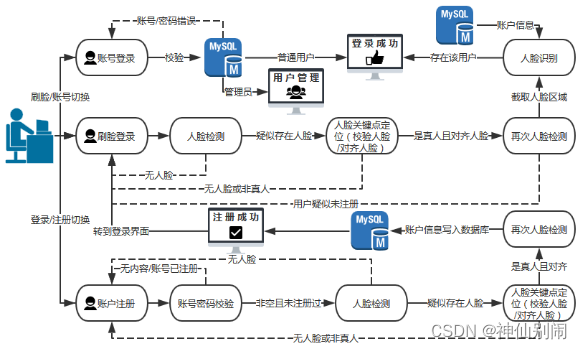
图4.1 系统结构图
4.2 系统配置
系统版本:window 7 x64;
开发工具:Myeclipse 2016;
Opencv库版本:opencv 340;
Dlib库版本:Dlib 19.1;
数据库版本:MySQL 5.5;
服务器版本:Tomcat 8.0;
测试工具:谷歌/火狐浏览器。
4.3 前端技术
1、HTML
HTML全称为Hyper Text Mark-up Language,中文名为超文本标记语言,是由 Tim Berners-lee提出的用于创建网页的标准语言,也即前端的结构层。
HTML包含头部 (Head)和主体 (Body) 两个部分,其中,头部用于配置浏览器所需的信息,主体包含由 HTML命令组成的描述性文本,如文字、 图片、表格、表单、超链接等。
2、CSS
CSS全称为Cascading Style Sheets,中文名为层叠样式表,是一种旨在将网页样式与内容分离的样式设计语言,也即前端的表现层。
CSS不仅可以简化网页格式代码,而且由于外部的样式表能被浏览器缓存,上传下载都极其方便。只要修改保存着网站格式的CSS样式表文件就可以改变整个站点的风格特色,因此,在修改页面数量庞大的站点时,可以避免了一个个网页的修改,这样就大大减少了工作量,极大地提高了我们开发的速度,降低了维护的成本[14]。
3、JavaScript
JavaScript是由Netscape公司于1995年首次提出的一门世界性流行的解释型脚本语言,属于前端的行为层。
JavaScript轻量、简洁,提供了一些内置函数、对象和DOM操作,借助这些可以实现一些客户端的特效、验证、交互等,增加HTML的动态功能,因此被广泛应用于浏览器中[15]。
4、jQuery
jQuery是一个免费开源、快速简洁、兼容性强的JavaScript框架,倡导写更少的代码做更多的事。其封装JavaScript一些常用功能代码,提供了一种简洁方便的JavaScript设计模式,优化HTML文档操作、事件处理、动画设计和Ajax交互,并且拥有便捷的插件扩展机制和丰富的插件,能够极大缩短开发时间,提高开发速度。
5、Ajax
