
爬虫教程( 4 ) --- 分布式爬虫 scrapy-redis、集群
1、分布式爬虫 scrapy - redis
scrapy 分布式爬虫
文档:http://doc.scrapy.org/en/master/topics/practices.html#distributed-crawls
Scrapy 并没有提供内置的机制支持分布式(多服务器)爬取。不过还是有办法进行分布式爬取, 取决于您要怎么分布了。
如果您有很多spider,那分布负载最简单的办法就是启动多个Scrapyd,并分配到不同机器上。
如果想要在多个机器上运行一个单独的spider,那您可以将要爬取的 url 进行分块,并发送给spider。 例如:
首先,准备要爬取的 url 列表,并分配到不同的文件 url 里:
http://somedomain.com/urls-to-crawl/spider1/part1.list
http://somedomain.com/urls-to-crawl/spider1/part2.list
http://somedomain.com/urls-to-crawl/spider1/part3.list接着在3个不同的 Scrapd 服务器中启动 spider。spider 会接收一个(spider)参数 part , 该参数表示要爬取的分块:
curl http://scrapy1.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=1
curl http://scrapy2.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=2
curl http://scrapy3.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=3
scrapy-redis 分布式爬虫
scrapy-redis 巧妙的利用 redis 队列实现 request queue 和 items queue,利用 redis 的 set 实现 request 的去重,将 scrapy 从单台机器扩展多台机器,实现较大规模的爬虫集群
Scrapy-Redis 架构分析
scrapy 任务调度是基于文件系统,这样只能在单机执行 crawl。
scrapy-redis 将待抓取 request 请求信息 和 数据 items 信息 的存取放到 redis queue 里,使多台服务器可以同时执行 crawl 和 items process,大大提升了数据爬取和处理的效率。
scrapy-redis 是基于 redis 的 scrapy 组件,主要功能如下:
- 分布式爬虫。多个爬虫实例分享一个 redis request 队列,非常适合大范围多域名的爬虫集群
- 分布式后处理。爬虫抓取到的 items push 到一个 redis items 队列,这就意味着可以开启多个 items processes 来处理抓取到的数据,比如存储到 Mongodb、Mysql
- 基于 scrapy 即插即用组件。Scheduler + Duplication Filter、Item Pipeline、 Base Spiders
scrapy 原生架构
分析 scrapy-redis 的架构之前先回顾一下 scrapy 的架构

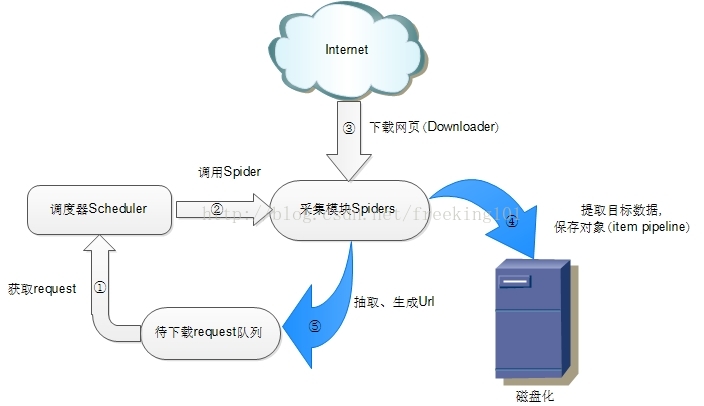
- 调度器(Scheduler):调度器维护 request 队列,每次执行取出一个 request。
- Spiders:Spider 是 Scrapy 用户编写用于分析 response,提取 item 以及跟进额外的 URL 的类。每个 spider 负责处理一个特定 (或一些) 网站。
- Item Pipeline:Item Pipeline 负责处理被 spider 提取出来的 item。典型的处理有清理、验证数据及持久化(例如存取到数据库中)。
如上图所示,scrapy-redis 在 scrapy 的架构上增加了 redis,基于 redis 的特性拓展了如下组件:
- 调度器(Scheduler)
scrapy-redis 调度器通过 redis 的 set 不重复的特性, 巧妙的实现了Duplication Filter去重(DupeFilter set存放爬取过的request)。 Spider 新生成的 request,将 request 的指纹到 redis 的 DupeFilter set 检查是否重复, 并将不重复的request push写入redis的request队列。 调度器每次从 redis 的 request 队列里根据优先级 pop 出一个 request, 将此 request 发给 spider 处理。 - Item Pipeline
将 Spider 爬取到的 Item 给 scrapy-redis 的 Item Pipeline, 将爬取到的 Item 存入 redis 的 items 队列。可以很方便的从 items 队列中提取 item, 从而实现 items processes 集群
总结
scrapy-redis 巧妙的利用 redis 实现 request queue 和 items queue,利用 redis 的 set 实现 request 的去重,将 scrapy 从单台机器扩展多台机器,实现较大规模的爬虫集群
scrapy-redis 安装
文档: https://scrapy-redis.readthedocs.org.
