
Mask RCNN网络源码解读(Ⅶ) --- Mask分支解析以及将其映射回原尺度----完结撒花
目录
0.先决知识
学习此篇博客之前,读者应有:
①一定的python编程基础
②已经完全读懂Faster R-CNN代码,如果您还没学过Faster R-CNN内容,请参阅我的专栏:
Faster R-CNN网络源码解析
https://blog.csdn.net/qq_41694024/category_12155708.html ③应有深度学习的基础
1.简介
本篇博客将讲述如何利用之前实现好的Faster R-CNN算法实现Mask R-CNN。
2.mask_rcnn.py解析
这里我们定义了MaskRCNN类,继承自FasterRCNN。
2.1 初始化函数
def __init__( self, backbone, num_classes=None, # transform parameters min_size=800, max_size=1333, image_mean=None, image_std=None, # RPN parameters rpn_anchor_generator=None, rpn_head=None, rpn_pre_nms_top_n_train=2000, rpn_pre_nms_top_n_test=1000, rpn_post_nms_top_n_train=2000, rpn_post_nms_top_n_test=1000, rpn_nms_thresh=0.7, rpn_fg_iou_thresh=0.7, rpn_bg_iou_thresh=0.3, rpn_batch_size_per_image=256, rpn_positive_fraction=0.5, rpn_score_thresh=0.0, # Box parameters box_roi_pool=None, box_head=None, box_predictor=None, box_score_thresh=0.05, box_nms_thresh=0.5, box_detections_per_img=100, box_fg_iou_thresh=0.5, box_bg_iou_thresh=0.5, box_batch_size_per_image=512, box_positive_fraction=0.25, bbox_reg_weights=None, # Mask parameters mask_roi_pool=None, mask_head=None, mask_predictor=None, ): if not isinstance(mask_roi_pool, (MultiScaleRoIAlign, type(None))): raise TypeError( f"mask_roi_pool should be of type MultiScaleRoIAlign or None instead of {type(mask_roi_pool)}" ) if num_classes is not None: if mask_predictor is not None: raise ValueError("num_classes should be None when mask_predictor is specified") out_channels = backbone.out_channels if mask_roi_pool is None: mask_roi_pool = MultiScaleRoIAlign(featmap_names=["0", "1", "2", "3"], output_size=14, sampling_ratio=2) if mask_head is None: out_channels = backbone.out_channels mask_layers = (256, 256, 256, 256) mask_dilation = 1 mask_head = MaskRCNNHeads(out_channels, mask_layers, mask_dilation) if mask_predictor is None: mask_predictor_in_channels = 256 mask_dim_reduced = 256 mask_predictor = MaskRCNNPredictor(mask_predictor_in_channels, mask_dim_reduced, num_classes) super().__init__( backbone, num_classes, # transform parameters min_size, max_size, image_mean, image_std, # RPN-specific parameters rpn_anchor_generator, rpn_head, rpn_pre_nms_top_n_train, rpn_pre_nms_top_n_test, rpn_post_nms_top_n_train, rpn_post_nms_top_n_test, rpn_nms_thresh, rpn_fg_iou_thresh, rpn_bg_iou_thresh, rpn_batch_size_per_image, rpn_positive_fraction, rpn_score_thresh, # Box parameters box_roi_pool, box_head, box_predictor, box_score_thresh, box_nms_thresh, box_detections_per_img, box_fg_iou_thresh, box_bg_iou_thresh, box_batch_size_per_image, box_positive_fraction, bbox_reg_weights, ) self.roi_heads.mask_roi_pool = mask_roi_pool self.roi_heads.mask_head = mask_head self.roi_heads.mask_predictor = mask_predictor传入了一些参数,一直到Mask parameters之前的参数我们在Faster R-CNN部分有讲到过,这里不再赘述!在这些参数之外,我们会新增三个参数:
@mask_roi_pool
@mask_head
@mask_predictor
这三个参数组成了Mask分支的一系列结构,这里默认为空。
获取backbone的输出通道数赋值给out_channels。
如果mask_roi_pool没有传入(类初始化为空),则通过MultiScaleRoIAlign方法构建一个mask_roi_pool。这里主要将我们的输入特征
下采样到
的大小,我们在构造mask_roi_pool时,参数featmap_names是指采用FPN结构时,在哪些特征层进行目标特征采样,output_size指采样的高和宽,sampling_ratio采样率默认为2,即采样四个点,之前我们有说过这里不再赘述。
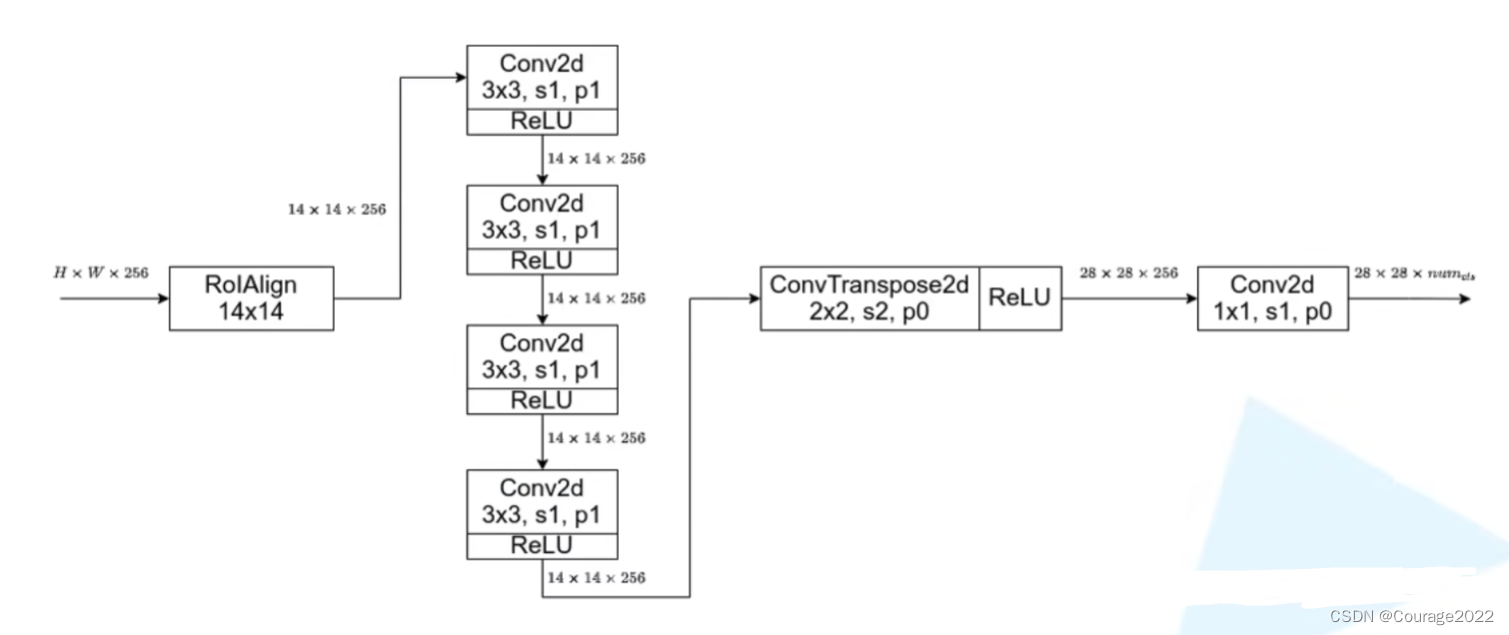
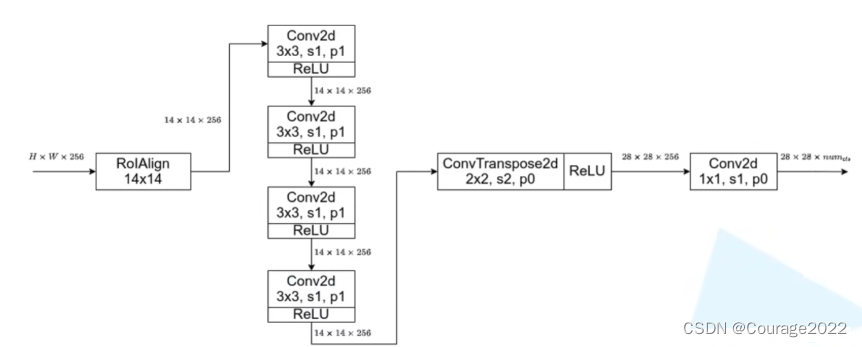
如果mask_head没有传入(类初始化为空),则通过MaskRCNNHeads方法构建一个mask_head,这里就对应着上图中的四个
的卷积层。(2.2节)。
如果mask_predictor没有传入(类初始化为空),则通过MaskRCNNPredictor方法构建一个mask_predictor,这里的mask_predictor_in_channels就是mask_head中输出的256通道数的特征矩阵,mask_dim_reduced是通过转置卷积将通道数调整为256,num_classes是分类类别个数。(2.3节)。
之后将参数传给父类FasterRCNN中,就会自动构建好在Faster RCNN中使用的结构了。这些参数不包含mask_head、mask_predictor、mask_roi_pool。
比如说在faster_rcnn_framework.py中的roi_head中:
roi_heads = RoIHeads( # box box_roi_pool, box_head, box_predictor, box_fg_iou_thresh, box_bg_iou_thresh, # 0.5 0.5 box_batch_size_per_image, box_positive_fraction, # 512 0.25 bbox_reg_weights, box_score_thresh, box_nms_thresh, box_detections_per_img) # 0.05 0.5 100它会将这个roi_head传入到FasterRCNN的父类中(FasterRCNNBase类)
super(FasterRCNN, self).__init__(backbone, rpn, roi_heads, transform)
调用父类的初始化方法之后,我们的roi_heads就已经创建好了,所以直接可以进行如下代码了:
self.roi_heads.mask_roi_pool = mask_roi_pool self.roi_heads.mask_head = mask_head self.roi_heads.mask_predictor = mask_predictor也就是说mask-rcnn分支是添加到ROIHeads类下的。

2.2 MaskRCNNHeads类
class MaskRCNNHeads(nn.Sequential): def __init__(self, in_channels, layers, dilation): """ Args: in_channels (int): number of input channels layers (tuple): feature dimensions of each FCN layer dilation (int): dilation rate of kernel """ d = OrderedDict() next_feature = in_channels for layer_idx, layers_features in enumerate(layers, 1): d[f"mask_fcn{layer_idx}"] = nn.Conv2d(next_feature, layers_features, kernel_size=3, stride=1, padding=dilation, dilation=dilation) d[f"relu{layer_idx}"] = nn.ReLU(inplace=True) next_feature = layers_features super().__init__(d) # initial params for name, param in self.named_parameters(): if "weight" in name: nn.init.kaiming_normal_(param, mode="fan_out", nonlinearity="relu")if mask_head is None: out_channels = backbone.out_channels mask_layers = (256, 256, 256, 256) mask_dilation = 1 mask_head = MaskRCNNHeads(out_channels, mask_layers, mask_dilation)传入变量:
in_channels:FPN层的out_channels
layers:将四个特征层的channel调整到(256,256,256,256)
mask_dilation:不起作用的参数
类继承自nn.Sequential,首先初始化有序字典d,将in_channels赋值给next_feature。
