
【目标检测】 R-CNN/FPN/YOLO经典算法梳理
本文用来简单梳理目标检测中的几个经典算法
更详尽的内容可参看这位博主的讲解:https://space.bilibili.com/18161609/channel/seriesdetail?sid=244160
R-CNN
R-CNN是目标检测领域的开山之作,它首次将“深度学习”和传统的“计算机视觉”的知识相结合,如图所示,相比于传统的目标检测方法,R-CNN碾压了之前五年发展的成果。
论文地址:https://openaccess.thecvf.com/content_cvpr_2014/papers/Girshick_Rich_Feature_Hierarchies_2014_CVPR_paper.pdf
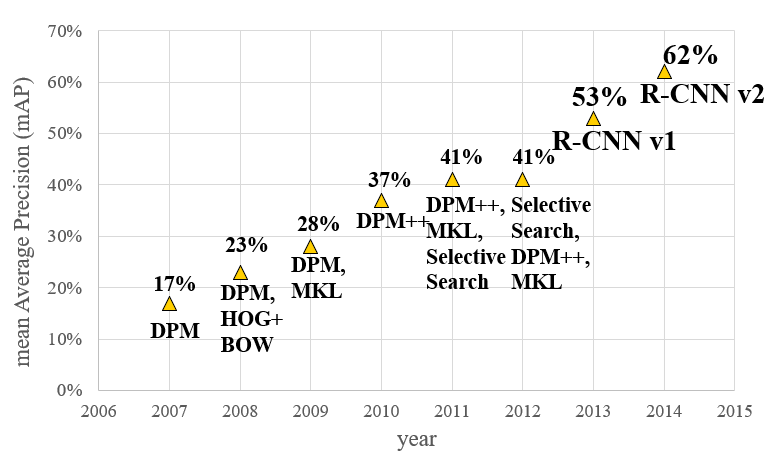
主要步骤
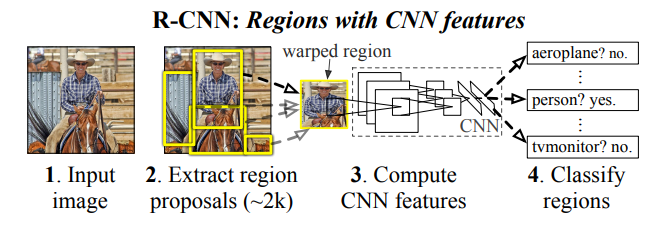
该图出自原论文,R-CNN的操作主要分成四步:
- 1.输入图像,生成2K个候选区域
- 2.对每个候选区域使用CNN提取特征
- 3.将特征送入SVM进行分类
- 4.使用回归器修正候选框位置(这一步图里没画出来)
R-CNN先生成候选区域,再进行分类回归,因此属于two-stage方法。
当然,这几个流程可用其它方法来替代,如下图所示:
步骤细节
下面对每个步骤具体展开分析:
1.候选区域的生成

图源[1]
原论文中的这一段写道,候选区域的生成使用的是selective search方法。

selective search方法的算法流程如下[2]:

举个例子:
输入图片:

利用《Efficient Graph-Based Image Segmentation》提到的图像分割方法进行分割:

根据基于颜色相似性、纹理相似性、尺寸相似性和形状兼容性,进行区域合并[3]:
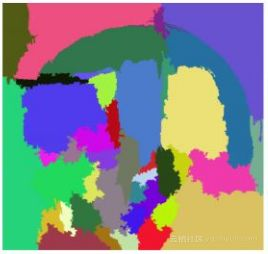
最终得到感兴趣的区域(ROI)。
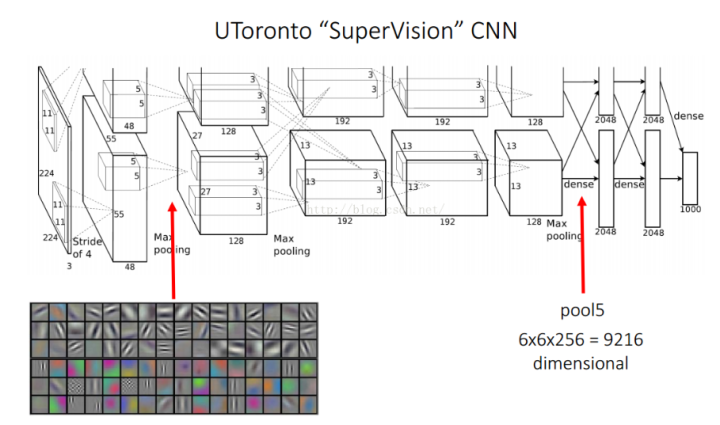
2.对每个候选区域,使用CNN提取特征

