
机器学习笔记之变分推断(五)重参数化技巧
机器学习笔记之变分推断——重参数化技巧
引言
上一节介绍了随机梯度变分推断(Stochastic Gradient Variational Inference,SGVI)。本节将介绍SGVI求解过程中遇到的问题,并针对为题介绍一种处理方法——重参数化技巧。
回顾:随机梯度变分推断
由于基于平均场假设的经典变分推断(Classical Variational Inference)的假设条件非常苛刻,基本无法在真实环境中使用。
因此,介绍了随机梯度变分推断,从 P ( Z ∣ X ) P(\mathcal Z \mid \mathcal X) P(Z∣X)整体角度进行求解。
SGVI的核心是将分布
Q
(
Z
)
\mathcal Q(\mathcal Z)
Q(Z)视为概率模型,既然是概率模型,自然存在描述概率模型的模型参数。
这里定义
Q
(
Z
)
\mathcal Q(\mathcal Z)
Q(Z)的模型参数为
ϕ
\phi
ϕ,将求解
Q
(
Z
)
\mathcal Q(\mathcal Z)
Q(Z)的梯度转化为求解模型参数
ϕ
\phi
ϕ的梯度。
实际上,
Q
(
Z
)
\mathcal Q(\mathcal Z)
Q(Z)本身并不是‘隐变量的边缘概率分布’,而是条件概率分布
Q
(
Z
∣
X
)
\mathcal Q(\mathcal Z \mid \mathcal X)
Q(Z∣X)。只是
X
\mathcal X
X是观测数据,是已知量,因此省略。
Q
(
Z
)
→
Q
(
Z
∣
ϕ
)
L
[
Q
(
Z
)
]
=
∫
Z
∣
ϕ
Q
(
Z
∣
ϕ
)
⋅
log
[
P
(
X
,
Z
)
Q
(
Z
∣
ϕ
)
]
d
Z
=
L
(
ϕ
)
\mathcal Q(\mathcal Z) \to \mathcal Q(\mathcal Z \mid \phi) \\ \begin{aligned} \mathcal L[\mathcal Q(\mathcal Z)] & = \int_{\mathcal Z \mid \phi} \mathcal Q(\mathcal Z \mid \phi) \cdot \log \left[\frac{P(\mathcal X ,\mathcal Z)}{\mathcal Q(\mathcal Z \mid \phi)}\right] d\mathcal Z\\ & = \mathcal L(\phi) \end{aligned}
Q(Z)→Q(Z∣ϕ)L[Q(Z)]=∫Z∣ϕQ(Z∣ϕ)⋅log[Q(Z∣ϕ)P(X,Z)]dZ=L(ϕ)
随后
L
(
ϕ
)
\mathcal L(\phi)
L(ϕ)对
ϕ
\phi
ϕ求解梯度,最终化简结果如下:
∇
ϕ
L
(
ϕ
)
=
E
Q
(
Z
∣
ϕ
)
{
∇
ϕ
log
Q
(
Z
∣
ϕ
)
⋅
[
l
o
g
P
(
X
,
Z
)
−
log
Q
(
Z
∣
ϕ
)
]
}
\nabla_{\phi} \mathcal L(\phi) = \mathbb E_{\mathcal Q(\mathcal Z \mid \phi)} \left\{ \nabla_{\phi} \log \mathcal Q(\mathcal Z \mid \phi) \cdot \left[log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi)\right] \right\}
∇ϕL(ϕ)=EQ(Z∣ϕ){∇ϕlogQ(Z∣ϕ)⋅[logP(X,Z)−logQ(Z∣ϕ)]}
至此,将梯度结果
∇
ϕ
L
(
ϕ
)
\nabla_{\phi}\mathcal L(\phi)
∇ϕL(ϕ)表示为期望形式,后续操作可以通过蒙特卡洛采样方法对期望结果进行估计。
假设从 概率模型
P
(
Z
∣
ϕ
)
P(\mathcal Z \mid \phi)
P(Z∣ϕ)中采集了
N
N
N个样本。即:
z
(
n
)
∼
Q
(
Z
∣
ϕ
