
使用python在es中基本操作详解(添加索引、查询索引、删除索引、判断索引是否存在、添加数据、更新数据、查询数据)
1.添加索引
示例代码1:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
"mappings": {
"properties": {
"grade": {
"type": "long"
},
"id": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"subject": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
# 创建索引
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
# 创建索引
res2 = es.index(index='test_index2', document=doc)
print(res2)
运行结果:

示例代码2:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
"mappings": {
"properties": {
"grade": {
"type": "long"
},
"id": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"subject": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
# 创建索引
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
print("*" * 100)
# 创建索引
res2 = es.index(index='test_index2', document=doc)
print(res2)
print(res2['result'])
print("*" * 100)
# 创建索引 res3运行两次会报错
res3 = es.indices.create(index="test_index3", body=doc)
print(res3)
# print(res3['result']) # 注意:此行运行会报错
print("*" * 100)
# 创建索引 res4多次执行会报错
res4 = es.create(index='test_index4', id=1, document=doc)
print(res4)
print(res4['result'])
运行结果:
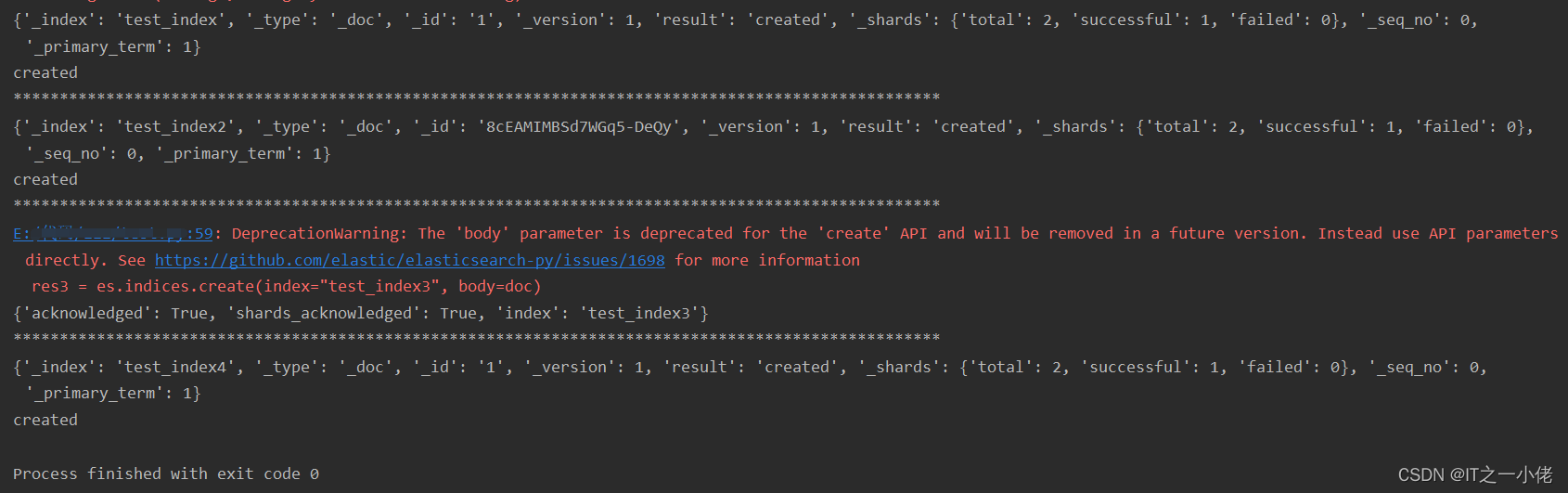
示例代码3:
from elasticsearch import Elasticsearch
from datetime import datetime
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'author': 'dgw',
'text': 'Elasticsearch: cool. bonsai cool.',
'timestamp': datetime.now(),
}
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
运行结果:

注意:对比上面几种建立索引的方法,是有一定区别的。根据响应结果可以看出:es. indices.create()方法是标准的创建索引的方法,其它几种方法在创建索引的同时也会生成一条数据,并且生成mapping不是我们自己定义的类型,分别如下图所示:

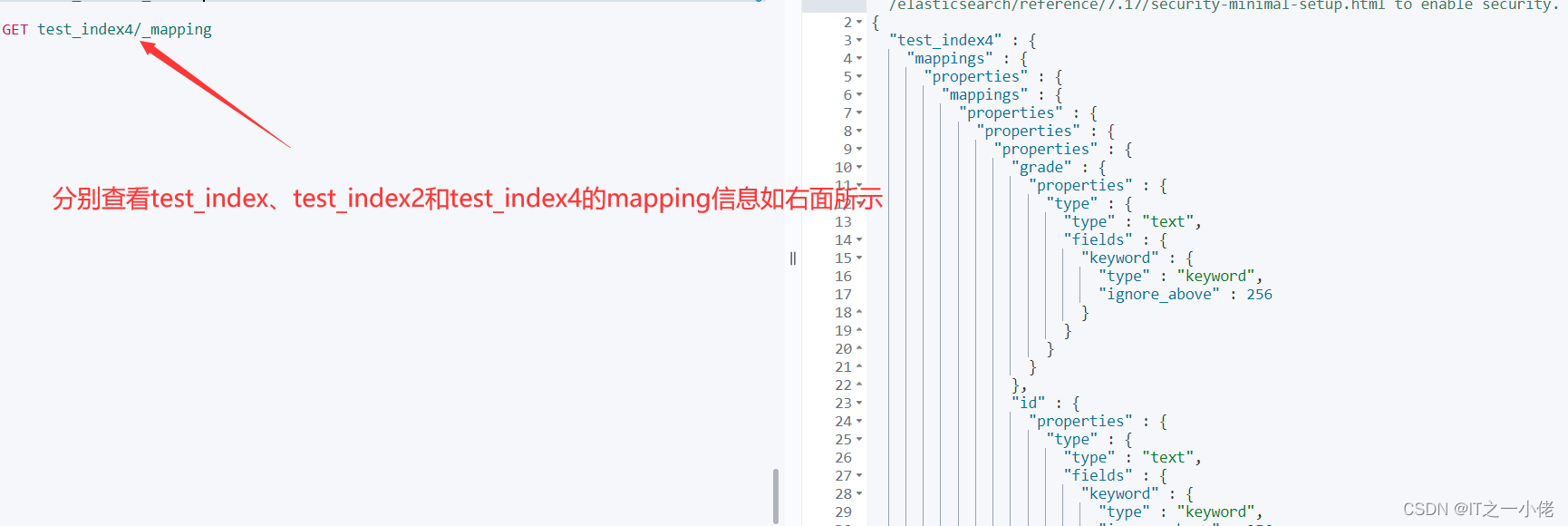
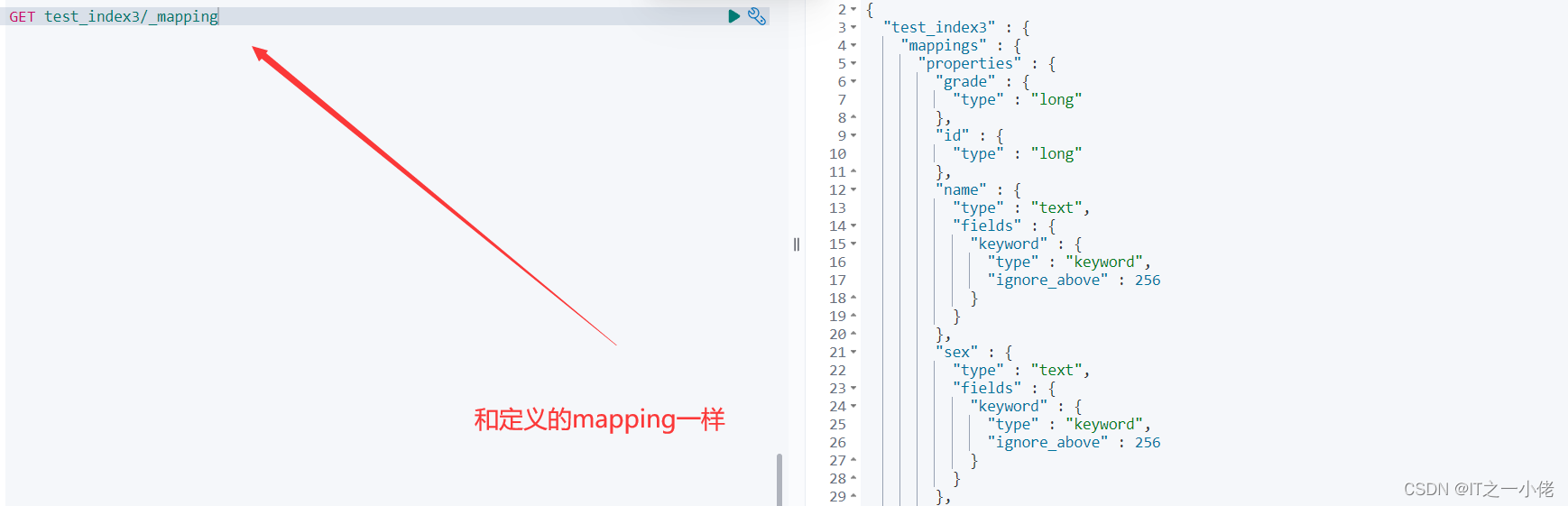
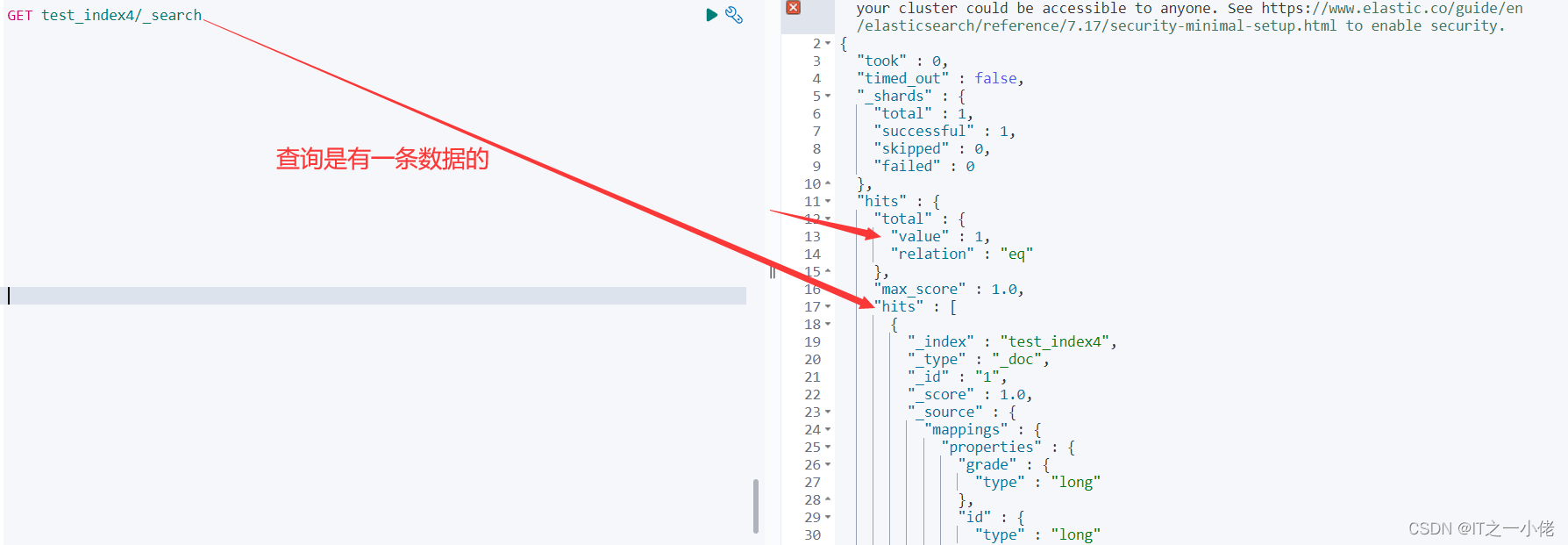
2.查询索引
示例代码:
