
微服务注册中心比较(ZooKeeper/Eureka/Consul/Nacos)
2023-09-11 14:16:54 时间
1. 注册中心概念和定义
服务注册中心本质上是为了解耦服务提供者和服务消费者。对于任何一个微服务,原则上都应存在或者支持多个提供者,这是由微服务的分布式属性决定的。更进一步,为了支持弹性扩缩容特性,一个微服务的提供者的数量和分布往往是动态变化的,也是无法预先确定的。因此,原本在单体应用阶段常用的静态LB机制就不再适用了,需要引入额外的组件来管理微服务提供者的注册与发现,而这个组件就是服务注册中心
能够提供额外服务来管理微服务提供者的注册与发现的组件就是服务注册中心。
2. CAP理论
CAP理论是分布式架构中重要理论, 它包含:
- 一致性(Consistency)
所有节点在同一时间具有相同的数据
- 可用性(Availability)
保证每个请求不管成功或者失败都有响应
(某个系统的某个节点挂了,但是并不影响系统的接受或者发出请求)
- 分隔容忍(Partition tolerance)
系统中任意信息的丢失或失败不会影响系统的继续运作
(在整个系统中某个部分,挂掉了,或者宕机了,并不影响整个系统的运作或者说使用)
CAP不可能都满足
原因如下:
1. 如果C是第一需求的话,那么会影响A的性能。
因为要数据同步,不然请求结果会有差异,但是数据同步会消耗时间,可用性就会降低。
2. 如果A是第一需求,那么只要有一个服务在,就能正常接受请求。
但是对于返回结果便不能保证,原因是,在分布式部署的时候,数据一致的过程不可能像切线路那么快。
3. 如果同时满足一致性和可用性,那么分区容错就很难保证了。
但是CAP理论提出就是针对分布式数据库环境的,所以P这个属性是必须具备的。
P就是在分布式环境中,由于网络的问题可能导致某个节点和其它节点失去联系,这时候就形成了P(partition)。
3. 服务注册中心的主流解决方案
纵观当下的主流服务注册中心解决方案,大致可归为三类:
- 应用内
直接集成到应用中,依赖于应用自身完成服务的注册与发现(eg: Netflix Eureka -- 一站式解决方案)
- 应用外
把应用当成黑盒,通过应用外的某种机制将服务注册到注册中心,最小化对应用的侵入性
(eg:Airbnb的SmartStack,HashiCorp的Consul)
- DNS
将服务注册为DNS的SRV记录,严格来说,是一种特殊的应用外注册方式
(eg: SkyDNS是其中的代表, 由于DNS固有的缓存缺陷,这里不对第三类注册方式作深入探讨)
4. 各类注册中心产品详细介绍
Apache Zookeeper -> CP
Apache Zookeeper在设计时就紧遵CP原则。
任何时候对 Zookeeper 的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,
但是 Zookeeper 不能保证每次服务请求都是可达的。
Zookeeper适合的场景:
分布式数据存储
但是由于Zookeeper 不能保证服务可用性。
对于服务发现来说,情况就不太一样了,针对同一个服务,
即使注册中心的不同节点保存的服务提供者信息不尽相同,也并不会造成灾难性的后果。
因为对于服务消费者来说,能消费才是最重要的,
消费者虽然拿到可能不正确的服务实例信息后尝试消费一下,
也要胜过因为无法获取实例信息而不去消费,导致系统异常要好。
Spring Cloud Eureka -> AP
Netflix在设计Eureka时就紧遵AP原则(尽管现在2.0发布了,但是由于其闭源的原因, 目前 Ereka 1.x 任然是比较活跃的)
架构图:
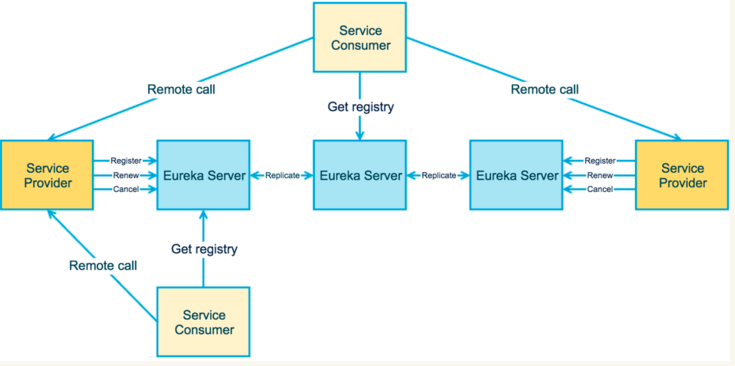
优点:
从设计角度来看,Eureka可以说是无懈可击,注册中心、提供者、调用者边界清晰<br>通过去中心化的集群支持保证了注册中心的整体可用性
缺点:
Eureka属于应用内的注册方式,对应用的侵入性太强,且只支持Java应用
Eureka Server 也可以运行多个实例来构建集群,解决单点问题。
但不同于 ZooKeeper 的选举 leader 的过程,Eureka Server 采用的是Peer to Peer 对等通信。
这是一种去中心化的架构,无 master/slave 之分,每一个 Peer 都是对等的。
在这种架构风格中,节点通过彼此互相注册来提高可用性,
每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。
每个节点都可被视为其他节点的副本。
在集群环境中如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点上,
当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。
当节点开始接受客户端请求时,所有的操作都会在节点间进行复制(Replicate To Peer)操作,
将请求复制到该 Eureka Server 当前所知的其它所有节点中。