- 安装 scrapy-redis:pip install scrapy-redis
scrapy-redis 源码截图:

可以看到 scrapy-redis 的 spiders.py 模块,导入了 scrapy.spiders 的 Spider、CrawlSpider,然后重新写了两个类 RedisSpiders、RedisCrawlSpider,分别继承 Spider、CrawlSpider,所以如果要想从 redis 读取任务,需要把自己写的 spider 继承 RedisSpiders、RedisCrawlSpider,而不是 scrapy 的 Spider、CrawlSpider。。。
scrapy-redis 使用 项目案例( 抓取校花网图片 )
:http://www.521609.com/daxuexiaohua/
:https://www.51tietu.net/xiaohua/
(
scrapy_redis.spiders下有两个类 RedisSpider 和 RedisCrawlSpider,能够使 spider 从 Redis 读取 start_urls,然后执行爬取,若爬取过程中返回更多的 request url,那么它会继续进行直至所有的 request 完成之后,再从 redis start_urls 中读取下一个 url,循环这个过程 )
创建 scrapy-redis 的工程目录
方法 1:命令行执行:scrapy startproject MyScrapyRedis,然后自己写的 spider 继承 RedisSpider 或者 RedisCrawlSpider ,设置对应的 redis_key ,即队列的在 redis 中的 key。注意:这个需要手动 在 setting.py 里面配置设置。( 参考配置:https://github.com/rmax/scrapy-redis )
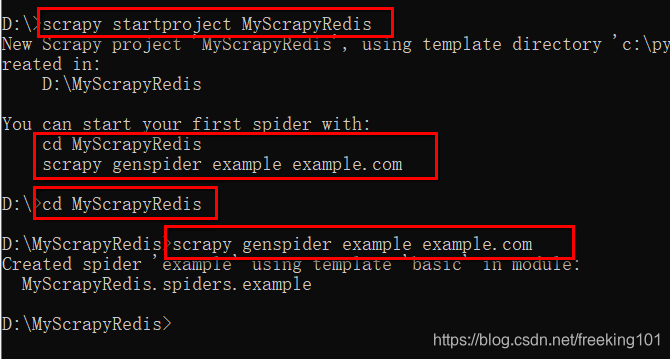
方法 2:使用 scrapy-redis 的 example 来修改。先从 github ( https://github.com/rmax/scrapy-redis ) 上拿到 scrapy-redis 的 example,然后将里面的 example-project 目录移到指定的地址。
tree 查看项目目录

修改 settings.py ( 参考配置:https://github.com/rmax/scrapy-redis )
下面列举了修改后的配置文件中与 scrapy-redis 有关的部分,middleware、proxy 等内容在此就省略了。
# Scrapy settings for example project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/topics/settings.html
#
BOT_NAME = 'example'
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
# USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# The class used to detect and filter duplicate requests.
# The default (RFPDupeFilter) filters based on request fingerprint using
# the scrapy.utils.request.request_fingerprint function.
# In order to change the way duplicates are checked you could subclass RFPDupeFilter and
# override its request_fingerprint method. This method should accept scrapy Request object
# and return its fingerprint (a string).
# By default, RFPDupeFilter only logs the first duplicate request.
# Setting DUPEFILTER_DEBUG to True will make it log all duplicate requests.
DUPEFILTER_DEBUG = True
# 指定使用 scrapy-redis 的 Scheduler
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 在 redis 中保持 scrapy-redis 用到的各个队列,从而允许暂停和暂停后恢复
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,默认是按照优先级排序
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
