
即学即用:Pandas入门与时间序列分析
Note: 下面的例子都是在时间戳--温度数据上运行的,示例如下:
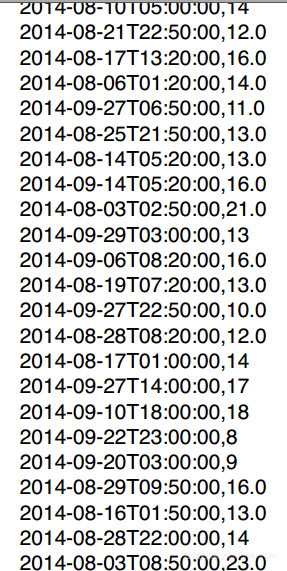
2. # 读取数据 3. df = pd.read_csv(raw_weather_data_aug_sep_2014/tempm.csv, header=None) 4. print df.head(5) #输出前n行 5. print df.tail(5) #输出最后n行
得到:
【可视化】
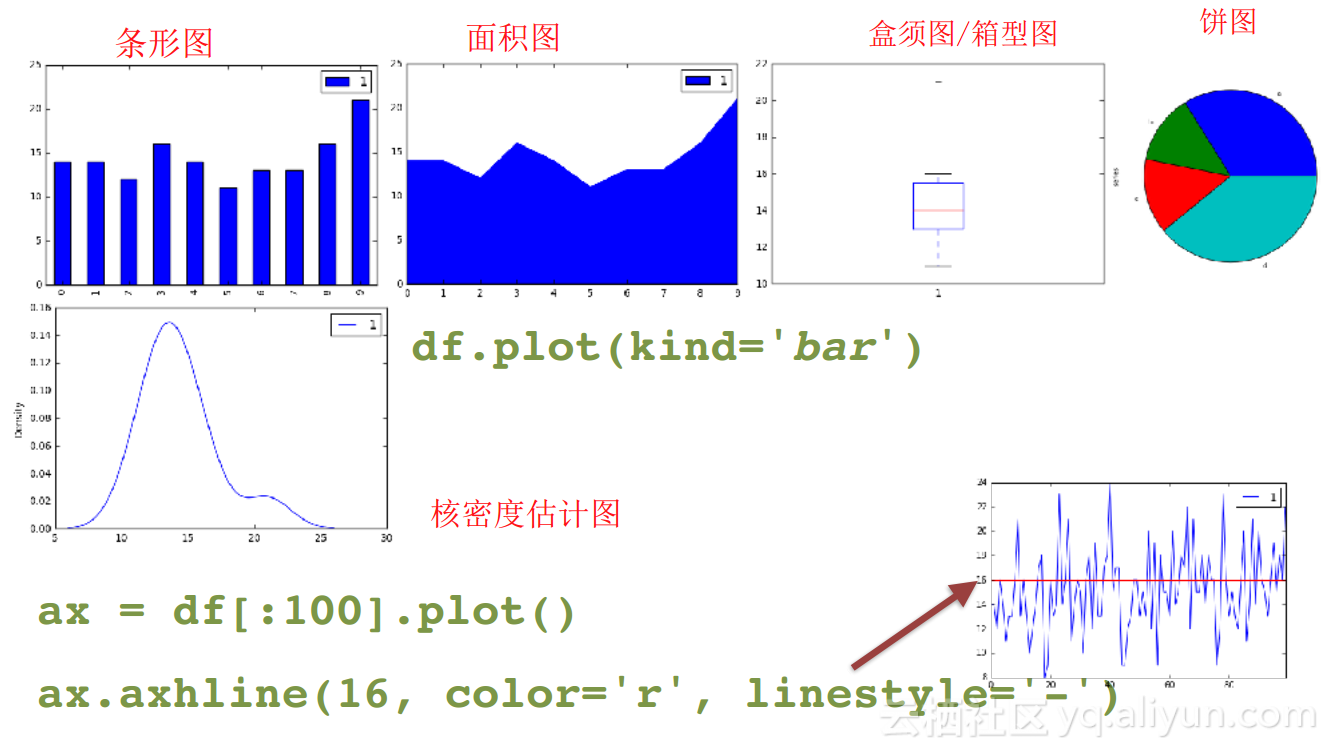