Ajax技术全称为Asynchronous JavaScript and XML,其中文名称是异步JavaScript和XML。它集合了多种技术,是web2.0的核心。Ajax技术可以在不必刷新整个页面的情况下,对网页的局部进行更新,以达到节省网络带宽,加快网页加载速度,缩短用户的等待时长,改善用户的浏览体验的作用。
在传统的web应用中,用户发送表单请求给servlet服务器,servlet服务器在收到表单请求后,会返回全新的页面给客户端,这个过程是同步的,用户只能等待网页的响应而不能做其他操作,同时这种做法也会浪费很多带宽,原因是请求之前的页面和获得的新页面有很多共同的代码。如果采用Ajax技术,情况就有所不同了。如图4.2所示,客户端发起请求后,Ajax只需要通过xml或者json来获取一些必需的数据,利用JavaScript对网页进行局部更新,同时它支持异步操作,用户可以不用刻意等待ajax与servlet的交互完毕,这样用户请求就能得到了加速,体验大大改善。
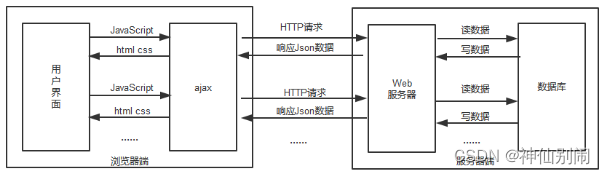
图4.2 异步交互方式
4.4 后端技术
1、MySQL数据库
MySQL是由瑞典MySQL AB 公司开发的一种关系型数据库。MySQL属于 Oracle 旗下的免费开源产品,是当前最为流行的关系型数据库管理系统之一。由于MySQL不是把全部数据储存在一张表中,而是将不同类型的数据保存于不同表中,因此,不仅读写速度得到极大的增加,灵活性也大大提高[12]。
MySQL体积小、总体拥有成本低、速度快、所采用的 SQL 语言是最常用于访问数据库的标准化语言,因其具备种种优点,一般中小型的网站的开发在选择数据库时都会优先采用MySQL。
本系统采用MySQL 5.5作为数据库,来存储账号、密码、人脸图片路径以及人脸特征(即二进制数字),如图4.3和图4.4所示。

图4.3 建表结构

图4.4 数据存储
- JSP
JSP的全称为Java Server Pages,它是一种用于开发动态网页的技术,能够实现在HTML网页中插入Java代码。
JSP本质上是一种servlet,是为解决servlet输出动态页面过于复杂的问题而出现的后端渲染技术[11]。通过具有丰富功能的JSP标签、JSP动作以及九大内置对象等,可以实现数据库的访问、作用域信息的传递和共享以及循环展示和条件判断等功能,实现生成动态网页的功能。
