
干货|机器学习-感知机perceptron
2023-09-11 14:16:13 时间

定义

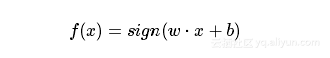
称为感知机。其中,参数w叫做权值向量weight,b称为偏置bias。w⋅x表示w和x的点积
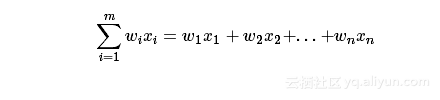 sign为符号函数,即
sign为符号函数,即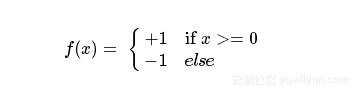 在二分类问题中,f(x)的值(+1或-1)用于分类x为正样本(+1)还是负样本(-1)。感知机是一种线性分类模型,属于判别模型。我们需要做的就是找到一个最佳的满足w⋅x+b=0的w和b值,即分离超平面(separating hyperplane)。如下图,一个线性可分的感知机模型
在二分类问题中,f(x)的值(+1或-1)用于分类x为正样本(+1)还是负样本(-1)。感知机是一种线性分类模型,属于判别模型。我们需要做的就是找到一个最佳的满足w⋅x+b=0的w和b值,即分离超平面(separating hyperplane)。如下图,一个线性可分的感知机模型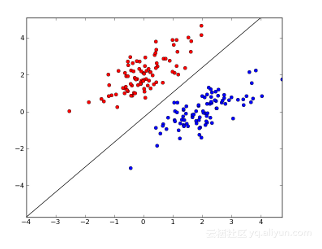 中间的直线即w⋅x+b=0这条直线。线性分类器的几何表示有:直线、平面、超平面。
中间的直线即w⋅x+b=0这条直线。线性分类器的几何表示有:直线、平面、超平面。学习策略
核心:极小化损失函数。如果训练集是可分的,感知机的学习目的是求得一个能将训练集正实例点和负实例点完全分开的分离超平面。为了找到这样一个平面(或超平面),即确定感知机模型参数w和b,我们采用的是损失函数,同时并将损失函数极小化。
对于损失函数的选择,我们采用的是误分类点到超平面的距离(可以自己推算一下,这里采用的是几何间距,就是点到直线的距离):
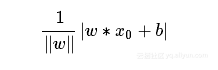 其中||w||是L2范数。
其中||w||是L2范数。对于误分类点(xi,yi)来说:
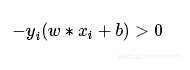 误分类点到超平面的距离为:
误分类点到超平面的距离为: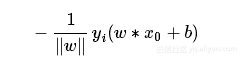 那么,所有点到超平面的总距离为:
那么,所有点到超平面的总距离为: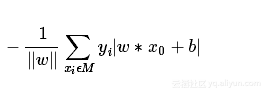

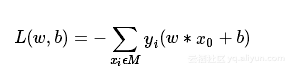
其中M为误分类的集合。这个损失函数就是感知机学习的经验风险函数。
可以看出,随时函数L(w,b)是非负的。如果没有误分类点,则损失函数的值为0,而且误分类点越少,误分类点距离超平面就越近,损失函数值就越小。同时,损失函数L(w,b)是连续可导函数。
学习算法
感知机学习转变成求解损失函数L(w,b)的最优化问题。最优化的方法是随机梯度下降法(stochastic gradient descent),这里采用的就是该方法。关于梯度下降的详细内容,参考wikipedia Gradient descent。下面给出一个简单的梯度下降的可视化图: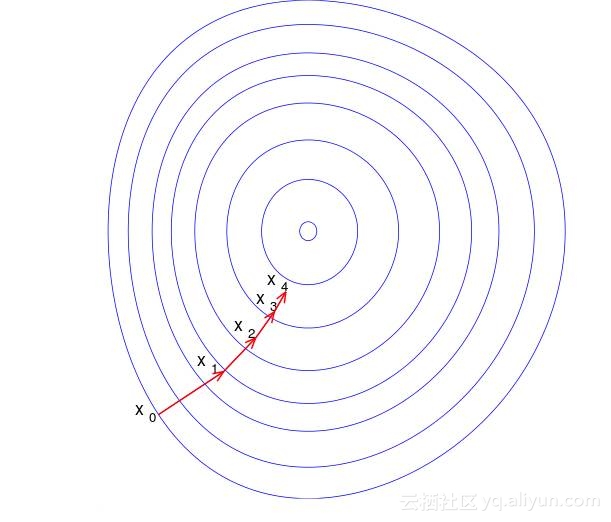
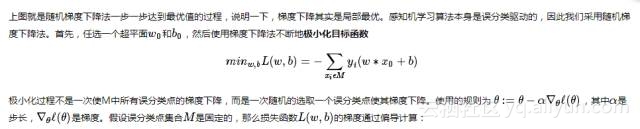

