
爬虫教程( 3 ) --- 手机 APP 数据抓取
1. Fiddler 设置
这是使用 fiddler 进行手机 app 的抓包,也可以使用 Charles,burpSuite 等。。。
- 电脑安装 Fiddler,
- 手机 和 安装 fiddler 的电脑处于同一个网络里, 否则手机不能把 HTTP 发送到 Fiddler 的机器上来。
配置 Fiddler,允许"远程连接"。用 Fiddler 对 Android 应用进行抓包
启动Fiddler,打开菜单栏中的 Tools > Fiddler Options,打开“Fiddler Options”对话框。

在Fiddler Options”对话框切换到“Connections”选项卡,然后勾选“Allow romote computers to connect”后面的复选框,然后点击“OK”按钮。

在本机命令行输入:ipconfig,找到本机的 ip 地址。

2. 移动设备设置
2.1. 安卓手机设置
Android 设备上的代理服务器设置“”
- 打开 android 设备的 “设置”->“WLAN”,找到你要连接的网络,在上面长按,然后选择“修改网络”,弹出网络设置对话框,在接下来弹出的对话框中,勾选“显示高级选项”。在接下来显示的页面中,点击“代理”,选择“手动”。然后在“代理服务器主机名”后面的输入框输入电脑的ip地址,在“代理服务器端口”后面的输入框输入8888,然后点击“保存”按钮。
代理服务器主机名设为 PC 的 IP,代理服务器端口设为Fiddler上配置的端口8888,点"保存"。
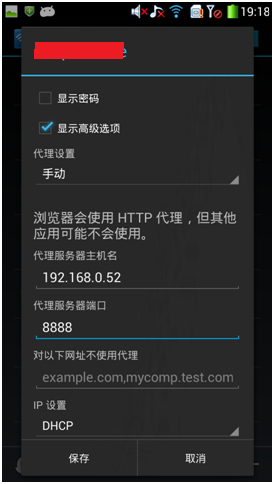
然后启动 android 设备中的浏览器,访问百度的首页,在 fiddler 中可以看到完成的请求和响应数据。
2.2. IOS 应用进行抓包
打开 IPhone, 找到网络连接, 打开 HTTP 代理, 输入 Fiddler 所在机器的 IP 地址(比如:192.168.1.104) 以及 Fiddler 的端口号8888