当一个新的 Eureka Server 节点启动后,会首先尝试从邻近节点获取所有注册列表信息,并完成初始化。
Eureka Server 通过 getEurekaServiceUrls() 方法获取所有的节点,并且会通过心跳契约的方式定期更新。
默认情况下,如果 Eureka Server 在一定时间内没有接收到某个服务实例的心跳(默认周期为30秒),
Eureka Server 将会注销该实例
(默认为90秒, eureka.instance.lease-expiration-duration-in-seconds 进行自定义配置)。
当 Eureka Server 节点在短时间内丢失过多的心跳时,那么这个节点就会进入自我保护模式。
Eureka的集群中,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),
只不过查到的信息可能不是最新的(不保证强一致性)。
除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,
那么Eureka就认为客户端与注册中心出现了网络故障。
此时会出现以下几种情况:
1. Eureka不再从注册表中移除因为长时间没有收到心跳而过期的服务;
2. Eureka仍然能够接受新服务注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用);
3. 当网络稳定时,当前实例新注册的信息会被同步到其它节点中;
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,
而不会像zookeeper那样使得整个注册服务瘫痪。
Consul
Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。
Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X)。
架构图:
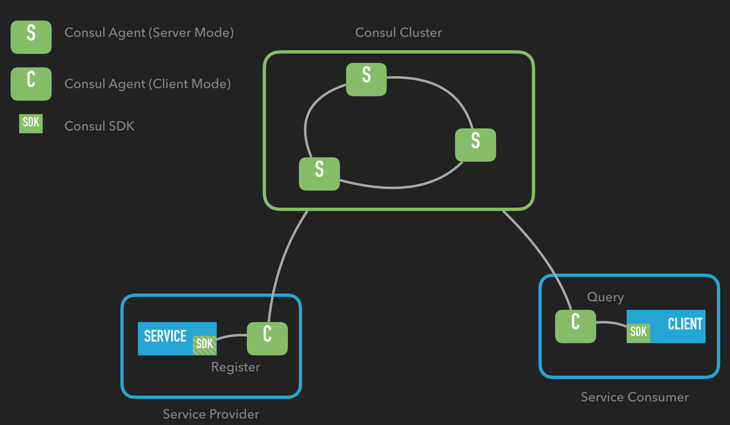
Consul本质上属于应用外的注册方式,但可以通过SDK简化注册流程。
而服务发现恰好相反,默认依赖于SDK,但可以通过Consul Template去除SDK依赖。
Consul 内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,
不再需要依赖其他工具(比如 ZooKeeper 等),使用起来也较为简单。
Consul 遵循CAP原理中的CP原则,保证了强一致性和分区容错性,
且使用的是Raft算法,比zookeeper使用的Paxos算法更加简单。
虽然保证了强一致性,但是可用性就相应下降了,
例如服务注册的时间会稍长一些,因为 Consul 的 raft 协议要求必须过半数的节点都写入成功才认为注册成功 ;
在leader挂掉了之后,重新选举出leader之前会导致Consul 服务不可用。
优点:
最小化对已有应用的侵入性
降低运维的复杂度(Consul Agent既可以运行在服务器模式,又可以运行在客户端模式)
缺点:
由于是实现了CP, A没有保证, 在leader挂掉了之后,重新选举出leader之前会导致Consul 服务不可用
Nacos
Nacos是阿里开源的,Nacos 支持基于 DNS 和基于 RPC 的服务发现。
Nacos = Spring Cloud注册中心 + Spring Cloud配置中心
优点:
同时支持AP和CP模式, 可以根据服务注册选择临时和永久来决定走AP模式还是CP模式
同时支持注册中心和配置中心
架构图:
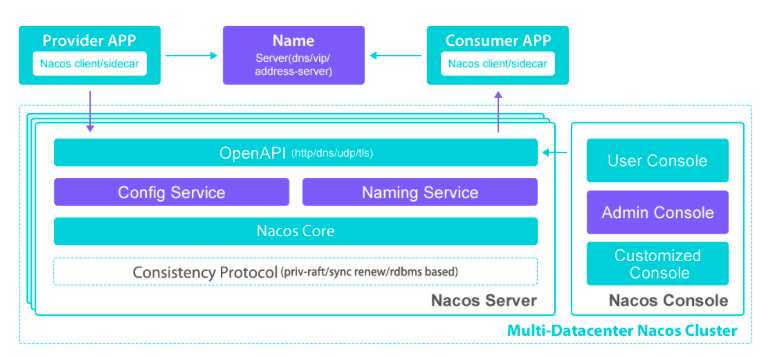
在Spring Cloud中使用Nacos,只需要先下载 Nacos 并启动 Nacos server,
Nacos只需要简单的配置就可以完成服务的注册发现。
相关文章
- SpringBoot2 整合Nacos组件,环境搭建和入门案例详解
- Springboot: 如何将服务注册到Nacos
- nacos设置开机自启动
- 谷粒商城Nacos配置(五)
- Nacos服务发现简单应用
- 【Nacos源码之配置管理 一】阅读源码第一步,本地启动Nacos
- Spring Cloud Alibaba 2.2.6发布:新增Nacos注册快速失败的配置
- Docker 中 部署 Nacos
- Windows下IDEA run能运行springboot,java -jar maven打的包拉有中文的nacos配置,报org.yaml.snakeyaml.error.YAMLException错误解决
- windows下启动nacos(单机配置)
- 【Spring Cloud】Nacos命名空间Namespace的介绍与使用
- 漏洞复现 - - - Alibaba Nacos权限认证绕过
- 综合对比ZooKeeper、Eureka、Consul 、Nacos等微服务注册中心,用途及优缺点分析