这里的网络结构选择经典的AlexNet。
AlexNet特征提取部分包含了5个卷积层、2个全连接层,在AlexNet中p5层神经元个数为9216、 f6、f7的神经元个数都是4096,通过这个网络训练完毕后,最后提取特征每个输入候选框图片都能得到一个4096维的特征向量[4]。
关于正负样本的确定,论文给出了这样的描述:
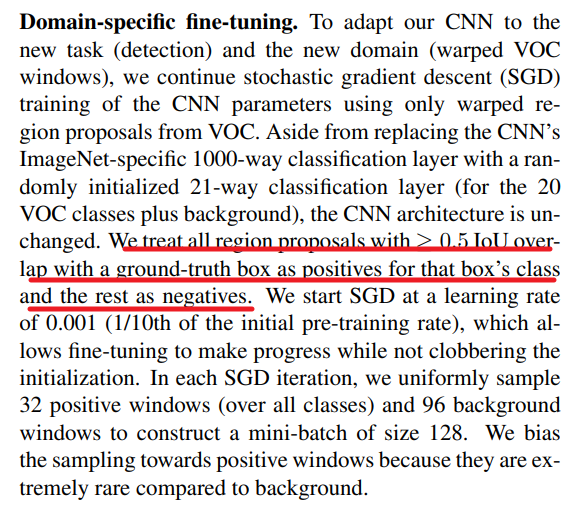
翻译一下:
如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