
吴恩达机器学习笔记 —— 11 应用机器学习的建议
2023-09-11 14:17:24 时间
http://www.cnblogs.com/xing901022/p/9356783.html
本篇讲述了在机器学习应用时,如何进行下一步的优化。如训练样本的切分验证?基于交叉验证的参数与特征选择?在训练集与验证集上的学习曲率变化?在高偏差或者高方差时如何进行下一步的优化,增加训练样本是否有效?
更多内容参考 机器学习&深度学习
如果已经创建好了一个机器学习的模型,当我们训练之后发现还存在很大的误差,下一步应该做什么呢?通常能想到的是:
- 1 获取更多的数据
- 2 尝试选择更少的特征集合
- 3 获得更多的特征
- 4 增加多项式特征
- 5 增加λ
- 6 减小λ
样本的切分:首先针对我们的样本集,选择其中的70%作为训练集,训练模型;选择其中的30%作为测试集,验证模型的准确度。当使用交叉验证时,就不能简单的把数据集分成两份了,因为这样无法同时选择模型并衡量模型的好坏。因此可以把样本分成3份,其中60%作为训练集,20%作为交叉验证集,20%作为准确率测试集。

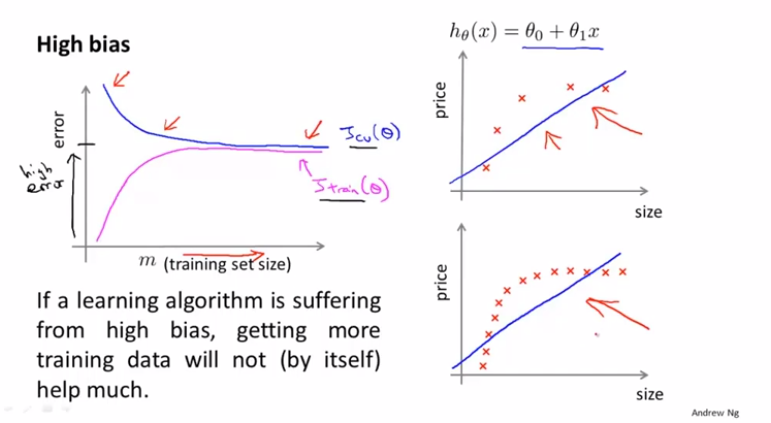
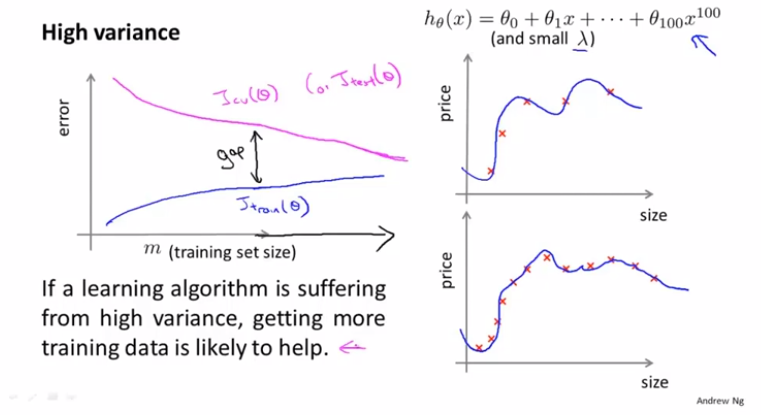
通过多项式的维度与训练集和验证集的误差可以画出上面的图形。如果多项式维度很低,训练集和测试集误差都很大,就叫做高偏差,即欠拟合。如果维度很高,训练集的误差很低,但是验证集误差很高,就叫做高方差,即过拟合。针对正则化λ也可以用这种方式进行选择:

当训练样本很少时,训练的模型在训练集上很容易就拟合出来,所以误差很小,随着训练样本的增加,误差也随之增加;对于验证集,由于最开始的样本很少,泛化能力很差,所以误差很高,随着样本的增加,验证集的效果越来越好。

针对于高偏差的情况,由于多项式维度很低,所以拟合出来的是一条直线。因此随着样本的增加,训练集的误差也会增加,但是最后会趋于稳定。此时,增加样本数量并没有什么作用。
针对于高方差的情况,增加样本则会帮助模型拟合的更好。
相关文章
- 机器学习算法在用户行为检测(UBA)领域的应用
- 台大《机器学习基石》课程感受和总结---Part 2 (转)
- linux机器之间拷贝和同步文件命令
- 数据分析/机器学习模型无法部署的八大原因
- 基于机器学习人脸识别face recognition具体的算法和原理
- 机器学习实战之PCA
- 【玩转数据系列八】机器学习算法的离线调度实现-广告CTR预测
- 机器学习入门11 - 逻辑回归 (Logistic Regression)
- 机器学习笔记 - 模式识别的应用场景之一简单车牌识别
- 机器学习笔记 - HaGRID—手势识别图像数据集简介
- 机器学习笔记 - 什么是元学习?
- 【玩转数据系列二】机器学习应用没那么难,这次教你玩心脏病预测
- Atitit 人工智能 统计学 机器学习的相似性 一些文摘收集 没有人工智能这门功课,人工智能的本质是统计学和数学,就是通过机器对数据的识别、计算、归纳和学习,然后做出下一步判断和决策的科学
- 部署在SAP Cloud Platform CloudFoundry环境的应用如何消费SAP Leonardo机器学习API
- DataScience:机器学习中特征工程之WOE编码(离散变量编码/有监督)的简介、计算过程、案例应用之详细攻略
- AI:2020年6月22日北京智源大会演讲分享之10:40-11:10Daniel教授《 可微分的加权有限状态机及其机器学习应用》、11:10何晓冬教授《启动“智源-京东”任务导向多模态对话大赛》
- ML与Information:信息论(信息熵/互信息/最大熵模型/条件熵/KL散度)在机器学习中的简介、主要内容、关系、常用方法、案例应用
- ML之ME/LF:机器学习之风控业务中常用模型监控指标CSI(特征稳定性指标)的简介、使用方法、案例应用之详细攻略
- DataScience:机器学习中特征工程之连续型变量离散化—变量分箱的简介、常用方法、案例应用(评分卡模型为例)之详细攻略
- 实战案例|基于机器学习的 Python 信用卡欺诈检测!
- 【机器学习】模型评估
- 应用机器学习的建议(Advice for Applying Machine Learning)
- 【机器学习项目实战】Python基于协同过滤算法进行电子商务网站用户行为分析及服务智能推荐
- OpenMLDB + Jupyter Notebook:快速搭建机器学习应用
- Andrew Ng-ML-第十章-应用机器学习的建议
- 【机器学习】逻辑回归和线性回归的区别?(面试回答)
- 【机器学习】7、聚类算法与应用
- 机器学习有哪些应用场景?具体有什么作用?
- 机器学习应用在哪些方向?机器学习应用实例