2.3 安装证书、捕获 HTTPS
只能捕获 HTTP,而不能捕获 HTTPS 的解决办法:
- 为了让 Fiddler 能捕获 HTTPS 请求,需要在 安卓设备 或者 苹果设备上安装 证书
IOS 设备步骤:
- 首先要知道 Fiddler 所在的机器的 IP 地址:假如我安装了 Fiddle r的机器的IP地址是:192.168.1.104
- 打开IPhone 的Safari, 访问 http://192.168.0.52:8888, 点"FiddlerRoot certificate" 然后安装证书

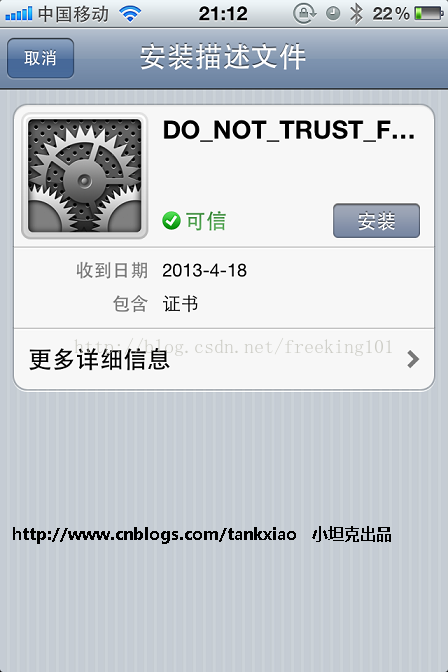
过证书校验
上面的设置还不能抓像招商银行、支付宝等 APP的 https 包,因为这些 APP 对 https 证书进行了校验,还需要将 Fiddler 代理服务器的证书导到 Android 设备上才能抓这些 APP 的包
导入的过程:
打开浏览器,在地址栏中输入代理服务器的IP和端口,会看到一个Fiddler提供的页面:

点击页面中的 “FiddlerRootcertificate” 链接,接着系统会弹出对话框:

输入一个证书名称,然后直接点“确定”就好了。
注意:用完了, 记得把 IPhone 上的 Fiddle r代理关闭, 以免 IPhone 上不了网。
也可以使用模拟器,例如:雷电、夜神、蓝叠 等等。。
3. 斗鱼app、妹子图app
斗鱼 官网:https://www.douyu.com/ 斗鱼 app 下载:https://www.douyu.com/client?tab=client#mobile
可以到 妹子图官网 下载 妹子图app
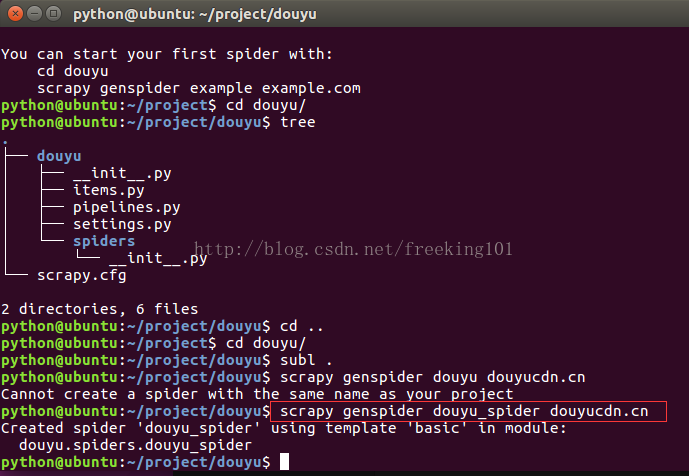
创建项目 'douyu'
scrapy startproject douyu树形图展示项目
cd douyu/
tree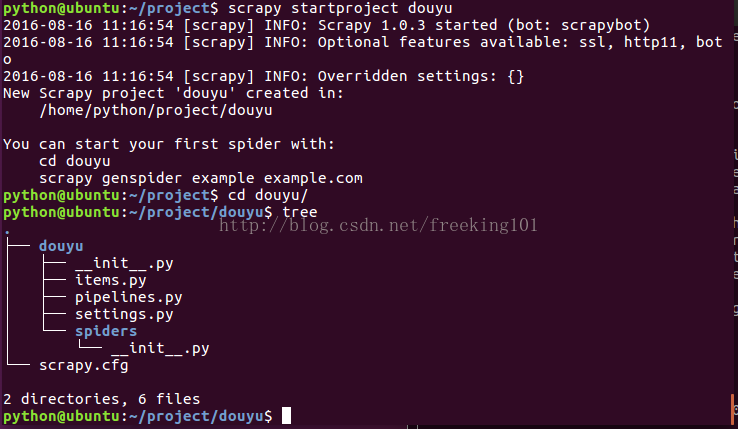
Sublime 打开项目
subl .