1. 使用Matplotlib库,.plot() 函数
2. 可定制,可扩展
3. 盒图、条形图、散点图等
4. 也可以使用Bokeh库或Seaborn库
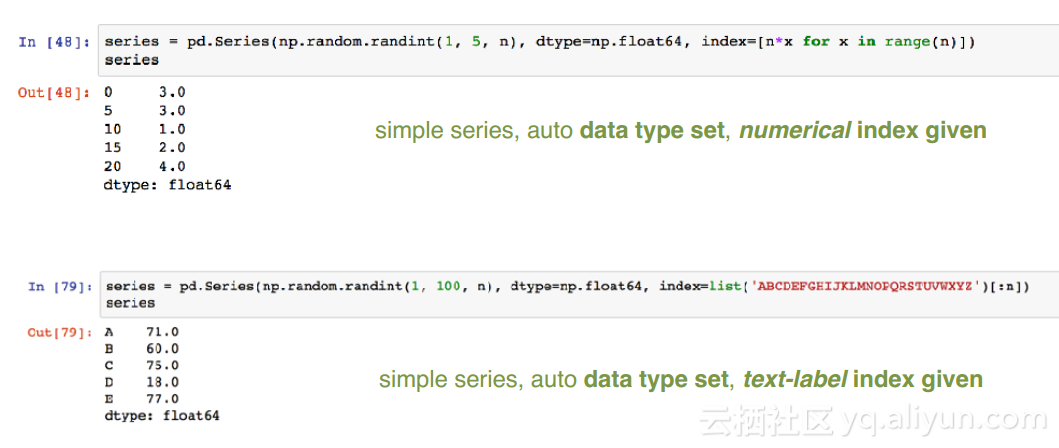
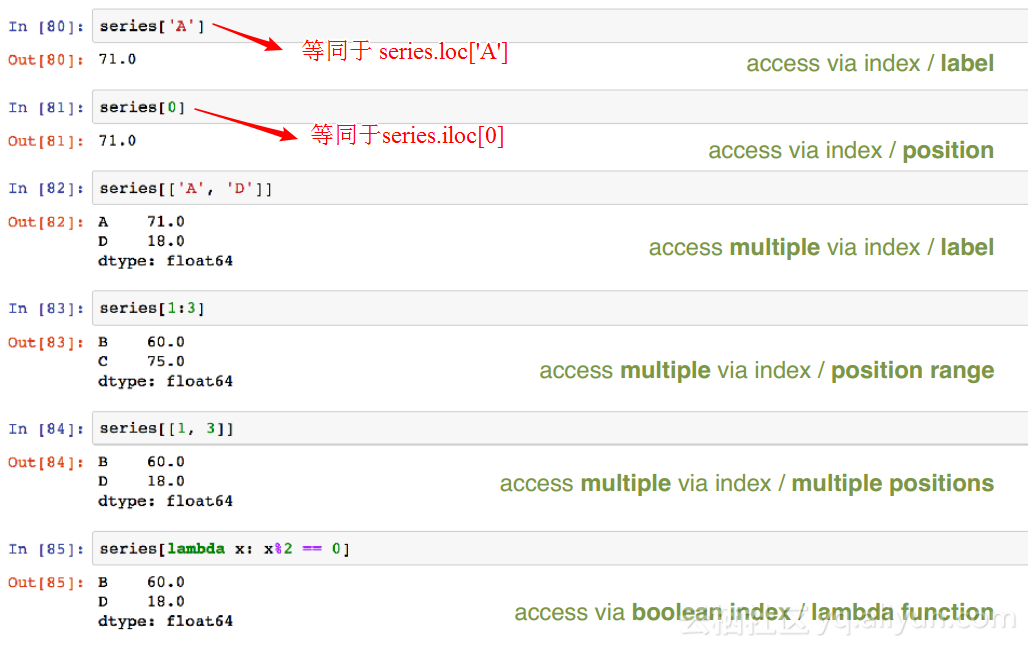
1. 一维有标签数组结构,可以存入任一种python的数据类型(integers, strings, floating point numbers, Python objects, etc.)