from elasticsearch import Elasticsearch
from datetime import datetime
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'author': 'dgw',
'text': 'Elasticsearch: cool. bonsai cool.',
'timestamp': datetime.now(),
}
# 创建索引
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
# 查询数据
res2 = es.get(index="test_index", id=1)
print(res2)
print(res2['_source'])
es.indices.refresh(index="test_index")
query = {
"match_all": {}
}
res3 = es.search(index='test_index', query=query)
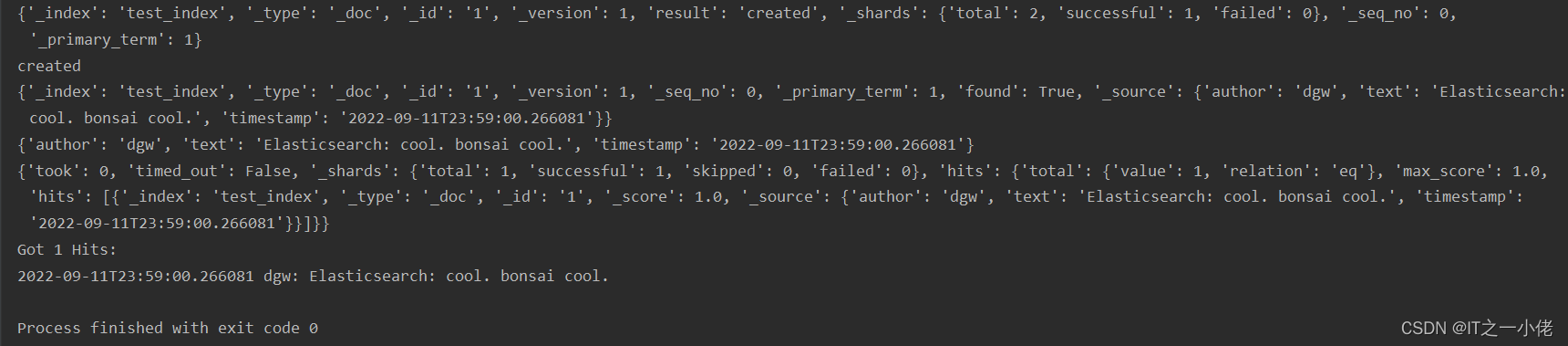
print(res3)
print("Got %d Hits:" % res3['hits']['total']['value'])
for hit in res3['hits']['hits']:
print("%(timestamp)s %(author)s: %(text)s" % hit["_source"])
运行结果:
3.删除索引/数据
示例代码1:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
# 判断索引是否存在,存在则删除索引
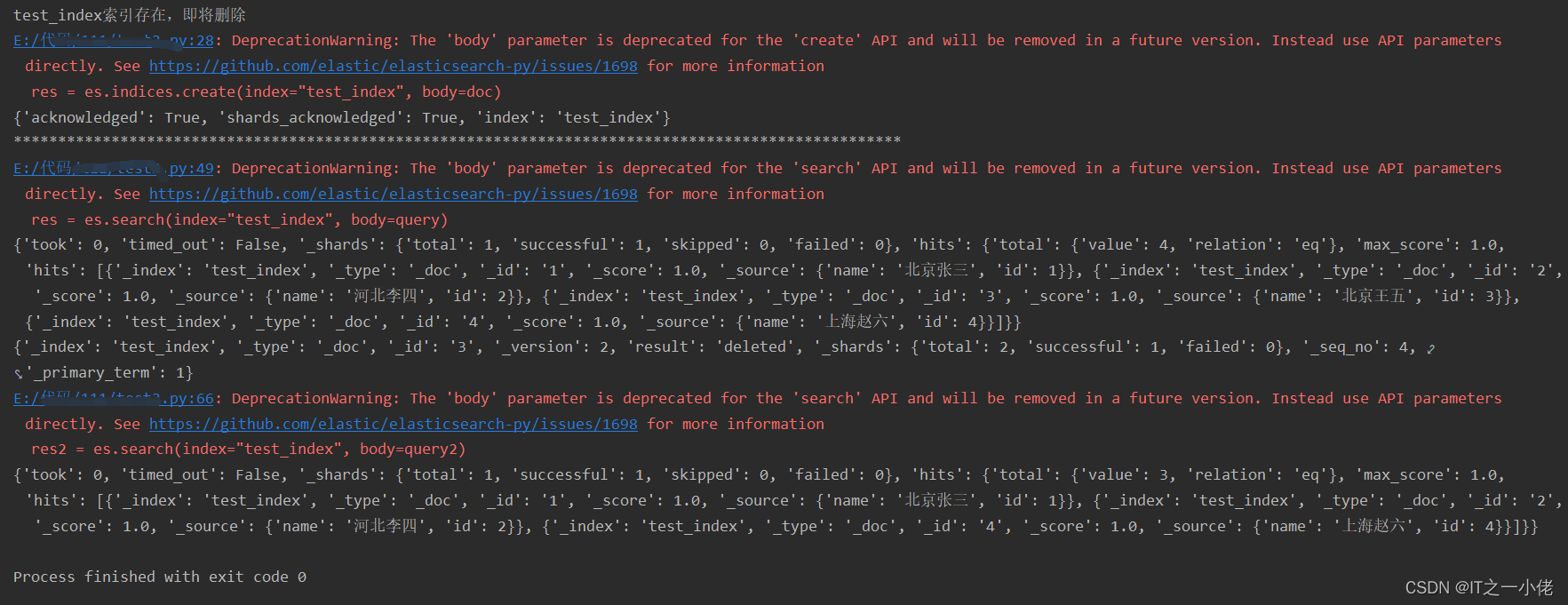
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('test_index索引不存在!')