生成采集模块 spider
使用 genspider 在当前项目中创建 spider。语法: scrapy genspider [-t template] <name> <domain>
$ scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
$ scrapy genspider -d basic
import scrapy
class $classname(scrapy.Spider):
name = "$name"
allowed_domains = ["$domain"]
start_urls = (
'http://www.$domain/',
)
def parse(self, response):
pass
$ scrapy genspider -t basic example example.com
Created spider 'example' using template 'basic' in module:
mybot.spiders.example创建:
scrapy genspider douyu_spider douyucdn.cn
编辑项目
item.py
import scrapy
class DouyuItem(scrapy.Item):
# define the fields for your item here like:
data = scrapy.Field()
image_path = scrapy.Field()
pass
setting.py
设置 USER_AGENT
USER_AGENT = 'DYZB/2.271 (iPhone; iOS 9.3.2; Scale/3.00)'
douyu_spider.py
# -*- coding: utf-8 -*-
import json
import scrapy
class DouYuSpider(scrapy.spiders.Spider):
name = 'douyu_spider'
allowed_domains = ["douyucdn.cn"]
'''添加内容'''
offset = 0
start_urls = [f'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset={offset}']
def parse(self, response):
"""添加内容"""
data = json.loads(response.body)['data']
if not data:
return
for it in data:
# item = DouyuItem()
item = dict()
item['image_url'] = it['vertical_src']
item['data'] = it
# yield item
print(item)
self.offset += 20
yield scrapy.Request(
f'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset={self.offset}',
callback=self.parse
)
if __name__ == '__main__':
from scrapy import cmdline
cmdline.execute('scrapy crawl douyu_spider'.split())
pass
pipeline.py
文件系统存储: 文件以它们URL的 SHA1 hash 作为文件名
sha1sum sha1sum对文件进行唯一较验的hash算法,
用法: sha1sum [OPTION] [FILE]... 参数: -b, --binary 二进制模式读取 -c, --check 根据sha1 num检查文件 -t, --text 文本模式读取(默认)
举例:
f51be4189cce876f3b1bbc1afb38cbd2af62d46b scrapy.cfg{ 'image_path': 'full/9fdfb243d22ad5e85b51e295fa60e97e6f2159b2.jpg', 'image_url': u'http://staticlive.douyucdn.cn/upload/appCovers/845876/20160816/c4eea823766e2e5e018eee6563e4c420_big.jpg' }测试:
sudo vi test.txt
拷贝内容
http://staticlive.douyucdn.cn/upload/appCovers/845876/20160816/c4eea823766e2e5e018eee6563e4c420_big.jpg
sha1sum test.txt
9fdfb243d22ad5e85b51e295fa60e97e6f2159b2 test.txt
参考文档:http://doc.scrapy.org/en/latest/topics/media-pipeline.html
下面是你可以在定制的图片管道里重写的方法:
class scrapy.pipelines.images.ImagesPipeline ( ImagesPipeline 是 FilesPipeline 的扩展 )
get_media_requests(item, info)
管道会得到文件的 URL 并从项目中下载。需要重写 get_media_requests() 方法,
并对各个图片 URL 返回一个 Request。( Must return a Request for each image URL. )def get_media_requests(self, item, info): for image_url in item['image_urls']: yield scrapy.Request(image_url)
