
Flink主要组件以及工作流程
Flink简介
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流(批处理和流处理)进行有状态计算。并且 Flink 提供了数据分布、容错机制以及资源管理等核心功能。
Flink提供了诸多高抽象层的API以便用户编写分布式任务:
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
根据官网的介绍,Flink 的特性包含:
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口 (Window) 操作
支持有状态计算的 Exactly-once 语义
支持高度灵活的窗口 (Window) 操作,支持基于 time、count、session 以及 data-driven 的窗口操作
支持具有 Backpressure 功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
Flink 在 JVM 内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存
Flink 相比传统的 Spark Streaming 有什么区别
Flink 是标准的实时处理引擎,基于事件驱动。而 Spark Streaming 是微批(Micro-Batch)的模型(每次处理一小批数据,一小批数据包含多个事件,以接近实时处理的效果)。
分几个方面介绍两个框架的主要区别:
1. 架构模型
Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
2. 任务调度
Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
3. 时间机制
Spark Streaming 支持的时间机制有限,只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
4. 容错机制
对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰好一次处理语义。Flink 则使用两阶段提交协议来解决这个问题。
备注:Storm是第一代流处理框架,数据吞吐量和延迟上的表现不尽如人意,并且只支持"at least once"和"at most once",即数据流里的事件投递只能保证至少一次或至多一次,不能保证只有一次,在数据准确性方面也存在不足。
Flink可以算是第三代流引擎框架,支持在有界和无界数据流上做有状态计算,以事件为单位,并且支持SQL、State、WaterMark等。它支持"exactly once",即事件投递保证只有一次,数据的准确性能得到提升。相比Storm,它吞吐量更高,延迟更低;相比Spark Streaming,Flink是真正意义上的实时计算,且所需计算资源相对更少。
flink处理时间优势劣势
优势:较低的延迟
劣势:1:无法正确处理历史数据 2:无法正确处理超过最大无序边界的数据 3:结果将是不确定的
在实际上的大数据平台应用当中,Flink也并非是完美的,作为计算引擎,Flink能满足绝大部分的数据处理需求,但是作为系统平台而言,Flink的缺点也是存在的,所以主流的趋势还是与其他平台例如Hadoop进行集成开发应用。
Flink基于数据有界和无界的思想,可支持流式和批量处理,但是决定性的优势仍然在流处理上,相比较而言在批处理上,Spark反而更具优势。
Flink组件
为了支持分布式运行,Flink跟其他大数据引擎一样,采用了主从(Master-Worker)架构。
Flink 程序在运行时主要有 TaskManager,JobManager,Client三种角色。其中JobManager扮演着集群中的管理者Master的角色,它是整个集群的协调者,负责接收Flink Job,协调检查点,Failover 故障恢复等,同时管理Flink集群中从节点TaskManager。
TaskManager是实际负责执行计算的Worker,在其上执行Flink Job的一组Task,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。一般地,一个Flink作业是分布在多个TaskManager上执行的,单个TaskManager上提供一定量的Slot。一个TaskManager启动后,相关Slot信息会被注册到ResourceManager中。当某个Flink作业提交后,ResourceManager会将空闲的Slot提供给JobManager。JobManager获取到空闲Slot信息后会将具体的计算任务部署到该Slot之上,任务开始在这些Slot上执行。在执行过程,由于要进行数据交换,TaskManager还要和其他TaskManager进行必要的数据通信.