遍历layers循环构建每一个
循环完成之后我们就构建了3个
2.3 MaskRCNNPredictor类
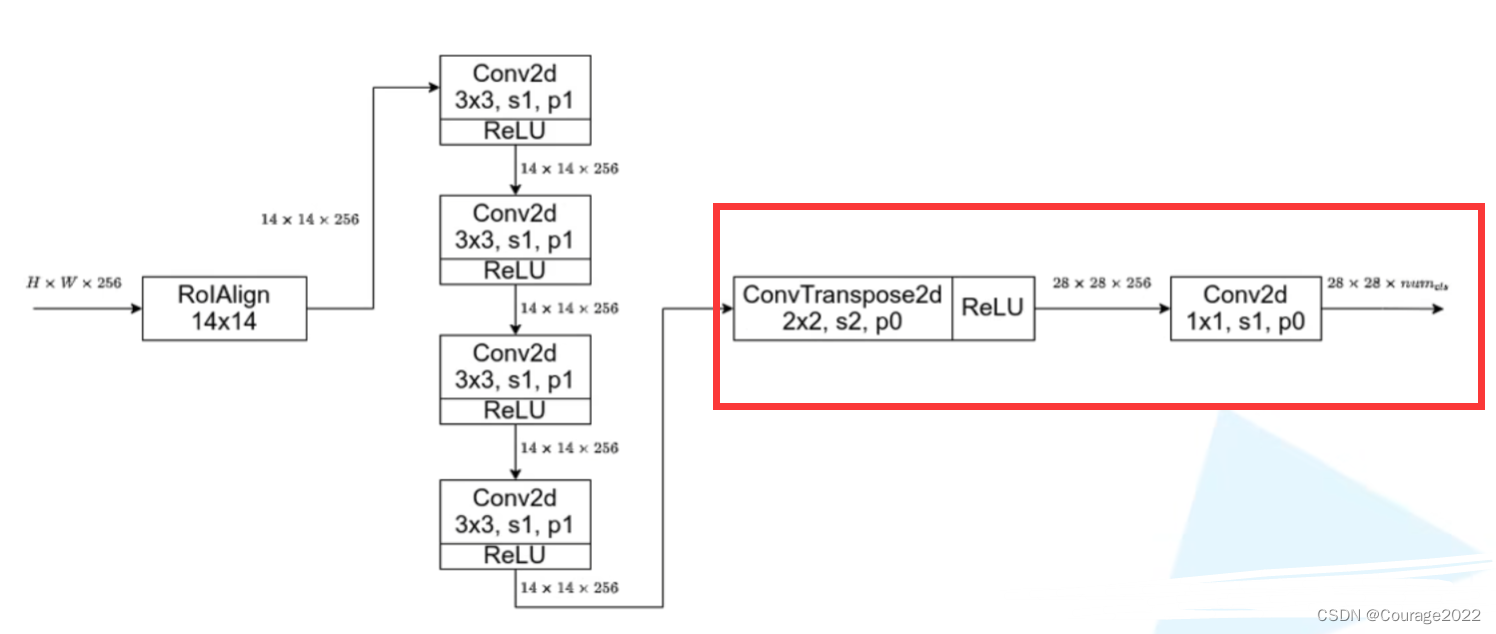
class MaskRCNNPredictor(nn.Sequential): def __init__(self, in_channels, dim_reduced, num_classes): super().__init__(OrderedDict([ ("conv5_mask", nn.ConvTranspose2d(in_channels, dim_reduced, 2, 2, 0)), ("relu", nn.ReLU(inplace=True)), ("mask_fcn_logits", nn.Conv2d(dim_reduced, num_classes, 1, 1, 0)) ])) # initial params for name, param in self.named_parameters(): if "weight" in name: nn.init.kaiming_normal_(param, mode="fan_out", nonlinearity="relu")
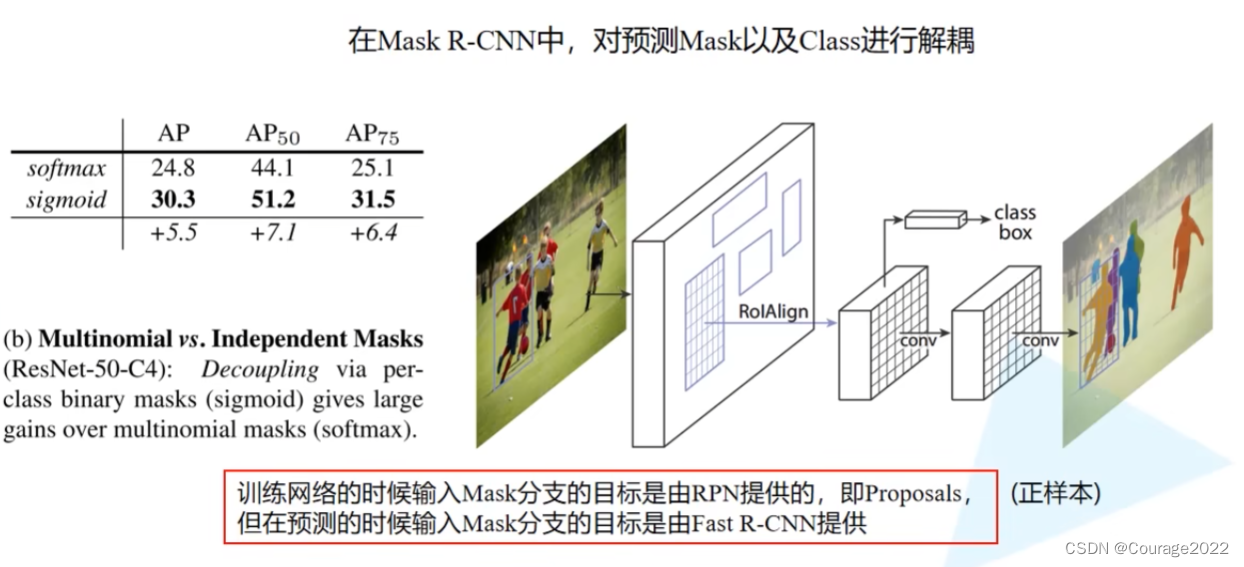
这里对应上图中红色框体部分。
在父类初始化函数中传入有序字典:
①第一个结构是转置卷积:in_channels就是256;dim_reduced就是out_channel,这里也是256;卷积核大小为
,步距为2,padding为0。再用ReLU激活函数激活。
②第二个结构是卷积层:输入channel是dim_reduced,输出channel是分类类别,卷积核大小为
,步距为1,padding为0。
3.RoIHeads类解析
3.1 正向传播过程
def forward(self, features, # type: Dict[str, Tensor] proposals, # type: List[Tensor] image_shapes, # type: List[Tuple[int, int]] targets=None # type: Optional[List[Dict[str, Tensor]]] ): # type: (...) -> Tuple[List[Dict[str, Tensor]], Dict[str, Tensor]] """ Arguments: features (List[Tensor]) proposals (List[Tensor[N, 4]]) image_shapes (List[Tuple[H, W]]) targets (List[Dict]) """ # 检查targets的数据类型是否正确 if targets is not None: for t in targets: floating_point_types = (torch.float, torch.double, torch.half) assert t["boxes"].dtype in floating_point_types, "target boxes must of float type" assert t["labels"].dtype == torch.int64, "target labels must of int64 type" if self.training: # 划分正负样本,统计对应gt的标签以及边界框回归信息 proposals, matched_idxs, labels, regression_targets = self.select_training_samples(proposals, targets) else: labels = None regression_targets = None matched_idxs = None # 将采集样本通过Multi-scale RoIAlign pooling层 # box_features_shape: [num_proposals, channel, height, width] box_features = self.box_roi_pool(features, proposals, image_shapes) # 通过roi_pooling后的两层全连接层 # box_features_shape: [num_proposals, representation_size] box_features = self.box_head(box_features) # 接着分别预测目标类别和边界框回归参数 class_logits, box_regression = self.box_predictor(box_features) result: List[Dict[str, torch.Tensor]] = [] losses = {} if self.training: assert labels is not None and regression_targets is not None loss_classifier, loss_box_reg = fastrcnn_loss( class_logits, box_regression, labels, regression_targets) losses = { "loss_classifier": loss_classifier, "loss_box_reg": loss_box_reg } else: boxes, scores, labels = self.postprocess_detections(class_logits, box_regression, proposals, image_shapes) num_images = len(boxes) for i in range(num_images): result.append( { "boxes": boxes[i], "labels": labels[i], "scores": scores[i], } ) if