
【pandas】教程:9-如何轻松处理时间序列数据
Pandas 如何轻松处理时间序列数据
数据
本节使用的数据为 data/air_quality_no2_long.csv,链接为 pandas案例和教程所使用的数据-机器学习文档类资源-CSDN文库
import pandas as pd
import matplotlib.pyplot as plt
air_quality = pd.read_csv("data/air_quality_no2_long.csv")
# 重命名列名
air_quality = air_quality.rename(columns={"date.utc": "datetime"})
air_quality
city country datetime location parameter \
0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2
1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2
2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2
3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2
4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2
... ... ... ... ... ...
2063 London GB 2019-05-07 06:00:00+00:00 London Westminster no2
2064 London GB 2019-05-07 04:00:00+00:00 London Westminster no2
2065 London GB 2019-05-07 03:00:00+00:00 London Westminster no2
2066 London GB 2019-05-07 02:00:00+00:00 London Westminster no2
2067 London GB 2019-05-07 01:00:00+00:00 London Westminster no2
value unit
0 20.0 µg/m³
1 21.8 µg/m³
2 26.5 µg/m³
3 24.9 µg/m³
4 21.4 µg/m³
... ... ...
2063 26.0 µg/m³
2064 16.0 µg/m³
2065 19.0 µg/m³
2066 19.0 µg/m³
2067 23.0 µg/m³
[2068 rows x 7 columns]
利用 pandas 的 datetime 属性
- 将 文本型的数据转换为
datetime
air_quality["datetime"] = pd.to_datetime(air_quality["datetime"])
air_quality["datetime"]
0 2019-06-21 00:00:00+00:00
1 2019-06-20 23:00:00+00:00
2 2019-06-20 22:00:00+00:00
3 2019-06-20 21:00:00+00:00
4 2019-06-20 20:00:00+00:00
...
2063 2019-05-07 06:00:00+00:00
2064 2019-05-07 04:00:00+00:00
2065 2019-05-07 03:00:00+00:00
2066 2019-05-07 02:00:00+00:00
2067 2019-05-07 01:00:00+00:00
Name: datetime, Length: 2068, dtype: datetime64[ns, UTC]
利用
to_datetime函数可以将string类型的时间变量 转换为datetime64[ns, UTC]对象。
pd.read_csv("data/air_quality_no2_long.csv", parse_dates=["datetime"])可以在读入数据的时候,直接将日期时间数据转换为datetime64[ns, UTC]对象。
为什么需要 datetime ?
- 可以计算开始时间和结束时间
- 可以计算时间间隔
- 可以进行时间比较等等。
air_quality["datetime"].min(), air_quality["datetime"].max()
(Timestamp('2019-05-07 01:00:00+0000', tz='UTC'),
Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
air_quality["datetime"].max() - air_quality["datetime"].min()
Timedelta('44 days 23:00:00')
- 将数据中的月份单独作为数据
DataFrame的一列。
air_quality["month"] = air_quality["datetime"].dt.month
air_quality.head()
city country datetime location parameter value unit \
0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0 µg/m³
1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8 µg/m³
2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5 µg/m³
3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9 µg/m³
4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4 µg/m³
month
0 6
1 6
2 6
3 6
4 6
Timestamp对象有很多属性可以使用,除了month, 还可以用year,weekofyear,quarter…,这些都可以通过dt访问器来访问。
- 如何计算每个地区周一到周日每天平均 N O 2 NO_2 NO2浓度?
air_quality.groupby([air_quality["datetime"].dt.weekday, "location"])["value"].mean()
datetime location
0 BETR801 27.875000
FR04014 24.856250
London Westminster 23.969697
1 BETR801 22.214286
FR04014 30.999359
London Westminster 24.885714
2 BETR801 21.125000
FR04014 29.165753
London Westminster 23.460432
3 BETR801 27.500000
FR04014 28.600690
London Westminster 24.780142
4 BETR801 28.400000
FR04014 31.617986
London Westminster 26.446809
5 BETR801 33.500000
FR04014 25.266154
London Westminster 24.977612
6 BETR801 21.896552
FR04014 23.274306
London Westminster 24.859155
Name: value, dtype: float64
还记得
groupby提供的split-apply-combine模式吗?