JSP的优势明显。与ASP相比,JSP动态部分用Java编写,更强大,更易用,可移植;与 Servlet 相比,JSP能够很方便地编写或者修改HTML,灵活性高。与SSI相比:JSP能够使用表单数据、能够访问数据库;与JavaScript相比:JSP可以提供更复杂的逻辑交互;与HTML相比:JSP可以包含动态信息。
- Servlet
Servlet,中文名为服务连接器,是一门应用于web资源动态开发的技术,由Sun公司提供[11]。Servlet主要用于处理客户端发起的HTTP请求以及将响应结果反馈给客户端,过程如图4.5所示。
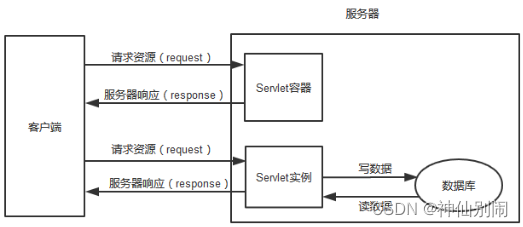
图4.5 HTTP请求与响应
tomcat和servlet的关系:Tomcat 是免费、开源的Web应用服务器,可以作为Servlet/JSP容器。作为一个Servlet容器,Tomcat负责将客户端发起的请求传给Servlet处理,并将Servlet的响应传回给客户端。Servlet是运行在支持Java的服务器上的一种组件。它通常用于扩展Java Web服务器功能,提供安全的、高效的、可移植的、易维护的CGI替代品。
用户访问web系统时,从发起http请求到响应http请求,过程如图4.6所示。
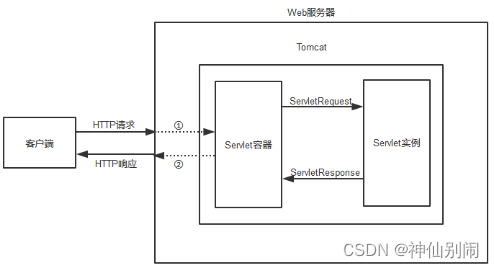
图4.6 服务器工作形式
①:Tomcat接收并解析http请求文本,然后封装成request对象(HttpServletRequest类型),通过request对象调用相应的方法就能查询到所有的HTTP头数据。②:Tomcat将响应的信息封装为response对象(HttpServletResponse类型),通过设置response属性就可以控制想要输出到浏览器的内容,然后将response交给tomcat,tomcat就会将其变成响应文本的格式发送给浏览器。
Java Servlet API 是Servlet容器(tomcat)和servlet之间的接口,它不仅定义了serlvet的不同方法,同时也定义了从Servlet容器传给Servlet的对象类,尤以ServletRequest和ServletResponse最为重要。我们在创建servlet时,必须实现Servlet接口,并且严格按照其规范进行编写。