2. 序列的标签通常称为索引(index)
3. 如果index没给定,会自动创建()
4. pd.Series()函数中的参数,如data, index和dtype, 均是可选的
数据选择与访问方式:
1. 可以通过标签(index)选择,也可以通过位置来选择(从0开始);
 【DataFrame】
【DataFrame】
二维有标签数据结构,如2维Numpy数组,关于索引,有如下规定:
1.如果没有指定索引,将会自动创建;
2.索引可以重置或者替换;
3. 类型:位置,时间戳,时间范围,标签…;
4.一个索引号可能会出现多次(不唯一)
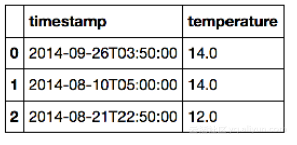
例2. 对数据进行运算:
1. def to_fahrenheit(celsius): 2. return (celsius * 9./5.) + 32. 3. df[temperature].map(to_fahrenheit)[:5] 4. df[temperature F] = df[temperature].map(to_fahrenheit) 5. df.head(5) 6. df[temperature F] = df[temperature].apply(lambda x: (x * 9./5.) + 32.) 7. df.head()
第3行仅仅是对temperature这一列进行了运算,则输出:

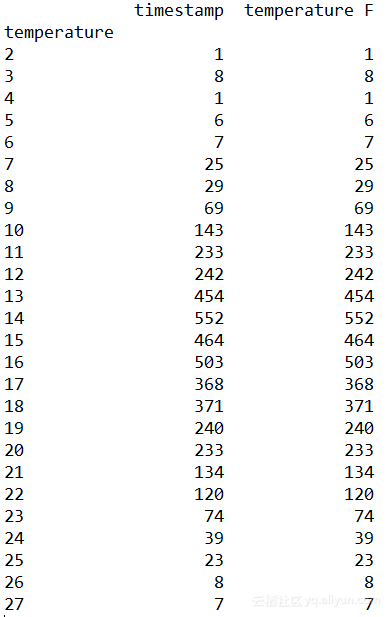
而第4行和第6行为不存在的列(temperature F)赋值,创建新列(temperatureF),均输出:
Series和DataFrame的方法实际上并没有修改原始的Series和DataFrame,而是返回一个新的Series或DataFrame,可以使用inplace参数来决定是否要用新结果替换掉原来的数据。
原列名被替换,输出:
1. # .mean()函数计算指定数据的均值 2. df[deviation] = df[temperature] - df[temperature].mean() 3. df.head()
输出:
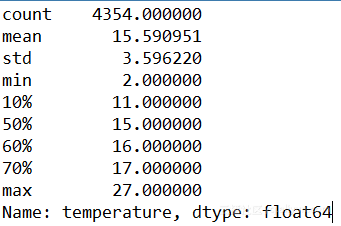
例3. 输出指定数据统计信息
1. # describe()方法返回数据的统计信息,不考虑空值 2. df[temperature].describe(percentiles=[.1,.5,.6,.7])
NaN表示空值,可以使用drop( )移除;也可以用默认值替换或者前向填充/后向填充
例1. 使用Isnull( )函数判断是否为空
1. df[temperature].isnull()[2350:2357]