# 只在使用 SpiderQueue 或者 SpiderStack 是有效的参数,,指定爬虫关闭的最大空闲时间
SCHEDULER_IDLE_BEFORE_CLOSE = 10
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'example.pipelines.MyRedisPipeline': 400,
# 'scrapy_redis.pipelines.RedisPipeline': 400,
}
LOG_LEVEL = 'DEBUG'
# Introduce an artifical delay to make use of parallelism. to speed up the
# crawl.
# DOWNLOAD_DELAY = 1
# 指定redis的连接参数
# REDIS_PASS是我自己加上的redis连接密码,需要简单修改scrapy-redis的源代码以支持使用密码连接redis
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
# REDIS_URL = 'redis://user:pass@hostname:9001'
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Accept-Encoding': 'gzip, deflate, sdch',
}
查看 pipeline.py。注意:RedisPipeline 往 redis 写 item 数据时进行了序列化( 可以查看 RedisPipeline 的 _process_item 方法即刻看到进行了序列化),为了看到原始数据的 item,这里自定义了一个 MyRedisPipeline,继承自 RedisPipeline,重写 _process_item 方法,不进行序列化,直接把数据写到 redis 里。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/topics/item-pipeline.html
import json
from datetime import datetime
from scrapy_redis.pipelines import RedisPipeline
class ExamplePipeline(object):
def process_item(self, item, spider):
item["crawled"] = str(datetime.now().replace(microsecond=0))
item["spider"] = spider.name
return item
class MyRedisPipeline(RedisPipeline):
def _process_item(self, item, spider):
key = self.item_key(item, spider)
# data = self.serialize(item)
self.server.rpush(key, json.dumps(item, ensure_ascii=False))
return item
也可以不用重写,通过在 setting.py 里面配置 REDIS_ITEMS_SERIALIZER = 'json.dumps' 即可使用 json 序列化( # scrapy-redis 默认使用 ScrapyJSONEncoder 进行项目序列化 #You can use any importable path to a callable object. #REDIS_ITEMS_SERIALIZER = 'json.dumps',通过查看 scrapy-redis 的 pipelines.py )
参考:https://www.cnblogs.com/Alexephor/p/11446167.html

修改 items.py,增加我们最后要保存的 Profile 项
class Profile(Item):
# 提取头像地址
header_url = Field()
# 提取相册图片地址
pic_urls = Field()
username = Field()
# 提取内心独白
monologue = Field()
age = Field()
# youyuan
source = Field()
source_url = Field()
crawled = Field()
spider = Field()
RedisSpider 示例
以 example 下 mycrawler_redis.py 举例
运行:scrapy runspider example/spiders/myspider_redis.py
push urls to redis:redis-cli lpush myspider:start_urls http://baidu.com
RedisCrawlSpider 示例
首先添加任务,push urls to redis:( add_task.py ):

示例代码
import json