运行结果:

示例代码2:
from elasticsearch import Elasticsearch
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
# 使用create时,当id已经存在时会报错
es.create(index="test_index", id="3", document={"name": "北京王五", "id": 3})
es.create(index="test_index", id='4', document={"name": "上海赵六", "id": 4})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 使用search查询数据
query = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res = es.search(index="test_index", body=query)
print(res)
# 删除指定id数据
res = es.delete(index="test_index", id=3)
print(res)
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果可能受影响,上面删除数据需要时间
# 使用search查询数据
query2 = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res2 = es.search(index="test_index", body=query2)
print(res2)
运行结果:
4.判断索引是否存在
为防止在创建索引的时候出现重复,产生错误,在创建之前最好判断一下索引是否存在。
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://47.93.5.86:9200')
# print(es)
doc = {
"mappings": {
"properties": {
"grade": {
"type": "long"
},
"id": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"subject": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
# 创建索引
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
# 判断索引是否存在
es_exist = es.exists(index="test_index", id=2)
print(es_exist)
# 判断索引是否存在
es_exist = es.indices.exists(index='test_index')
print(es_exist)
运行结果:

5.添加数据
示例代码1:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
# 查询数据
res = es.get(index="test_index", id=1)
print(res)
运行结果:

示例代码2:
from elasticsearch import Elasticsearch
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
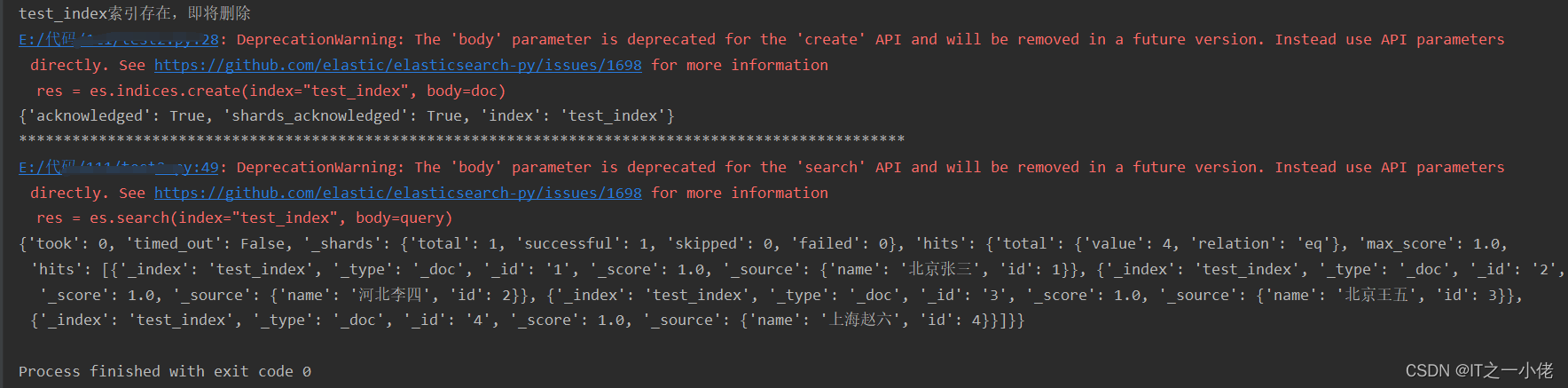
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
# index可以自动生成id
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
# 使用create时,当id已经存在时会报错,id唯一标识,当id不存在时也报错
es.create(index="test_index", id="3", document={"name": "北京王五", "id": 3})
es.create(index="test_index", id='4', document={"name": "上海赵六", "id": 4})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 使用search查询数据
query = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:
6.更新数据
全局更新:在 Elasticsearch 中,通过指定文档的 _id, 使用 Elasticsearch 自带的 index api 可以实现插入一条 document , 如果该 _id 已存在,将直接更新该 document。通过这种方法修改,因为是 reindex 过程,所以当数据量或者 document 很大的时候,效率非常的低
示例代码1:
from elasticsearch import Elasticsearch
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
es.index(index="test_index", id='3', document={"name": "北京王五", "id": 3})