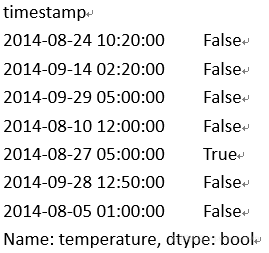
例2. 删除缺失值:
1. df.dropna(inplace=True) 2. print df[temperature].isnull().any()
输出: False ,因为已经删除缺失值,并且用删除之后的数据替换掉原数据,所以判断是否存在空值时,返回False,即不存在空数据。
Part2 时间序列分析(以时间戳为index的序列)在进行时间序列分析时,先将DataFrame的索引值由默认的数字索引变为时间戳索引:
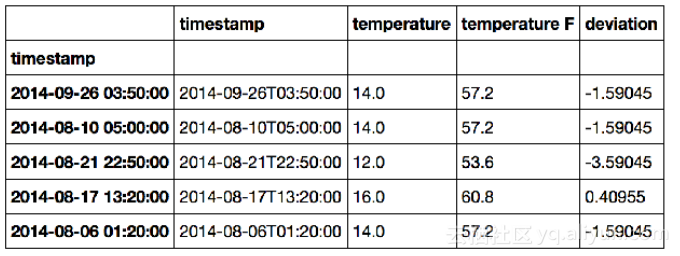
1. #新增一列deviation,然后将默认的索引值变为时间戳索引值 2. df[deviation]=df[temperature]-df[temperature].mean() 3. df.index=pd.to_datetime(df[timestamp]) 4. df.head()
此时,DataFrame变为如下形式:
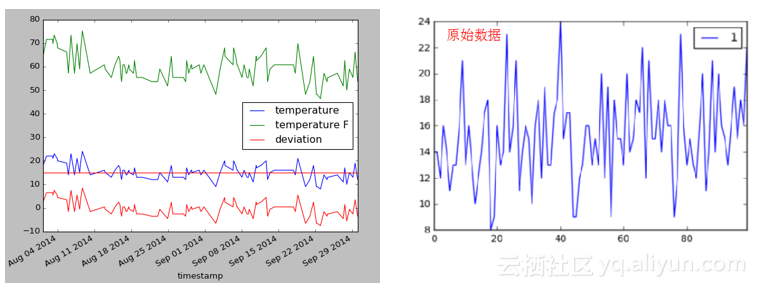
画出DataFrame前100行,此时图的横坐标不再是数值索引,而是时间戳。如下:
1. ax=df[:100].plot() 2. ax.axhline(df[:100][temperature].median(),color=r,line ) 3. plt.show()
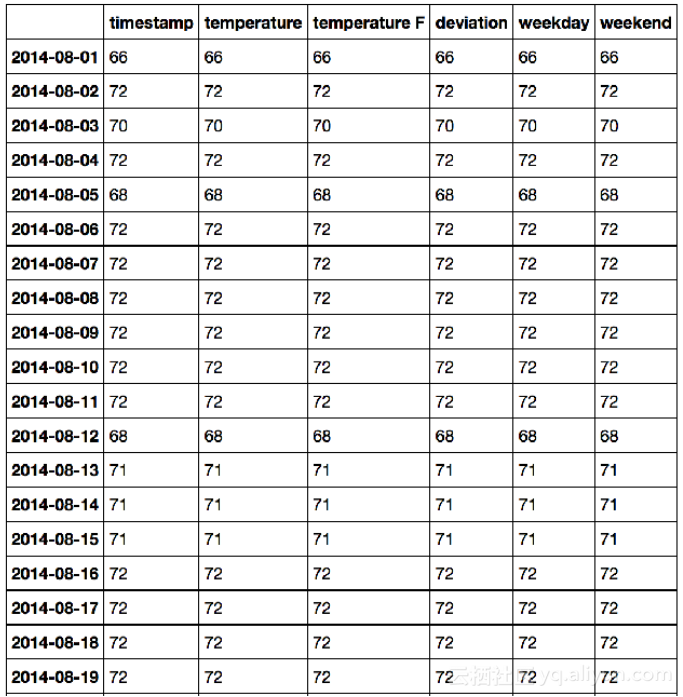
此时,对DataFrame加入weekday列和weekend列,
1. # DatetimeIndex.weekday 将返回该日期是一星期中的第几天,星期一是0,星期天是6
2. df[weekday] = df.index.weekday
3. # isin()返回布尔值,表示df[weekday]是否在{5,6}中,
4. # 即判断是否是周末
5. df[weekend] = df[weekday].isin({5, 6})
6. # 根据日期来分组,进行统计
7. df.groupby(df.index.date).count()
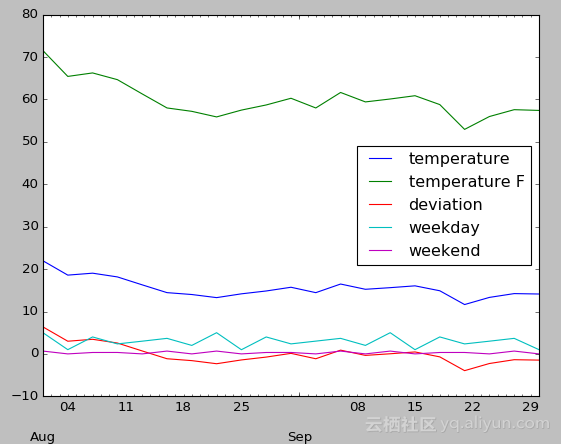
目前,已经得到每天的数据包括时间戳,摄氏温度,华氏温度,偏差以及周几和是否周末,统计输出如下:
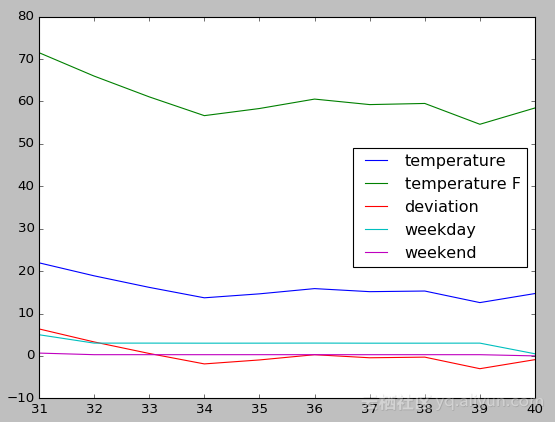
那么就可以进一步分析温度随着时间的变化趋势,比如观察每周气温的变化情况:
1. # 以周为时间单位进行聚合,分析气温的变化情况 2. # 前面已经将时间序列作为索引值,那么这里df.index.week返回的是一年的第几周 3. df.groupby(df.index.week).plot()