from scrapy.utils.project import get_project_settings
from scrapy_redis.connection import get_redis_from_settings
from scrapy_redis import connection
from scrapy_redis.queue import PriorityQueue
# def _encode_request(self, request):
# """Encode a request object"""
# obj = request_to_dict(request, self.spider)
# return self.serializer.dumps(obj)
#
#
# def _decode_request(self, encoded_request):
# """Decode an request previously encoded"""
# obj = self.serializer.loads(encoded_request)
# return request_from_dict(obj, self.spider)
def add_task_to_redis():
redis_key = 'start_urls:yy_spider_request'
url_string = 'http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/'
# 方法 1
server = get_redis_from_settings(get_project_settings())
server.lpush(redis_key, url_string)
# server.zadd(redis_key, url_string, 1000)
# 方法 2
# server = connection.from_settings(get_project_settings())
# server.execute_command('ZADD', redis_key, 1000, url_string)
if __name__ == '__main__':
# temp = 'test json string'
# print(json.dumps(temp))
add_task_to_redis()
pass
添加完任务,可以看到 redis 里面 的 start_urls:yy_spider_request 已经有添加的任务

添加任务到 Redis 有序集合(sorted set)
思考:
- 现在添加的任务是到 redis 的 list 里面,怎么添加任务到 redis 的 有序集合中 ???
- 怎么实现队列中添加的任务是 json 格式的字符串 ???
- 使用布隆去重代替 scrapy_redis (分布式爬虫)自带的 dupefilter ???
防禁封策略 --- 分布式实战
以 丁香园用药助手( http://drugs.dxy.cn/ ) 项目为例。架构示意图如下:
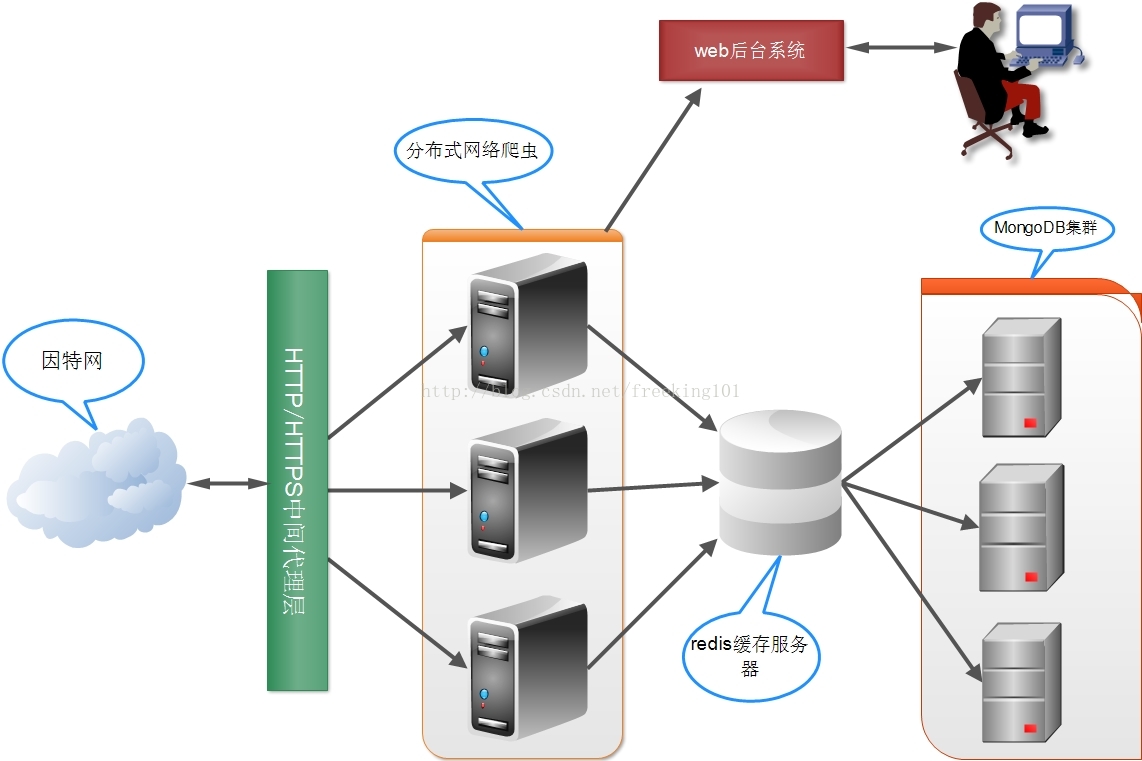
首先通过药理分类采集一遍,按照drug_id排序,发现:
我们要完成 http://drugs.dxy.cn/drug/[50000-150000].htm
正常采集:
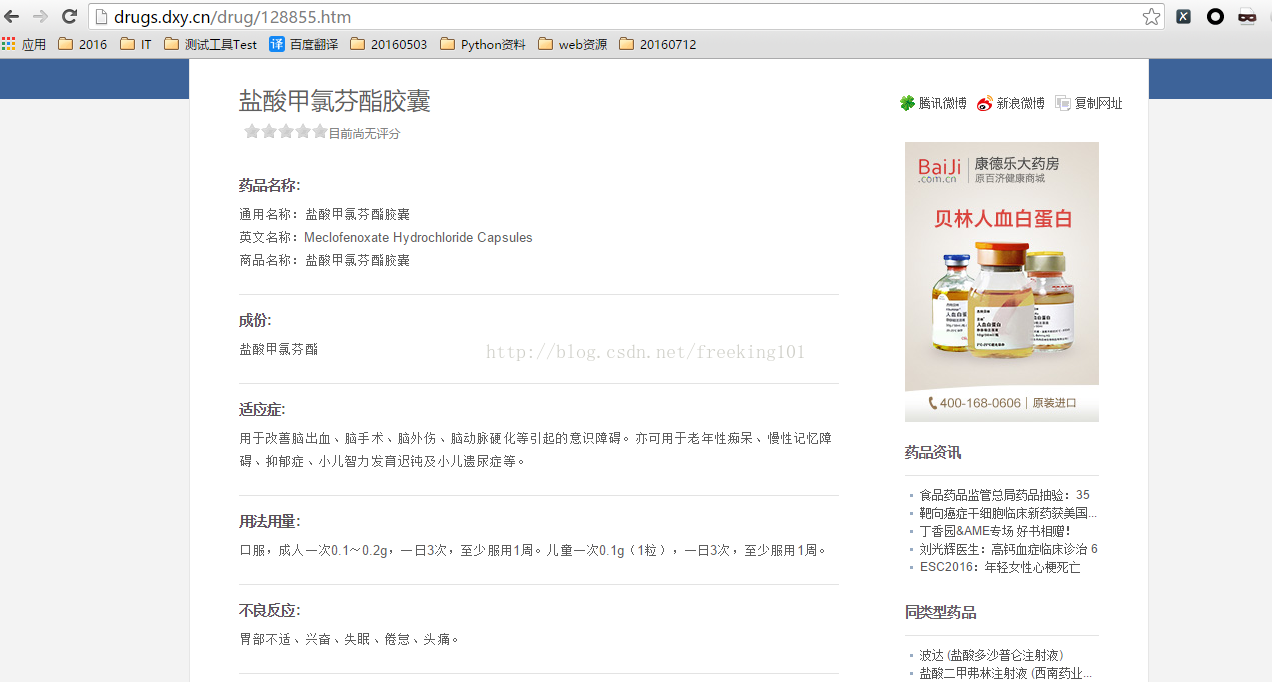
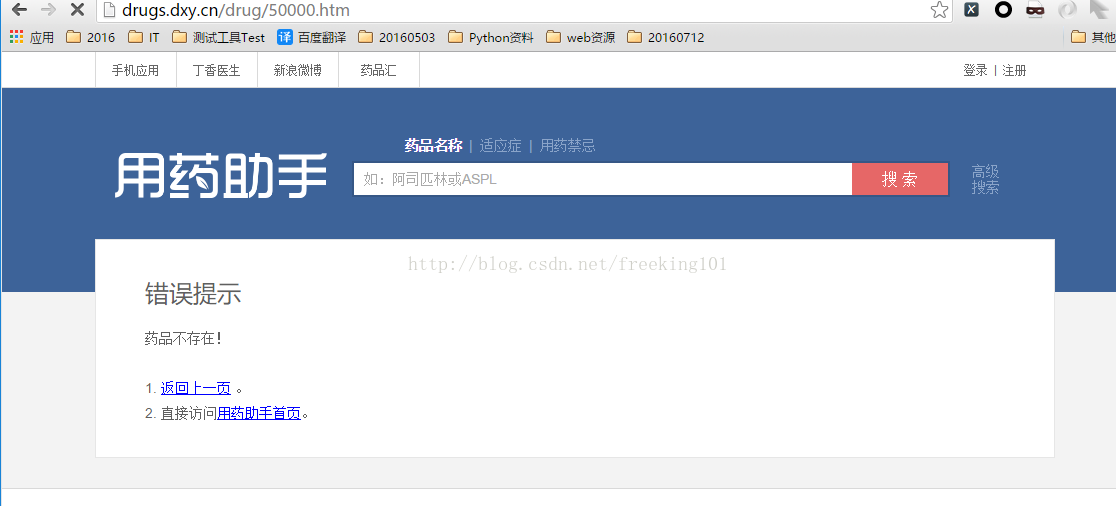
异常数据情况包括如下:
- 药品不存在
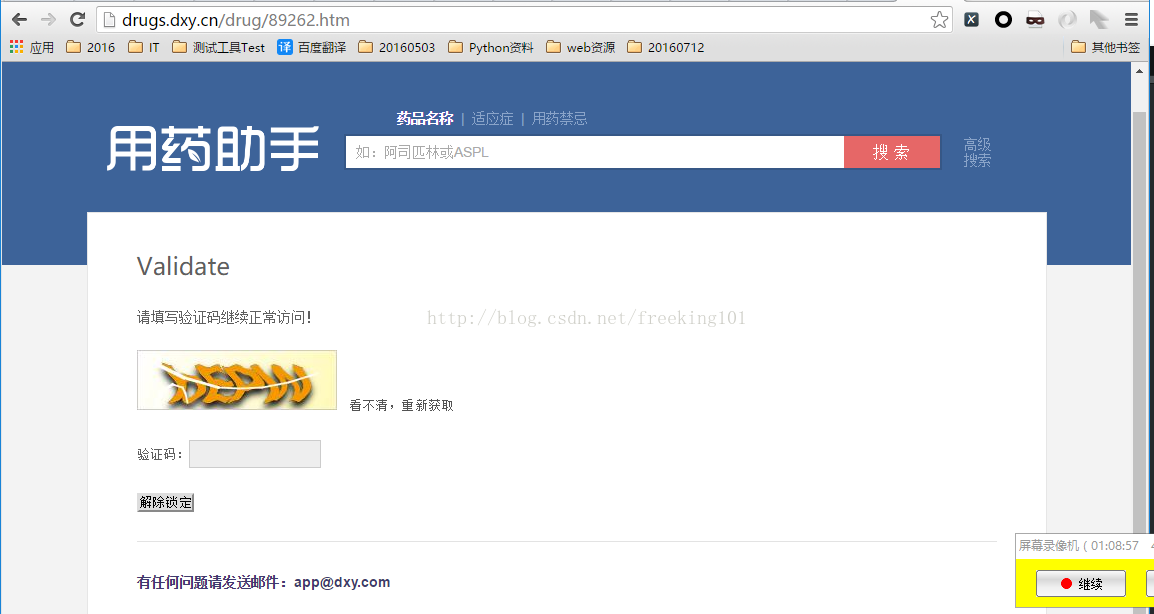
- 当采集频率过快,弹出验证码
- 当天采集累计操作次数过多,弹出禁止
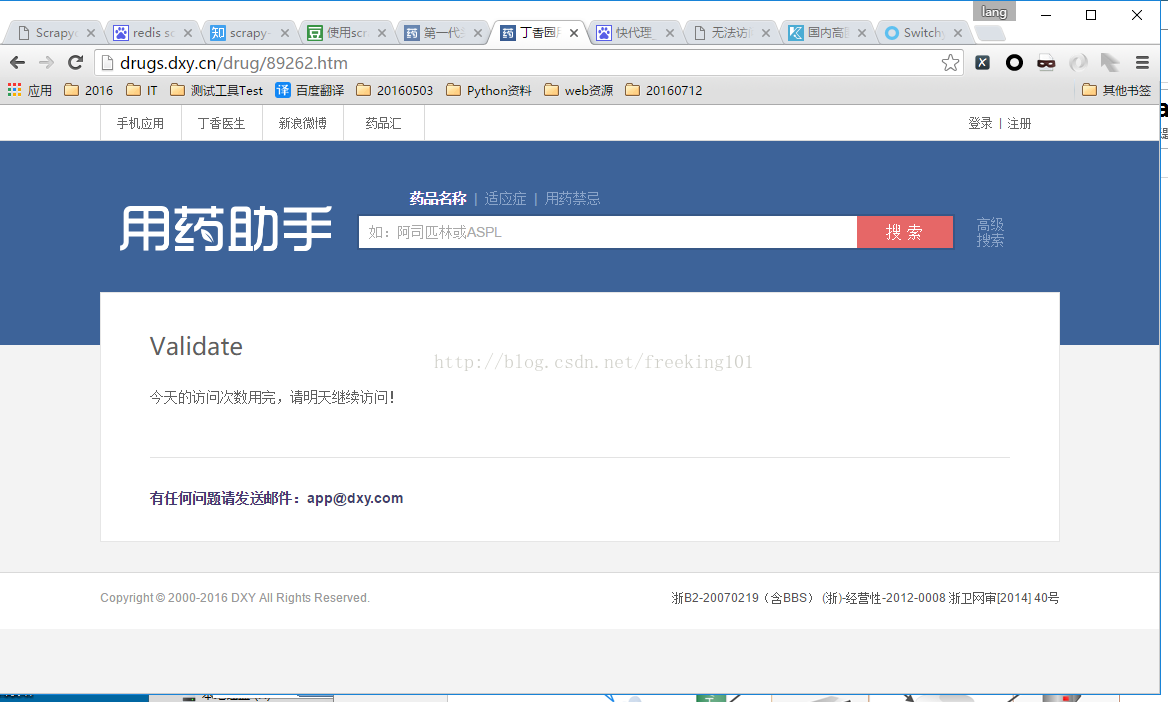
这个时候就需要用到代理
项目流程
1. 创建项目
scrapy startproject drugs_dxy
# 创建 spider
cd drugs_dxy/
scrapy genspider -t basic Drugs dxy.cn2. items.py 下添加类 DrugsItem
class DrugsItem(scrapy.Item):
# define the fields for your item here like:
#药品不存在标记
exists = scrapy.Field()
#药品id
drugtId = scrapy.Field()
#数据
data = scrapy.Field()
#标记验证码状态
msg = scrapy.Field()
pass3. 编辑 spider 下 DrugsSpider 类
# -*- coding: utf-8 -*-
# from drugs_dxy.items import DrugsItem
import re
import scrapy
from scrapy.spiders import Spider
class DrugsSpider(Spider):
name = "Drugs"
allowed_domains = ["dxy.cn"]