JSP和servlet的区别与联系:JSP是基于servlet实现的,本质上是一种servlet;JSP代表传统MVC架构中的View视图,它注重于视图显示;而servlet代表传统MVC架构中的Controller层,它注重于控制;JSP只需要编译一次,在只修改静态内容的情况下,不需要重新编译。
4.5 JNI技术
本系统采用Dlib库中的人脸关键点定位程序是通过JNI技术从C++环境移植而来。JNI,我们称之为Java本地接口,用于实现Java和其它语言(主要是C语言和C++)的通信。JNI标准从Java1.1开始便成为Java平台的一部分,它允许Java代码和其它语言编写的代码进行通信交互。本系统移植C++程序步骤如下:
步骤一,编写制作JNI的java类,在本系统为DlibJNIJAVA类,代码如下。
package com.zelong.lin.utils;
public class DlibJNIJAVA {
` `public native double[] getLandMarks(String dat,String img);
}
步骤二,生成C头文件,生成命令如图4.7所示,生成的头文件如图4.8所示。

图4.7 生产C头文件的命令
图4.8 生成的C头文件及其位置
步骤三,本系统采用的C++编程环境为visual studio 2017,在该软件上创建一个dll动态链接库项目(本系统中dll项目取名为DlibJNI),将jdk目录下的include目录里的一个jni.h文件、include目录下的win32目录里的jni_md.h文件和第二步中生成的C头文件一起拷贝到C工程的DlibJNI目录下(本系统当前工程名就叫DlibJNI,工程目录下还有一个DlibJNI目录),如图4.9所示。
图4.9 h头文件的存放位置
步骤四,完成c++程序的功能,编译后将生成的DlibJNI.dll加载进DlibJNIJAVA类。其中,DlibJNI.dll位于当前工程DlibJNI\x64\Release目录下,代码如下。
package com.zelong.lin.utils;
public class DlibJNIJAVA {
` `static{
` `System.load("E:/face68/DlibJNI.dll");
` `}
