
python进程绑定CPU的意义
1. 绑定CPU后对计算密集型的任务可能会一定程度上提升运算性能:(小幅度的性能提升,甚至小幅度落后,总之就是差别不大)
对比1代码A:
import os
from multiprocessing import Process
from timeit import timeit
import numpy as np
cpu_avia = os.sched_getaffinity(os.getpid())
os.sched_setaffinity(os.getpid(), list(cpu_avia)[:1]) # 绑定两个核心
def func():
s = np.random.random(100)
for _ in range(10000000):
s += np.random.random(100)
t = timeit('func()', "from __main__ import func", number=100)
print(t)运行时间:
2340.2266417220235
对比1代码B:
import os
from multiprocessing import Process
from timeit import timeit
import numpy as np
def func():
s = np.random.random(100)
for _ in range(10000000):
s += np.random.random(100)
t = timeit('func()', "from __main__ import func", number=100)
print(t)运行时间:
2321.7808491662145
==========================
对比2代码A:
import os
from multiprocessing import Process
from timeit import timeit
import numpy as np
cpu_avia = os.sched_getaffinity(os.getpid())
os.sched_setaffinity(os.getpid(), list(cpu_avia)[:1]) # 绑定两个核心
def func():
s = np.random.random(100)
for _ in range(1000000000):
s += np.random.random(100)
t = timeit('func()', "from __main__ import func", number=1)
print(t)运行时间:
2405.4125552885234
对比2代码B:
import os
from multiprocessing import Process
from timeit import timeit
import numpy as np
def func():
s = np.random.random(100)
for _ in range(1000000000):
s += np.random.random(100)
t = timeit('func()', "from __main__ import func", number=1)
print(t)运行时间:
2415.607121781446
可以说,绑定CPU其实对于算法的运行性能影响不大,即使有提升也是微乎其微的。但是对于绑定CPU的作用个人认为还是分隔计算资源才是最有用的应用,这就是本文要说的第二点。
-----------------------------------------
2. 绑定CPU后可以实现计算资源的分隔
场景:
1. 一个主机有8个CPU内核,现在计划用4个CPU内核运行生产者进程,另外4个CPU内核运行消费者进程。
2. 消费者进程为每个CPU核心上运行一个消费者进程,因为消费者进程为计算密集型任务,为保证消费者进程不被生产者进程抢占计算资源,因此把CPU核心0-3绑定给生产者进程,CPU核心4-7绑定给消费者进程。消费者进程共有4个。
3. 生产者进程需要接收网络数据并进行数据处理,然后把处理后的数据通过进程消息队列的方式传输给消费者进程;消费者进程则不断的从消息队列中读取数据进行下一步的处理。
4. 生产者进程需要接收的网络源有100个,即socket要开100个。
解决方案1:
为生产者进程单独设置一个网络数据接收进程,由该进程接收网络数据,然后把网络数据传递给生产者进程,这样生产者进程的进程数量设置为4个即可以保证绑定的CPU核心达到充分的利益。此时网络IO操作由网络接收进程负责,数据处理的计算任务由4个生产进程负责。该种设计简单的说就是生产者部分设置一个网络接收进程和4个生产者进程。大致总体设计如下:
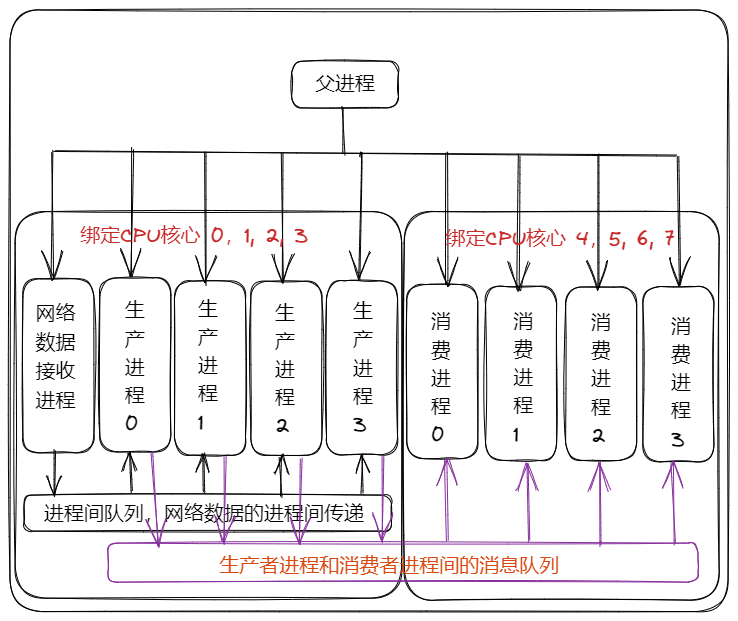
此时又出现了新的问题,那就是网络数据接收进程如何维护对100个socket数据的读取操作,使用轮询机制还是多线程阻塞等待,还是用异步的方式,不同的方式性能会有如何的影响。
对于网络数据接收进程来说,设计性能最高的方式就是使用异步的方式,而设计操作最简单的就是多线程的方式。
解决方案2:
方案2其实是对方案1的改进和补充,方案1中生产者部分中单独采用了一个网络数据接受进程,然后由该进程接收数据后再传递给其他生产者进程,但是如果由于某些原因,如数据量较大、数据难以进行序列化等原因难以进行进程间传递,因此给出方案2。
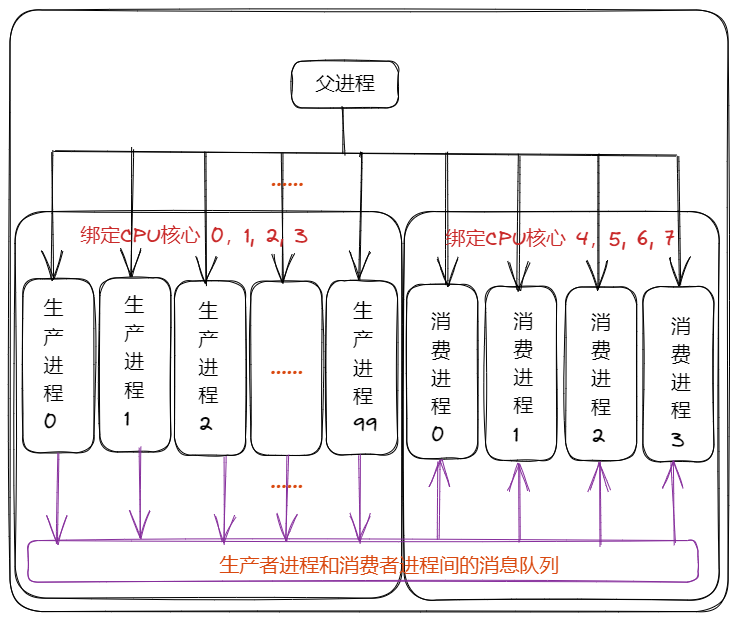
该种设计就是不使用网络数据接收进程,而是使用多个生产者进程的方式,每个生产者进程均负责一个socket数据的接收和处理。该种设计还是较大程度上依赖CPU锁定的设置,因为如果不是把这100个生产者进程锁定在0,1,2,3号CPU核心上,那么必然会出现100个进程同时进行数据处理而抢占消费者进程的计算资源的情况。
该种设计的最大好处就是简单,在编写具体代码的时候可以比较简单的快速完成;但是该种设置的最大坏处就是扩展性的问题,如果socket源过多,那么我们就需要建立大量的生产者进程,而大量的生产者进程进行切换的时候必然会占用资源,也就是说该种设计会随着生产进程数量的增加而极大的损失掉总体的性能。
这里再给出一个折中的方案,那就是在生产者进程中使用多线程或者异步,如下图:
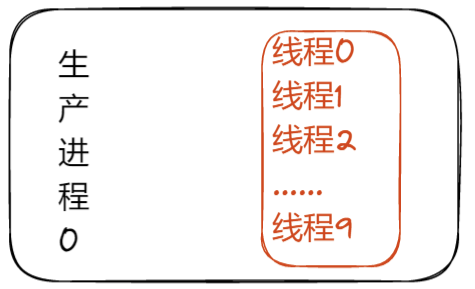
一个生产者进程中带有10个线程,10个线程分别监听10个socket,当然这里也可以使用异步方式来解决。
PS: 之所以有上面复杂的几种方案,归根到底就是因为python的多线程不能并发执行,多进程之间通信会造成性能损耗以及多方面的限制问题。
=====================================
相关:
相关文章
- python之simplejson,Python版的简单、 快速、 可扩展 JSON 编码器/解码器
- 理解 Python 的 Dataclasses第一篇(转)
- 使用python和tableau对数据进行抓取及可视化
- Python 日期和时间_python 当前日期时间_python日期格式化
- 【python cookbook】【字符串与文本】5.查找和替换文本
- python中日志logging模块的性能及多进程详解
- python中os模块获取路径的几种方式
- python: easyocr的安装和使用(easyocr 1.6.2 / Python 3.7.15 )
- python程序员都在用到5个酷毙的Python工具
- Python语言学习:利用python语言实现调用内部命令(python调用Shell脚本)—命令提示符cmd的几种方法
- Python编程:利用python编程实现对基于时间序列的数据(dataframe格式)按照指定时间范围进行单方向关联,不存在的日期补充为默认的NaN
- Python之tkinter:动态演示调用python库的tkinter带你进入GUI世界(text.insert/link各种事件)
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- python 怎样创建多个进程?
- 从0到1学Python丨图像平滑方法的两种非线性滤波:中值滤波、双边滤波
- python 根据输入的内容输出类型
- Python标准库:内置函数any(iterable)
- Python标准库:内置函数setattr(object, name, value)
- Python开发案例之用Python子进程关闭Excel自动化中的弹窗
- python 爬取链家
- python多进程假死
- python并发编程之多进程、多线程、异步和协程
- 【Python中面向对象的学习】
- python3(十四)Python 异常处理
- Python: 爬虫入门-python爬虫入门教程(非常详细)
- Python 3 自动化运维之psutil获取系统进程
- python内置函数__init__及__str__的区别