item_completed(results, item, info)
当它们完成下载后,结果将以2-元素的元组列表形式传送到item_completed() 方法 results 参数: 每个元组包含 (success, file_info_or_error):
-
success是一个布尔值,当图片成功下载时为True,因为某个原因下载失败为False -
file_info_or_error是一个包含下列关键字的字典(如果成功为 True)或者出问题时为Twisted Failure- url - 文件下载的url。这是从 get_media_requests() 方法返回请求的url。
- path - 图片存储的路径
- checksum - 图片内容的
MD5 hash
下面是
item_completed(results, items, info)中 results 参数的一个典型值:
[(True,
{'checksum': '2b00042f7481c7b056c4b410d28f33cf',
'path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg',
'url': 'http://staticlive.douyucdn.cn/upload/appCovers/420134/20160807/f18f869128d038407742a7c533070daf_big.jpg'}),
(False,
Failure(...))]默认 get_media_requests() 方法返回 None ,这意味着项目中没有文件可下载。
item_completed(results, items, info)
当图片请求完成时(要么完成下载,要么因为某种原因下载失败),该方法将被调用
item_completed() 方法需要返回一个输出,其将被送到随后的项目管道阶段,因此你需要返回(或者丢弃)项目
举例:
其中我们将下载的图片路径(传入到results中)存储到file_paths 项目组中,如果其中没有图片,我们将丢弃项目:
from scrapy.exceptions import DropItem
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
'''
image_paths=s[]
for ok, x in results:
if ok:
image_paths.append(x['path'])
return image_paths
'''
if not image_paths :
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item默认情况下,item_completed()方法返回项目
定制图片管道:
下面是项目图片管道
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class ImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
image_url = item['image_url']
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_path'] = image_paths[0]
return item启用pipelines
设置图片下载位置
是定义在 IMAGES_STORE 设置里的文件夹
IMAGES_STORE = '/home/python/project/douyu/photos'启用PIPELINES:设置item后处理模块
ITEM_PIPELINES = {
'douyu.pipelines.ImagesPipeline': 300,
}运行爬虫
scrapy runspider douyu/spiders/douyu_spider.py
或者是 scrapy crawl douyu_spider项目还缺什么? item 存储、pipeline.py 编写
import json
import codecs
class JsonWriterPipeline(object):
def __init__(self):
self.file = codecs.open('items.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()启用 JsonWriterPipeline 编写
ITEM_PIPELINES = {
'douyu.pipelines.ImagesPipeline': 300,
'douyu.pipelines.JsonWriterPipeline': 800,
}再次运行
scrapy crawl douyu_spider
美团 App 热门商圈团购采集 (1)
环境:针对美团版本5.4
在 tutorial 项目下,新建一个 spider
scrapy genspider -t basic Meituan_City meituan.com编辑items.py
class MeituanCity(Item):
data = Field()编辑 Meituan_City.py
# -*- coding: utf-8 -*-
import scrapy
import json
from tutorial.items import MeituanCity
class MeituanCitySpider(scrapy.Spider):
name = "Meituan_City"
allowed_domains = ["meituan.com"]
start_urls = (
'http://api.mobile.meituan.com/group/v1/city/list?show=all',
)
def parse(self, response):