总之,TaskManager负责具体计算任务的执行,启动时它会将Slot资源向ResourceManager注册。
Client是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。Client提交作业时需要配置一些必要的参数,比如使用Standalone集群还是YARN集群等。整个作业被打成了Jar包,DataStream API被转换成了
JobGraph,JobGraph是一种类似逻辑视图。
JobManager是单个Flink作业的协调者,一个作业会有一个JobManager来负责。JobManager会将Client提交的JobGraph转化为ExceutionGraph,ExecutionGraph是类似并行的物理执行图。JobManager会向ResourceManager申请必要的资源,当获取足够的资源后,JobManager将ExecutionGraph以及具体的计算任务分发部署到多个TaskManager上。同时,JobManager还负责管理多个TaskManager,这包括:收集作业的状态信息,生成检查点,必要时进行故障恢复等问题。 早期,Flink Master被命名为JobManager,负责绝大多数Master进程的工作。随着迭代和开发,出现了名为JobMaster的组件,JobMaster负责单个作业的执行。本书中,我们仍然使用JobManager的概念,表示负责单个作业的组件。一些Flink文档也可能使用JobMaster的概念,读者可以将JobMaster等同于JobManager看待
ResourceManager
Flink现在可以部署在Standalone、YARN或Kubernetes等环境上,不同环境中对计算资源的管理模式略有不同,Flink使用一个名为ResourceManager的模块来统一处理资源分配上的问题。在Flink中,计算资源的基本单位是TaskManager上的任务槽位(Task Slot,简称槽位Slot)。ResourceManager的职责主要是从YARN等资源提供方获取计算资源,当JobManager有计算需求时,将空闲的Slot分配给JobManager。当计算任务结束时,ResourceManager还会重新收回这些Slot。
Flink作业提交过程
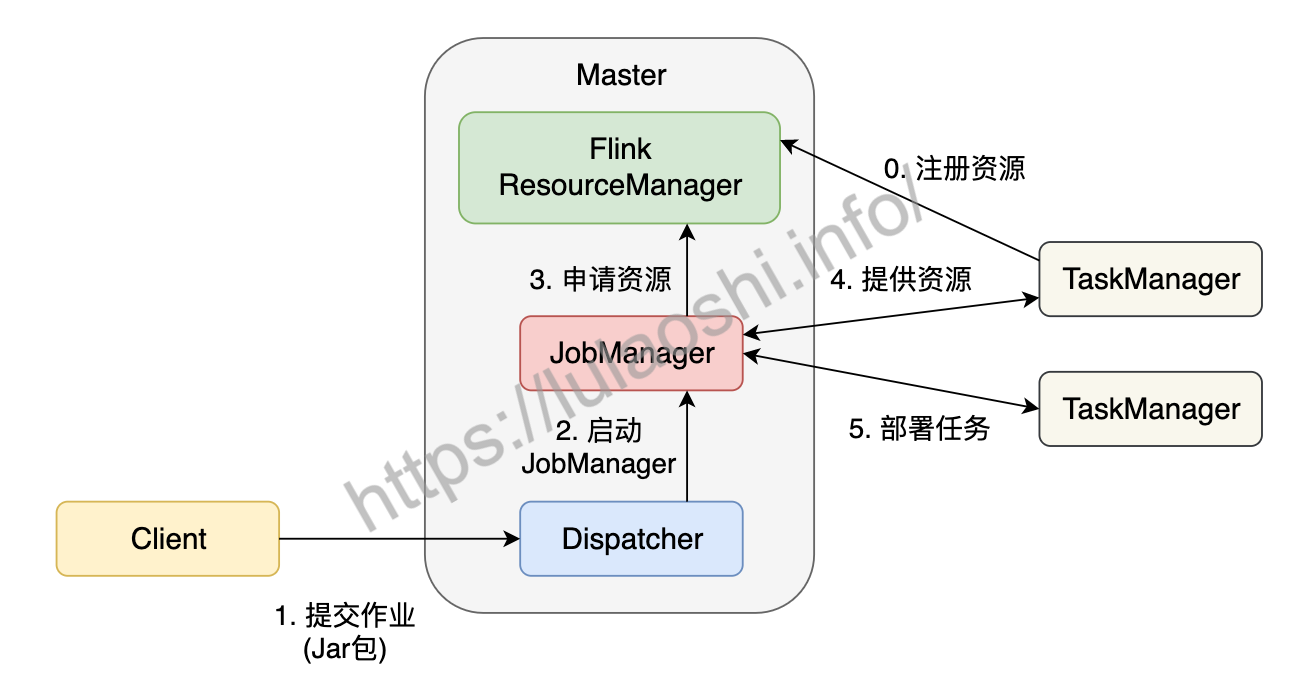
在一个作业提交前,Master和TaskManager等进程需要先被启动。我们可以在Flink主目录中执行脚本来启动这些进程:
bin/start-cluster.sh。Master和TaskManager被启动后,TaskManager需要将自己注册给Master中的ResourceManager。这个初始化和资源注册过程发生在单个作业提交前,我们称之为第0步。接下来我们根据上图,逐步分析一个Flink作业如何被提交:
用户编写应用程序代码,并通过Flink客户端(Client)提交作业。程序一般为Java或Scala语言,调用Flink API,构建逻辑视角数据流图。代码和相关配置文件被编译打包,被提交到Master的Dispatcher,形成一个应用作业(Application)。
Dispatcher接收到这个作业,启动JobManager,这个JobManager会负责本次作业的各项协调工作。
JobManager向ResourceManager申请本次作业所需资源。
由于在第0步中TaskManager已经向ResourceManager中注册了资源,这时闲置的TaskManager会被反馈给JobManager。