)
(
n
=
1
,
2
,
⋯
,
N
)
z^{(n)} \sim \mathcal Q(\mathcal Z \mid \phi) \quad (n=1,2,\cdots,N)
z(n)∼Q(Z∣ϕ)(n=1,2,⋯,N)
上述期望使用蒙特卡洛采样方法近似表示为:
∇
ϕ
L
(
ϕ
)
≈
1
N
∑
n
=
1
N
{
∇
ϕ
log
Q
(
z
(
n
)
∣
ϕ
)
[
log
P
(
X
,
z
(
n
)
)
−
log
Q
(
z
(
n
)
∣
ϕ
)
]
}
\nabla_{\phi}\mathcal L(\phi) \approx \frac{1}{N} \sum_{n=1}^{N} \left\{\nabla_{\phi} \log \mathcal Q(z^{(n)} \mid \phi) \left[ \log P(\mathcal X,z^{(n)}) - \log \mathcal Q(z^{(n)} \mid \phi)\right]\right\}
∇ϕL(ϕ)≈N1n=1∑N{∇ϕlogQ(z(n)∣ϕ)[logP(X,z(n))−logQ(z(n)∣ϕ)]}
随机梯度变分推断的问题
公式推导方式本身没有问题,问题在于采样过程中出现的高方差现象(High Variance)。该现象产生的具体原因如下:
-
观察基于蒙特卡洛方法的近似公式,大括号内主要包含两项,两项均包含 z ( n ) z^{(n)} z(n)。观察第一项:
∇ ϕ log Q ( z ( n ) ∣ ϕ ) \nabla_{\phi} \log \mathcal Q(z^{(n)} \mid\phi) ∇ϕlogQ(z(n)∣ϕ) -
注意,该项并不是求解 log Q ( z ( n ) ∣ ϕ ) \log \mathcal Q(z^{(n)} \mid \phi) logQ(z(n)∣ϕ)的结果,而是该结果的梯度。 Q ( z ( n ) ∣ ϕ ) \mathcal Q(z^{(n)} \mid \phi) Q(z(n)∣ϕ)是一个 描述概率的函数,因此它的值域是 ( 0 , 1 ) (0,1) (0,1)。观察 log Q ( z ( n ) ∣ ϕ ) \log \mathcal Q(z^{(n)} \mid \phi) logQ(z(n)∣ϕ)在 ( 0 , 1 ) (0,1) (0,1)范围内的结果以及梯度分别表示如下:
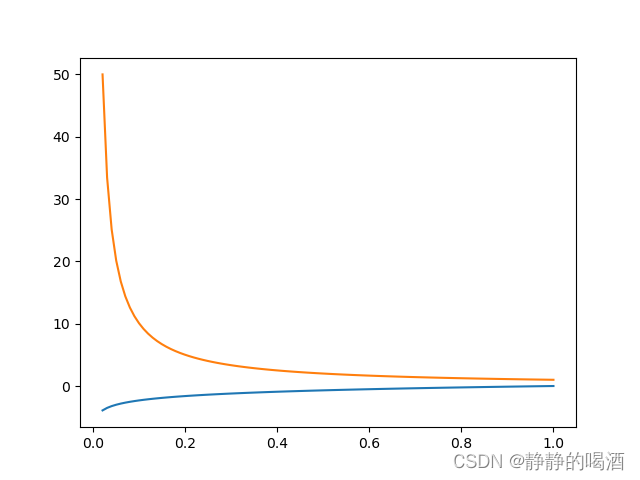
其中橙色线表示梯度,蓝色线表示数值结果。由于 从 Q ( Z ∣ ϕ ) \mathcal Q(\mathcal Z \mid \phi) Q(Z∣ϕ)中采样 z z z是纯随机采样,对应的结果 Q ( z ∣ ϕ ) \mathcal Q(z \mid \phi) Q(z∣ϕ)也必然是 ( 0 , 1 ) (0,1) (0,1)范围内的随机结果。那么对于极小的 Q ( z ∣ ϕ ) \mathcal Q(z \mid \phi) Q(z∣ϕ)结果对应的梯度反而是极高的数值。因此,采集出的样本中会存在少数数值极高的结果,从而对 ∇ ϕ L ( ϕ ) \nabla_{\phi} \mathcal L(\phi) ∇ϕL(ϕ)的近似计算产生更大的误差。本身通过蒙特卡洛方法求出的 ∇ ϕ L ( ϕ ) \nabla_{\phi} \mathcal L(\phi) ∇ϕL(ϕ)在梯度下降算法过程中就存在一定误差;如果 ∇ ϕ L ( ϕ ) \nabla_{\phi} \mathcal L(\phi) ∇ϕL(ϕ)也存在较大误差,这种误差叠加的结果自然使 Q ( Z ∣ ϕ ) \mathcal Q(\mathcal Z \mid \phi) Q(Z∣ϕ)的模型参数 ϕ \phi ϕ更加 难以保证其准确性。
至此,需要寻找方法,降低数据采样的高方差问题(Variance Reduction)。
本节将介绍通过重参数化技巧(Reparameterization Trick)来降低采样结果的高方差问题。
重参数化技巧