data = json.loads(response.body)
for item in data['data']:
cityId = item['id']
# http://api.mobile.meituan.com/group/v2/area/list?cityId=42&spatialFields=center
url = 'http://api.meituan.com/group/v2/area/list?cityId=%s&spatialFields=center' % cityId
print url
yield scrapy.Request(
url,
callback=self.Parse_Geo,
meta={'item': item}
)
break
def Parse_Geo(self, response):
print response.url
data = json.loads(response.body)
metaitem = response.meta['item']
# 商区信息
subareasinfo = dict()
if 'data' in data:
if 'subareasinfo' in data['data']:
for item in data['data']['subareasinfo']:
subareasinfo[item['id']] = item
if 'data' in data:
if 'areasinfo' in data['data']:
for line in data['data']['areasinfo']:
# 行政区
districtName = line['name']
districtId = line['id']
for tmp in line['subareas']:
# 商圈信息
area = subareasinfo[tmp]
center = area['center']
center = center.replace('POINT(', '').replace(')', '').split()
if len(center) > 1:
lat = center[1]
lng = center[0]
longitude = None
latitude = None
try:
longitude = str(int(float(lng) * 1000000))
latitude = str(int(float(lat) * 1000000))
except:
pass
Item = MeituanCity()
Item['data'] =dict()
geoItem=Item['data']
# 城市信息
geoItem['cityid'] = metaitem['id']
geoItem['cityname'] = metaitem['name']
# 行政区
geoItem['districtId'] = districtId
geoItem['districtName'] = districtName
# 商圈
geoItem['SubAreaId'] = area['id']
geoItem['secondArea'] = area['name']
# 经纬度
geoItem['longitude'] = longitude
geoItem['latitude'] = latitude
yield Item此时运行:
scrapy runspider tutorial/spiders/Meituan_City.py
美团 App 热门商圈团购采集 (2)
把上节内容生成的城市信息 items.json改成city_items.json 作为第二部分爬虫的启动数据
添加items.py
class MeituanItem(Item):
data = Field()创建模板:
scrapy genspider -t basic Meituan_meishi meituan.com添加以下代码到Meituan_meishi.py
# -*- coding: utf-8 -*-
import scrapy
import codecs
import json
from tutorial.items import MeituanItem
import re
class MeituanMeishiSpider(scrapy.Spider):
'''
美食团购页面信息采集
'''
name = "Meituan_meishi"
allowed_domains = ["meituan.com"]
'''
start_urls = (
'http://www.meituan.com/',
)
'''
offset = 0
def start_requests(self):
file = codecs.open('city_items.json', 'r', encoding='utf-8')
for line in file:
item = json.loads(line)
cityid = item['data']['cityid']
latitude = item['data']['latitude']
longitude= item['data']['longitude']
lat = round(float(latitude), 6)
lng= round(float(longitude), 6)
url = 'http://api.mobile.meituan.com/group/v4/deal/select/city/42/cate/1?sort=defaults&mypos='+ str(lat) +'%2C'+ str(lng) +'&offset=0&limit=15'
yield scrapy.Request(url,callback=self.parse)
break
file.close()