其中η是步长,大于0小于1,在统计学习中称之为学习率(learning rate)。这样,通过迭代可以期待损失函数L(w,b)不断减小,直至为0.
下面给出一个感知器学习的图,比较形象:
 由于上图采取的损失函数不同,所以权值的变化式子有点区别,不过思想都是一样的。
由于上图采取的损失函数不同,所以权值的变化式子有点区别,不过思想都是一样的。算法描述如下:
算法:感知机学习算法原始形式

解释:当一个实例点被误分类时,调整w,b,使分离超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直至超越该点被正确分类。伪代码描述:

对于每个w⋅x其实是这样子的(假设x表示的是七维):
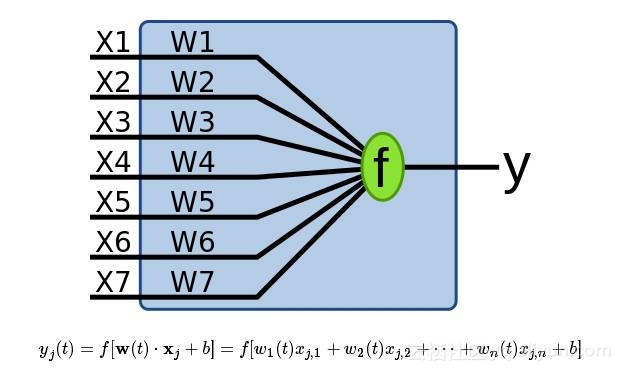
对于输入的每个特征都附加一个权值,然后将相加得到一个和函数f,最后该函数的输出即为输出的y值。
实例
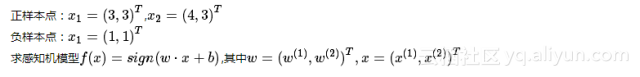
解答思路:根据上面讲解的,写初始化权值w和偏置b,然后一步一步的更新权值,直到所有的点都分正确为止。
解:(1) 令w0=0,b0=0
(2) 随机的取一个点,如x1,计算y1(w0⋅x1+b0),结果为0,表示未被正确分类,根据下面的式子更新w,b(此例中,我们将学习率η设置为1):
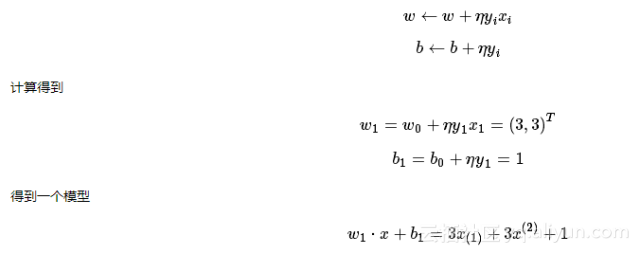