JobManager将用户作业中的逻辑视图转化为图所示的并行化的物理执行图,将计算任务分发部署到多个TaskManager上。至此,一个Flink作业就开始执行了。
TaskManager在执行计算任务过程中可能会与其他TaskManager交换数据,会使用图中的一些数据交换策略。同时,TaskManager也会将一些任务状态信息会反馈给JobManager,这些信息包括任务启动、运行或终止的状态,快照的元数据等。
Flink的时间有那几种

Flink在流处理程序中支持三种时间的概念,分别是EventTime(事件事件)、ProcessingTime(处理时间)、IngestionTime(摄入时间),Flink流式处理中,绝大部分的业务都会使用EventTime,一般只在EventTime无法使用时,考虑其他时间属性。
1:事件时间
Event Time(事件时间)是每个事件在产生它的设备上发生的时间。在进入 Flink 之前,事件时间通常要嵌入到记录中,并且事件时间也可以从记录中提取出来。对于事件时间,时间的进度取决于数据,而不是系统时钟。基于事件时间的程序必须指定如何生成事件时间的Watermarks,这是表示事件时间进度的机制。
在理想情况下,事件时间处理将产生完全一致且确定的结果,无论事件何时到达以及以什么样的顺序到达。但是,除非已知事件是按顺序(按时间戳)到达,否则事件时间处理在等待无序事件时产生一定的延迟。由于只能等待有限的时间,因此这限制了事件时间应用程序的确定性。
假定所有数据都已到达,事件时间算子将按预期方式运行,即使在处理无序、迟到事件或重新处理历史数据时,也会产生正确且一致的结果。例如,每小时事件时间窗口将将处理事件时间在这一小时之内所有的记录,不管它们何时到达,以及它们以什么顺序到达。
按事件时间处理往往会导致一定的延迟,因为它要等待延迟事件和无序事件一段时间。因此,事件时间程序通常与处理时间操作相结合使用
2:摄入时间
Ingestion Time(摄入时间)是事件进入Flink的时间。在 Source 算子中,每个记录将 Source 的当前时间记为时间戳,基于时间的操作(如时间窗口)会使用该时间戳。
摄入时间在概念上处于事件时间和处理时间之间。与处理时间相比,摄入时间的成本稍微更高一些,但是可以提供更可预测的结果。因为摄入时间的时间戳比较稳定(在 Source 处只记录一次),同一数据在流经不同窗口操作时将使用相同的时间戳,然而对于处理时间,每个窗口算子可能将记录分配给不同的窗口(基于本地系统时钟以及传输延迟)。与事件时间相比,摄入时间程序无法处理任何无序事件或延迟事件,但程序不必指定如何生成watermarks。
在内部,摄入时间与事件时间非常相似,但事件时间会自动分配时间戳以及自动生成watermark。
3: 处理时间
Processing Time(处理时间)是指执行相应操作的机器系统时间,是操作算子在计算过程中获取到的所在主机的系统时间。当用户选择使用处理时间时,所有和时间相关的算子,例如 Windows 计算,在当前任务中所有的算子直接使用所在主机的系统时间。例如,一个基于处理时间按每小时进行处理的时间窗口将处理一个小时内(以系统时间为标准)到达指定算子的所有的记录。
处理时间是最简单的一个时间概念,不需要在数据流和机器之间进行协调。具有最好的性能和最低的延迟。然而,在分布式或者异步环境中,处理时间具有不确定性,因为容易受到记录到达系统速度的影响(例如,从消息队列到达的记录),还会受到系统内记录在不同算子之间的流动速度的影响。对数据乱序的处理,处理时间不是一种最优的选择。
总之,处理时间适用于时间计算精度要求不是特别高的计算场景。