size = 60
def __init__(self):
super(DrugsSpider, self).__init__()
self.temp = None
def start_requests(self):
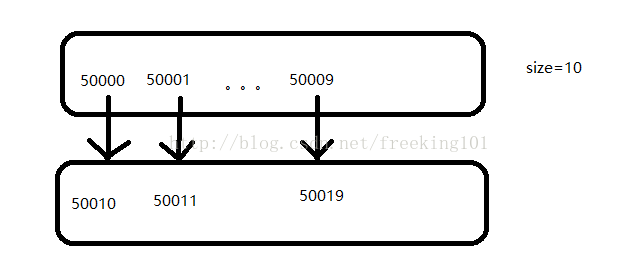
for i in range(50000, 50000 + self.size, 1):
url = f'http://drugs.dxy.cn/drug/{i}.htm'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
self.temp = None
# drug_Item = DrugsItem()
drug_item = dict()
drug_item["drugId"] = int(re.search(r'(\d+)', response.url).group(1))
if drug_item["drugId"] >= 150000:
return
url = f'http://drugs.dxy.cn/drug/{drug_item["drugId"] + self.size}.htm'
yield scrapy.Request(url=url, callback=self.parse)
if '药品不存在' in response.body:
drug_item['exists'] = False
yield drug_item
return
if '请填写验证码继续正常访问' in response.body:
drug_item["msg"] = '请填写验证码继续正常访问'
return
drug_item["data"] = {}
details = response.xpath("//dt")
for detail in details:
detail_name = detail.xpath('./span/text()').extract()[0].split(':')[0]
if detail_name == u'药品名称':
drug_item['data'][u'药品名称'] = {}
try:
detail_str = detail.xpath("./following-sibling::*[1]")
detail_value = detail_str.xpath('string(.)').extract()[0]
detail_value = detail_value.replace('\r', '').replace('\t', '').strip()
for item in detail_value.split('\n'):
item = item.replace('\r', '').replace('\n', '').replace('\t', '').strip()
name = item.split(u':')[0]
value = item.split(u':')[1]
drug_item['data'][u'药品名称'][name] = value
except BaseException as ex:
pass
else:
detail_str = detail.xpath("./following-sibling::*[1]")
detail_value = detail_str.xpath('string(.)').extract()[0]
detail_value = detail_value.replace('\r', '').replace('\t', '').strip()
# print detail_str,detail_value
drug_item['data'][detail_name] = detail_value
yield drug_item
if __name__ == '__main__':
from scrapy import cmdline
cmdline.execute('scrapy crawl Drugs'.split())
pass
4. Scrapy代理设置
4.1 在 settings.py 文件里
1)启用 scrapy_redis 组件
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# Specify the host and port to use when connecting to Redis (optional).
REDIS_HOST = '101.200.170.171'
REDIS_PORT = 6379
# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
#REDIS_URL = 'redis://user:pass@hostname:9001'
REDIS_PARAMS['password'] = 'redis_password'2) 启用 DownLoader 中间件;httpproxy