在对某概率分布 Q ( Z ) \mathcal Q(\mathcal Z) Q(Z)进行采样的过程中,如果直接从 Q ( Z ) \mathcal Q(\mathcal Z) Q(Z)中进行采样,可能出现高方差问题。
重参数化技巧的具体思想是:
已知条件:
随机变量
z
z
z服从概率分布
Q
(
z
∣
ϕ
)
\mathcal Q(z \mid \phi)
Q(z∣ϕ)。
- 随机变量
ϵ
\epsilon
ϵ服从某一分布
P
(
ϵ
)
\mathcal P(\epsilon)
P(ϵ),并且
ϵ
\epsilon
ϵ与
z
z
z之间存在如下关系:
z = G ( ϵ , X ∣ ϕ ) z = \mathcal G (\epsilon,\mathcal X \mid \phi) z=G(ϵ,X∣ϕ) - 此时,可以通过对概率分布 P ( ϵ ) \mathcal P(\epsilon) P(ϵ)进行采样,通过与 ϵ \epsilon ϵ在 P ( ϵ ) \mathcal P(\epsilon) P(ϵ)中的期望间接求解 z z z在概率分布 Q ( z ∣ ϕ ) \mathcal Q(z \mid \phi) Q(z∣ϕ)的期望结果。
示例:假设随机变量
z
z
z服从均值为
μ
\mu
μ,方差为
σ
2
\sigma^2
σ2的高斯分布:
z
∼
N
(
μ
,
σ
2
)
z \sim \mathcal N(\mu,\sigma^2)
z∼N(μ,σ2)
此时,想要求解上述概率分布下,关于
z
z
z的函数
f
(
z
)
f(z)
f(z)的期望结果:
E
P
(
z
)
[
f
(
z
)
]
\mathbb E_{\mathcal P(z)} [f(z)]
EP(z)[f(z)]
此时,存在一个随机变量
ϵ
\epsilon
ϵ,该变量服从于均值为0,方差为1的高斯分布:
ϵ
∼
N
(
0
,
1
)
\epsilon \sim \mathcal N(0,1)
ϵ∼N(0,1)
如何通过对
ϵ
\epsilon
ϵ进行采样从而对
E
P
(
z
)
[
f
(
z
)
]
\mathbb E_{\mathcal P(z)}[f(z)]
EP(z)[f(z)]进行求解?根据重参数化技巧,这里需要一个
z
z
z和
ϵ
\epsilon
ϵ之间的关联关系:
z
=
G
(
ϵ
)
=
μ
+
σ
×
ϵ
z = \mathcal G(\epsilon) = \mu + \sigma \times \epsilon
z=G(ϵ)=μ+σ×ϵ
E P ( z ) [ f ( z ) ] \mathbb E_{\mathcal P(z)}[f(z)] EP(z)[f(z)]的求解过程如下:
- 将
E
P
(
z
)
[
f
(
z
)
]
\mathbb E_{\mathcal P(z)}[f(z)]
EP(z)[f(z)]展开为积分形式,并将
P
(
z
)
\mathcal P(z)
P(z)的 概率密度函数带入公式中:
E P ( z ) [ f ( z ) ] = ∫ z P ( z ) f ( z ) d z = ∫ z ( 1 2 π σ e − ( z − μ ) 2 2 σ 2 ) ⋅ f ( z ) d z \begin{aligned} \mathbb E_{\mathcal P(z)}[f(z)] & = \int_{z} \mathcal P(z) f(z) dz \\ & = \int_z \left(\frac{1}{\sqrt{2\pi} \sigma} e^{-\frac{(z - \mu)^2}{2\sigma^2}}\right) \cdot f(z) dz \end{aligned} EP(z)[f(z)]=∫zP(z)f(z)dz=∫z(2πσ1e−2σ2(z−μ)2)⋅f(z)dz - 将
z
=
G
(
ϵ
)
z = \mathcal G(\epsilon)
z=G(ϵ)带入上式:
∫ ϵ ( 1 2 π σ e − ( μ + σ ⋅ ϵ − μ ) 2 2 σ 2 ) f [ G ( ϵ ) ] d [ G ( ϵ ) ] \int_{\epsilon} \left(\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(\mu + \sigma \cdot \epsilon - \mu)^2}{2\sigma^2}}\right) f \left[\mathcal G(\epsilon)\right] d[\mathcal G(\epsilon)] ∫ϵ(2πσ1e−2σ2(μ+σ⋅ϵ−μ)2)f[G(ϵ)]d[G(ϵ)] - 继续展开,得到如下结果:
E P ( z ) [ f ( z ) ] = ∫ ϵ ( 1 2 π σ e − ( μ + σ ⋅ ϵ − μ ) 2 2 σ 2 ) f [ G ( ϵ ) ] ⋅ σ d ϵ = ∫ ϵ 1 2 π e − ϵ 2 2 f [ G ( ϵ ) ] d ϵ ( 1 2 π e − ϵ 2 2 → N ( 0 , 1 ) → P ( ϵ ) ) = ∫ ϵ P ( ϵ ) f [ G ( ϵ ) ] d ϵ = E P ( ϵ ) [ f [ G ( ϵ ) ] ] \begin{aligned} \mathbb E_{\mathcal P(z)}[f(z)] & = \int_{\epsilon} \left(\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(\mu + \sigma \cdot \epsilon - \mu)^2}{2\sigma^2}}\right) f \left[\mathcal G(\epsilon)\right] \cdot \sigma d\epsilon \\ & = \int_{\epsilon} \frac{1}{\sqrt{2\pi}} e^{-\frac{\epsilon^2}{2}} f[\mathcal G(\epsilon)] d\epsilon \quad \left(\frac{1}{\sqrt{2\pi}} e^{-\frac{\epsilon^2}{2}} \to \mathcal N(0,1) \to \mathcal P(\epsilon)\right) \\ & = \int_{\epsilon} \mathcal P(\epsilon) f[\mathcal G(\epsilon)]d\epsilon \\ & = \mathbb E_{\mathcal P(\epsilon)} [f[\mathcal G(\epsilon)]] \end{aligned} EP(z)[f(z)]=∫ϵ(2πσ1e−2σ2(μ+σ⋅ϵ−μ)2)f[G(ϵ)]⋅σdϵ=∫ϵ2π1e−2ϵ2f[G(ϵ)]dϵ(2π1e−2ϵ2→N(0,1)→P(ϵ))=∫ϵP(ϵ)f[G(ϵ)]dϵ=EP(ϵ)[f[G(ϵ)]]
至此,我们将 随机变量为 z z z的期望转化为随机变量为 ϵ \epsilon ϵ的期望形式。
更泛化地说,只要
Q
(
z
)
\mathcal Q(z)
Q(z)和
P
(
ϵ
)
\mathcal P(\epsilon)
P(ϵ)之间满足如下关系:
Q
(
z
)
=
∫
δ
[
z
−
G
(
ϵ
,
X
∣
ϕ
)
]
P
(
ϵ
)
d
ϵ
\mathcal Q(z) = \int \delta[z - \mathcal G(\epsilon,\mathcal X \mid \phi)] \mathcal P(\epsilon) d\epsilon
Q(z)=∫δ[z−G(ϵ,X∣ϕ)]P(ϵ)dϵ
都可以实现:
E
Q
(
z
)
[
f
(
z
)
]
=
E
P
(
ϵ
)
[
f
[
G
(
ϵ
,
X
∣
ϕ
)
]
]
\mathbb E_{\mathcal Q(z)}[f(z)] = \mathbb E_{\mathcal P(\epsilon)}[f[\mathcal G(\epsilon,\mathcal X \mid \phi)]]
EQ(z)[f(z)]=EP(ϵ)[f[G(ϵ,X∣ϕ)]]