Flink DataStream 程序的第一部分通常设置基本的时间特性。该设置定义数据流源的行为方式(例如,它们是否产生时间戳),以及窗口操作如
KeyedStream.timeWindow(Time.seconds(30))应使用哪一类型的时间,是事件时间还是处理时间等。
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();//Flink默认
ProcessingTimeenv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
flink重启策略
Flink 实现了多种重启策略。
固定延迟重启策略(Fixed Delay Restart Strategy)
故障率重启策略(Failure Rate Restart Strategy)
没有重启策略(No Restart Strategy)
Fallback重启策略(Fallback Restart Strategy)
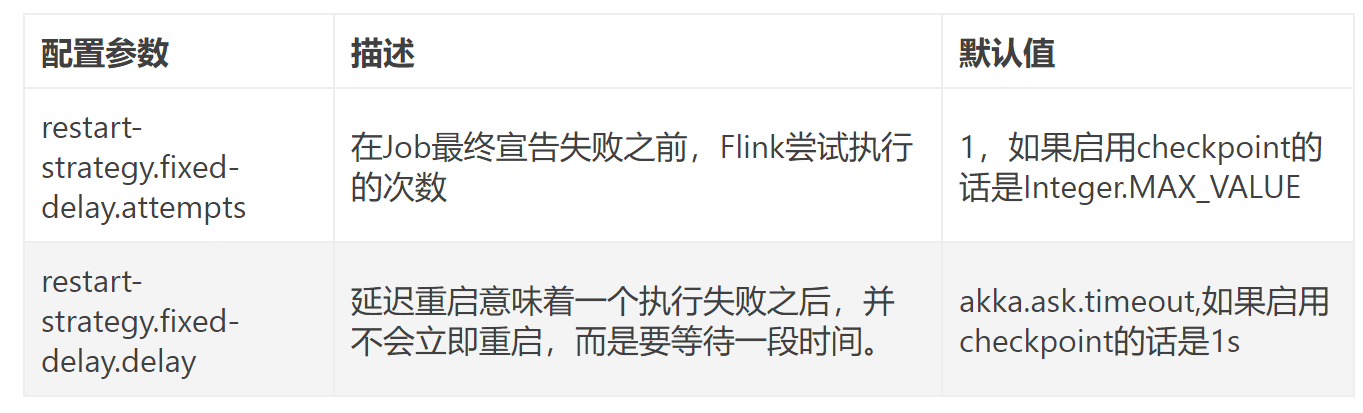
默认的重启策略是通过Flink的flink-conf.yaml来指定的,这个配置参数restart-strategy定义了哪种策略会被采用。如果checkpoint未启动,就会采用no restart策略,
如果启动了checkpoint机制,但是未指定重启策略的话,就会采用fixed-delay策略,
重试Integer.MAX_VALUE次。请参考上面的可用重启策略来了解哪些值是支持的。除了定义一个默认的重启策略之外,你还可以为每一个Job指定它自己的重启策略,这个重启策略可以在ExecutionEnvironment中调用setRestartStrategy()方法来程序化地调用,主意这种方式同样适用于StreamExecutionEnvironment。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启次数
Time.of(10, TimeUnit.SECONDS) // 延迟时间间隔
));
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 srestart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
相关文章
- AUTOSAR开发流程中解析诊断功能
- pycharm 配置pep8安装流程
- 配置Flink依赖的pom文件时报错:flink-clients_2.11 & flink-streaming-java_2.11
- 2022年全国大学生智能汽车竞赛西部赛 竞赛方案与实施流程
- HBuilder 打包流程
- 如何跨行汇款?搞明白跨行转账汇款处理流程
- 【源码学习】事件分发流程源码分析
- 《Android游戏开发详解》——第1章,第1.7节控制流程第1部分——if和else语句
- Flink 的Window 操作(基于flink 1.3描述)
- 买新车流程
- 浅析分布式一致性算法 - Raft算法:定义、为什么需要一致性、强/弱一致性分类区别、raft三种状态、领导选举算法流程、日志复制流程、安全选举限制、如何解决split brain的问题
- 微信小程序开发之授权登录流程
- HI3518E用J-link烧写裸板fastboot u-boot流程
- 【大数据】Flink运行时架构,任务提交流程,调度原理详细指南,包括脑图总结(建议收藏哦)
- Laravel 5系列教程二:路由,视图,控制器工作流程
- 码农的自我修养 - 程序的流程控制