def parse(self, response):
'''
数据存储以及翻页操作
'''
item = MeituanItem()
data = json.loads(response.body)
item['data']=dict()
item['data'] = data
yield item
offset = re.search('offset=(\d+)',response.request.url).group(1)
url = re.sub('offset=\d+','offset='+str(int(offset)+15),response.request.url)
yield scrapy.Request(url,callback=self.parse)运行:scrapy runspider tutorial/spiders/Meituan_meishi.py
采集方案策略设计
首先大的地方,我们想抓取某个数据源,我们要知道大概有哪些路径可以获取到数据源,基本上无外乎三种:
-
PC端网站
-
针对移动设备响应式设计的网站(也就是很多人说的 H5, 虽然不一定是H5);
-
移动 App
原则是能抓移动App的,最好抓移动App,如果有针对移动设备优化的网站,就抓针对移动设备优化的网站,最后考虑PC网站。因为移动 App 基本都是 API 很简单,而移动设备访问优化的网站一般来讲都是结构简单清晰的 HTML,而 PC 网站自然是最复杂的了;针对 PC 端网站和移动网站的做法一样,分析思路可以一起讲,移动App单独分析。
网站类型的分析
首先是网站类的,使用的工具就是 Chrome,建议用 Chrome 的隐身模式,分析时不用频繁清除 cookie,直接关闭窗口就可以了。
具体操作步骤如下:
-
输入网址后,先不要回车确认,右键选择审查元素,然后点击网络,记得要勾上preserve log选项,因为如果出现上面提到过的重定向跳转,之前的请求全部都会被清掉,影响分析,尤其是重定向时还加上了Cookie;
-
接下来观察网络请求列表,资源文件,例如css,图片基本都可以忽略,第一个请求肯定就是该链接的内容本身,所以查看源码,确认页面上需要抓取的内容是不是在HTML标签里面,很简单的方法,找到自己要找的内容,看到父节点,然后再看源代码里面该父节点里面有没有内容,如果没有,那么一定是异步请求,如果是非异步请求,直接抓该链接就可以了。 分析异步请求,按照网络列表,略过资源文件,然后点击各个请求,观察是否在返回时包含想要的内容,有几个方法:
-
内容比较有特点,例如人的属性信息,物品的价格,或者微博列表等内容,直接观察可以判断是不是该异步请求;
-
知道异步加载的内容节点或者父节点的class或者id的名称,找到js代码,阅读代码得到异步请求; 确认异步请求之后,就是要分析异步请求了,简单的,直接请求异步请求,能得到数据,但是有时候异步请求会有限制,所以现在分析限制从何而来。
针对分析对请求的限制,思路是逆序方法。
-
先找到最后一个得到内容的请求,然后观察headers,先看post数据或者url的某个参数是不是都是已知数据,或者有意义数据,如果发现不确定的先带上,只是更改某个关键字段,例如page,count看结果是不是会正常,如果不正常,比如多了个token,或者某个字段明显被加密,例如用户名密码,那么接下来就要看JS的代码,看到底是哪个函数进行了加密,一般会是原生JS代码加密,那么看到代码,直接加密就行,如果是类似RSA加密,那么就要看公钥是从何而来,如果是请求得到的,那么就要往上分析请求,另外如果是发现请求headers里面有陌生字段,或者有Cookie也要往上看请求,Cookie在哪一步设置的;
-
接下来找到刚刚那个请求未知来源的信息,例如Cookie或者某个加密需要的公钥等等,看看上面某个请求是不是已经包含,依次类推。
App 的分析
App 类使用的工具是 Fidder,手机和电脑在一个局域网内,先用 Fidde r配置好端口,然后手机设置代理,ip 为电脑的 ip,端口为设置的端口,然后如果手机上请求网络内容时,Fidder 会显示相应地请求,那么就 ok 了,分析的大体逻辑基本一致,限制会相对少很多,但是也有几种情况需要注意:
- 加密,App有时候也有一些加密的字段,这个时候,一般来讲都会进行反编译进行分析,找到对应的代码片段,逆推出加密方法;
- gzip压缩或者base64编码,base64编码的辨别度较高,有时候数据被gzip压缩了,不过Charles都是有自动解密的;
- https证书,有的https请求会验证证书, Fidder提供了证书,可以在官网找到,手机访问,然后信任添加就可以。
爬虫搜索策略
在爬虫系统中,待抓取 URL 队列是很重要的一部分。待抓取 URL 队列中的 URL 以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些 URL 排列顺序的方法,叫做抓取策略。
1、 深度优先搜索策略(顺藤摸瓜)(Depth-First Search)
即图的深度优先遍历算法。网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
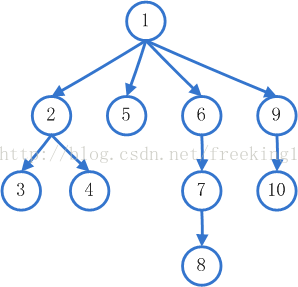
2、 广度(宽度)优先搜索策略(Breadth First Search)
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。
广度优先搜索和深度优先搜索
深度优先搜索算法涉及的是堆栈
广度优先搜索涉及的是队列。
堆栈(stacks)具有后进先出(last in first out,LIFO)的特征
队列(queue)是一种具有先进先出(first in first out,LIFO)特征的线性数据结构
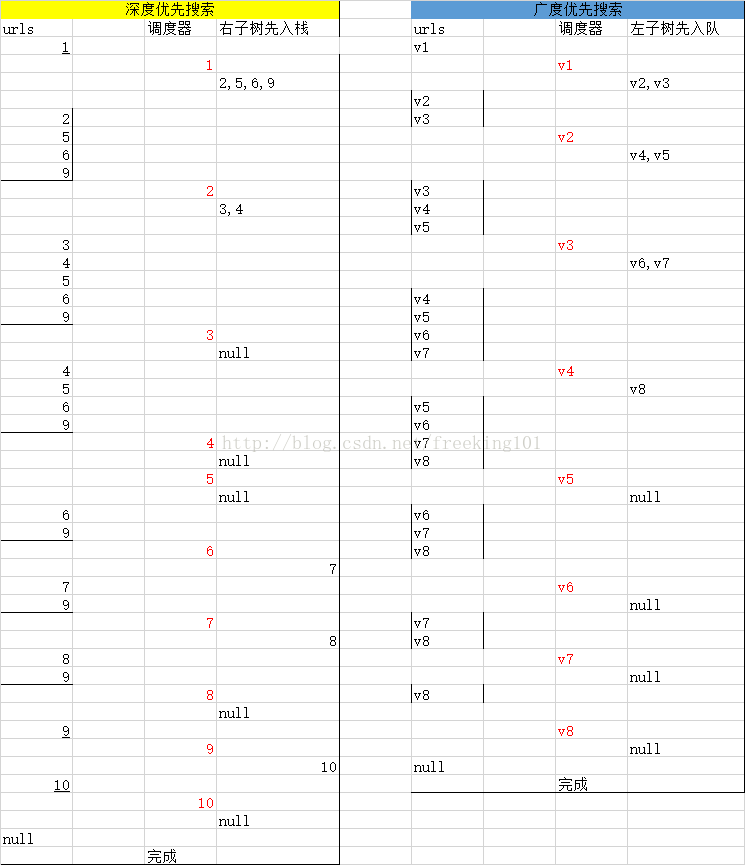
Scrapy是以广度优先还是深度优先进行爬取的呢?