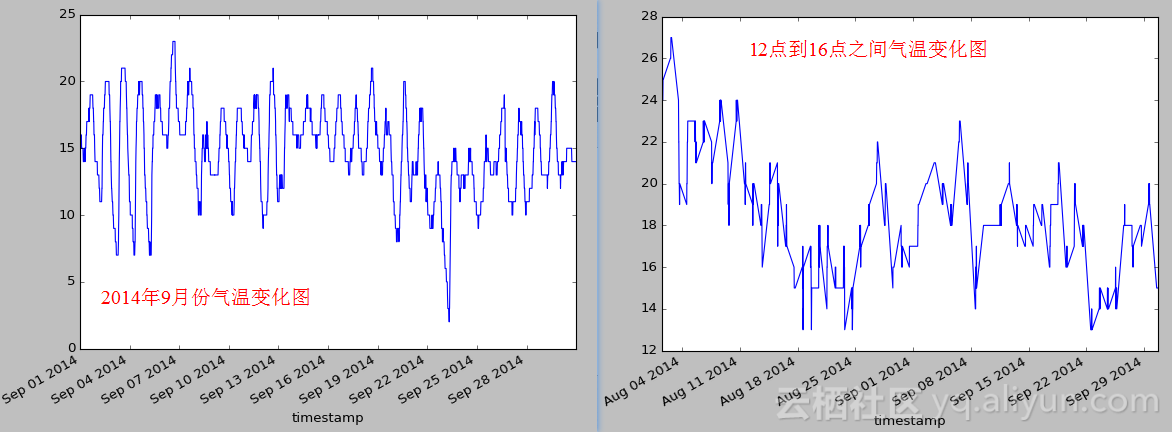
也可以分析指定时间内的温度变化趋势
重采样是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法,分为降采样和升采样,将高频率数据聚合到低频率数据称为降采样(downsampling),将低频率转换到高频率称为升采样(upsampling)。

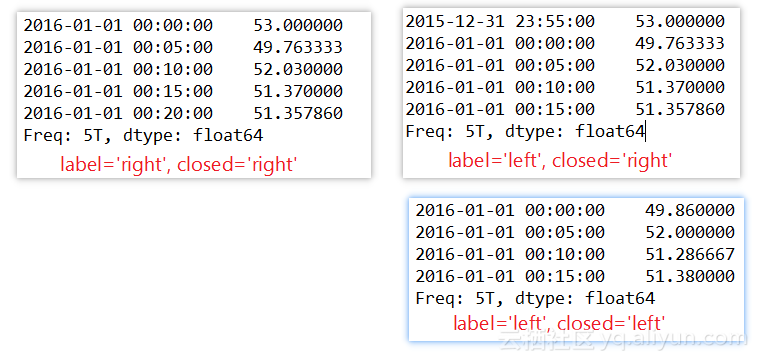
又如对Series进行降采样:
1. import random 2. index = pd.date_range(1/1/2016, periods=1200, freq=S) 3. series = pd.Series([random.randint(0,100) for p in range(1200)], index=index) 4. # label参数表示采用区间左边的时间戳还是右边的时间戳, 5. # closed参数表示区间是左边闭合还是右边闭合,和数学中[ ),( ]区间表示形式一样 6. # 一个时间戳只能属于一个时间段,所有时间段合并起来必须能组成原始的整个时间帧 7. # 降采样,从之前的1秒变为5分钟 8. resampled = series.resample(5T, label=right, closed=right) 9. print resampled 10. print series.resample(5T, label=left, closed=right) 11. print series.resample(5T, label=left, closed=left)
输出:
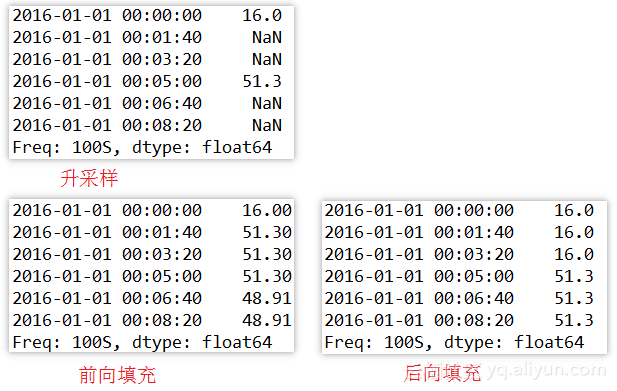
升采样,采样频率从5分钟变到100秒,
1. # 升采样默认会引入缺失值 2. print resampled.resample(100S)[:6] 3. # ffill()向前填充,即用上一个有效值填充缺失数据 4. # bfill()向后填充,即用下一个有效值填充缺失数据 5. print resampled.resample(100S).ffill()[:6] 6. print resampled.resample(100S).bfill()[:6]
 使用statsmodels库进一步分析时序数据
使用statsmodels库进一步分析时序数据
Note: statsmodels是一个包含统计模型、统计测试和统计数据挖掘python模块。对每一个模型都会生成一个对应的统计结果。统计结果会和现有的统计包进行对比来保证其正确性。