` `public native double[] getLandMarks(String dat,String img);
}
步骤五,使用DlibJNIJAVA类,在需要使用人脸关键点定位的类中,创建DlibJNIJAVA对象,然后调用它的getLandMarks(dat,path)方法。
DlibJNIJAVA jni = new DlibJNIJAVA ();
Double[] b = Jni.getLandMarks(dat,path);
4.6 运行演示
1、刷脸登录模块
步骤一:用户点击刷脸登录按钮前,给予温馨提示,点击按钮后,进入步骤二。
步骤二:提醒用户眨眼和张嘴,并每隔1秒截取5张照片,前者是为了确定活体,后者是为了防止用户通过切换图片来欺骗系统。
步骤三:①进行人脸检测,当检测不到人脸,弹出提示,返回步骤一;②当检测得到人脸,扩大并提取人脸所在区域进行人脸关键点定位,定位失败则回到步骤一,定位成功则进行人脸对齐,然后再次进行人脸检测并截取人脸区域,最后将截取的区域进行匹配,若匹配失败,弹出“用户疑似未注册”提示,返回步骤一;若匹配成功,先储存成功信息,进行步骤四。
步骤四:对后四张图片进行关键点定位,确定用户有过眨眼或张嘴行为,并且每张图片都能定位关键点,即每张图片都有清晰的人脸,进行步骤五;否则,弹出“疑似非真人登录”,返回步骤一。
步骤五:根据步骤三保存的成功信息,跳转到欢迎界面,进而跳转到广工大主页。
图4.10 刷脸登录前的温馨提示
图4.11 未注册用户弹出未注册提示
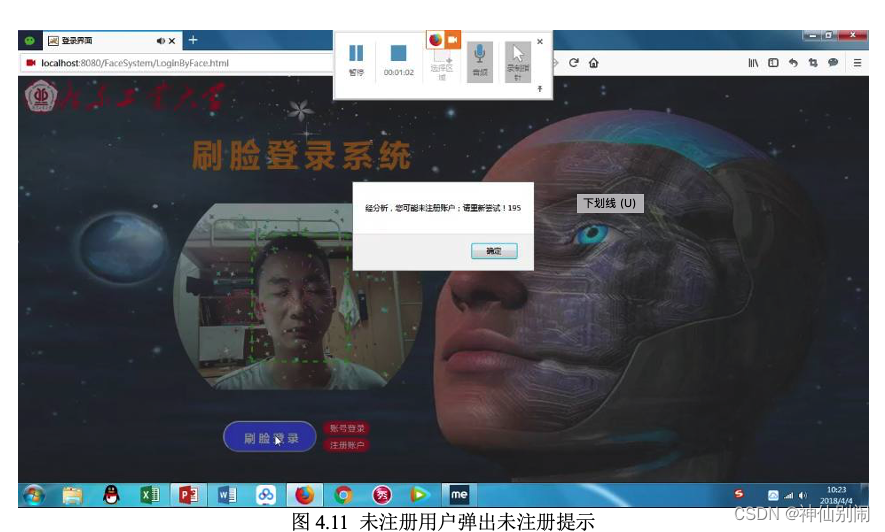
图4.12 张嘴眨眼的检测
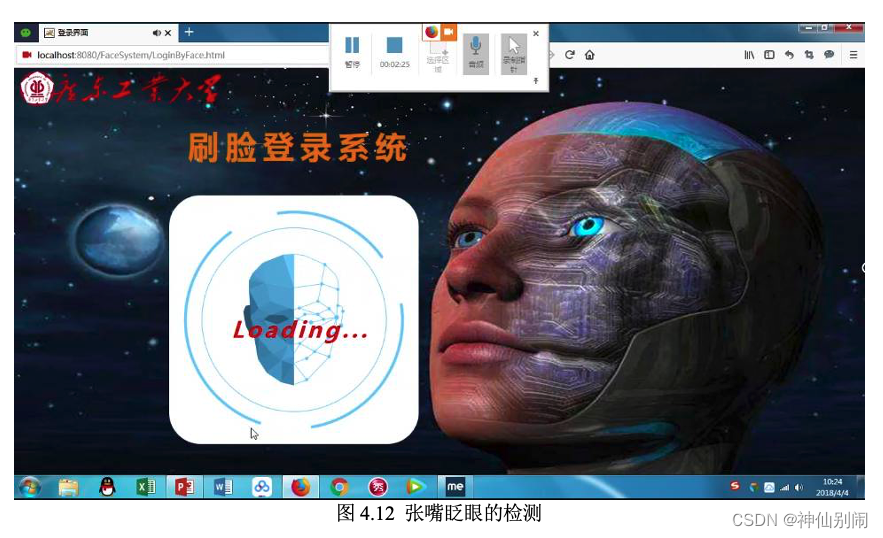
图4.13 匹配成功后的欢迎界面
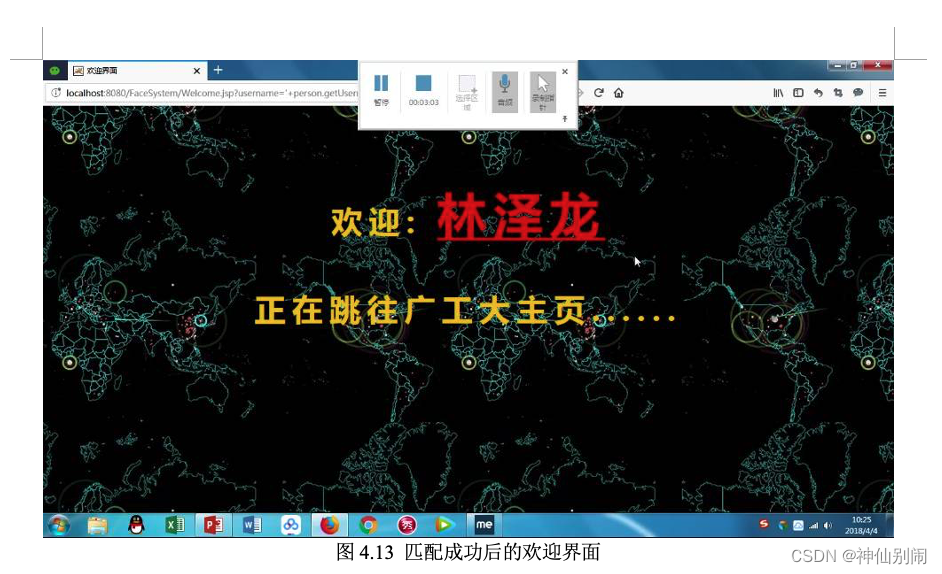
图4.14 试图用照片刷脸登录
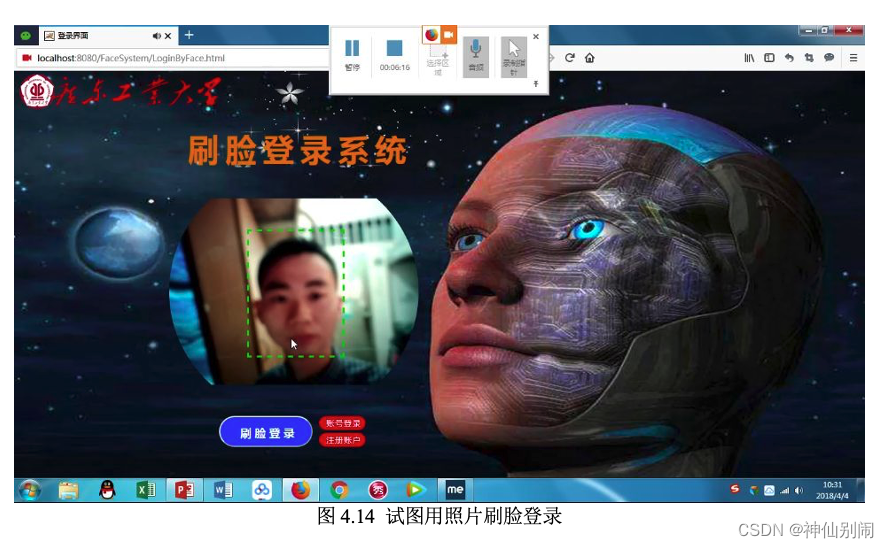
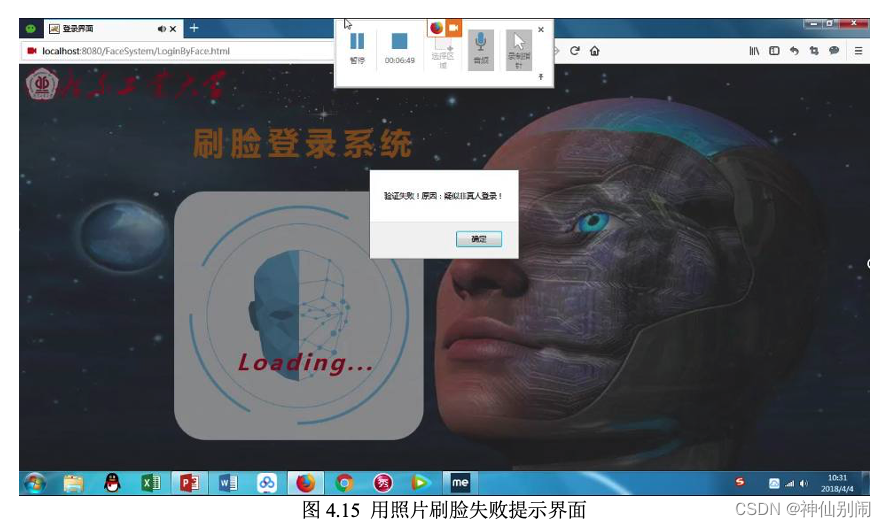
图4.15 用照片刷脸失败提示界面
2、账号登录模块
步骤一:在用户输入自己的账户点击登录后,进入步骤二。
步骤二:①前台对账户信息进行非空校验,当检测到空账号或空密码,弹出相应提示,返回步骤一;②当账号和密码非空,发送到后台,后台查询数据库,若账号或密码错误,弹出提示,返回步骤一;若账号存在,进行步骤三。