5,那么就把这个候选框标注成物体类别(正样本),否则我们就把它当做背景类别(负样本)。
3.通过SVM分类器来判定类别
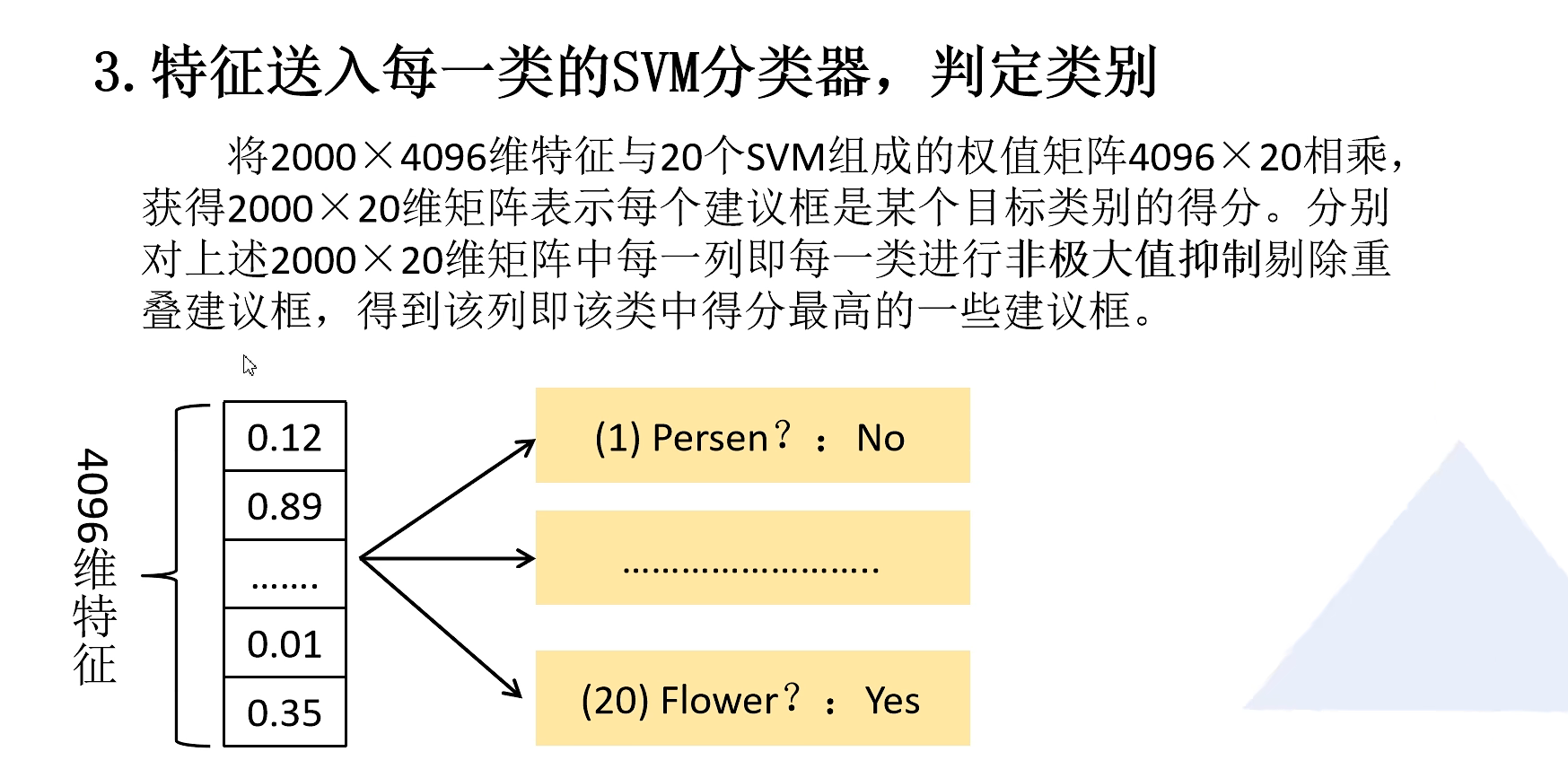
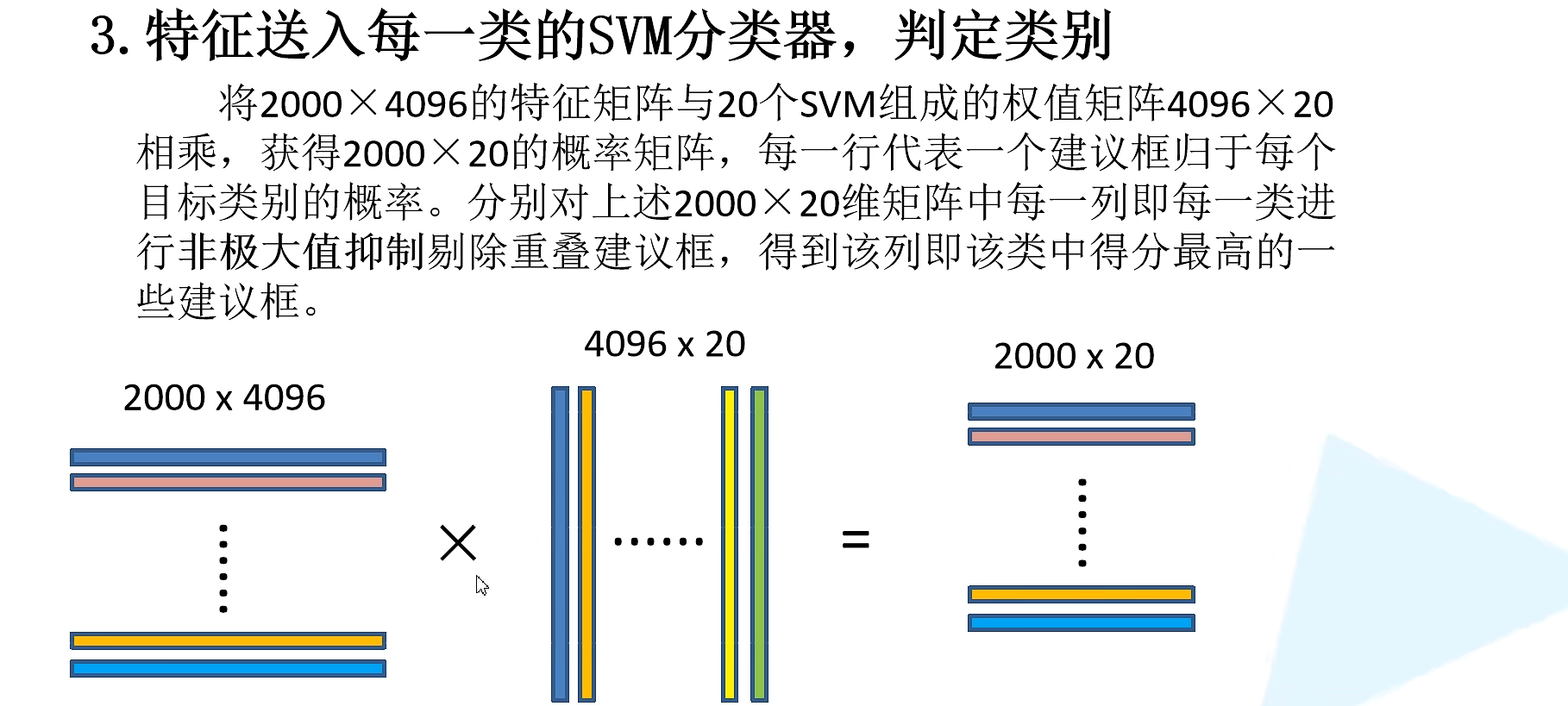
非极大抑制(NMS)知识补充:
非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
4.使用回归器修正候选框位置