self.has_mask(): mask_proposals = [p["boxes"] for p in result] # 将最终预测的Boxes信息取出 if self.training: # matched_idxs为每个proposal在正负样本匹配过程中得到的gt索引(背景的gt索引也默认设置成了0) if matched_idxs is None: raise ValueError("if in training, matched_idxs should not be None") # during training, only focus on positive boxes num_images = len(proposals) mask_proposals = [] pos_matched_idxs = [] for img_id in range(num_images): pos = torch.where(labels[img_id] > 0)[0] # 寻找对应gt类别大于0,即正样本 mask_proposals.append(proposals[img_id][pos]) pos_matched_idxs.append(matched_idxs[img_id][pos]) else: pos_matched_idxs = None mask_features = self.mask_roi_pool(features, mask_proposals, image_shapes) mask_features = self.mask_head(mask_features) mask_logits = self.mask_predictor(mask_features) loss_mask = {} if self.training: if targets is None or pos_matched_idxs is None or mask_logits is None: raise ValueError("targets, pos_matched_idxs, mask_logits cannot be None when training") gt_masks = [t["masks"] for t in targets] gt_labels = [t["labels"] for t in targets] rcnn_loss_mask = maskrcnn_loss(mask_logits, mask_proposals, gt_masks, gt_labels, pos_matched_idxs) loss_mask = {"loss_mask": rcnn_loss_mask} else: labels = [r["labels"] for r in result] mask_probs = maskrcnn_inference(mask_logits, labels) for mask_prob, r in zip(mask_probs, result): r["masks"] = mask_prob losses.update(loss_mask) return result, losses我们只说在Faster R-CNN中没有说过的部分:
我们判断是否有mask分支:if self.has_mask():
def has_mask(self): if self.mask_roi_pool is None: return False if self.mask_head is None: return False if self.mask_predictor is None: return False return True我们将Fast RCNN最终预测的信息result(框体boxes + 标签labels + 分数 scores)的框体信息(boxes)取出存放在mask_proposals中。(注意:如果在训练模式下result为空的列表,非训练模式才有)
如果是训练模式下,取出batch_size的数目num_images,初始化两个变量mask_proposals(存储后续用于计算mask分支损失时所利用到的proposal)和pos_matched_idxs(proposal对应的gt索引)。
遍历每一张图片:
①将每张图片所对应的labels(如果是训练模式labels就是在select_training_samples中对正负样本进行匹配后得到的proposal,其中即包含正样本也包含负样本)(每张图片对应的proposal的类别标签,其中背景的标签为0,我们寻找所有大于0的标签即被分配为正样本的proposal,我们记录它的索引在pos中)
②依次取每张图片中它所对应的proposal中的正样本存入mask_proposals中。
③依次取每张图片中它所对应的正样本proposal对应的gt的索引ID。
调试一下:
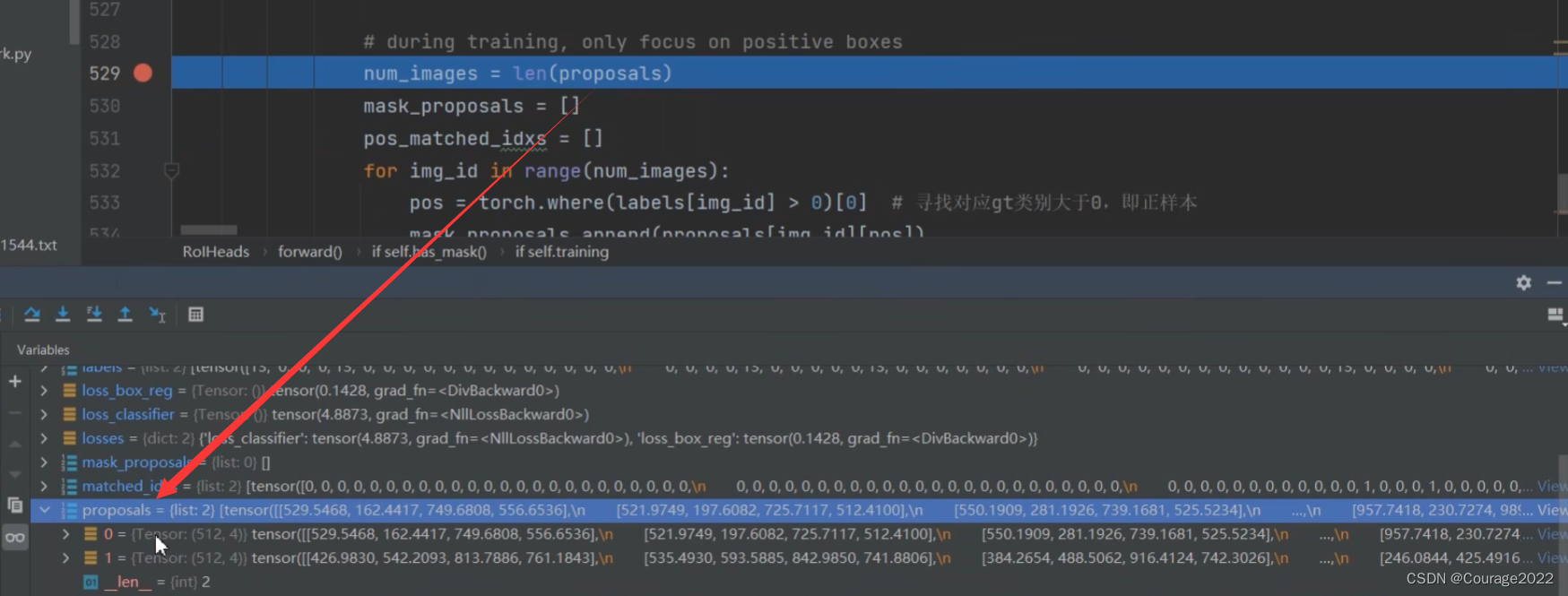
proposal是列表类型,由于我们的batch_size为2,因此只有两个元素,每个元素对应一张图片中的proposal个数(512*4) 
pos是当前图片中被分为正样本的proposal的索引 
mask_proposals存放着对应pos索引的proposal的框体信息 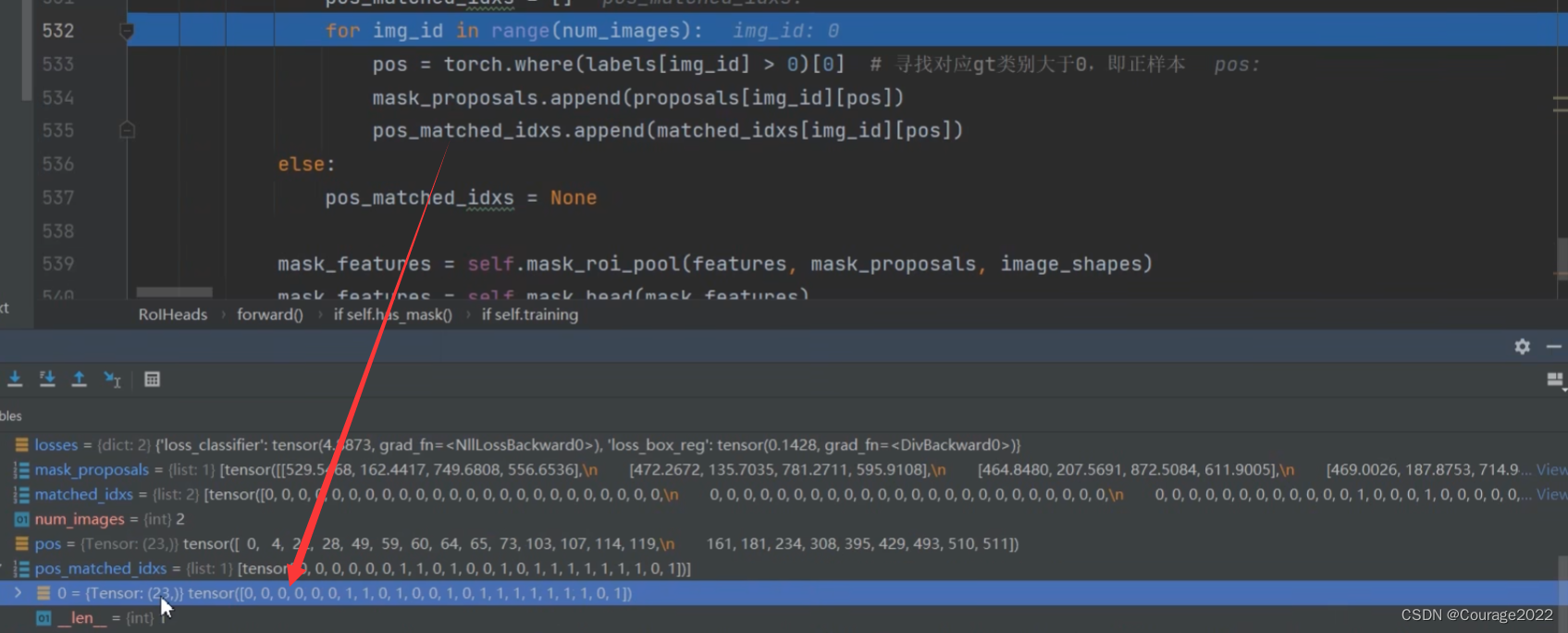
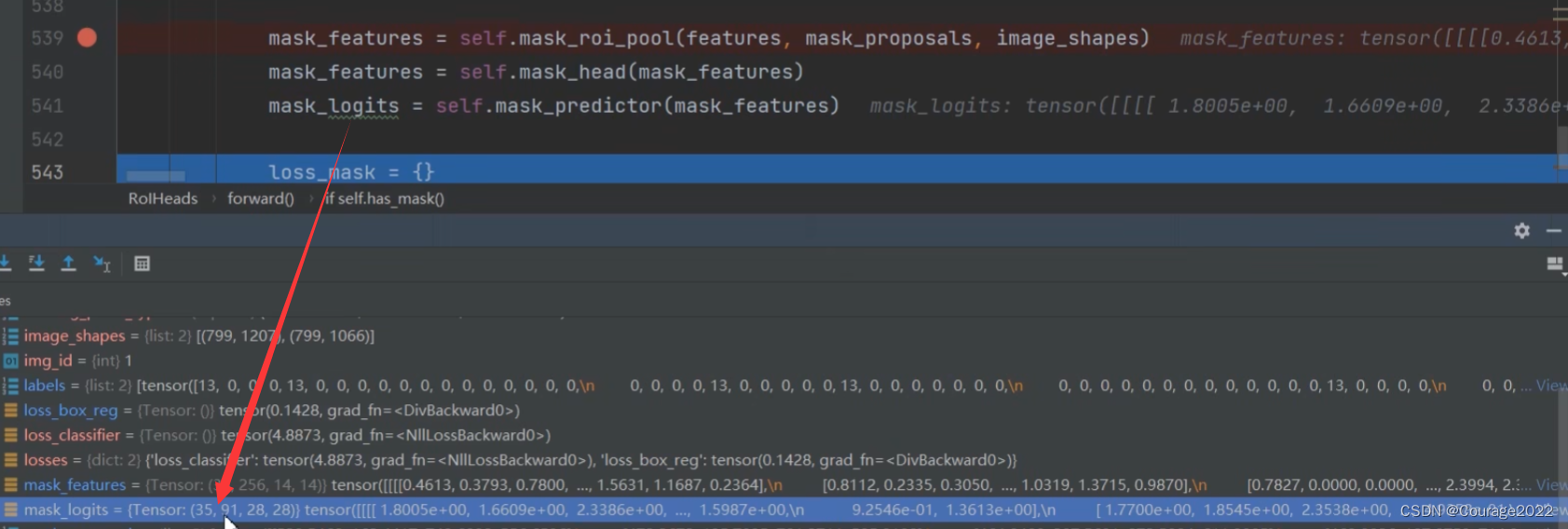
pos_matched_idxs对应着gt的索引 将特征层features、mask_proposals(对于训练模式是我们刚才寻找的归为正样本的proposals、对于验证模式是result得到的box信息)、image_shape(batch中每张图片经过resize后batch前的一个大小)传入mask_roi_pool中。
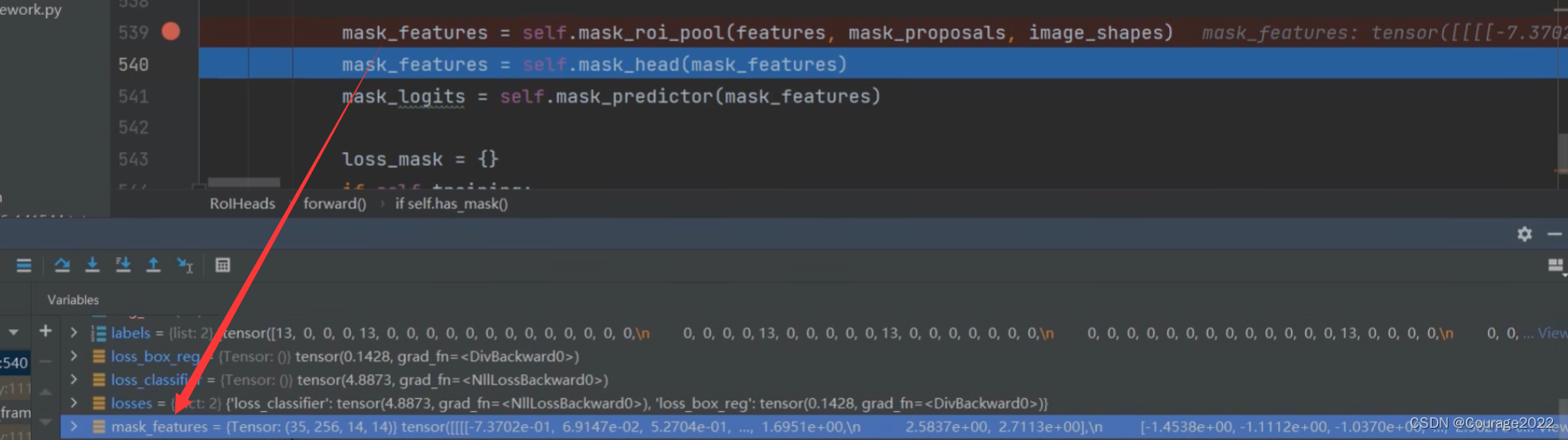