我们这里需要计算每个测量区域的周一到周日总体平均浓度。
首先将周一到周日每天分组(group)Monday=0, Sunday=6,weekday通过dt访问,
然后按地区分组(group),分别计算平均值,然后组合。
由于我们在这些例子中使用的是非常短的时间序列,因此分析并不能提供具有长期代表性的结果!
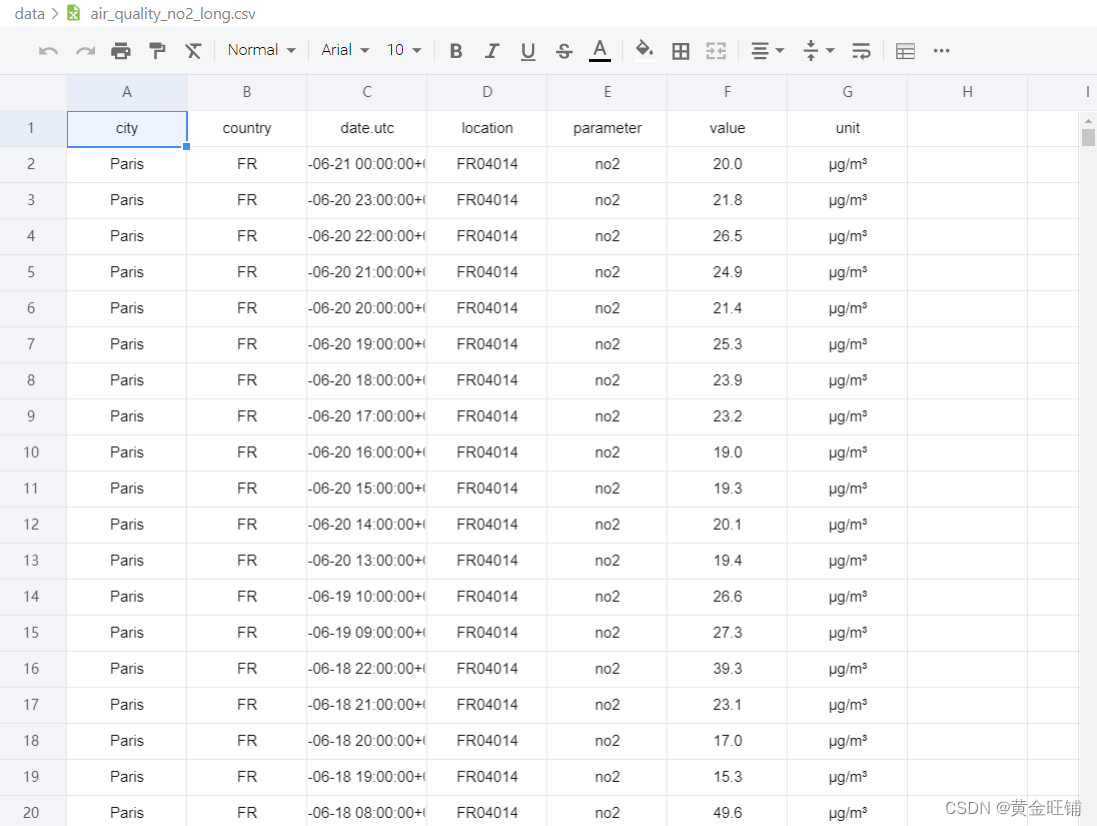
- 绘制一天中每个小时的 N O 2 NO_2 NO2 平均浓度
fig, axs = plt.subplots(figsize=(12, 4))
air_quality.groupby(air_quality["datetime"].dt.hour)["value"].mean().plot(
kind='bar', rot=0, ax=axs)
plt.xlabel("Hour of the day") # custom x label using Matplotlib
plt.ylabel("$NO_2 (µg/m^3)$")
Datetime 作为索引
在 (1条消息) 【pandas】教程:7-调整表格数据的布局_黄金旺铺的博客-CSDN博客 中提到了
pivot可以改变表格的形状,将每个地区做为单独的一列。
通过pivot数据,datetime 变成了表格的索引,通常情况下,设置一列为索引可以通过set_index函数实现。
no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
no_2
location BETR801 FR04014 London Westminster
datetime
2019-05-07 01:00:00+00:00 50.5 25.0 23.0
2019-05-07 02:00:00+00:00 45.0 27.7 19.0
2019-05-07 03:00:00+00:00 NaN 50.4 19.0
2019-05-07 04:00:00+00:00 NaN 61.9 16.0
2019-05-07 05:00:00+00:00 NaN 72.4 NaN
... ... ... ...