R-CNN问题

Fast R-CNN
针对R-CNN存在的问题,Fast R-CNN主要对最后的分类步骤进行了优化。原本的R-CNN的分类使用了SVM,而SVM的模型注定速度会很慢,因此Fast R-CNN将分类和候选框位置回归放在了同一个网络中,如下图所示:
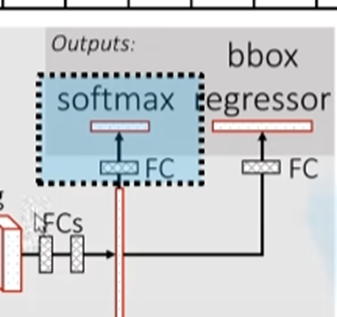
在最终的输出层,单独引出一层用softmax进行分类,这样就让整个算法运行速度加快。
网络总体的损失分成两个部分:分类损失和边界框回归损失。

式中的[u>=1]为艾弗森括号,即当前若不存在目标,损失为0。
Faster R-CNN
由于Fast R-CNN改善了网络输出端,训练速度提升了不少,但输入端仍然采用selective search来生成候选区域,速度仍然较慢。Faster R-CNN就提出RPN网络,来替代这个方法,解决这个问题。
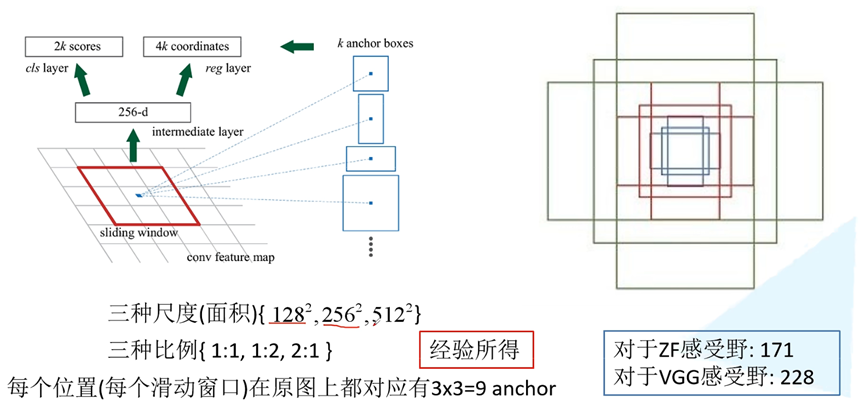
如图所示,RPN网络提出了三种不同尺寸的锚框,根据作者的描述,该尺寸是经验所得。通过不同的锚框在原图上进行滑动,从而得到各种不同的候选框。