步骤三:若账号为普通用户,跳转到普通用户欢迎界面,进而跳转到广工大主页;若账号为管理员用户,跳转到管理员欢迎界面,进而管理员可以对用户进行修改和删除。
图4.16 账号登录界面
图4.17 密码错误提示界面
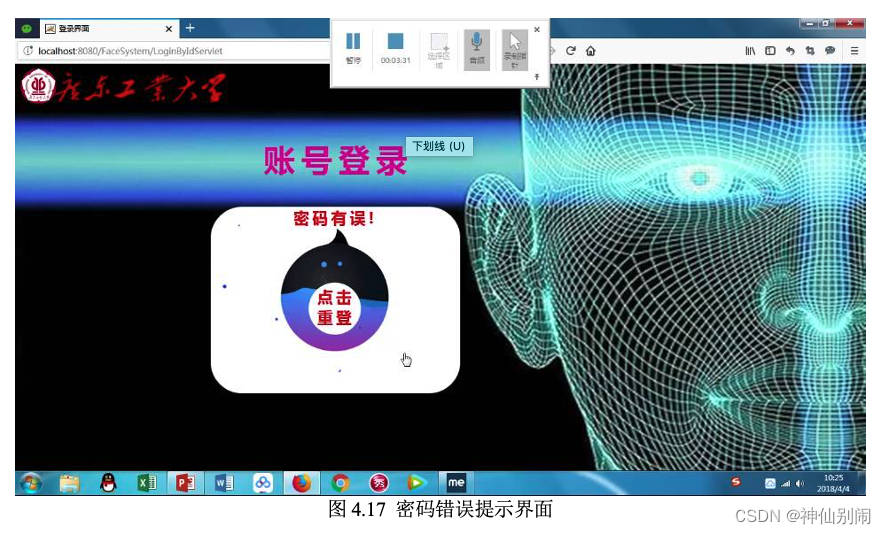
图4.18 管理员欢迎界面
3、注册模块
步骤一:用户填入账户信息点击注册后,进入步骤二。
步骤二:①系统对账号和密码进行非空校验,以及对摄像头进行开启判断,当账号或密码为空,或者摄像头未开启,弹出相应提示,返回步骤一;②当账号和密码非空,查询数据库,若账号已存在,弹出提示,返回步骤一;若账号未被注册,进行步骤三。
步骤三:①进行人脸检测,当检测不到人脸,弹出提示,返回步骤一;②当检测得到人脸,扩大并提取人脸所在区域,进行步骤四。
步骤四:对人脸图像进行关键点定位,确保步骤三截取的人脸区域包含人脸,同时对该图像进行对齐。对齐之后,再进行人脸检测,提取矫正后的人脸区域,然后进行步骤五;否则,弹出“检测不到人脸”提示,返回步骤一。
步骤五:将账号、密码、图片路径、人脸特征(二进制数字)写入数据库,将人脸图片保存在本地,然后跳转到注册成功界面,进而跳转到刷脸登录界面。
图4.19 注册前的温馨提示
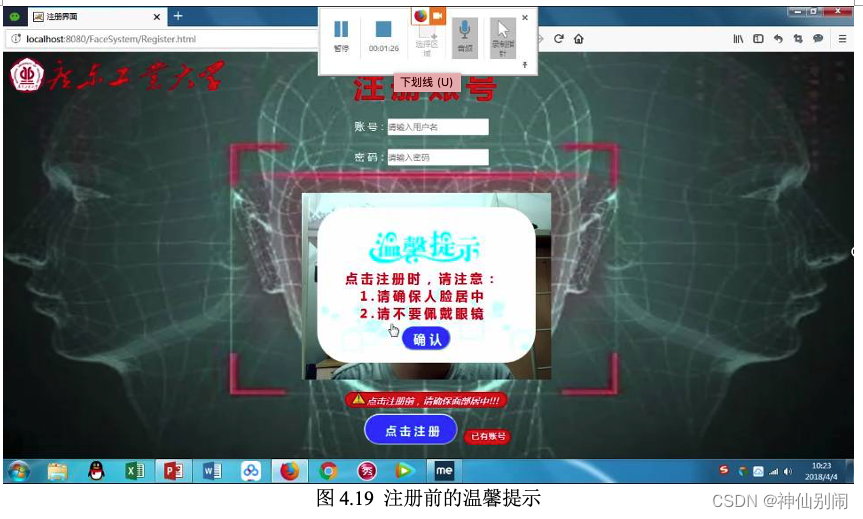
图4.20 注册成功界面
在这里插入图片描述
图4.21 储存在本地的人脸图像

4、管理员模块
管理员可以对用户的相关信息进行查询、修改和删除。
图4.22 用户信息分页显示界面
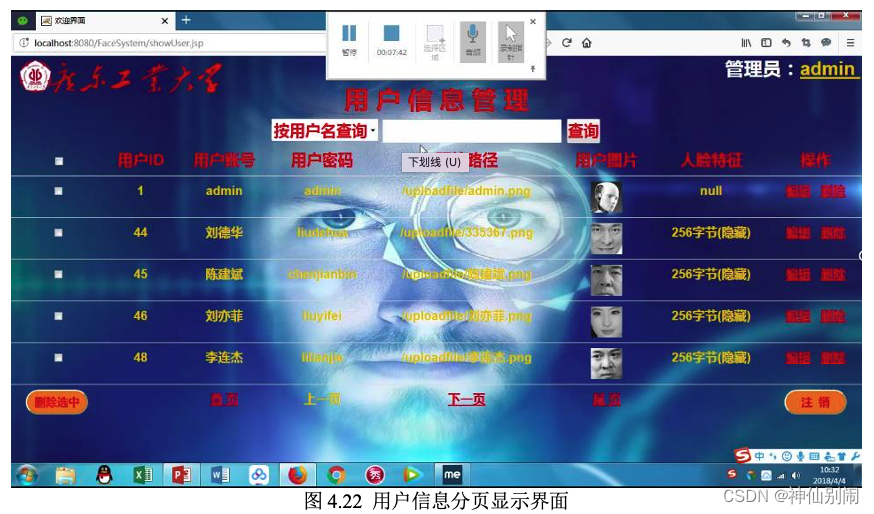
图4.23 条件查询界面
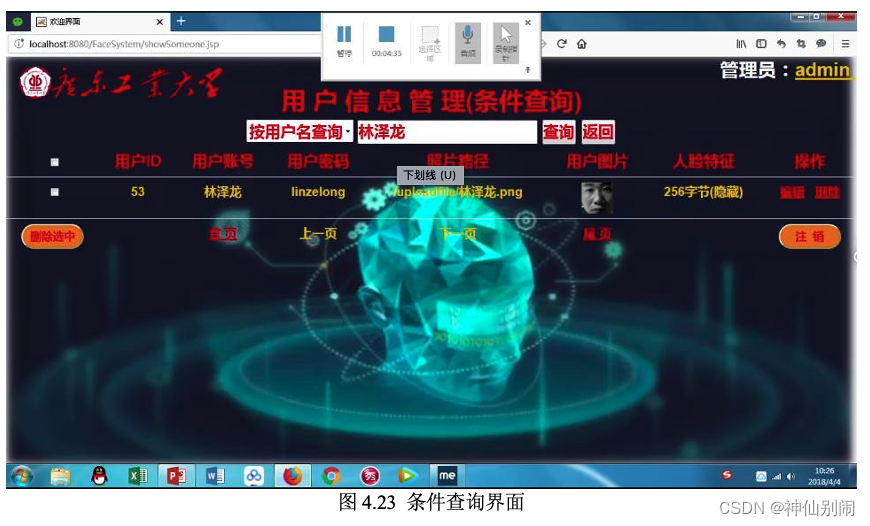
图4.24 用户信息修改界面
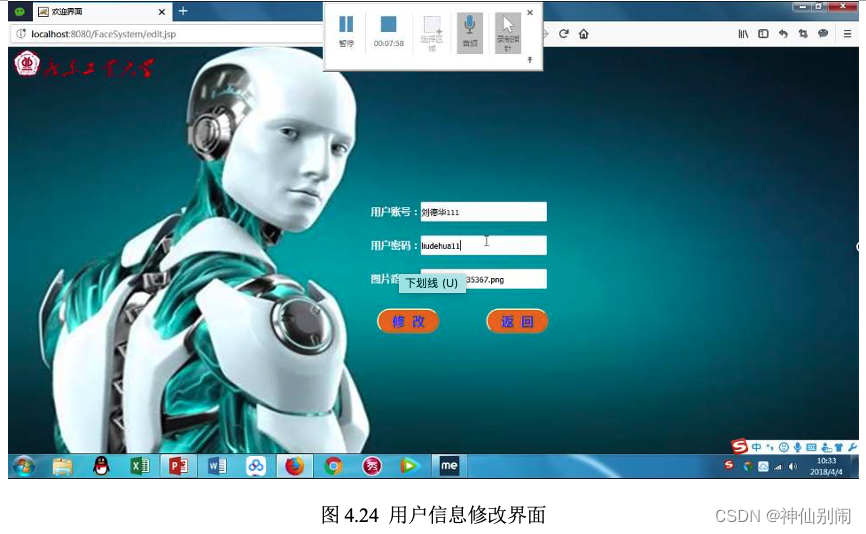
图4.25 用户信息批量删除界面

4.7 本章小结
本章主要介绍系统的总体架构、涉及到的前端技术、后端技术、JNI移植技术以及系统的运行演示。