es.index(index="test_index", id='4', document={"name": "上海赵六", "id": 4})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 使用search查询数据
query = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res = es.search(index="test_index", body=query)
print(res)
print("*" * 100)
# 更新数据 如果当前id存在则为更新,若不存在则为新增
# 注意:当id存在时的更新为整体替换,而不是局部替换
es.index(index="test_index", id='4', document={"name": "山西王五"})
es.index(index="test_index", id='5', document={"name": "山东周八", "id": 888})
es.index(index="test_index", id='6', document={"name": "上海孙七", "id": 6})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 查询数据
query2 = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res2 = es.search(index="test_index", body=query2)
print(res2)运行结果:
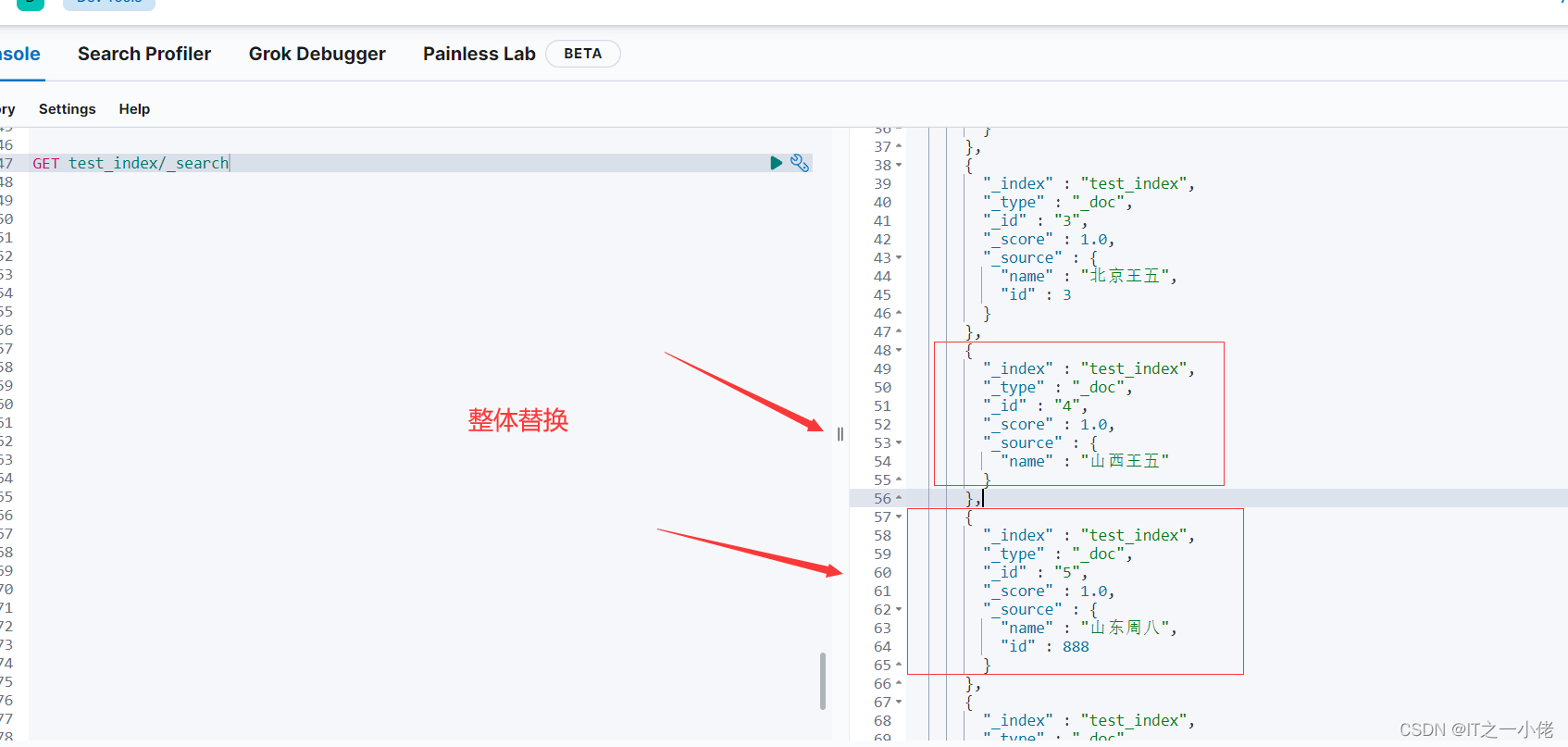
局部更新:Elasticsearch 中的 update API 支持根据用户提供的脚本去实现更新。Update 更新操作允许 ES 获得某个指定的文档,可以通过脚本等操作对该文档进行更新。可以把它看成是先删除再索引的原子操作,只是省略了返回的过程,这样即节省了来回传输的网络流量,也避免了中间时间造成的文档修改冲突。
示例代码2:
from elasticsearch import Elasticsearch
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
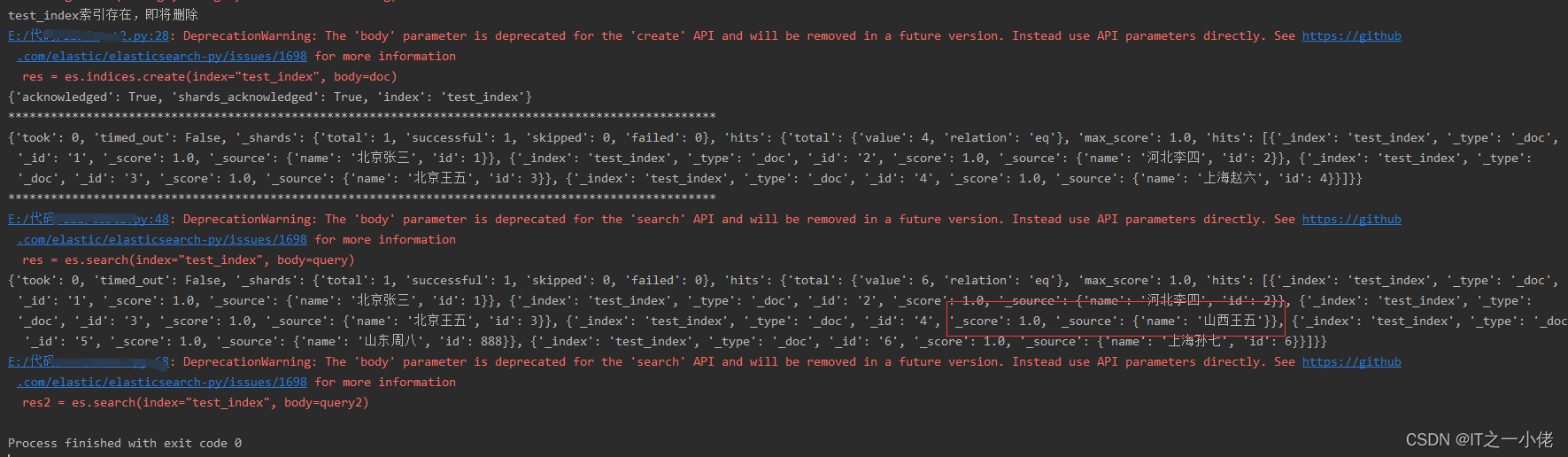
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
es.index(index="test_index", id='3', document={"name": "北京王五", "id": 3})
es.index(index="test_index", id='4', document={"name": "上海赵六", "id": 4})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 使用search查询数据
query = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res = es.search(index="test_index", body=query)
print(res)
print("*" * 100)
# 更新数据 局部更新数据 如果当前id存在则为局部更新,若不存在则报错
es.update(index="test_index", id='2', doc={"id": 222})
es.update(index="test_index", id='4', doc={"name": "山西王五"})
es.update(index="test_index", id='3', body={"doc": {"id": "333"}}) # 注意这儿和上面写法的不同
# 当update更新的文档id不存在时会报错
# es.update(index="test_index", id='5', doc={"name": "山东周八", "id": 6})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 查询数据
query2 = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res2 = es.search(index="test_index", body=query2)
print(res2)运行结果:
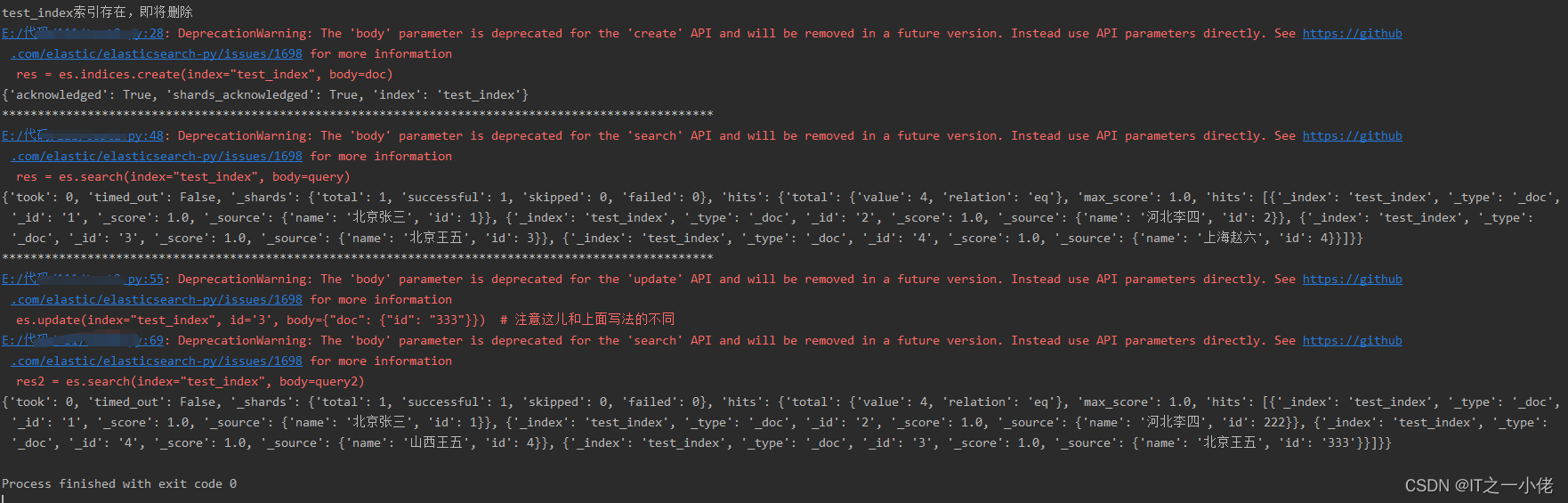
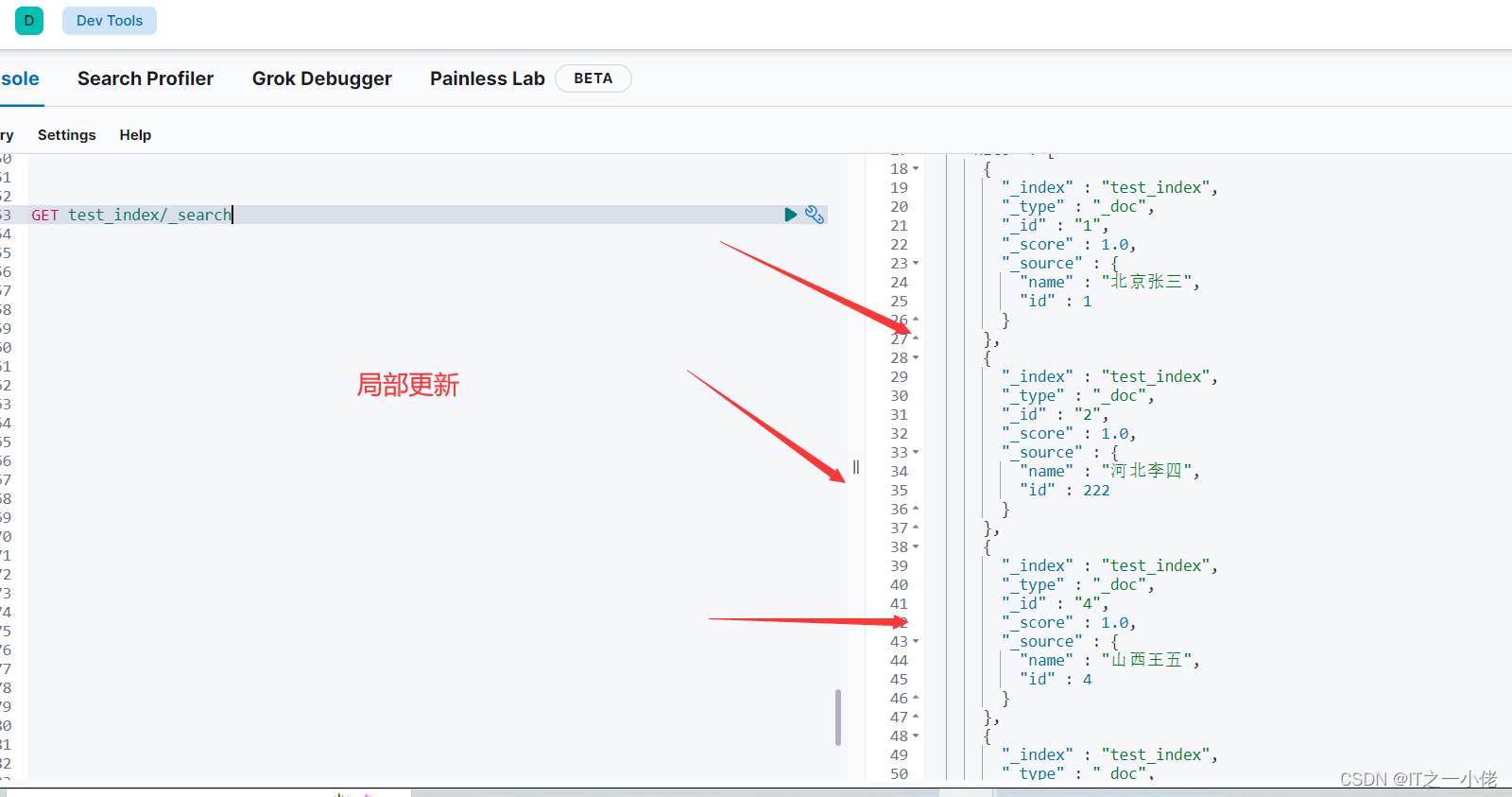
批量更新:ES 有提供批量操作的接口 bulk
示例代码:
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
es.index(index="test_index", id='3', document={"name": "北京王五", "id": 3})
es.index(index="test_index", id='4', document={"name": "上海赵六", "id": 4})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 使用search查询数据
query = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res = es.search(index="test_index", body=query)
print(res)
print("*" * 100)
# 需要更新的词典
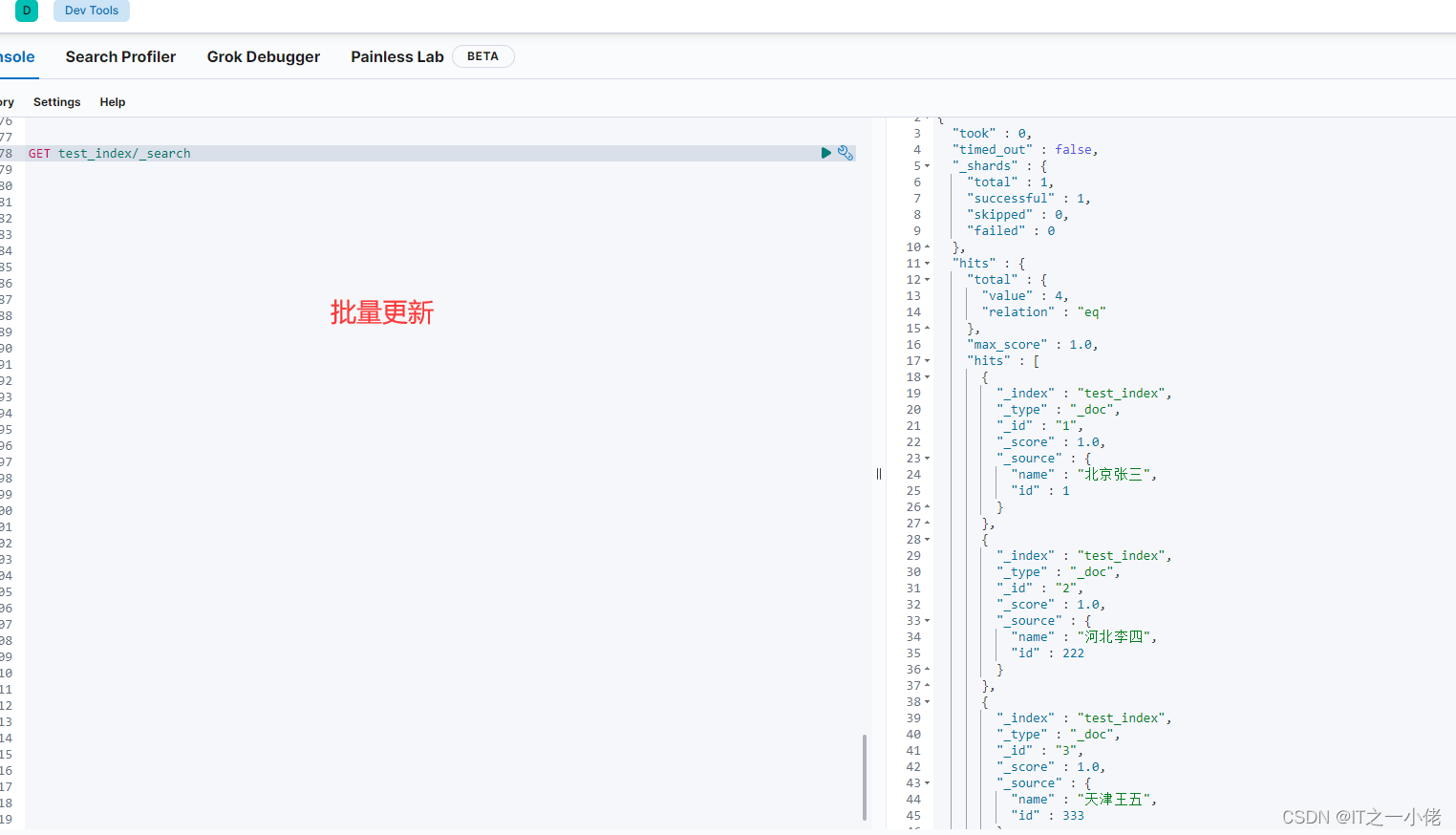
dic_lst = [{"_index": "test_index", "_id": 2, "_type": "_doc", "_op_type": "update", "doc": {"id": 222}},
{"_index": "test_index", "_id": 3, "_type": "_doc", "_op_type": "update",
"doc": {"name": "天津王五", "id": 333}},
{"_index": "test_index", "_id": 4, "_type": "_doc", "_op_type": "update", "doc": {"name": "山西王五"}}
]
# 批量更新数据,当id存在时是局部更新,当id不存在时报错
actions = []
for dic in dic_lst:
actions.append(dic)
if actions:
helpers.bulk(es, actions)
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 查询数据
query2 = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res2 = es.search(index="test_index", body=query2)
print(res2)
运行结果:
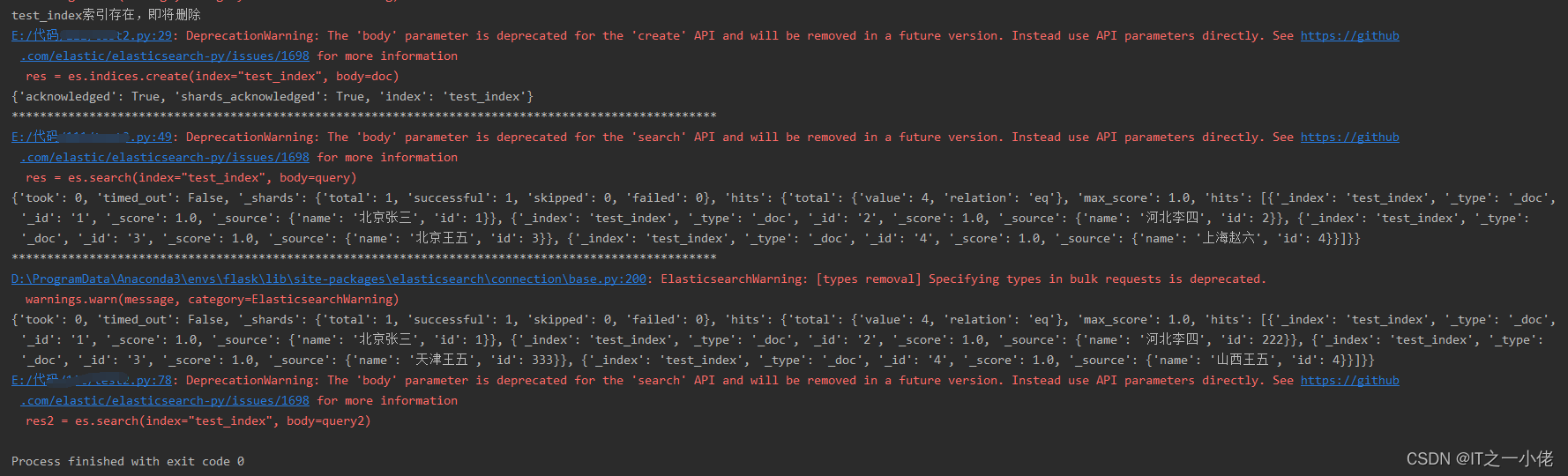
7.查询数据
示例代码:
from elasticsearch import Elasticsearch
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
es.index(index="test_index", id='3', document={"name": "北京王五", "id": 3})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 查询数据
# 使用get查询数据,按id来查询
res = es.get(index="test_index", id=1)
print(res)
print("*" * 100)
# 使用search查询数据
query1 = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res2 = es.search(index="test_index", body=query1)
print(res2)
print("*" * 100)
# 精确查找term
query2 = {
"query": {
"term": {
"name": {
"value": "北"
}
}
}
}
res2 = es.search(index="test_index", body=query2)
print(res2)
print("*" * 100)
# 精确查找terms
query3 = {
"query": {
"terms": {
"name": [
"张",
"李"
]
}
}
}
res3 = es.search(index="test_index", body=query3)
print(res3)
print("*" * 100)
# 模糊查找match
query4 = {
"query": {
"match": {
"name": "京"
}
}
}
res = es.search(index="test_index", body=query4)
print(res)
print("*" * 100)
# 查询id和name包含
query5 = {
"query": {
"multi_match": {
"query": "张三",
"fields": ["name"]
}
}
}
res = es.search(index="test_index", body=query5)
print(res)
print("*" * 100)
# 搜索出id为1或者2的所有数据
query6 = {
"query": {
"ids": {
"type": "_doc",
"values": ["1", "2"]
}
}
}
res = es.search(index="test_index", body=query6)
print(res)
print("*" * 100)
运行结果:
test_index索引存在,即将删除
{'acknowledged': True, 'shards_acknowledged': True, 'index': 'test_index'}