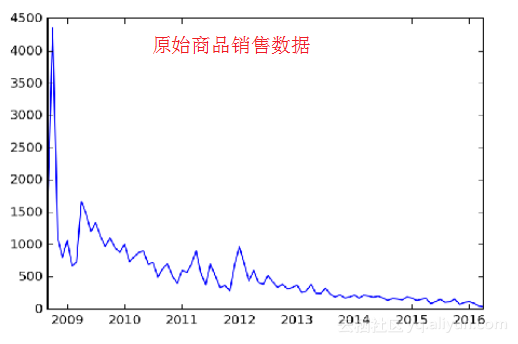
如上图所示,是某种商品的历史销售数据,为了更好地分析商品销售变化趋势,将销售时序数据分解为长期趋势、季节趋势和随机成分。statsmodels支持两类分解模型,加法模型和乘法模型。默认采用加法模型,即分解后的这3个趋势相加要等于原始数据。
1. dtap=pd.DataFrame(mdf.groupby(mdf.index)[activity].sum()) 2. # 对缺失数据插值 3. dtap.activity.interpolate(inplace=True) 4. res=sm.tsa.seasonal_decompose(dtap.activity) 5. resplot=res.plot() 6. resplot.set_size_inches(15,15)输出:
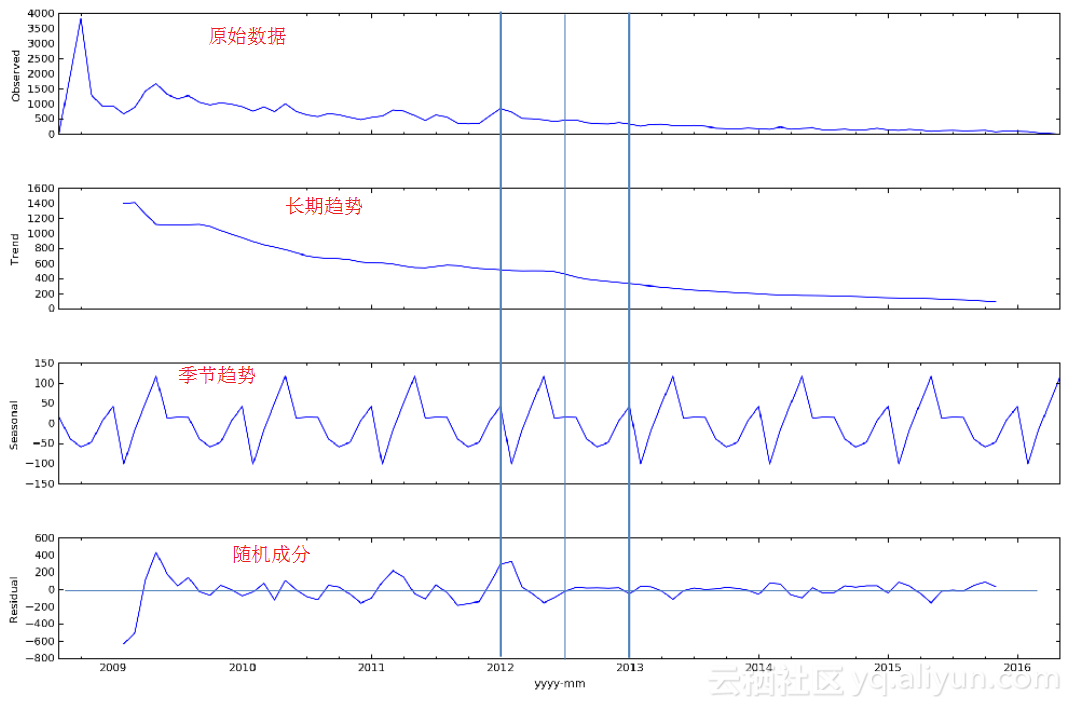
在得到不同的分解成分后,就可以使用时间序列模型对各个成分进行拟合,进行商品销量预测,这对商家库存管理和销售是很有帮助的。
安利一个会议:EuroPython 2017, 欧洲最大的Python会议,欢迎参加。
作者介绍

为创业和业界提供咨询服务
EuroPython PyConDE 的组织者和程序委员会主席
MongoDB大师
文章原标题《Introduction to Pandas and Time Series Analysis》,作者:Alexander C. S. Hendorf,译者:李烽 审校:海棠-段志成
文章为简译,更为详细的内容,请查看原文。
数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解)—Pandas—pandas入门(一) 你好,感谢你能点进来本篇博客,请不要着急退出,相信我,如果你有一定的 Python 基础,想要学习 Python数据分析的三大库:numpy,pandas,matplotlib;这篇文章不会让你失望,本篇博客是 【AIoT阶段一(下)】 的内容:Python数据分析,
数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解)—Pandas—pandas入门(二) 你好,感谢你能点进来本篇博客,请不要着急退出,相信我,如果你有一定的 Python 基础,想要学习 Python数据分析的三大库:numpy,pandas,matplotlib;这篇文章不会让你失望,本篇博客是 【AIoT阶段一(下)】 的内容:Python数据分析,