总体架构包含刷脸登录模块、账号登录模块、人脸账号注册模块以及管理员界面模块;前端技术包含Html、Css、Javascript、ajax、boostrap等;后端技术包含Jsp、Servlet、Mysql等;JNI技术为Java本地接口,本系统用于移植C++函数到Java环境中使用。
在介绍完以上技术后,对系统的运行界面进行描述展示。
总结展望
1、总结
本文主要介绍用Javaweb实现的基于动态人脸识别的身份认证系统,论文的主要结构如下:
开篇对人脸识别领域的背景、国内外现状、研究意义、算法分类等进行介绍,方便后文的展开。
接着介绍图像处理相关的知识以及本系统使用到的人脸检测算法。在人脸检测之前,需要对图像大小进行调整,提高读取图片的速度;再将彩色图像灰度化和均衡化,减少运算量和增强图像均匀度。在人脸检测的过程,先定位人脸区域,在将人脸部分截取,根据需要进行保存。
然后介绍人脸定位和匹配算法。本系统需要完成动态校验,在实际设计中,采用张嘴和眨眼判断的方案来进行活体检测,所使用的是Dlib库的人脸关键点定位算法,该算法也同时应用于人脸对齐。当活体检验通过,则进行人脸的匹配,确定该人的身份。人脸匹配采用的是哈希感知算法,原理简单,效率较高,当然,准确度略低。
最后,对系统设计使用到的前端后端技术进行介绍,以及用贴图的方式介绍系统每个功能模块。
本次毕设,基本实现了指导老师拟题时所提出的要求,但系统设计过程中所涉及的算法,有待进一步优化,系统的性能有待进一步提升。
2、展望
本系统的设计基于Javaweb,初次涉及人脸识别和web的开发,难免准备得不够充分。经过本次毕设,我对web及人脸识别领域有了更深的认识。系统需要进一步的改进与完善,以下是个人的一些改进建议与看法。
在人脸检测方面,可以采用更先进的算法,比如MTCNN算法[4],降低误检率和漏检率;在人脸识别方面,可以采用更先进的算法,比如DeepID算法[5]和PCA算法[7]等,提高匹配的准确率。在Web系统方面,可以采用SSM框架,优化系统结构,提高运行速度;在功能操作方面,可以提供更多的功能如审批功能、允许用户自己修改密码等,也可以继续提高安全性如加入虹膜识别,指纹识别等等。
人脸识别技术已远超我们想象的速度发展,我相信在不久的将来,人脸识别技术能像指纹识别技术一样,方便快捷,安全可靠,应用于生活的方方面面,大大提高效率。
♻️ 资源
大小: 24.9MB
➡️ 资源下载:https://download.csdn.net/download/s1t16/87359324