这时就会将我们的目标全部调整到相同大小(35:当前batch中有35个proposal;256:输入特征层的channel;14*14:通过ROIAlign后得到的特征图)
依次通过mask_head和mask_predictor就可以得到mask分支的输出了:
这里35指35个proposal,91是因为我们使用的COCO数据集(COCO数据集能分类的物体是90类 + 1类背景),针对每个类别我们都会预测一个mask,都是
的。
接下来对于训练模式和验证模式,我们又要做不同的处理:
对于训练模式,我们要去计算mask分支的损失;对于非训练模式,我们要提取针对每个目标它所对应预测类别的mask信息。
对于训练模式,将target中的masks信息以及labels信息提取出来
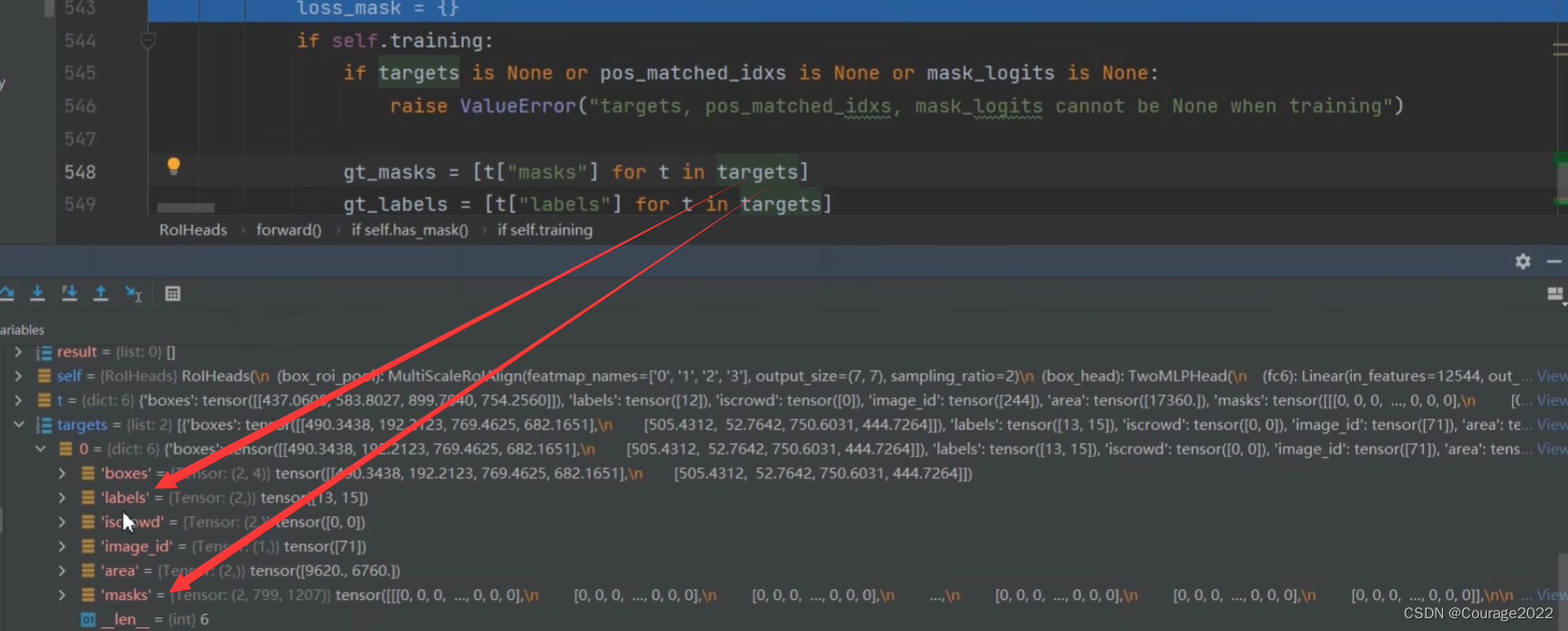
target中存放着提前标注好的信息;对于这个mask,这个2代表我们当前图片有两个目标,799和1207分别对应图片的高度和宽度,mask是和原图一样大小的默认位置填充为0目标位置填充为1 我们将mask_logits, mask_proposals, gt_masks, gt_labels, pos_matched_idxs传入maskrcnn_loss方法计算mask分支的损失。
对于非训练模式,获取所有目标的label,将mask_logits和labels信息传递给maskrcnn_inference中。
3.2 mask部分损失
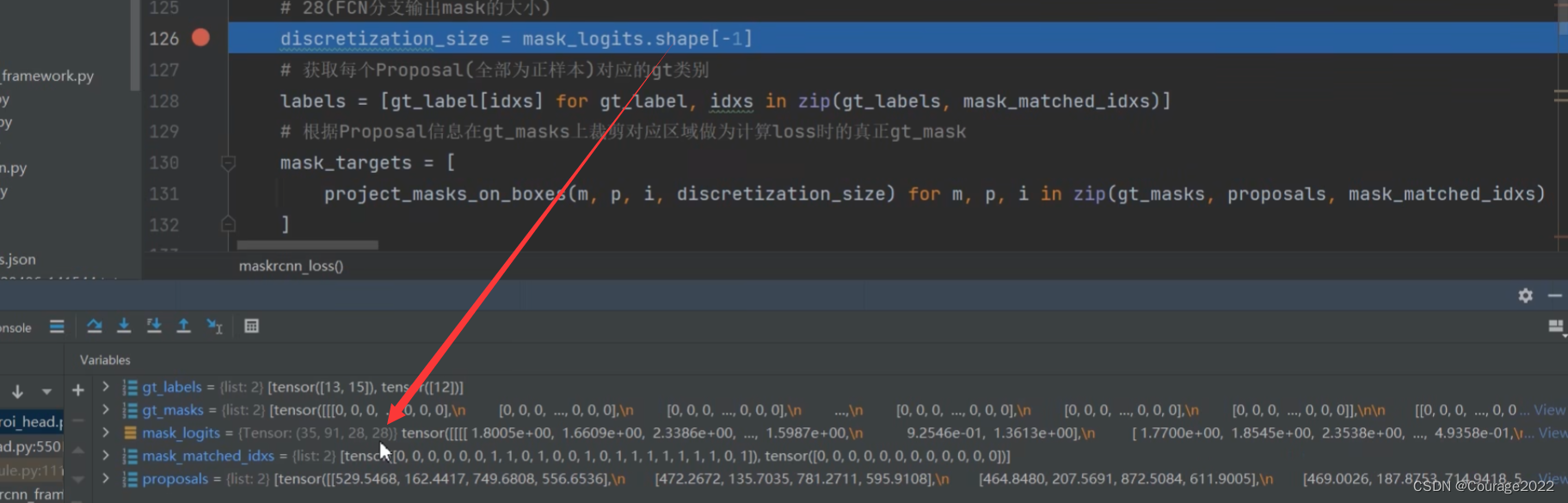
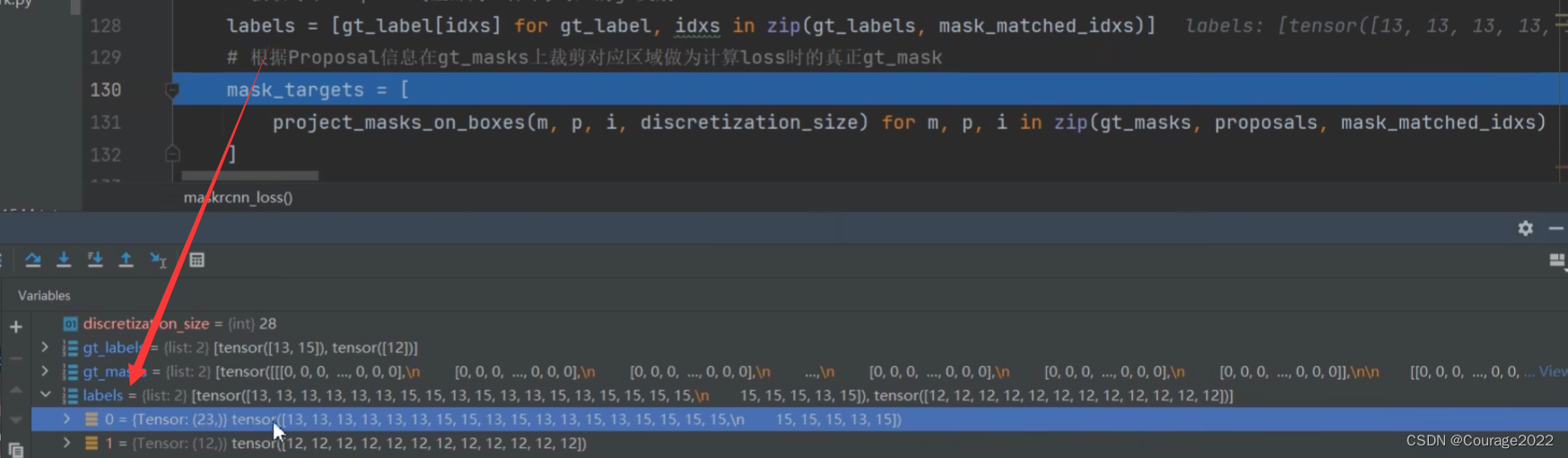
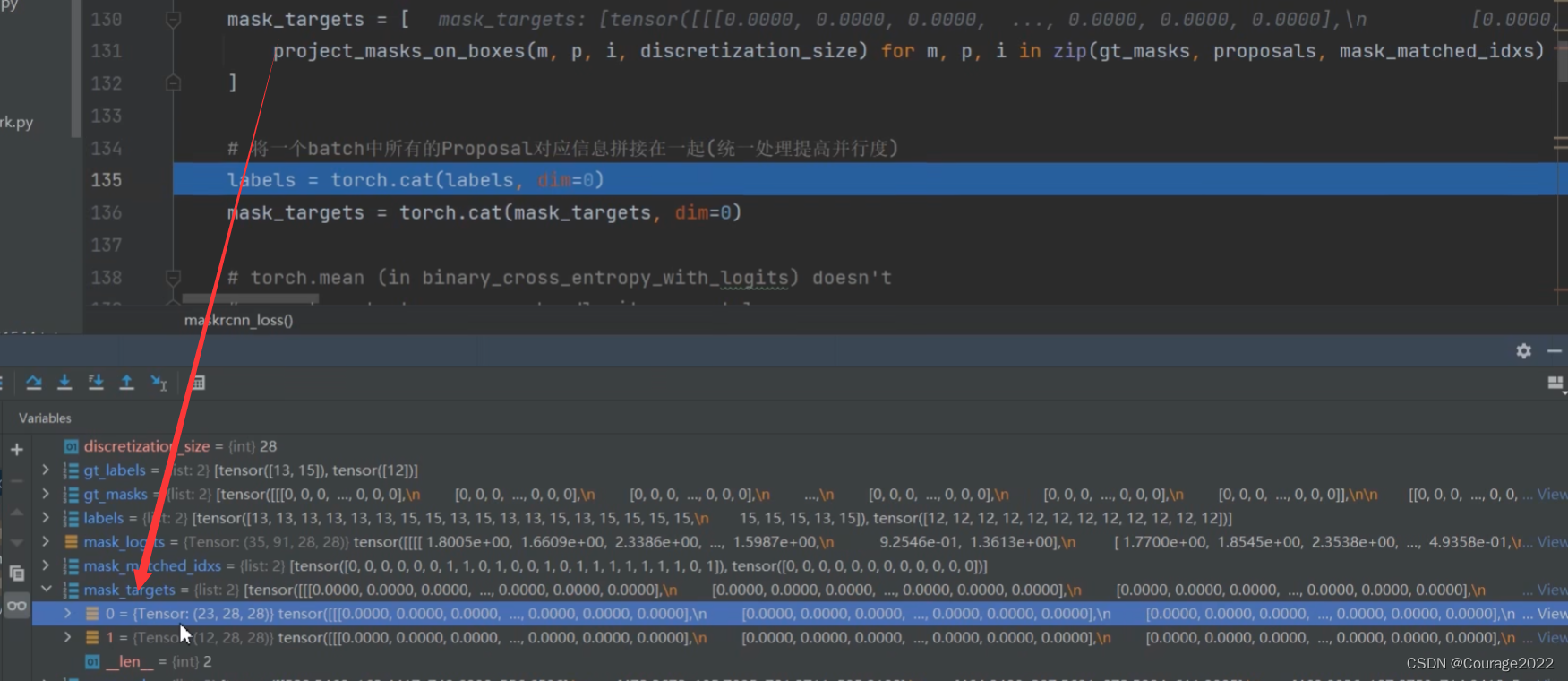
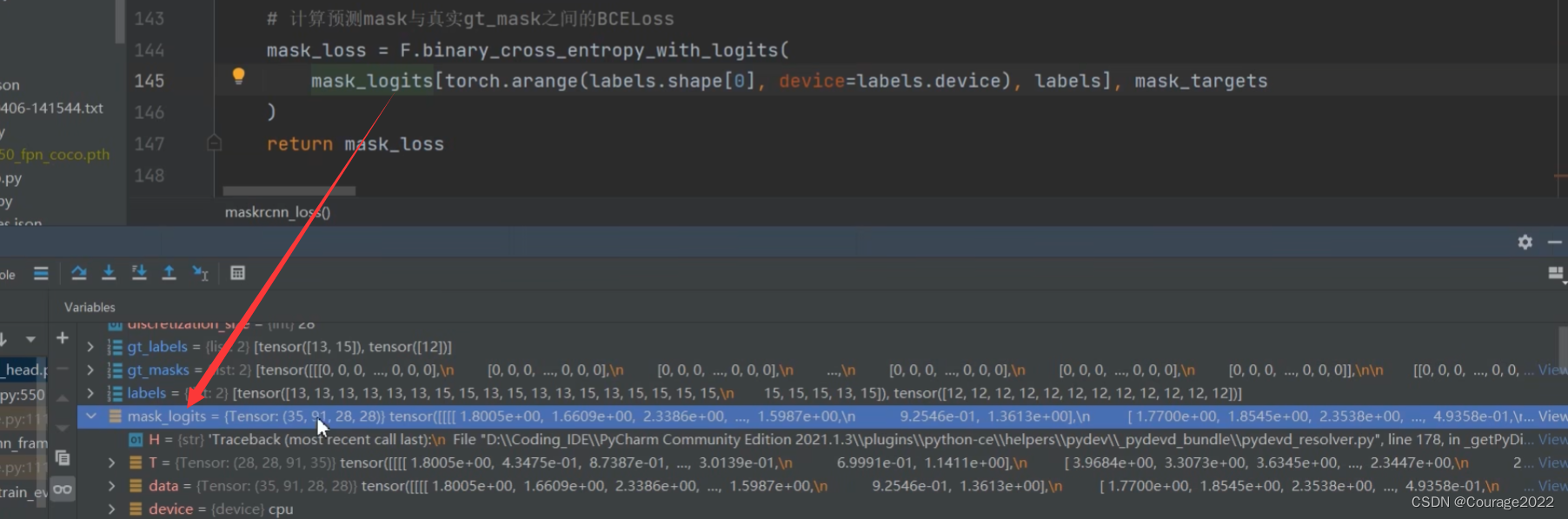
def maskrcnn_loss(mask_logits, proposals, gt_masks, gt_labels, mask_matched_idxs): # type: (Tensor, List[Tensor], List[Tensor], List[Tensor], List[Tensor]) -> Tensor """ Args: mask_logits: proposals: gt_masks: gt_labels: mask_matched_idxs: Returns: mask_loss (Tensor): scalar tensor containing the loss """ # 28(FCN分支输出mask的大小) discretization_size = mask_logits.shape[-1] # 获取每个Proposal(全部为正样本)对应的gt类别 labels = [gt_label[idxs] for gt_label, idxs in zip(gt_labels, mask_matched_idxs)] # 根据Proposal信息在gt_masks上裁剪对应区域做为计算loss时的真正gt_mask mask_targets = [ project_masks_on_boxes(m, p, i, discretization_size) for m, p, i in zip(gt_masks, proposals, mask_matched_idxs) ] # 将一个batch中所有的Proposal对应信息拼接在一起(统一处理提高并行度) labels = torch.cat(labels, dim=0) mask_targets = torch.cat(mask_targets, dim=0) # torch.mean (in binary_cross_entropy_with_logits) doesn't # accept empty tensors, so handle it separately if mask_targets.numel() == 0: return mask_logits.sum() * 0 # 计算预测mask与真实gt_mask之间的BCELoss mask_loss = F.binary_cross_entropy_with_logits( mask_logits[torch.arange(labels.shape[0], device=labels.device), labels], mask_targets ) return mask_loss
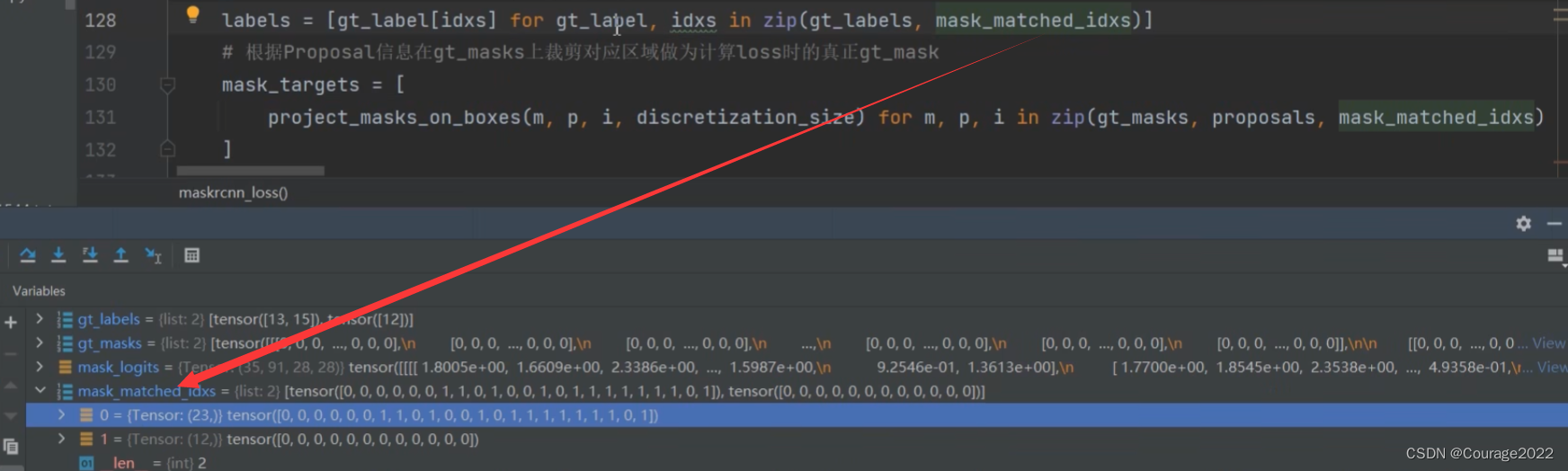
mask_matched_idxs存储的是针对每一张图片当中归为正样本的proposal所对应gt的索引:
将idx传入gt_label就可以获得每个Proposal(全部为正样本)对应的gt类别。
接着我们需要根据我们的proposal信息在gt_mask中裁剪用于我们最终计算损失时的mask:我们之前在讲计算损失的时候提到过,我们会根据proposal的位姿信息在原图的mask上进行裁剪,裁剪之后就会得到GT Mask
第一个数值对应当前图片中有多少个正样本的proposal,后面的
再将labels和mask_targets拼接在一起,最后进行二值交叉熵运算得到损失(网络预测的logits与真实的mask_targets)。
mask_logit对于每个类别都预测了一个mask。但对于计算损失的时候只需要计算关于gt的类别就可以了。因此我们采用切片的方式,将所有关于gt类别的mask抽出来了。

3.3 maskrcnn_inference
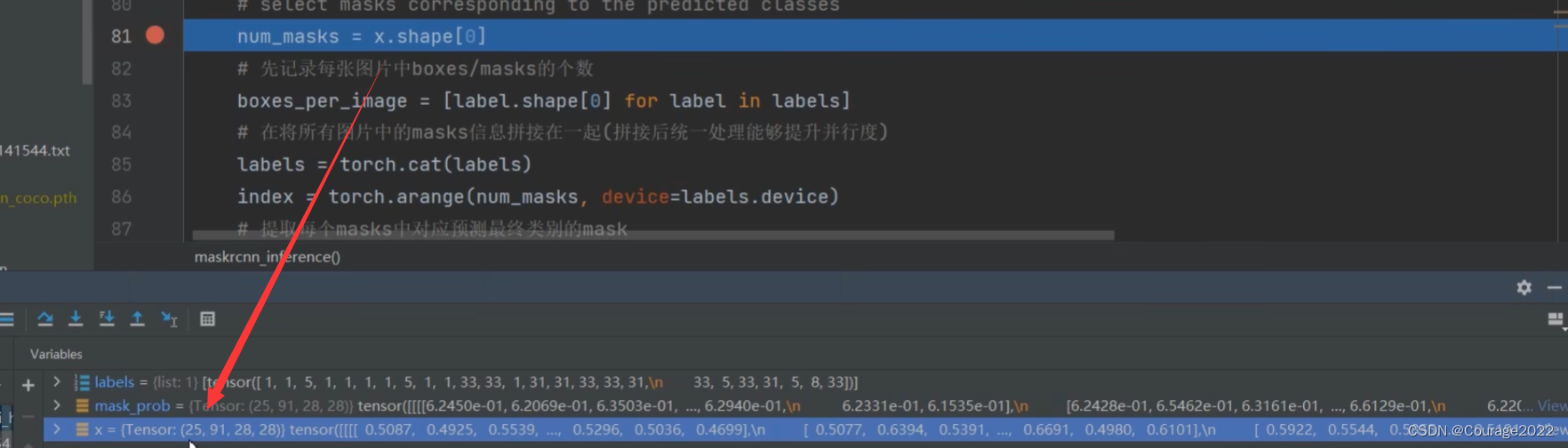