****************************************************************************************************
{'_index': 'test_index', '_type': '_doc', '_id': '1', '_version': 1, '_seq_no': 0, '_primary_term': 1, 'found': True, '_source': {'name': '北京张三', 'id': 1}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 3, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 1.0, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '2', '_score': 1.0, '_source': {'name': '河北李四', 'id': 2}}, {'_index': 'test_index', '_type': '_doc', '_id': '3', '_score': 1.0, '_source': {'name': '北京王五', 'id': 3}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 3, 'relation': 'eq'}, 'max_score': 0.13353139, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 0.13353139, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '2', '_score': 0.13353139, '_source': {'name': '河北李四', 'id': 2}}, {'_index': 'test_index', '_type': '_doc', '_id': '3', '_score': 0.13353139, '_source': {'name': '北京王五', 'id': 3}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 1.0, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '2', '_score': 1.0, '_source': {'name': '河北李四', 'id': 2}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 0.4700036, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 0.4700036, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '3', '_score': 0.4700036, '_source': {'name': '北京王五', 'id': 3}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 1, 'relation': 'eq'}, 'max_score': 1.9616582, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 1.9616582, '_source': {'name': '北京张三', 'id': 1}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 1.0, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '2', '_score': 1.0, '_source': {'name': '河北李四', 'id': 2}}]}}
****************************************************************************************************8.复合查询数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
query = {
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "张"
}
}
},
{
"term": {
"id": {
"value": "1"
}
}
}
]
}
}
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

9.切片查询数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
query = {
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

10.范围查询数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
query = {
"query": {
"range": {
"id": {
"gte": 1,
"lte": 2
}
}
}
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