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'drugs_dxy.middlewares.ProxyMiddleware': 400,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
}3) 设置禁止跳转(code=301、302),超时时间90s
DOWNLOAD_TIMEOUT = 90
REDIRECT_ENABLED = False
4.2 在 drugs_dxy 目录下创建 middlewares.py 并编辑 (settings.py 同级目录)
# -*- coding: utf-8 -*-
import random
import base64
import Queue
import redis
class ProxyMiddleware(object):
def __init__(self, settings):
self.queue = 'Proxy:queue'
# 初始化代理列表
self.r = redis.Redis(host=settings.get('REDIS_HOST'),port=settings.get('REDIS_PORT'),db=1,password=settings.get('REDIS_PARAMS')['password'])
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def process_request(self, request, spider):
proxy={}
source, data = self.r.blpop(self.queue)
proxy['ip_port']=data
proxy['user_pass']=None
if proxy['user_pass'] is not None:
#request.meta['proxy'] = "http://YOUR_PROXY_IP:PORT"
request.meta['proxy'] = "http://%s" % proxy['ip_port']
#proxy_user_pass = "USERNAME:PASSWORD"
encoded_user_pass = base64.encodestring(proxy['user_pass'])
request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass
print "********ProxyMiddleware have pass*****" + proxy['ip_port']
else:
#ProxyMiddleware no pass
print request.url, proxy['ip_port']
request.meta['proxy'] = "http://%s" % proxy['ip_port']
def process_response(self, request, response, spider):
"""
检查response.status, 根据status是否在允许的状态码中决定是否切换到下一个proxy, 或者禁用proxy
"""
print("-------%s %s %s------" % (request.meta["proxy"], response.status, request.url))
# status不是正常的200而且不在spider声明的正常爬取过程中可能出现的
# status列表中, 则认为代理无效, 切换代理
if response.status == 200:
print 'rpush',request.meta["proxy"]
self.r.rpush(self.queue, request.meta["proxy"].replace('http://',''))
return response
def process_exception(self, request, exception, spider):
"""
处理由于使用代理导致的连接异常
"""
proxy={}
source, data = self.r.blpop(self.queue)
proxy['ip_port']=data
proxy['user_pass']=None
request.meta['proxy'] = "http://%s" % proxy['ip_port']
new_request = request.copy()
new_request.dont_filter = True
return new_requestredis-scrapy
settings.py 千万不能添加:LOG_STDOUT=True
2、scrapy-redis-cluster ( 集群版_1 )
scrapy_redis_cluster ( 已经不在维护 ):https://github.com/thsheep/scrapy_redis_cluster
scrapy-redis-cluster :https://pypi.org/project/scrapy-redis-cluster
scrapy-redis-cluster 已经不在维护 !!!!!