def maskrcnn_inference(x, labels): # type: (Tensor, List[Tensor]) -> List[Tensor] """ From the results of the CNN, post process the masks by taking the mask corresponding to the class with max probability (which are of fixed size and directly output by the CNN) and return the masks in the mask field of the BoxList. Args: x (Tensor): the mask logits labels (list[BoxList]): bounding boxes that are used as reference, one for ech image Returns: results (list[BoxList]): one BoxList for each image, containing the extra field mask """ # 将预测值通过sigmoid激活全部缩放到0~1之间 mask_prob = x.sigmoid() # select masks corresponding to the predicted classes num_masks = x.shape[0] # 先记录每张图片中boxes/masks的个数 boxes_per_image = [label.shape[0] for label in labels] # 在将所有图片中的masks信息拼接在一起(拼接后统一处理能够提升并行度) labels = torch.cat(labels) index = torch.arange(num_masks, device=labels.device) # 提取每个masks中对应预测最终类别的mask mask_prob = mask_prob[index, labels][:, None] # 最后再按照每张图片中的masks个数分离开 mask_prob = mask_prob.split(boxes_per_image, dim=0) return mask_prob
预测目标的个数是25个。
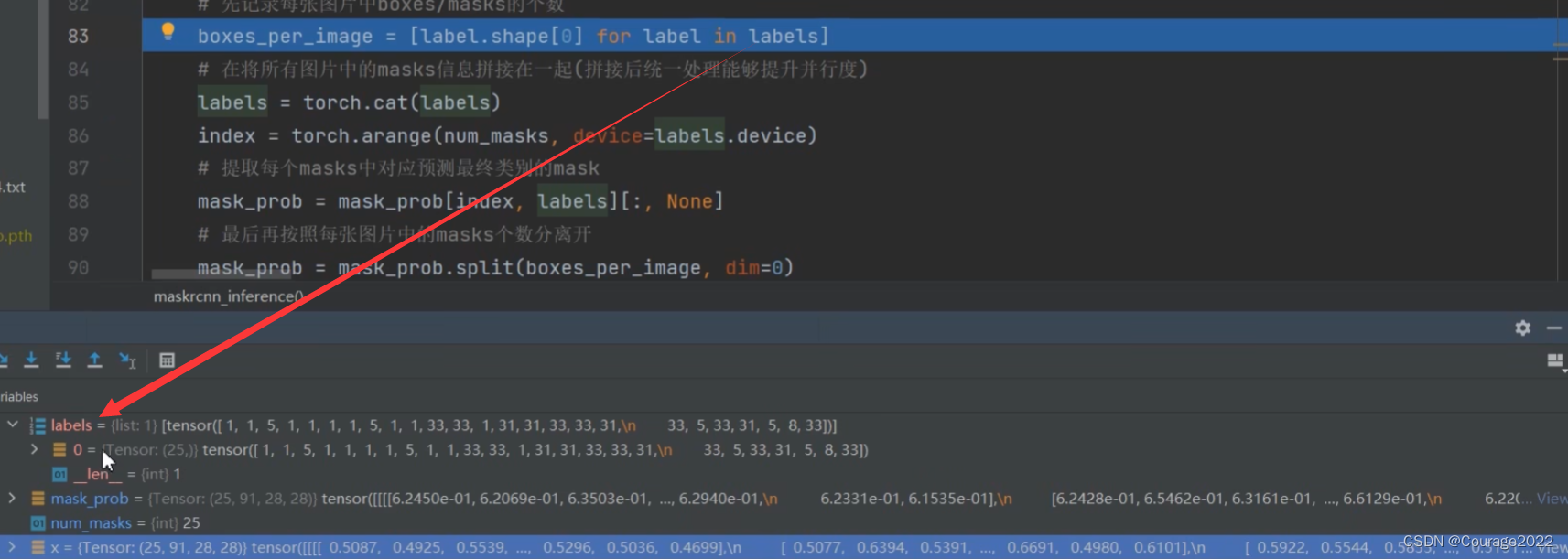
遍历labels:得到每张图片目标的个数boxes_per_image(这里我们只有一张图片)
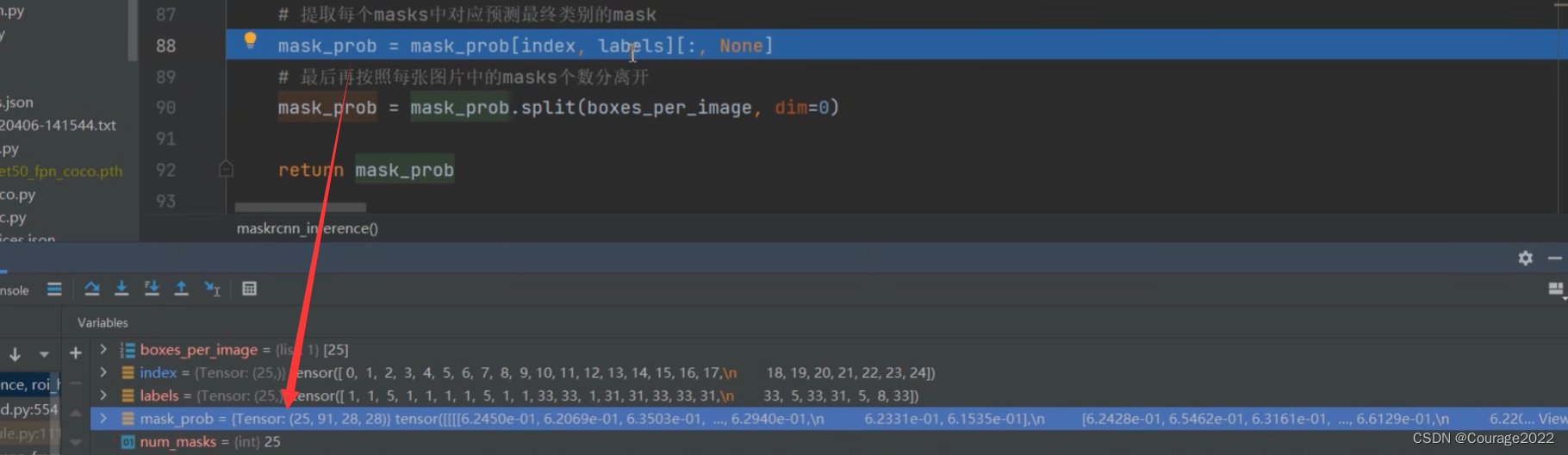
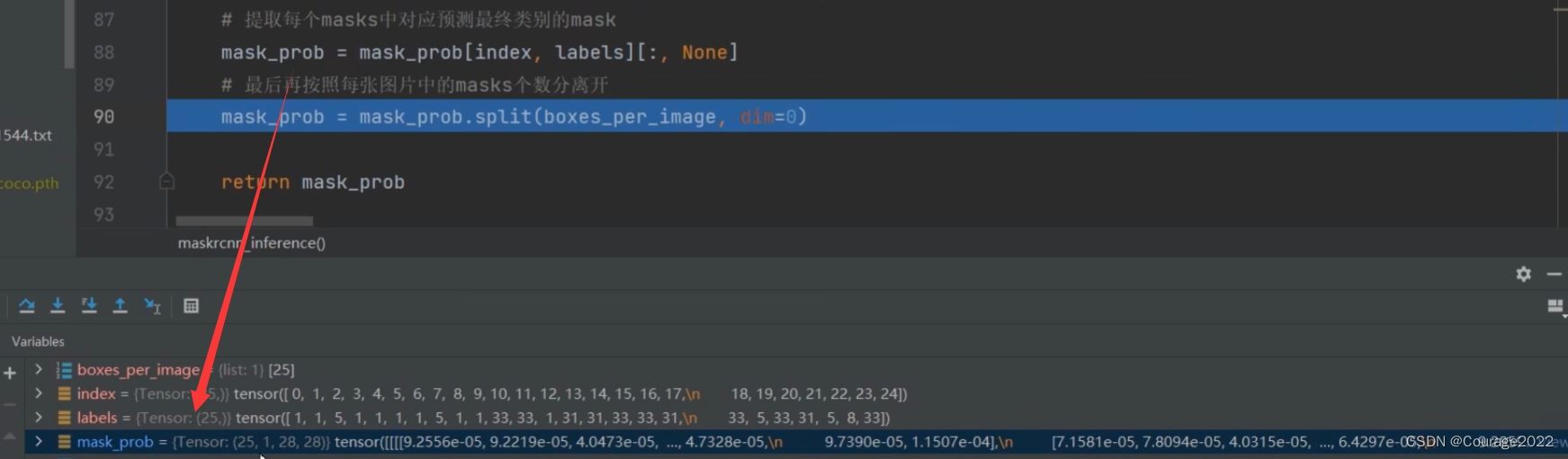
将labels拼接在一起(在这里没用),创建index索引,索引值为0-num_mask-1即0-24,提取每个masks中对应预测最终类别的mask:

4.将预测信息映射回原尺度 transform.py
4.1 GeneralizedRCNNTransform类
4.1.1 postprocess方法
在之前的Faster R-CNN中,这里主要的作用是将预测的边界框映射回原尺度。在Mask R-CNN中除了要做这步以外,我们也需要将mask信息也映射回原图尺度。
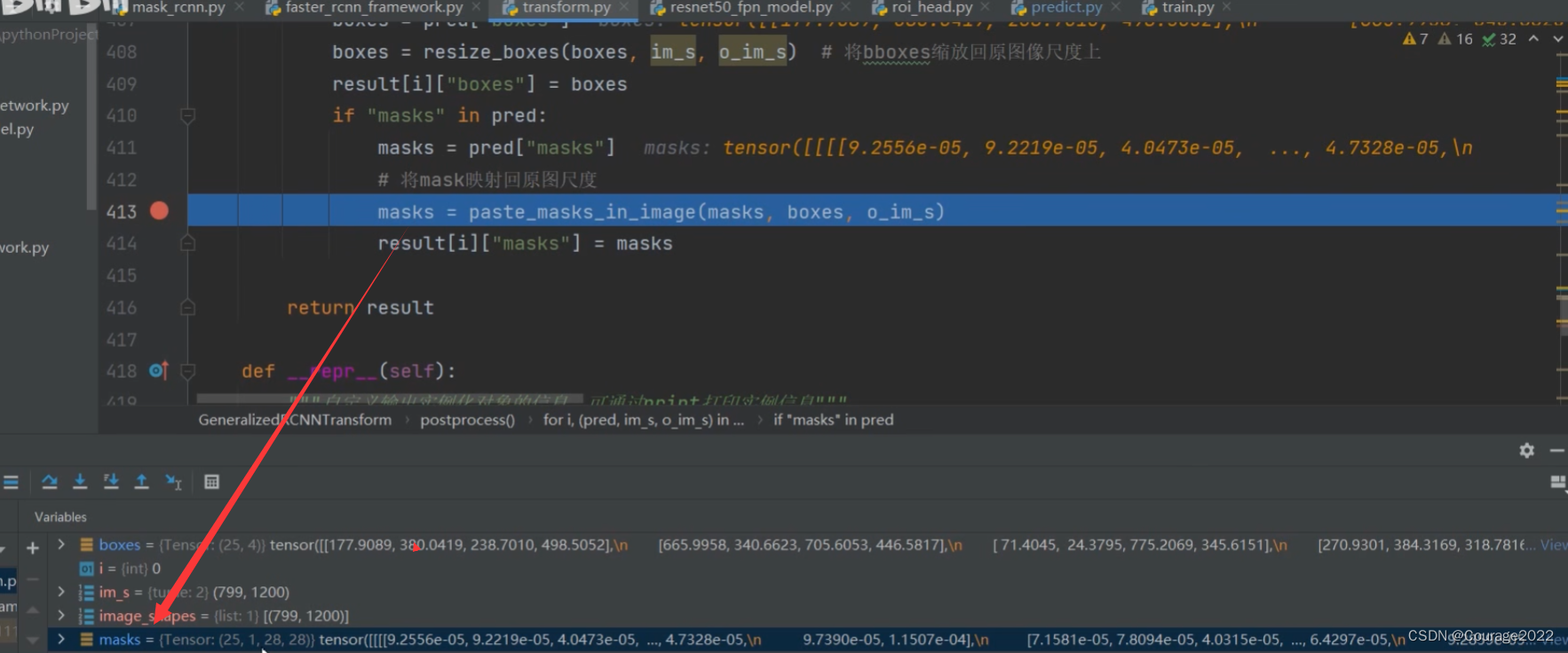
def postprocess(self, result, # type: List[Dict[str, Tensor]] image_shapes, # type: List[Tuple[int, int]] original_image_sizes # type: List[Tuple[int, int]] ): # type: (...) -> List[Dict[str, Tensor]] """ 对网络的预测结果进行后处理(主要将bboxes还原到原图像尺度上) Args: result: list(dict), 网络的预测结果, len(result) == batch_size image_shapes: list(torch.Size), 图像预处理缩放后的尺寸, len(image_shapes) == batch_size original_image_sizes: list(torch.Size), 图像的原始尺寸, len(original_image_sizes) == batch_size Returns: """ if self.training: return result # 遍历每张图片的预测信息,将boxes信息还原回原尺度 for i, (pred, im_s, o_im_s) in enumerate(zip(result, image_shapes, original_image_sizes)): boxes = pred["boxes"] boxes = resize_boxes(boxes, im_s, o_im_s) # 将bboxes缩放回原图像尺度上 result[i]["boxes"] = boxes if "masks" in pred: masks = pred["masks"] # 将mask映射回原图尺度 masks = paste_masks_in_image(masks, boxes, o_im_s) result[i]["masks"] = masks return result在前面所说,我们针对于每个目标都会预测一个
我们可以看到针对我们输入的预测图片有25个目标,每个目标都有一个
通过paste_masks_in_image方法将特征图中的mask映射到原图中,这里传入的参数是:
@masks:待预测回原图的mask信息
@boxes:已经映射回原图的边界框信息
@o_im_s:图像的原始尺寸
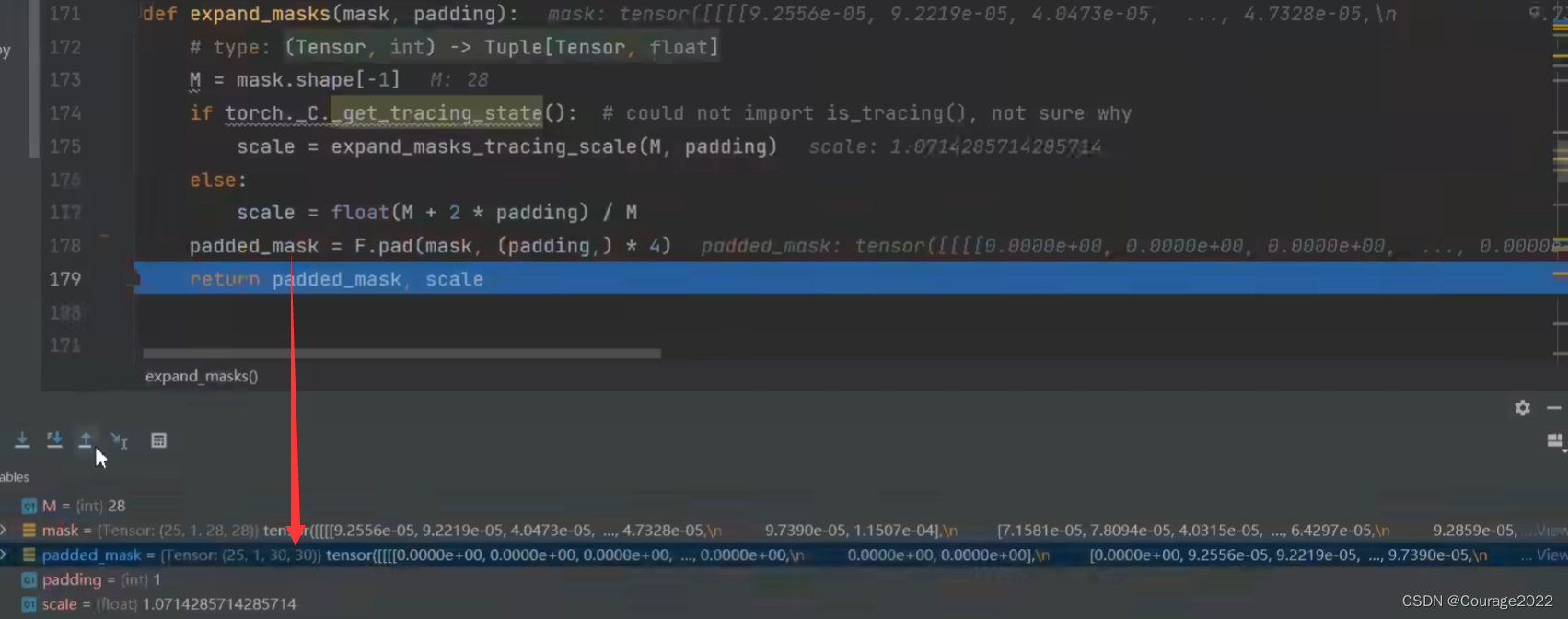