默认情况下,Scrapy使用 LIFO 队列来存储等待的请求。简单的说,就是 深度优先顺序 。深度优先对大多数情况下是更方便的。如果您想以 广度优先顺序 进行爬取,你可以设置以下的设定:
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
二叉树的深度优先遍历与广度优先遍历 [ C++ 实现 ]
深度优先搜索算法(Depth First Search),是搜索算法的一种。是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。
如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
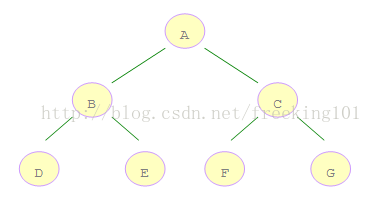
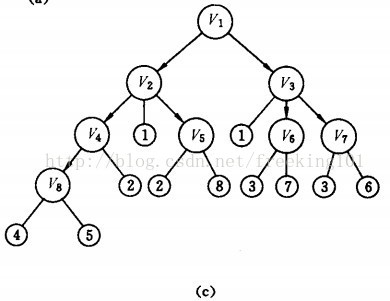
如右图所示的二叉树:
A 是第一个访问的,然后顺序是 B、D,然后是 E。接着再是 C、F、G。
那么,怎么样才能来保证这个访问的顺序呢?
分析一下,在遍历了根结点后,就开始遍历左子树,最后才是右子树。
因此可以借助堆栈的数据结构,由于堆栈是后进先出的顺序,由此可以先将右子树压栈,然后再对左子树压栈,
这样一来,左子树结点就存在了栈顶上,因此某结点的左子树能在它的右子树遍历之前被遍历。
深度优先遍历代码片段
//深度优先遍历
void depthFirstSearch(Tree root){
stack<Node *> nodeStack; //使用C++的STL标准模板库
nodeStack.push(root);
Node *node;
while(!nodeStack.empty()){
node = nodeStack.top();
printf(format, node->data); //遍历根结点
nodeStack.pop();
if(node->rchild){
nodeStack.push(node->rchild); //先将右子树压栈
}
if(node->lchild){
nodeStack.push(node->lchild); //再将左子树压栈
}
}
}广度优先搜索算法(Breadth First Search),又叫宽度优先搜索,或横向优先搜索。
是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。
如右图所示的二叉树,A 是第一个访问的,然后顺序是 B、C,然后再是 D、E、F、G。
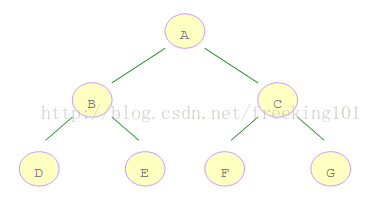
那么,怎样才能来保证这个访问的顺序呢?
