
文本相似度-bm25算法原理及实现
https://www.jianshu.com/p/1e498888f505
原理
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
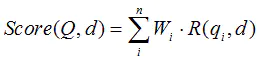
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
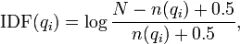
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:
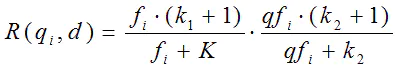
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
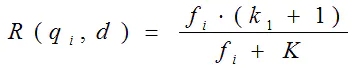
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
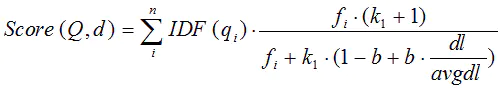
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
代码实现
import math
import jieba
from utils import utils
# 测试文本
text = '''
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,
所以它与语言学的研究有着密切的联系,但又有重要的区别。
自然语言处理并不是一般地研究自然语言,
而在于研制能有效地实现自然语言通信的计算机系统,
特别是其中的软件系统。因而它是计算机科学的一部分。
'''
class BM25(object):
def __init__(self, docs):
self.D = len(docs)
self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D
self.docs = docs
self.f = [] # 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数
self.df = {} # 存储每个词及出现了该词的文档数量
self.idf = {} # 存储每个词的idf值
self.k1 = 1.5
self.b = 0.75
self.init()
def init(self):
for doc in self.docs:
tmp = {}
for word in doc:
tmp[word] = tmp.get(word, 0) + 1 # 存储每个文档中每个词的出现次数
self.f.append(tmp)
for k in tmp.keys():
self.df[k] = self.df.get(k, 0) + 1
for k, v in self.df.items():
self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5)
def sim(self, doc, index):
score = 0
for word in doc:
if word not in self.f[index]:
continue
d = len(self.docs[index])
score += (self.idf[word]*self.f[index][word]*(self.k1+1)
/ (self.f[index][word]+self.k1*(1-self.b+self.b*d
/ self.avgdl)))
return score
def simall(self, doc):
scores = []
for index in range(self.D):
score = self.sim(doc, index)
scores.append(score)
return scores
if __name__ == '__main__':
sents = utils.get_sentences(text)
doc = []
for sent in sents:
words = list(jieba.cut(sent))
words = utils.filter_stop(words)
doc.append(words)
print(doc)
s = BM25(doc)
print(s.f)
print(s.idf)
print(s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域']))
相关文章
- 哈希算法原理【Java实现】
- 双链表算法原理【Java实现】
- 经典的7种排序算法 原理C++实现
- RSA算法原理
- Flink-容错机制-检查点原理和算法
- C#,基于视频的目标识别算法(Moving Object Detection)的原理、挑战及其应用
- manacher算法解题
- R语言数据挖掘2.2.5 基于最大频繁项集的GenMax算法
- 活在终极算法的世界,是怎样一种体验?
- DBoW2算法原理介绍
- 查找算法--跳跃查找(JumpSearch)、插值查找、指数查找及无界二分查找原理介绍及源码示例
- 【jvm系列-09】垃圾回收底层原理和算法以及JProfiler的基本使用
- hash算法 (hashmap 实现原理)
- 【多传感器融合】SORT算法原理
- Adaboost算法原理分析和实例+代码(简明易懂)
- 通信原理实验之线性均衡器-迫零算法【100010370】
- 八种排序算法原理及Java实现
- 《Hadoop与大数据挖掘》——2.5 K-Means算法原理及Hadoop MapReduce实现
- 《Hadoop与大数据挖掘》——2.6 TF-IDF算法原理及Hadoop MapReduce实现
- K-D TREE算法原理及实现
- PID控制器开发笔记之一:PID算法原理及基本实现
- 算法:comparable比较器的排序原理实现(二叉树中序排序)
- ECDHE椭圆曲线DH密钥交换算法的原理理解简单版
- 浅析HTTPS原理:网络通信的3大问题、对称加密算法、非对称加密算法、对称+非对称交换密钥具体流程及安全隐患、数字证书如何生成颁发如何验证、证书链、hash算法比较摘要防止篡改的流程、HMAC消息认证码对hash的优化、HTTPS的宏观安全模型、安全连接建立流程
- TF-IDF的算法原理以及Python实现
- 算法基础复盘笔记Day01【算法基础】—— 快速排序、归并排序、二分、高精度
- 华为OD机试 -查找单入口空闲区域(Python) | 机试题+算法思路+考点+代码解析 【2023】
- 续前篇---数据挖掘之聚类算法k-mediod(PAM)原理及实现
- MUSIC算法原理及MATLAB代码 阵列信号处理
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
- Java开发 - 常用算法深度讲解,让你再也不会忘记
- php与java通用AES加密解密算法
- 利用图文和代码深度解析操作系统OS的内存管理实现原理机制和算法
- Powell算法的原理与实现
- 随机化算法求定积分