
《ANTLR 4权威指南 》一2.4 使用语法分析树来构建语言类应用程序
本节书摘来自华章出版社《ANTLR 4权威指南 》一书中的第2章,第2.4节,[美] 特恩斯·帕尔(Terence Parr) 著张 博 译,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.4 使用语法分析树来构建语言类应用程序为了编写一个语言类应用程序,我们必须对每个输入的词组或者子词组执行一些适当的操作。进行这项工作最简单的方式是操作语法分析器自动生成的语法分析树。这种方式的优点在于,我们能够重回我们所熟悉的Java领域。这样,在语言类应用程序进一步的构建过程中,我们就不需要再学习复杂的ANTLR语法了。
首先,我们来认识一下ANTLR在识别和建立语法分析树的过程中使用的数据结构和类名。熟悉这些数据结构将为我们未来的讨论奠定基础。
前已述及,词法分析器处理字符序列并将生成的词法符号提供给语法分析器,语法分析器随即根据这些信息来检查语法的正确性并建造出一棵语法分析树。这个过程对应的ANTLR类是CharStream、Lexer、Token、Parser,以及ParseTree。连接词法分析器和语法分析器的“管道”就是TokenStream。图2-2展示了这些类型的对象在内存中的交互方式。
ANTLR尽可能多地使用共享数据结构来节约内存。如图2-2所示,语法分析树中的叶子节点(词法符号)仅仅是盛放词法符号流中的词法符号的容器。每个词法符号都记录了自己在字符序列中的开始位置和结束位置,而非保存子字符串的拷贝。其中,不存在空白字符对应的词法符号(索引为2和4的字符)的原因是,我们假定我们的词法分析器会丢弃空白字符。
图2-2中也显示出,ParseTree的子类RuleNode和TerminalNode,二者分别是子树的根节点和叶子节点。RuleNode有一些令人熟悉的方法,例如getChild()和getParent(),但是,对于一个特定的语法,RuleNode并不是确定不变的。为了更好地支持对特定节点的元素的访问,ANTLR会为每条规则生成一个RuleNode的子类。如图2-3所示,在我们的赋值语句的例子中,子树根节点的类型实际上是StatContext、AssignContext以及ExprContext。
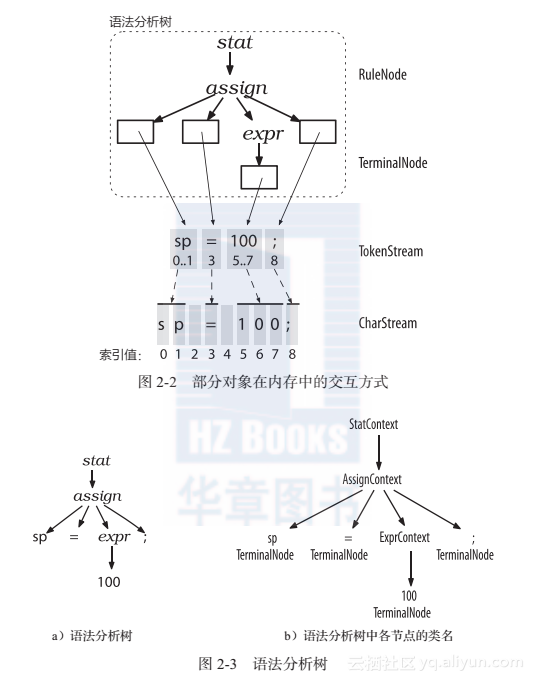
因为这些根节点包含了使用规则识别词组过程中的全部信息,它们被称为上下文(context)对象。每个上下文对象都知道自己识别出的词组中,开始和结束位置处的词法符号,同时提供访问该词组全部元素的途径。例如,AssignContext类提供了方法ID()和方法expr()来访问标识符节点和代表表达式的子树。
给定这些类型的具体实现,我们可以手工写出对语法分析树进行深度优先遍历的代码。这样,在访问其中的节点时,我们可以进行一切所需的操作。这个过程中的典型操作是诸如计算结果、更新数据结构或者产生输出一类的事情。实际上,我们可以利用ANTLR自动生成并遍历树的机制,而不需要每次都重复编写遍历树的代码。
《领域特定语言》一1.5使用代码生成 本节书摘来自华章出版社《领域特定语言》一书中的第1章,第1.5节,作者 (英)Martin Fowler,更多章节内容可以访问云栖社区“华章计算机”公众号查看
《ANTLR 4权威指南 》一3.4 构建一个语言类应用程序 我们继续完成能够处理数组初始化语句的示例程序,下一个目标是能够翻译初始化语句,而不仅仅是能够识别它们。例如,我们想要将Java中,类似{ 99, 3, 451 }的short数组翻译成 \u0063\u0003\u01c3 。注意,其中十进制数字99的十六进制表示是63。
《ANTLR 4权威指南 》一1.2 运行ANTLR并测试识别程序 ANTLR在运行库中提供了一个名为TestRig的方便的调试工具。它可以详细列出一个语言类应用程序在匹配输入文本过程中的信息,这些输入文本可以来自文件或者标准输入。TestRig使用Java的反射机制来调用编译后的识别程序。与之前一样,最好通过别名或者批处理文件来调用它。
相关文章
- Swift语言实战晋级
- 李宏毅课程-人类语言处理-BERT和它的家族-ELMo等(下)
- R语言数据挖掘2.2.2.4 Apriori算法的变体
- 聊聊动态语言那些事(Python)
- 第59节:Java中的html和css语言
- Xamarin XAML语言教程基本页面ContentPage占用面积(二)
- Xamarin XAML语言教程隐藏文件使用Progress属性设置进度条
- 《C和C++代码精粹》——第 1 章 更好的C1.1 两种语言简述
- 语言的扩展
- 《R语言与数据挖掘最佳实践和经典案例》—— 1.1 数据挖掘
- 《Python语言程序设计》——1.9 开始学习图形化程序设计
- 《数据科学:R语言实现》——2.5 使用Excel文件
- 初试 Julia 语言 (转)
- 盘点四个最好用的JavaScript语言IDE
- Proteus——开关控制端口输入、输出(汇编51两种语言)
- 1. 走进Java语言 —— Java SE
- R语言基础题及答案(四)——R语言与统计分析第四章课后习题(汤银才)
- Swift语言实现代理传值
- 38超文本标记语言HTML
- 【语言】Rust语言学习资源
- c语言 什么时候要传入参数的引用“&” —— 对参数的修改结果需要“带回来
- 请看matlab代码的排序和c语言中排序,总觉着matlab可能只剩下画图比较方便了吧