相关文章
- MySQL_(Java)使用JDBC向数据库发起查询请求
- JAVA-数据库之MySQL与JDBC驱动下载与安装
- 【MySQL】常见的mysql 进程state
- 单独java 程序连接Mysql数据库
- MySQL账户安全设置
- Java通过mysql-connector-java-8.0.11连接MySQL Server 8.0遇到的几个问题
- Warning: mysql_fetch_array(): supplied argument is not a valid MySQL result
- thinkphp6:访问mysql数据库(thinkphp 6.0.9/php 8.0.14)
- mysql explain介绍
- R语言使用RMySQL连接及读写Mysql数据库 测试通过
- 【JAVA】 03-Java中的异常和包的使用
- mysql where条件使用了or会不会扫全表
- MySQL事务隔离级别理解_解读MYSQL的可重复读、幻读及实现原理
- MySQL字段类型与Java数据类型的对应关系
- Atitit. 数据约束 校验 原理理论与 架构设计 理念模式java php c#.net js javascript mysql oracle
- 省市区县三级联动JAVA+MySQL+JQuery
- 详解MySQL information_schema数据库常用的表信息以及各表对应的字段信息;以及如何登录mysql和创建视图
- mysql事务 mysql事务回滚 MySQL事务死锁 如何解除死锁 资金出入账
- MySQL当您插入列无效的数据插入
- java链接到mysql
- MySQL之自带四库之mysql库
- Mysql基础篇之一条Sql更新语句的前世今生---02
- 【java】Java并发编程--Java实现多线程的4种方式
- JAVA开发讲义(二)-Java程序设计之数据之谜二
- Mysql报错:Got fatal error 1236 from master when reading data from binary log: ‘Could not find first lo
- 面试题系列:Mysql 夺命13问,你能扛到第几问?
- MySQL数据库从入门到实战应用(学习笔记一)