
selenium使用XPATH提取内容报错(已解决)
目录
一、说明
1.1、前言
背景:使用selenium,获取招工平台岗位要求与待遇信息出现报错
环境:windows 10家庭版
语言:python 3
模块:selenium
出现的问题:
selenium.common.exceptions.StaleElementReferenceException: Message: The element reference: element is not attached to the page document
意思是说节点陈旧,使用当前节点找不到信息,是否刷新啥的。
1.2、报错信息
完整报错信息如下:
selenium.common.exceptions.StaleElementReferenceException: Message: The element reference of <div class="item__10RTO"> is stale; either the element is no longer attached to the DOM, it is not in the current frame context, or the document has been refreshed
Stacktrace:
RemoteError@chrome://remote/content/shared/RemoteError.sys.mjs:8:8
WebDriverError@chrome://remote/content/shared/webdriver/Errors.sys.mjs:182:5
StaleElementReferenceError@chrome://remote/content/shared/webdriver/Errors.sys.mjs:463:5
element.resolveElement@chrome://remote/content/marionette/element.sys.mjs:674:11
evaluate.fromJSON@chrome://remote/content/marionette/evaluate.sys.mjs:255:31
evaluate.fromJSON@chrome://remote/content/marionette/evaluate.sys.mjs:263:29
evaluate.fromJSON@chrome://remote/content/marionette/evaluate.sys.mjs:263:29
receiveMessage@chrome://remote/content/marionette/actors/MarionetteCommandsChild.sys.mjs:74:34
1.3、报错代码
driver = Firefox() # 创建一个浏览器对象
driver.get("页面url") # 访问网页
# 访问页面后,出现登录或注册弹窗,影响下一步,所以要把弹窗关掉
# 右键检查,选项页面元素,直接复制xpath路径
driver.implicitly_wait(8)
# driver.switch_to.window(driver.window_handles[-1])
one_el = driver.find_element(By.XPATH, '//*[@id="cboxClose"]') # 定位标签位置,一般是打叉的位置
one_el.click() # 点击该位置,点击打叉也就是关闭弹窗
time.sleep(3)
# 在文本框输入内容,先定位,在输入值,敲回车或者点击搜索
driver.find_element(By.XPATH, '//*[@id="search_input"]').send_keys("python", Keys.ENTER)
all_li = driver.find_elements(By.XPATH, '/html/body/div/div[2]/div/div[2]/div[3]/div/div[1]/div')
for li in all_li:
job_name = li.find_element(By.XPATH, './div/div/div/a').text
job_time = li.find_element(By.XPATH, './div/div/div/span').text
job_price = li.find_element(By.XPATH, './div/div/div[2]/span').text
print(job_name, job_time, job_price)
二、解决
2.1、搜索引擎解决
1)首先是使用了搜索引擎进行问题的查找,大概明白了出现这个报错是什么原因(后面会讲),感谢热心网友分享;
2)尝试使用大部分网友分享的办法:使用try,except结构来进行页面的刷新,但是发现报的是一样的错误(此时已经加了延时)
这个办法在我这行不通。。。
2.2、最终解决
输入搜索内容后,进行延迟,确保页面内容可以完整出现,然后在进行刷新(关键是这个,这个刷新使节点更新了),在延迟,使内容完全加载,此时在进行节点与内容的获取。
代码如下:
driver = Firefox() # 创建一个浏览器对象
driver.get("页面url") # 访问网页
# 访问页面后,出现登录或注册弹窗,影响下一步,所以要把弹窗关掉
# 右键检查,选项页面元素,直接复制xpath路径
driver.implicitly_wait(8)
# driver.switch_to.window(driver.window_handles[-1])
one_el = driver.find_element(By.XPATH, '//*[@id="cboxClose"]') # 定位标签位置,一般是打叉的位置
one_el.click() # 点击该位置,点击打叉也就是关闭弹窗
time.sleep(3)
# 在文本框输入内容,先定位,在输入值,敲回车或者点击搜索
driver.find_element(By.XPATH, '//*[@id="search_input"]').send_keys("python", Keys.ENTER)
time.sleep(3) # 等待内容加载完成
driver.refresh() # 刷新页面,使节点刷新
time.sleep(3) # 等待页面加载完成,此时的节点才是正确的
all_li = driver.find_elements(By.XPATH, '/html/body/div/div[2]/div/div[2]/div[3]/div/div[1]/div')
# a = 1
for li in all_li:
job_name = li.find_element(By.XPATH, './div/div/div/a').text
job_time = li.find_element(By.XPATH, './div/div/div/span').text
job_price = li.find_element(By.XPATH, './div/div/div[2]/span').text
print(job_name, job_time, job_price)
结果如下图1:
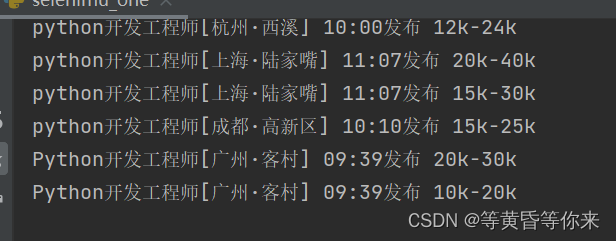
图1
程序能跑了,我不用跑了。
相关文章
- 使用selenium启动火狐浏览器,解决Unable to create new remote session问题
- 解决IDEA报错:无法检索应用程序 JMX 服务 URL[Failed to retrieve application JMX service URL]亲测可用
- SQL Developer 连接 oracle数据库 报错 Io 异常 The Network Adapter could not establish the connection的三种解决方法
- [转]让iframe自适应高度-真正解决
- 解决:Caused by: java.lang.ClassNotFoundException: org.springframework.core.metrics.ApplicationStartup
- Informix 启动 Fatal error in shared memory initialization解决方法
- CentOS Linux解决网卡报错Bringing up interface eth0.....
- VisionPro 报错解决方法
- 解决报错(Could not create connection to database server.)
- [转]Java compiler level does not match解决方法
- 解决nginx转发websocket报400错误
- SwiftUI基础教程之如何解决点击无响应问题扩大选择区域Button(教程含源码)
- macOS 苹果系统安装软件 提示app已损坏,无法打开如何解决
- 解决doubleselect的doubleheadervalue不起作用
- “代理 XP”组件已作为此服务器安全配置的一部分被关闭。解决方法
- redis运用连接池报错解决
- 浅析https引入http资源、什么是混合内容、报错已阻止载入混合活动内容的问题及解决
- KEIL编译报错,解决方法汇总
- FluorineFx 播放FLV 时堆棧溢出解决 FluorineFx NetStream.play 并发时,无法全部连接成功的解决办法
- 如何解决微信分享大图报错
- Oracle死锁解决方法
- 自动化测试如何解决验证码的问题
- [已解决]报错:Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop102:10000
- [未解决]yarn安装报错网络问题解决
- [已解决]报错: Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: '/Users/mac/Ana
- [已解决]报错:have mixed types. Specify dtype option on import or set low_memory=False
- [已解决]报错This event loop is already running
- curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection reset by peer解决
- Vue项目报错:Parsing error: Unexpected reserved word ‘await‘ 解决方法
- nodejs安装node-rsa遇到的问题及解决
- Vue开发实例(06)之Vue3注册Element-ui报错解决
- 在 Postman 中报错:Self-signed SSL certificates are being blocked 的分析与解决