将RPN网络和Fast R-CNN网络进行结合,形成了Faster R-CNN的网络结构,因此,整个网络形成了一个端到端的结构,即输入图片-输出图片,所有步骤放在网络中一起被训练。
这样优化之后,相较于之前算法,Faster R-CNN速度上有了进一步提升。但是作为Two-stage算法,它的速度仍然较慢,并且它的另一弱点是对小目标检测效果很差。
FPN
针对Faster R-CNN对小目标检测效果很差的弱点,FPN提出了一种新的网络结构-特征金字塔。
特征金字塔的原理也不是空中楼阁。分析一下为什么小目标检测效果不好,因为在特征提取的过程中,频繁使用卷积的结果就导致特征图越来越小,大目标不是问题,而小目标本身就没几个像素点,最后提取的特征更少,因此效果差。特征金字塔的思想就是能不能把卷积提取后的特征和卷积提取前的特征都考虑进去(有点残差网络的思想了)。
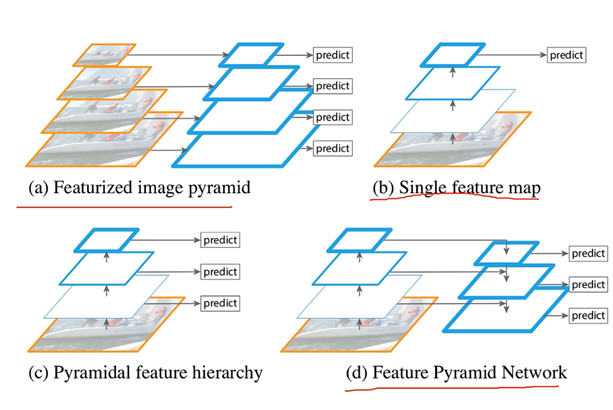
如图所示,特征金字塔就是在卷积前后的特征图(feature map)分别提取出来,自底向上或自顶向下进行相加,这样的特征融合操作被实验证实了能够缓解小目标检测效果很差的问题。
SSD
SSD全称Single Shot MultiBox Detector,属于One-Stage算法。
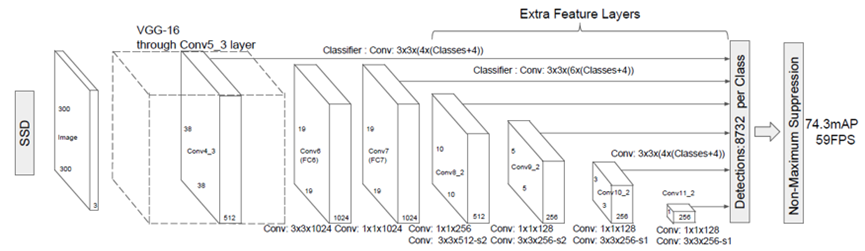
SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,其核心思想是在不同特征尺度上预测不同尺度的目标。
YOLO
Yolo全称Yolo Only Look Once,共有5个版本,是目前应用最多的目标检测模型。
正如它的名字一样,只看一次就能目标检测,属于One-Stage算法,具有较好的实时性。
核心思想:如下图所示,YOLO的核心思想是把原始图像分成SxS个网格,每个网格负责预测类别。
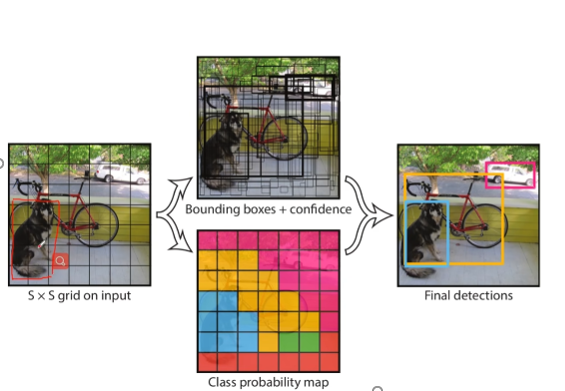
由于每个网格都要预测多个分类目标,因此分类向量对应多个分类的分数。
分数采用下面的公式进行计算:分数=有无目标的概率x有目标下当前分类的先验概率x预测框和真实框的交并比(IOU)。
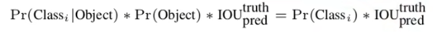
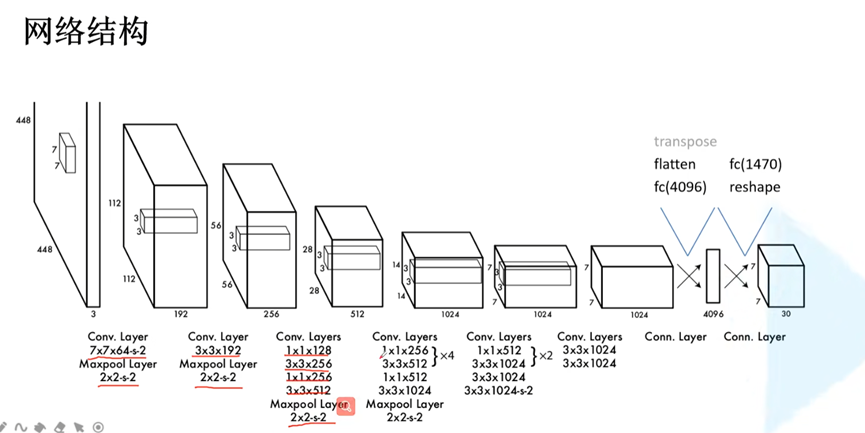
Yolo-v1网络结构:
损失函数由三部分构成:

定位损失(bounding box损失):衡量边界框和GroundTruth的差异
置信度损失(confidence损失):衡量是否有目标
分类损失(classes损失):衡量目标的类别
以这个网络结构为例,最终输出为7x7x30的向量
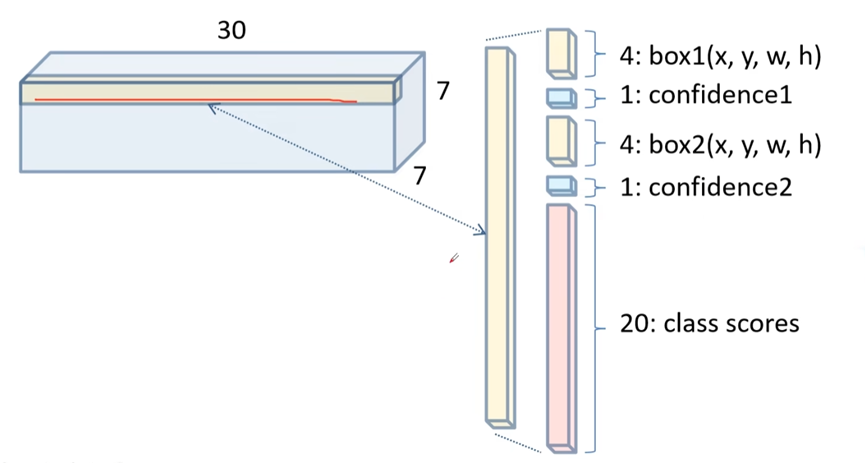
7x7为最终得到的特征图网格分布,每个网格长度为30,这里采用了两个boundding box,每个boundding box对应5个数值,分别为(x,y)中心点坐标,(w,h)宽度高度,置信度。后面20个为20个分类类别分数。
后续,yolo在此基础上,又引入BN层、Darknet、残差块、SPP、SPPF、数据增强等各种tricks,发展了5个版本,这里不作细述。
References
[1]https://www.bilibili.com/video/BV1af4y1m7iL
[2]https://www.bilibili.com/video/BV1N64y197s9
[3]https://blog.csdn.net/weixin_43694096/article/details/121610856
[4]https://blog.csdn.net/weixin_43694096/article/details/123827942
相关文章
- 经典神经网络 | fast rcnn目标检测算法详解
- 深度学习经典算法 | 遗传算法详解
- 经典算法:不大于N的特殊数字
- 机器学习十大经典算法入门[通俗易懂]
- java语言算法描述_六大java语言经典算法[通俗易懂]
- 软件设计师算法--常见算法,常见面试算法,经典面试算法
- 计算机视觉中,目前有哪些经典的目标跟踪算法?
- fastRcNN算法路面病害检测_R语言经典算法
- 谷歌复用30年前经典算法,CV引入强化学习,网友:视觉RLHF要来了?
- Acrobat最经典的版本:PDF编辑器Acrobat 2021经典版,下载
- 一段经典的抽奖算法 for PHP版
- 十大经典排序算法
- 关于递归算法的优化Ⅰ(以经典的斐波那契数列为例)
- C语言 | 动图演示十大经典排序算法(含代码)
- 独家 | 三个经典强化学习算法中重大缺陷(及如何修复)
- 详解:7大经典回归模型
- 微软确认:Win10 21H1是首个没有经典版Edge的功能更新
- Linux经典内容大精选(linux典藏大系)
- 玩转Linux:探索经典游戏世界(linux经典游戏)
- 比较经典常用Redis 版本号(常用redis版本号)
- 题MySQL面试20个经典问题等你去挑战(20个经典mysql面试)
- CSS经典技巧十则第1/2页
- 关于JAVA经典算法40题(超实用版)
- 30个经典的jQuery代码开发技巧