11.前缀查询数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
# 查询前缀为“张”的数据。注意:这个要看分词后的前缀
query = {
"query": {
"prefix": {
"name": {
"value": "张"
}
}
}
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

12.通配符查询
wildcard查询:会对查询条件进行分词。还可以使用通配符?(任意单个字符)和*(0个或多个字符)
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
query = {
"query": {
"wildcard": {
"name": {
"value": "三"
}
}
}
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

13.正则匹配查询
示例代码:
from elasticsearch import Elasticsearch
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
"mappings": {
"properties": {
"grade": {
"type": "long"
},
"id": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
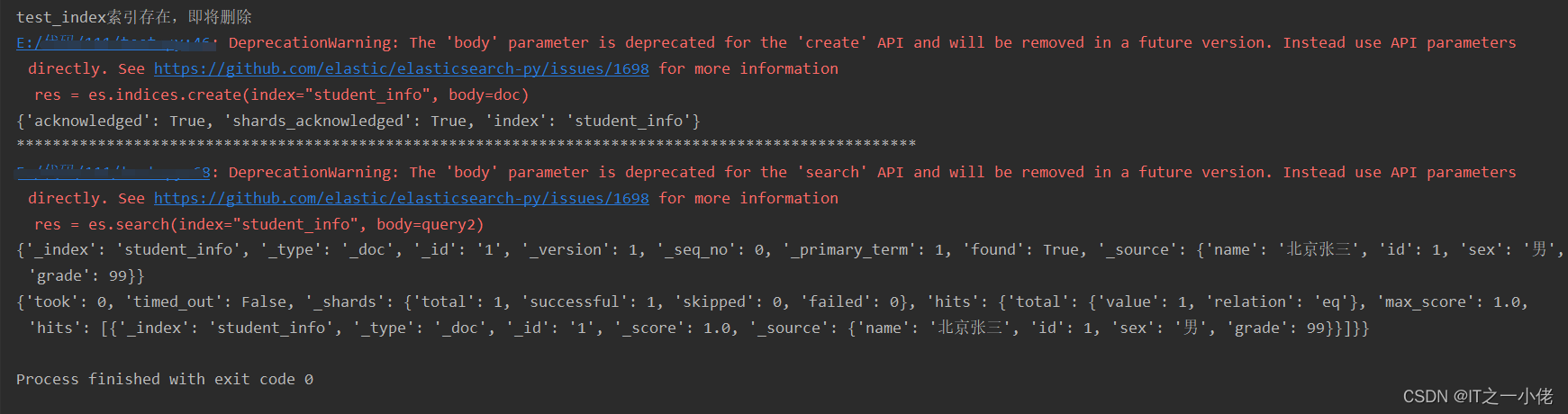
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="student_info"):
print('test_index索引存在,即将删除')
es.indices.delete(index="student_info")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="student_info", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="student_info", id='1', document={"name": "北京张三", "id": 1, "sex": "男", "grade": 99})
es.index(index="student_info", id='2', document={"name": "河北李四", "id": 2, "sex": "男", "grade": 98})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 查询数据
res = es.get(index="student_info", id=1)
print(res)
# 正则查询
query2 = {
"query": {
"regexp": {
"name.keyword": "(.*?)三(.*?)"
}
}
}
res = es.search(index="student_info", body=query2)
print(res)
运行结果:
14.查询数据排序
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
query = {
"query": {
"match_all": {}
},
"sort": [
{
"id": {
"order": "desc" # asc升序,desc降序
}
}
]
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

相关文章
- Python 操作 Kafka --- kafka-python
- Python脚本扫描给定网段的MAC地址表(scapy或 python-nmap)
- Python&JS宏 实现保留样式合并表格后拆分
- 如何快速学习python,学好python?能通过Python赚到的第一笔钱,有哪些经验可以分享吗?
- python中elasticsearch_dsl查询语句转换成es查询语句
- 全网通用Python点赞器
- 《python 与数据挖掘 》一1.3 Python开发环境的搭建
- 【Python】【PyPI】twine模块打包python项目上传pypi
- 使用python计算最大回撤
- python不起眼的知识点
- python if语句条件判断,三目运算
- Python 爬虫知识点 - XPath
- Python 相对路径和绝对路径--python实战(九)
- Python NLP教程之知识图谱,从文本构建知识,实现从文本或在线文章中提取知识库的管道(教程含源码)
- python进程绑定CPU的意义
- 【Python实战02】共享Python代码到PyPI社区
- 华为OD机试 - 合并数组(Python) | 机试题+算法思路+考点+代码解析 【2023】
- Python 工具 之 Windows 上 python 虚拟环境的搭建与简单使用的相关说明
- Python对文件的读写操作
- [Python]2分钟完成python + Selenium Web端自动化环境搭建,开启~~~
- Python编程基础:实验1——程序的控制结构
- 调用python 报R6034 错误