数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解)—Pandas—pandas入门—数据选择(1)(三) 你好,感谢你能点进来本篇博客,请不要着急退出,相信我,如果你有一定的 Python 基础,想要学习 Python数据分析的三大库:numpy,pandas,matplotlib;这篇文章不会让你失望,本篇博客是 【AIoT阶段一(下)】 的内容:Python数据分析,
数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解)—Pandas—pandas入门—数据选择(2)(四) 你好,感谢你能点进来本篇博客,请不要着急退出,相信我,如果你有一定的 Python 基础,想要学习 Python数据分析的三大库:numpy,pandas,matplotlib;这篇文章不会让你失望,本篇博客是 【AIoT阶段一(下)】 的内容:Python数据分析,
数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解)—Pandas—pandas入门(五) 你好,感谢你能点进来本篇博客,请不要着急退出,相信我,如果你有一定的 Python 基础,想要学习 Python数据分析的三大库:numpy,pandas,matplotlib;这篇文章不会让你失望,本篇博客是 【AIoT阶段一(下)】 的内容:Python数据分析,
pandas 入门(四) 本文其实属于:Python的进阶之道【AIoT阶段一】的一部分内容,本篇把这部分内容单独截取出来,方便大家的观看,本文介绍 pandas 入门,后续还会单独发一篇 pandas 高级以及 pandas 进阶内容供读者学习。
相关文章
- pandas 左右边界切割 用merge join和concat合并Pandas中的数据
- Java实现 LeetCode 674 最长连续递增序列(暴力)
- Java实现 LeetCode 491递增子序列
- Java实现子序列问题
- 机器学习笔记 - 时间序列的线性回归
- ML之prophet:利用prophet算法对维基百科页面的日志每日页面浏览量实现回归预测(时间序列的趋势/周季节性趋势/年季节性趋势)案例
- 基于最小二乘支持向量机(LS-SVM)进行分类、函数估计、时间序列预测和无监督学习(Matlab代码实现)
- 几行 Python 代码就可以提取数百个时间序列特征
- Leetcode 1218. 最长定差子序列(提供一种思路)
- 求先序序列
- DLNg第三周:序列模型和注意力机制
- 2-3课程 比较:统计序列中元素的出现频度
- 【洛谷】P1439 【模板】求最长公共子序列
- 【pandas】教程:9-如何轻松处理时间序列数据