基于重参数化技巧的求解过程
继续观察
∇
ϕ
L
(
ϕ
)
\nabla_{\phi} \mathcal L(\phi)
∇ϕL(ϕ):
∇
ϕ
L
(
ϕ
)
=
E
Q
(
Z
∣
ϕ
)
{
∇
ϕ
log
Q
(
Z
∣
ϕ
)
⋅
[
l
o
g
P
(
X
,
Z
)
−
log
Q
(
Z
∣
ϕ
)
]
}
\nabla_{\phi} \mathcal L(\phi) = \mathbb E_{\mathcal Q(\mathcal Z \mid \phi)} \left\{ \nabla_{\phi} \log \mathcal Q(\mathcal Z \mid \phi) \cdot \left[log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi)\right] \right\}
∇ϕL(ϕ)=EQ(Z∣ϕ){∇ϕlogQ(Z∣ϕ)⋅[logP(X,Z)−logQ(Z∣ϕ)]}
- 假设存在
ϵ
∼
P
(
ϵ
)
\epsilon \sim \mathcal P(\epsilon)
ϵ∼P(ϵ),并且
Z
\mathcal Z
Z和
ϵ
\epsilon
ϵ满足:
Z = G ( ϵ , X ∣ ϕ ) \mathcal Z = \mathcal G(\epsilon,\mathcal X \mid \phi) Z=G(ϵ,X∣ϕ)
必然有:
概率密度积分~
∫ Z Q ( Z ∣ ϕ ) d Z = ∫ ϵ P ( ϵ ) d ϵ = 1 \begin{aligned} \int_{\mathcal Z} \mathcal Q(\mathcal Z \mid \phi) d\mathcal Z = \int_{\epsilon} \mathcal P(\epsilon) d\epsilon = 1 \end{aligned} ∫ZQ(Z∣ϕ)dZ=∫ϵP(ϵ)dϵ=1
从而有:
∣ Q ( Z ∣ ϕ ) d Z ∣ = ∣ P ( ϵ ) d ϵ ∣ |\mathcal Q(\mathcal Z \mid \phi) d\mathcal Z| = |\mathcal P(\epsilon) d\epsilon| ∣Q(Z∣ϕ)dZ∣=∣P(ϵ)dϵ∣ - 将上述变换直接带入
∇
ϕ
L
(
ϕ
)
\nabla_{\phi} \mathcal L(\phi)
∇ϕL(ϕ)中:
∇ ϕ L ( ϕ ) = ∇ ϕ ∫ Z [ log P ( X , Z ) − log Q ( Z ∣ ϕ ) ] ⋅ Q ( Z ∣ ϕ ) d Z = ∇ ϕ ∫ Z [ log P ( X , Z ) − log Q ( Z ∣ ϕ ) ] ⋅ P ( ϵ ) d ϵ \begin{aligned} \nabla_{\phi} \mathcal L(\phi) & = \nabla_{\phi} \int_{\mathcal Z} \left[ \log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi)\right] \cdot \mathcal Q(\mathcal Z \mid \phi) d\mathcal Z \\ & = \nabla_{\phi} \int_{\mathcal Z} \left[ \log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi)\right] \cdot \mathcal P(\epsilon) d\epsilon \end{aligned} ∇ϕL(ϕ)=∇ϕ∫Z[logP(X,Z)−logQ(Z∣ϕ)]⋅Q(Z∣ϕ)dZ=∇ϕ∫Z[logP(X,Z)−logQ(Z∣ϕ)]⋅P(ϵ)dϵ
使用牛顿-莱布尼兹公式将 ∇ ϕ \nabla_{\phi} ∇ϕ写入积分号中:
∫ Z ∇ ϕ [ log P ( X , Z ) − log Q ( Z ∣ ϕ ) ] ⋅ P ( ϵ ) d ϵ \int_{\mathcal Z} \nabla_{\phi}\left[ \log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi)\right] \cdot \mathcal P(\epsilon) d\epsilon ∫Z∇ϕ[logP(X,Z)−logQ(Z∣ϕ)]⋅P(ϵ)dϵ
因为 ∇ ϕ \nabla_{\phi} ∇ϕ是对 ϕ \phi ϕ求解积分,因此和 P ( ϵ ) \mathcal P(\epsilon) P(ϵ)无关。进而化简得:
E P ( ϵ ) [ ∇ ϕ ( log P ( X , Z ) − log Q ( Z ∣ ϕ ) ) ] \mathbb E_{\mathcal P(\epsilon)} [\nabla_{\phi} (\log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi))] EP(ϵ)[∇ϕ(logP(X,Z)−logQ(Z∣ϕ))]
为了将 Z = G ( ϵ , X ∣ ϕ ) \mathcal Z = \mathcal G(\epsilon,\mathcal X \mid \phi) Z=G(ϵ,X∣ϕ)代入公式,通过链式求导法则,引入 Z \mathcal Z Z,对 ∇ ϕ \nabla_{\phi} ∇ϕ进行重新表示:
E P ( ϵ ) [ ∇ Z ( log P ( X , Z ) − log Q ( Z ∣ ϕ ) ) ⋅ ∇ ϕ Z ] \mathbb E_{\mathcal P(\epsilon)} [\nabla_{\mathcal Z} (\log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi)) \cdot \nabla_{\phi}\mathcal Z] EP(ϵ)[∇Z(logP(X,Z)−logQ(Z∣ϕ))⋅∇ϕZ]
最终将 Z = G ( ϵ , X ∣ ϕ ) \mathcal Z = \mathcal G(\epsilon,\mathcal X \mid \phi) Z=G(ϵ,X∣ϕ)代入上式,则有:
E P ( ϵ ) [ ∇ Z ( log P ( X , Z ) − log Q ( Z ∣ ϕ ) ) ⋅ ∇ ϕ G ( ϵ , X ∣ ϕ ) ] \begin{aligned} \mathbb E_{\mathcal P(\epsilon)} [\nabla_{\mathcal Z} (\log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi)) \cdot \nabla_{\phi}\mathcal G(\epsilon,\mathcal X \mid \phi) ] \end{aligned} EP(ϵ)[∇Z(logP(X,Z)−logQ(Z∣ϕ))⋅∇ϕG(ϵ,X∣ϕ)]
至此,将最初始的基于 Q ( Z ) \mathcal Q(\mathcal Z) Q(Z)的期望转化为基于 P ( ϵ ) \mathcal P(\epsilon) P(ϵ)的期望。
具体的执行流程如下: - 从概率分布
P
(
ϵ
)
\mathcal P(\epsilon)
P(ϵ)中获取
L
L
L个样本:
ϵ ( l ) ∼ P ( ϵ ) l = 1 , 2 , ⋯ , L \epsilon^{(l)} \sim \mathcal P(\epsilon) \quad l = 1,2,\cdots,L ϵ(l)∼P(ϵ)l=1,2,⋯,L - 对期望结果进行处理:
E P ( ϵ ) [ ∇ Z ( log P ( X , Z ) − log Q ( Z ∣ ϕ ) ) ⋅ ∇ ϕ G ( ϵ , X ∣ ϕ ) ] = E P ( ϵ ) [ ( ∇ Z P ( X , Z ) P ( X , Z ) − ∇ Z Q ( Z ∣ ϕ ) Q ( Z ∣ ϕ ) ) ⋅ ∇ ϕ G ( ϵ , X ∣ ϕ ) ] \begin{aligned} & \mathbb E_{\mathcal P(\epsilon)} [\nabla_{\mathcal Z} (\log P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z \mid \phi)) \cdot \nabla_{\phi}\mathcal G(\epsilon,\mathcal X \mid \phi)] \\ & = \mathbb E_{\mathcal P(\epsilon)} \left[\left(\frac{\nabla_{\mathcal Z}P(\mathcal X,\mathcal Z)}{P(\mathcal X,\mathcal Z)} - \frac{\nabla_{\mathcal Z}\mathcal Q(\mathcal Z \mid \phi)}{Q(\mathcal Z \mid \phi)}\right) \cdot \nabla_{\phi}\mathcal G(\epsilon,\mathcal X \mid \phi)\right] \end{aligned} EP(ϵ)[∇Z(logP(X,Z)−logQ(Z∣ϕ))⋅∇ϕG(ϵ,X∣ϕ)]=EP(ϵ)[(P(X,Z)∇ZP(X,Z)−Q(Z∣ϕ)∇ZQ(Z∣ϕ))⋅∇ϕG(ϵ,X∣ϕ)] - 将
Z
=
G
(
ϵ
,
X
∣
ϕ
)
\mathcal Z = \mathcal G(\epsilon,\mathcal X \mid \phi)
Z=G(ϵ,X∣ϕ)代入,此时整个期望中,就仅剩余
ϵ
\epsilon
ϵ一个变量。最后将
ϵ
(
l
)
(
l
=
1
,
2
,
⋯
,
L
)
\epsilon^{(l)}(l=1,2,\cdots,L)
ϵ(l)(l=1,2,⋯,L)代入, 使用蒙特卡洛方法求解均值近似期望结果 即可,最终近似求解
∇
ϕ
L
(
ϕ
)
\nabla_{\phi} \mathcal L(\phi)
∇ϕL(ϕ)。
从而继续使用随机梯度变分推断,使用梯度上升法求解概率分布 Q ( Z ∣ ϕ ) \mathcal Q(\mathcal Z \mid \phi) Q(Z∣ϕ)的最优参数 ϕ ^ \hat \phi ϕ^:
ϕ ( t + 1 ) ← ϕ ( t ) + λ ( t ) ⋅ ∇ ϕ L ( ϕ ) \phi^{(t+1)} \gets \phi^{(t)} + \lambda^{(t)} \cdot \nabla_{\phi} \mathcal L(\phi) ϕ(t+1)←ϕ(t)+λ(t)⋅∇ϕL(ϕ)
至此,变分推断部分的介绍结束。下一节将介绍马尔可夫链蒙特卡洛采样方法(Markov Chain Monte Carlo,MCMC)。
相关文章
- 机器学习笔记(九)---- 集成学习(ensemble learning)【华为云技术分享】
- 机器学习笔记(四)---- 逻辑回归的多分类
- 机器学习入门 - Google机器学习速成课程 - 笔记汇总
- 机器学习笔记 - 使用Keras、TensorFlow框架进行自定义数据集目标检测训练
- 机器学习笔记 - 使用python从头构建和训练神经网络
- 机器学习笔记 - 自动编码器autoencoder
- 机器学习笔记 - 使用Streamlit探索对象检测数据集
- 机器学习笔记 - LUX:用于自动探索性数据分析的 Python API
- 机器学习笔记 - Keras中的回调函数Callback使用教程
- 机器学习笔记 - 机器学习中的聚类算法
- 机器学习笔记 - 使用SMOTE和Near Miss算法处理不平衡数据
- 机器学习笔记 - 探索性数据分析(EDA) 入门案例三
- 机器学习笔记 - Kaggle表格游乐场 Jan 2022 学习二
- 机器学习笔记 - cifar10数据集下载及查看
- 机器学习笔记 - 过拟合和欠拟合
- 机器学习笔记(八)---- 神经网络【华为云分享】
- LR 算法总结--斯坦福大学机器学习公开课学习笔记