scrapyd-redis 的集群版
- 此包Python名称:scrapy-redis-cluster
- 目前版本: scrapy-redis-cluster 0.4
- 最后维护时间:Jul 5, 2018
- 摘要:scrapyd-redis的集群版
- 安装命令:pip install scrapy-redis-cluster
- 其它:scrapy-redis-cluster 这个Python第三方库的作者没有提供更多的项目描述信息了,2019-11-10 23:44:14。
scrapy-redis 使用 redis 集群进行分布式爬取
正常情况单机的redis可以满足scrapy-redis进行分布式爬取,可是如果单机的redis的内存过小,很容易导致系统内存不够,读取数据缓慢,如果使用docker运行redis,更加可能导致redis的容器的进程被杀掉。(笔者就曾经经常遇到这种情况,机器内存才8GB,上面跑了N个docker容器,一旦内存吃紧,某个容器就被kill掉,导致爬虫经常出问题)。
使用redis集群可以增加redis集体内存,防止出现上面的情况。
scrapy redis-cluster 很简单,只需要按照以下步骤:
1. 安装库:pip install scrapy-redis-cluster
2. 修改 settings 文件
# Redis集群地址
REDIS_MASTER_NODES = [
{"host": "192.168.10.233", "port": "30001"},
{"host": "192.168.10.234", "port": "30002"},
{"host": "192.168.10.235", "port": "30003"},
]
# 使用的哈希函数数,默认为6
BLOOMFILTER_HASH_NUMBER = 6
# Bloomfilter使用的Redis内存位,30表示2 ^ 30 = 128MB,默认为22 (1MB 可去重130W URL)
BLOOMFILTER_BIT = 22
# 不清空redis队列
SCHEDULER_PERSIST = True
# 调度队列
SCHEDULER = "scrapy_redis_cluster.scheduler.Scheduler"
# 去重
DUPEFILTER_CLASS = "scrapy_redis_cluster.dupefilter.RFPDupeFilter"
# queue
SCHEDULER_QUEUE_CLASS = 'scrapy_redis_cluster.queue.PriorityQueue'
3、scrapy-redis-sentinel( 集群版_2 )
scrapy-redis-sentinel :https://github.com/crawlaio/scrapy-redis-sentinel
pypi 地址:https://pypi.org/project/scrapy-redis-sentinel/
基于原项目 scrpy-redis:https://github.com/rmax/scrapy-redis
进行修改,修改内容如下:
- 添加了
Redis哨兵连接支持 - 添加了
Redis集群连接支持 - 添加了
Bloomfilter去重
安装第三方库:pip install scrapy-redis-sentinel
原版本 scrpy-redis 的所有配置都支持。优先级:哨兵模式 > 集群模式 > 单机模式
配置示例
# ----------------------------------------Bloomfilter 配置-------------------------------------
# 使用的哈希函数数,默认为 6
BLOOMFILTER_HASH_NUMBER = 6
# Bloomfilter 使用的 Redis 内存位,30 表示 2 ^ 30 = 128MB,默认为 30 (2 ^ 22 = 1MB 可去重 130W URL)
BLOOMFILTER_BIT = 30
# 是否开启去重调试模式 默认为 False 关闭
DUPEFILTER_DEBUG = False
# ----------------------------------------Redis 单机模式-------------------------------------
# Redis 单机地址
REDIS_HOST = "172.25.2.25"
REDIS_PORT = 6379
# REDIS 单机模式配置参数
REDIS_PARAMS = {
"password": "password",
"db": 0
}
# ----------------------------------------Redis 哨兵模式-------------------------------------
# Redis 哨兵地址
REDIS_SENTINELS = [
('172.25.2.25', 26379),
('172.25.2.26', 26379),
('172.25.2.27', 26379)
]
# REDIS_SENTINEL_PARAMS 哨兵模式配置参数。
REDIS_SENTINEL_PARAMS= {
"service_name":"mymaster",
"password": "password",
"db": 0
}
# ----------------------------------------Redis 集群模式-------------------------------------
# Redis 集群地址
REDIS_STARTUP_NODES = [
{"host": "172.25.2.25", "port": "6379"},
{"host": "172.25.2.26", "port": "6379"},
{"host": "172.25.2.27", "port": "6379"},
]
# REDIS_CLUSTER_PARAMS 集群模式配置参数
REDIS_CLUSTER_PARAMS= {
"password": "password"
}
# ----------------------------------------Scrapy 其他参数-------------------------------------
# 在 redis 中保持 scrapy-redis 用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理 redis queues
SCHEDULER_PERSIST = True
# 调度队列
SCHEDULER = "scrapy_redis_sentinel.scheduler.Scheduler"
# 去重
DUPEFILTER_CLASS = "scrapy_redis_sentinel.dupefilter.RFPDupeFilter"
# 指定排序爬取地址时使用的队列
# 默认的 按优先级排序( Scrapy 默认),由 sorted set 实现的一种非 FIFO、LIFO 方式。
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis_sentinel.queue.SpiderPriorityQueue'
# 可选的 按先进先出排序(FIFO)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis_sentinel.queue.SpiderStack'
# 可选的 按后进先出排序(LIFO)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis_sentinel.queue.SpiderStack'注:当使用集群时单机不生效
spiders 使用
原版本 scrpy-redis 使用方式
from scrapy_redis.spiders import RedisSpider
class Spider(RedisSpider):
...修改 RedisSpider 引入方式后,scrapy-redis-sentinel 的使用方式
from scrapy_redis_sentinel.spiders import RedisSpider
class Spider(RedisSpider):
...