2019-06-20 20:00:00+00:00 NaN 21.4 NaN
2019-06-20 21:00:00+00:00 NaN 24.9 NaN
2019-06-20 22:00:00+00:00 NaN 26.5 NaN
2019-06-20 23:00:00+00:00 NaN 21.8 NaN
2019-06-21 00:00:00+00:00 NaN 20.0 NaN
[1033 rows x 3 columns]
datetime提供了强大的index功能,例如,我们不需要dt来获取时间序列的属性,可以直接使用index获得这些属性;
no_2.index.year, no_2.index.weekday
(Int64Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
...
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int64', name='datetime', length=1033),
Int64Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
dtype='int64', name='datetime', length=1033))
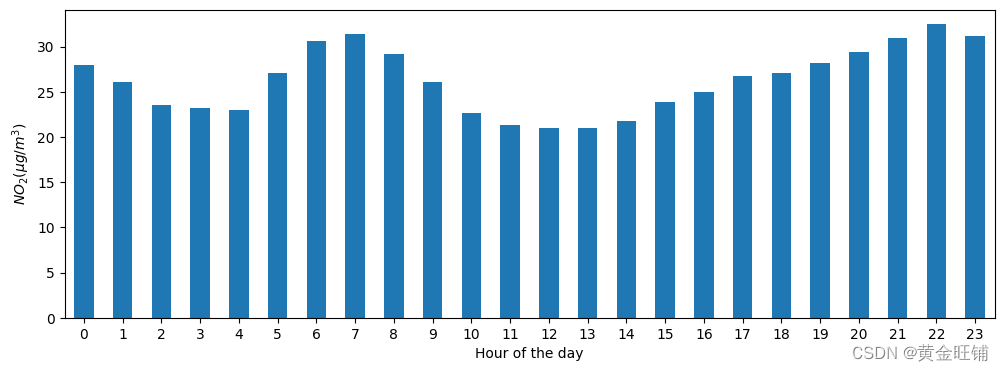
- 绘制 5月20日 到 5月21日 不同地区的 N O 2 NO_2 NO2 浓度值
no_2["2019-05-20":"2019-05-21"].plot()
将时间序列重新采样另一个频率
- 将当前每小时的时间序列采样值聚合到每个站点的月最大值;
monthly_max = no_2.resample("M").max()
monthly_max
location BETR801 FR04014 London Westminster
datetime
2019-05-31 00:00:00+00:00 74.5 97.0 97.0
2019-06-30 00:00:00+00:00 52.5 84.7 52.0
在时间序列上一个非常强大的方法是
datetime的index可以通过resample时间序列到不同频率(例如:将每秒的数据转换为每五分钟的数据)
resample有点类似于groupby操作;