借助队列数据结构,由于队列是先进先出的顺序,因此可以先将左子树入队,然后再将右子树入队。
这样一来,左子树结点就存在队头,可以先被访问到。
广度优先遍历代码片段
//广度优先遍历
void breadthFirstSearch(Tree root){
queue<Node *> nodeQueue; //使用C++的STL标准模板库
nodeQueue.push(root);
Node *node;
while(!nodeQueue.empty()){
node = nodeQueue.front();
nodeQueue.pop();
printf(format, node->data);
if(node->lchild){
nodeQueue.push(node->lchild); //先将左子树入队
}
if(node->rchild){
nodeQueue.push(node->rchild); //再将右子树入队
}
}
}完整代码:
/**
* <!--
* File : binarytree.h
* Author : fancy
* Email : fancydeepin@yeah.net
* Date : 2013-02-03
* --!>
*/
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <Stack>
#include <Queue>
using namespace std;
#define Element char
#define format "%c"
typedef struct Node {
Element data;
struct Node *lchild;
struct Node *rchild;
} *Tree;
int index = 0; //全局索引变量
//二叉树构造器,按先序遍历顺序构造二叉树
//无左子树或右子树用'#'表示
void treeNodeConstructor(Tree &root, Element data[]){
Element e = data[index++];
if(e == '#'){
root = NULL;
}else{
root = (Node *)malloc(sizeof(Node));
root->data = e;
treeNodeConstructor(root->lchild, data); //递归构建左子树
treeNodeConstructor(root->rchild, data); //递归构建右子树
}
}
//深度优先遍历
void depthFirstSearch(Tree root){
stack<Node *> nodeStack; //使用C++的STL标准模板库
nodeStack.push(root);
Node *node;
while(!nodeStack.empty()){
node = nodeStack.top();
printf(format, node->data); //遍历根结点
nodeStack.pop();
if(node->rchild){
nodeStack.push(node->rchild); //先将右子树压栈
}
if(node->lchild){
nodeStack.push(node->lchild); //再将左子树压栈
}
}
}
//广度优先遍历
void breadthFirstSearch(Tree root){
queue<Node *> nodeQueue; //使用C++的STL标准模板库
nodeQueue.push(root);
Node *node;
while(!nodeQueue.empty()){
node = nodeQueue.front();
nodeQueue.pop();
printf(format, node->data);
if(node->lchild){
nodeQueue.push(node->lchild); //先将左子树入队
}
if(node->rchild){
nodeQueue.push(node->rchild); //再将右子树入队
}
}
}
/**
* <!--
* File : BinaryTreeSearch.h
* Author : fancy
* Email : fancydeepin@yeah.net
* Date : 2013-02-03
* --!>
*/
#include "binarytree.h"
int main() {
//上图所示的二叉树先序遍历序列,其中用'#'表示结点无左子树或无右子树
Element data[15] = {'A', 'B', 'D', '#', '#', 'E', '#', '#', 'C', 'F','#', '#', 'G', '#', '#'};
Tree tree;
treeNodeConstructor(tree, data);
printf("深度优先遍历二叉树结果: ");
depthFirstSearch(tree);
printf("\n\n广度优先遍历二叉树结果: ");
breadthFirstSearch(tree);
return 0;
}
相关文章
- 五分钟,运用cocoaui库,搭建主流iOS app中我的界面
- 由App的启动说起
- 在Web.config或App.config中的添加自定义配置
- android app 集成 支付宝支付 微信支付
- [React] Setup an API Proxy in Create React App
- uni-app:nvue和vue均引入自定义字体文件(hbuilderx 3.6.18)
- [APP] Android 开发笔记 001-环境搭建与命令行创建项目
- Express app.get 进行路由 Route 设置
- Atitit 数据库 负载均衡 方法总结 目录 1. 对称模型负载均衡 vs 非对称模型2 1.1. 业务分离法2 1.2. App + db分布式分离法2 2. 负载均衡算法2 2.1.
- Atitit.提升软件Web应用程序 app性能的方法原理 h5 js java c# php python android .net
- App Thinning(为什么苹果app上传时的包比在appStore下载下来的包大很多)
- android 11.0 12.0第三方输入法app设置系统默认输入法
- Android 11.0 12.0Recent列表不显示某个app
- android 11.0 12.0自定义开机向导app
- android app 仿小米全面屏手势返回UI样式
- android 10.0 app 改变系统FoneSize大小 和 DisplaySize(density)
- App开发流程
- Testin云測公布首份国内应用质量报告:半数APP平均启动时间不合格
- 【2023最新教程】一文3000字从0到1教你做app自动化测试(保姆级教程)
- Android 指定调用已安装的某个“相机”App