最后求得
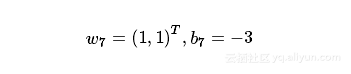
所以感知机模型为:
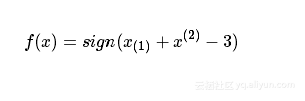
即我们所求的感知机模型。
小结
感知器Perceptron在机器学习当中是相当重要的基础,理解好感知器对后面的SVM和神经网络都有很大的帮助。事实上感知器学习就是一个损失函数的最优化问题,这里采用的是随机梯度下降法来优化。好吧,对于感知机的介绍,就到此为止!在复习的过程中顺便做下笔记,搜搜资料,整理整理,也算是给自己一个交代吧。希望本文章能对大家能有点帮助。
References
[1] 统计学习方法, 李航 著
[2] Wikiwand之Perceptron http://www.wikiwand.com/en/Perceptron
[3] Wikipedia https://en.wikipedia.org/wiki/Machine_learning
原文链接:http://blog.csdn.net/dream_angel_z/article/details/48915561
相关文章链接:https://www.52ml.net/15104.html
本文来源于"中国人工智能学会",原文发表时间" 2016-09-08"
python机器学习数据建模与分析——数据预测与预测建模 机器学习的预测建模在多个领域都具有重要的应用价值,包括个性化推荐、商品搜索、自动驾驶、人脸识别等。本篇文章将带领大家了解什么是预测建模
python机器学习——朴素贝叶斯算法笔记详细记录 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier 或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
python机器学习课程——决策树全网最详解超详细笔记附代码 决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。决策树方法最早产生于上世纪60年代,到70年代末。由J Ross Quinlan提出了ID3算法,此算法的目的在于减少树的深度。但是忽略了叶子数目的研究。C4.5算法在ID3算法的基础上进行了改进,对于预测变量的缺值处理、剪枝技术、派生规则等方面作了较大改进,既适合于分类问题,又适合于回归问题。决策树算法构造决策
python机器学习数据建模与分析——决策树详解及可视化案例 你是否玩过二十个问题的游戏,游戏的规则很简单:参与游戏的一方在脑海里想某个事物,其他参与者向他提问题,只允许提20个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围。决策树的工作原理与20个问题类似,用户输人一系列数据,然后给出游戏的答案。我们经常使用决策树处理分类问题,近来的调查表明决策树也是最经常使用的数据挖掘算法。它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它是如何工作的。
相关文章
- 神经网络与机器学习 笔记—小规模和大规模学习问题
- 神经网络与机器学习 笔记—时序模式、非线性滤波
- 神经网络与机器学习 笔记—Rosenblatt感知机
- 李宏毅机器学习_9-半监督学习
- (《机器学习》完整版系列)第2章 模型评估与选择 ——2.5 代价的曲线美
- 隆重介绍恩智浦MCU机器学习教育套件——OpenART
- 【FPGA教程案例94】机器学习1——基于FPGA的SVM支持向量机二分类系统实现之理论和MATLAB仿真
- 大疆笔试——机器学习提前批
- 深度学习机器学习面试题——GAN
- 机器学习笔记之变分推断(五)重参数化技巧
- 机器学习在互联网金融中的应用
- 《机器学习与R语言(原书第2版)》一 第2章 数据的管理和理解
- 演讲实录丨丨Young-Jo Cho 基于网络的机器智能机器人技术的发展
- 谷歌发布基于机器学习的Android APP安全检测系统:Google Play Protect
- 集成华为机器学习服务(ML Kit)轻松打造爆款小游戏
- 超详细!上线一个机器学习项目你需要哪些准备?
- 【机器学习】机器学习的经典算法
- 【干货】机器学习中的五种回归模型及其优缺点
- Android平台中的三种翻页效果机器实现原理
- 深入浅出的人工智能、机器学习和深度学习的技术原理和延伸应用
- Python3 机器学习之计算香农熵
- 《Scala机器学习》一一1.2 去除分类字段的重复值
- 《Scala机器学习》一一第2章 数据管道和建模
- 为什么做机器学习的很少使用假设检验? (转载)
- 大数据与机器学习:实践方法与行业案例.2.3 ETL
- AI学习--机器学习概述
- 【HMS core】【ML Kit】机器学习服务常见问题FAQ(二)
- 机器学习原来如此有趣!全世界最简单的机器学习入门指南
- Ingenu宣布将联合MEC Telematik推出覆盖整个中东的机器网络
- GyoiThon:基于机器学习的渗透测试工具