使用示例:
修改 setting.py文件
ITEM_PIPELINES = {
'scrapy_redis_sentinel.pipelines.RedisPipeline': 543,
}
# Bloomfilter 配置
# 使用的哈希函数数,默认为 6
BLOOMFILTER_HASH_NUMBER = 6
# Bloomfilter 使用的 Redis 内存位,30 表示 2 ^ 30 = 128MB,默认为 30 (2 ^ 22 = 1MB 可去重 130W URL)
BLOOMFILTER_BIT = 30
# 是否开启去重调试模式 默认为 False 关闭
DUPEFILTER_DEBUG = False
# Redis 集群地址
REDIS_MASTER_NODES = [
{"host": "192.168.56.30", "port": "9000"},
{"host": "192.168.56.31", "port": "9000"},
{"host": "192.168.56.32", "port": "9000"},
]
# REDIS_CLUSTER_PARAMS 集群模式配置参数
REDIS_CLUSTER_PARAMS= {
# "password": "password"
}
# scrapy其他参数
# 在 redis 中保持 scrapy-redis 用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理 redis queues
SCHEDULER_PERSIST = True
# 调度队列
SCHEDULER = "scrapy_redis_sentinel.scheduler.Scheduler"
# 去重
DUPEFILTER_CLASS = "scrapy_redis_sentinel.dupefilter.RFPDupeFilter"
# 指定排序爬取地址时使用的队列
# 默认的 按优先级排序( Scrapy 默认),由 sorted set 实现的一种非 FIFO、LIFO 方式。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis_sentinel.queue.SpiderPriorityQueue'
# 可选的 按先进先出排序(FIFO)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis_sentinel.queue.SpiderStack'
# 可选的 按后进先出排序(LIFO)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis_sentinel.queue.SpiderStack'修改 spider
from scrapy_redis_sentinel.spiders import RedisSpider
class scrapy_spider(RedisSpider):
......Redis 集群( Redis5.0.7集群搭建:https://blog.csdn.net/pcengineercn/article/details/104502061 )
经过调试,修复了一个bug(使用默认爬取队列时会报错),需要将源码中的 PriorityQueue(位于 Python 安装目录 /lib/python3.6/site-packages/scrapy_redis_sentinel/queue.py)替换为如下
class PriorityQueue(Base):
"""Per-spider priority queue abstraction using redis' sorted set"""
def __len__(self):
"""Return the length of the queue"""
return self.server.zcard(self.key)
def push(self, request):
"""Push a request"""
data = self._encode_request(request)
score = -request.priority
# We don't use zadd method as the order of arguments change depending on
# whether the class is Redis or StrictRedis, and the option of using
# kwargs only accepts strings, not bytes.
self.server.execute_command("ZADD", self.key, score, data)
def pop(self, timeout=0):
"""
Pop a request
timeout not support in this queue class
"""
if not isinstance(self.server, RedisCluster):
# use atomic range/remove using multi/exec
pipe = self.server.pipeline()
pipe.multi()
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])
# 使用集群的时候不能使用 multi/exec 来完成一个事务操作;使用lua脚本来实现类似功能
pop_lua_script = """
local result = redis.call('zrange', KEYS[1], 0, 0)
local element = result[1]
if element then
redis.call('zremrangebyrank', KEYS[1], 0, 0)
return element
else
return nil
end
"""
script = self.server.register_script(pop_lua_script)
results = script(keys=[self.key])
if results:
return self._decode_request(results)
相关文章
- python爬虫知识点总结(十四)使用Redis和Flask维护Cookies池
- 深入理解MVC C#+HtmlAgilityPack+Dapper走一波爬虫 StackExchange.Redis 二次封装 C# WPF 用MediaElement控件实现视频循环播放 net 异步与同步
- Redis 入门指令
- 96 爬虫 - scrapy-redis实战(七)
- 91 爬虫 - scrapy-redis实战(二)
- 87 爬虫 - scrapy-redis源码分析(queue)
- 84 爬虫 - scrapy-redis源码分析(dupefilter)
- redis性能监控(一): Redis Info 命令 - 获取 Redis 服务器的各种信息和统计数值
- Redis——Lettuce连接redis集群
- Redis——maven、spring、jedis快速搭建redis工程
- Redis开发 - 1. 认识redis
- Shiro Redis注入失败,shiro导致redis不能注入
- Linux Redis 主从复制,Redis slaveof replicaof主从复制,redis-sentinel哨兵
- 扩展thinkphp5的redis类方法
- redis在linux中安装,java端代码jedis和jedisPool
- lettuce连接池连接redis失败
- Redis(1.17)redis客户端管理
- Golang中通过go-redis操作Redis
- 曹工说Redis源码(2)-- redis server 启动过程解析及简单c语言基础知识补充
- Scrapy爬虫(九):scrapy的调试技巧
- .net下 本地锁、redis分布式锁、zk分布式锁的实现
- java连接redis使用jedis