提供了基于时间的grouping, 可以利用字符串 (例如:M,5H…)
需要提供聚合函数mean,max…
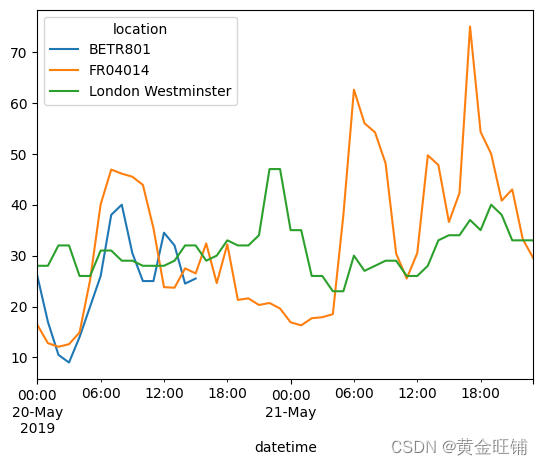
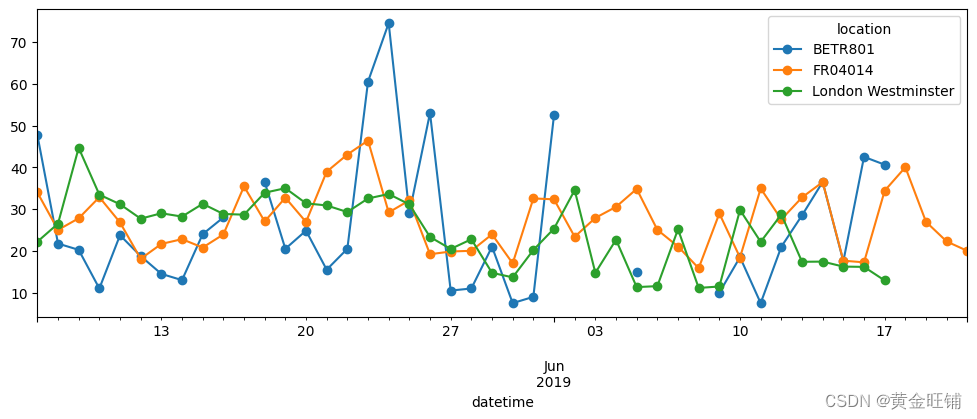
- 绘制每个地区日均 N O 2 NO_2 NO2 浓度
no_2.resample("D").mean().plot(style="-o", figsize=(12, 4))
记住
有效的日期字符串可以使用
to_datetime转换为datetime对象,也可以在读入数据时直接转换为datetime对象。
pandas里的datetime对象支持计算和逻辑运算等,还可以方便的使用dt访问时间的属性。
DatetimeIndex包含了日期时间相关的属性,并支持方便的切片。
resample是一个非常强大的方法,支持时间序列的采样频率变换。
参考
How to handle time series data with ease? — pandas 1.5.2 documentation (pydata.org)
相关文章
- 时间序列数据库武斗大会之 KairosDB 篇
- Java 第十一届 蓝桥杯 省模拟赛 递增序列
- Java 第十一届 蓝桥杯 省模拟赛 合法括号序列
- Java实现 LeetCode 673 最长递增子序列的个数(递推)
- Java实现 蓝桥杯VIP 算法提高 最长字符序列
- Java实现 蓝桥杯VIP 算法训练 摆动序列
- 时间序列--Holt-Winters
- (字符串)最长公共子序列(Longest-Common-Subsequence,LCS)
- 【二叉树】106. 从中序与后序遍历序列构造二叉树 【中等】
- Python之Pandas:pandas.read_csv()函数的简介、具体案例、使用方法详细攻略
- 编程笔试(解析及代码实现):序列重排之给一个长度为n的序列A,求找出某种排列方式使得相邻两个数的差值之和最大并求出该最大值
- 【推荐】南大《时间序列分析 (Time Series Analysis)》课程已梳理完毕
- 《5G网络协议与客户感知》读书笔记 | 网络鉴权信令序列
- 基于System Verilog的序列检测器
- 基于命令序列的异常行为分析 业界研究现状分析
- 动态规划05~不会吧,不会吧。还有人没把子序列和子串搞明白呀?