def paste_masks_in_image(masks, boxes, img_shape, padding=1): # type: (Tensor, Tensor, Tuple[int, int], int) -> Tensor # pytorch官方说对mask进行expand能够略微提升mAP # refer to: https://github.com/pytorch/vision/issues/5845 masks, scale = expand_masks(masks, padding=padding) boxes = expand_boxes(boxes, scale).to(dtype=torch.int64) im_h, im_w = img_shape if torchvision._is_tracing(): return _onnx_paste_mask_in_image_loop( masks, boxes, torch.scalar_tensor(im_h, dtype=torch.int64), torch.scalar_tensor(im_w, dtype=torch.int64) )[:, None] res = [paste_mask_in_image(m[0], b, im_h, im_w) for m, b in zip(masks, boxes)] if len(res) > 0: ret = torch.stack(res, dim=0)[:, None] # [num_obj, 1, H, W] else: ret = masks.new_empty((0, 1, im_h, im_w)) return retexpand_masks方法是在特征图周围填充了padding个数的0,即在
的特征图。
scale是在padding前后的缩放因子。为了与目标边界框进行对齐对目标边界框也需要进行一个expand处理。
语句块if torchvision._is_tracing():不会执行。
res = [paste_mask_in_image(m[0], b, im_h, im_w) for m, b in zip(masks, boxes)]同时遍历masks和boxes,将每个目标的mask信息、边界框box信息、原图的高宽输入到paste_mask_in_image方法中。
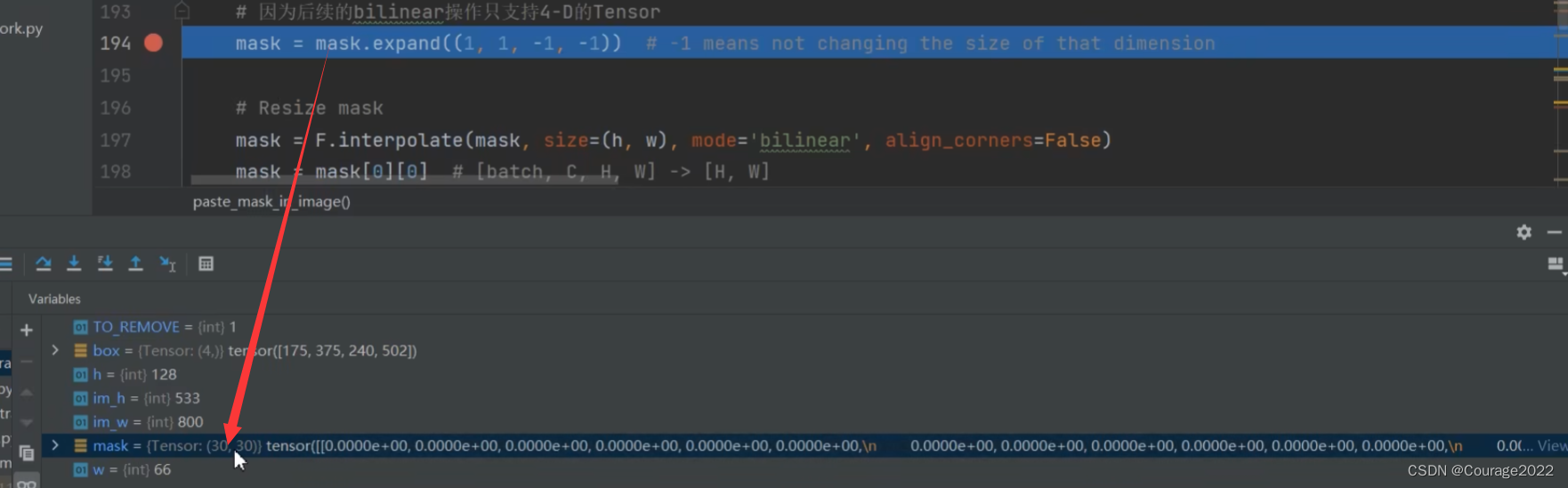
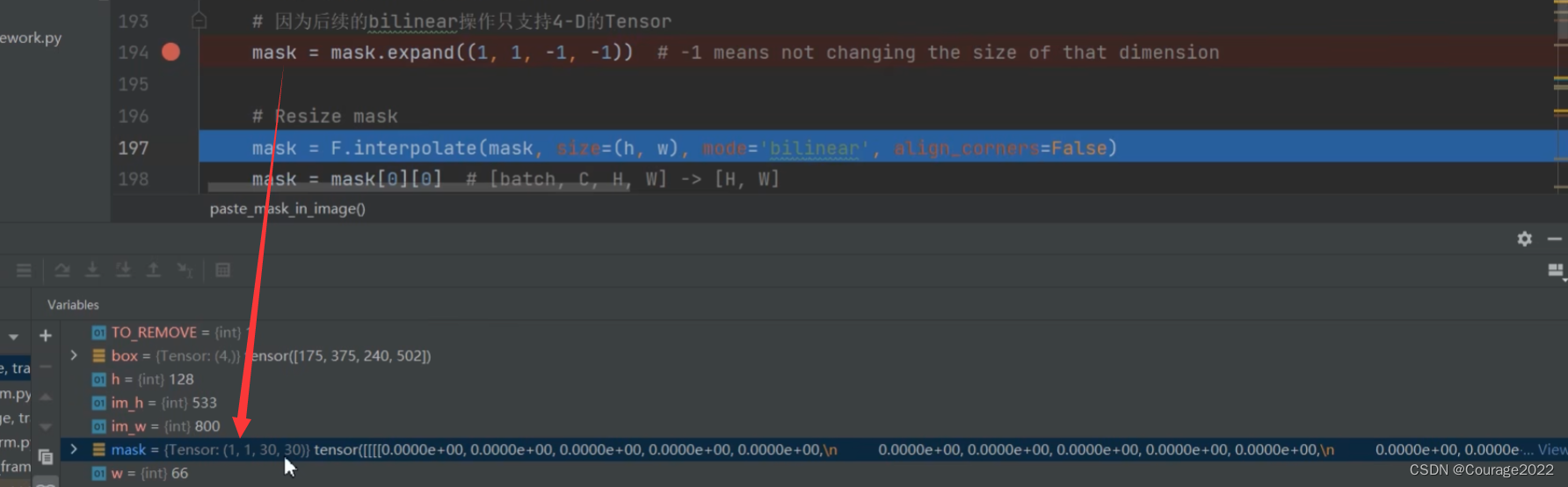
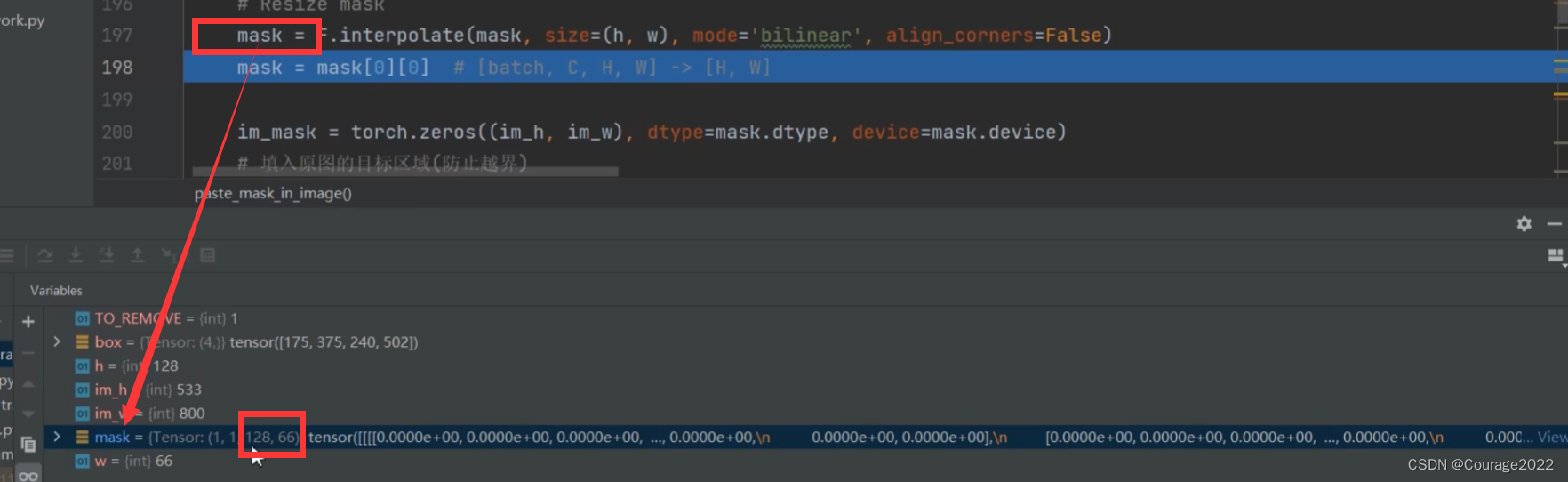
def paste_mask_in_image(mask, box, im_h, im_w): # type: (Tensor, Tensor, int, int) -> Tensor # refer to: https://github.com/pytorch/vision/issues/5845 TO_REMOVE = 1 w = int(box[2] - box[0] + TO_REMOVE) h = int(box[3] - box[1] + TO_REMOVE) w = max(w, 1) h = max(h, 1) # Set shape to [batch, C, H, W] # 因为后续的bilinear操作只支持4-D的Tensor mask = mask.expand((1, 1, -1, -1)) # -1 means not changing the size of that dimension # Resize mask mask = F.interpolate(mask, size=(h, w), mode='bilinear', align_corners=False) mask = mask[0][0] # [batch, C, H, W] -> [H, W] im_mask = torch.zeros((im_h, im_w), dtype=mask.dtype, device=mask.device) # 填入原图的目标区域(防止越界) x_0 = max(box[0], 0) x_1 = min(box[2] + 1, im_w) y_0 = max(box[1], 0) y_1 = min(box[3] + 1, im_h) # 将resize后的mask填入对应目标区域 im_mask[y_0:y_1, x_0:x_1] = mask[(y_0 - box[1]):(y_1 - box[1]), (x_0 - box[0]):(x_1 - box[0])] return im_mask前五行代码进行了一个预处理,我也不太明白,大概的流程是让目标边界框的高度和宽度都是大于1的。我们对图片进行处理的时候是以像素为基准的,也不可能一个目标的高宽小于一个像素吧!!!???
由于我们输入的mask只有高宽信息:
这步是因为我们在进行双线性插值的时候规定的tensor维度是4D的。
利用双线性插值的方法对mask进行尺度还原,与原图片(输入时)大小相等。
再通过切片的方式只把mask的高宽提取出来:
创建一个值为0的tensor,大小和我们的输入预测图片原尺寸相同:防止目标边界框越界,因为我们刚才对目标边界框进行了expand处理可能会出现越界的情况,因此将其裁剪将目标边界框限制在图片内部。
(为什么要+1,切片是左闭右开的形式,为了能够取到xmax和ymax都需要+1)
将mask对应区域的信息填充到创建的im_mask中。这就是将mask映射到原图的主要实现方式。

这里假设黑的的框是原图,橙色对应网络预测的目标边界框,最后一行对应的操作就是将mask中对应图片内部的信息填充到im_mask中,因为经过双线性插值填充过的mask = mask.expand((1, 1, -1, -1)信息可能会把目标边界框信息溢出原图像,因此我们需要进行一个类似移花接木的操作 回到这部分代码:
def paste_masks_in_image(masks, boxes, img_shape, padding=1): # type: (Tensor, Tensor, Tuple[int, int], int) -> Tensor # pytorch官方说对mask进行expand能够略微提升mAP # refer to: https://github.com/pytorch/vision/issues/5845 masks, scale = expand_masks(masks, padding=padding) boxes = expand_boxes(boxes, scale).to(dtype=torch.int64) im_h, im_w = img_shape if torchvision._is_tracing(): return _onnx_paste_mask_in_image_loop( masks, boxes, torch.scalar_tensor(im_h, dtype=torch.int64), torch.scalar_tensor(im_w, dtype=torch.int64) )[:, None] res = [paste_mask_in_image(m[0], b, im_h, im_w) for m, b in zip(masks, boxes)] if len(res) > 0: ret = torch.stack(res, dim=0)[:, None] # [num_obj, 1, H, W] else: ret = masks.new_empty((0, 1, im_h, im_w)) return ret这里得到的res就是将每一个目标的mask蒙版都映射到原图之中了。
如果len(res)大于0表示当前有目标,我们通过stack方法将其拼接在一起。
这时我们的ret的shape如下:
返回的ret就是把所有的mask映射回原图的信息了。
def postprocess(self, result, # type: List[Dict[str, Tensor]] image_shapes, # type: List[Tuple[int, int]] original_image_sizes # type: List[Tuple[int, int]] ): # type: (...) -> List[Dict[str, Tensor]] """ 对网络的预测结果进行后处理(主要将bboxes还原到原图像尺度上) Args: result: list(dict), 网络的预测结果, len(result) == batch_size image_shapes: list(torch.Size), 图像预处理缩放后的尺寸, len(image_shapes) == batch_size original_image_sizes: list(torch.Size), 图像的原始尺寸, len(original_image_sizes) == batch_size Returns: """ if self.training: return result # 遍历每张图片的预测信息,将boxes信息还原回原尺度 for i, (pred, im_s, o_im_s) in enumerate(zip(result, image_shapes, original_image_sizes)): boxes = pred["boxes"] boxes = resize_boxes(boxes, im_s, o_im_s) # 将bboxes缩放回原图像尺度上 result[i]["boxes"] = boxes if "masks" in pred: masks = pred["masks"] # 将mask映射回原图尺度 masks = paste_masks_in_image(masks, boxes, o_im_s) result[i]["masks"] = masks return result输出的mask就是我们得到的经过输入的mask映射回原图的信息了,将mask信息存入到网络预测结果中。我们的Mask RCNN网络也就到此结束了。
相关文章
- 【Python3网络爬虫开发实战】1.2.5-PhantomJS的安装
- 《UNIX网络编程(第3版)》unp.h等源码文件的编译安装
- Linux网络下载命令 wget 简介
- 深度学习Bible学习笔记:第六章 深度前馈网络
- Go netpoll I/O 多路复用构建原生网络模型之源码深度解析
- K8S Flannel网络组件介绍及作用:让集群中不同节点创建的docker容器都具有全集群唯一的虚拟IP地址
- Atitit web 3.0(web技术)展望与实现 和语义网络 目录 1. 为了说明Web 3.0,我们需要回顾Web历史上的重要浪潮。2 1.1. 2.Web 2.0:任何人可以参与。Web
- pytorch手写数字识别验证四流网络
- jittor和pytorch生成网络对比之began
- 网络聊天室
- 第二人生的源码分析(二十九)Windows网络初始化
- 零基础自学用Python 3开发网络爬虫
- Windiws10系统不显示可用网络的处理方法!
- 姿态估计0-09:DenseFusion(6D姿态估计)-源码解析(5)-PoseRefineNet网络与loss详解(重点篇)
- 前端网络基础 - axios源码分析
- Faster RCNN网络源码解读(Ⅸ) --- ROIAlign、TwoMLPHead、FastRCNNPredictor部分解析
- Faster RCNN网络源码解读(Ⅶ) --- RPN网络代码解析(中)RegionProposalNetwork类解析
- Faster RCNN网络源码解读(Ⅵ) --- RPN网络代码解析(上)RPNHead类与AnchorsGenerator类解析
- Faster RCNN网络源码解读(Ⅱ) --- Faster RCNN源码使用
- Mask RCNN网络源码解读(Ⅵ) --- 自定义数据集读取:MS COCO&Pascal VOC
- Mask RCNN网络源码解读(Ⅱ) --- ResNet、ResNeXt网络结构、BN及迁移学习
- Mask RCNN网络源码解读(Ⅰ) --- 语义分割前言与转置卷积
- RCNN网络源码复现(Ⅵ) --- 非极大值抑制及测试模型(完结撒花)
- RCNN网络源码复现(Ⅴ) --- 训练SVM二分类模型的训练过程
- RCNN网络源码解读(Ⅲ) --- finetune训练过程
- RCNN网络源码解读(Ⅱ) --- 使用IOU计算正负样本用于finetune训练
- Docker NameSpace 对 进程 ID、主机名、用户 ID、文件名、网络和进程间通信等资源隔离