
RCNN网络源码解读(Ⅱ) --- 使用IOU计算正负样本用于finetune训练
目录
2.1 code(cerate_classifier_data.py)
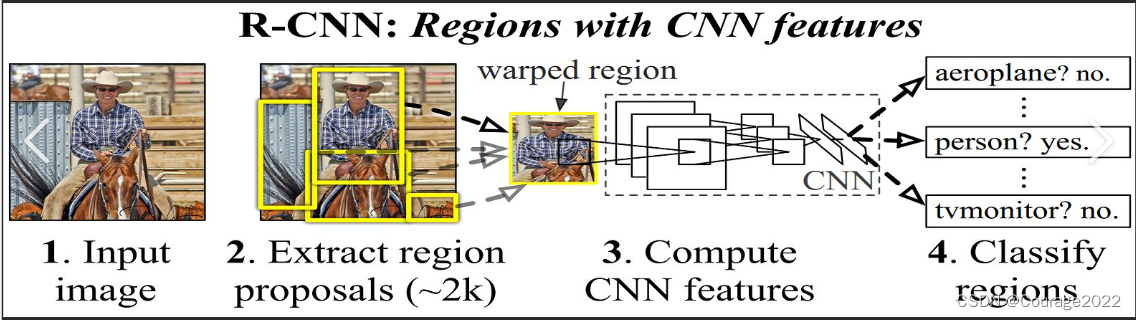
1.预训练二分类器Alexnet
1.1 code(finetune.py)
1.引入头文件
import os import copy import time import torch import torch.nn as nn import torch.optim as optin from torch.utils.data import DataLoader import torchvision.transforms as transforms import torchvision.models as models from utils.data.custom_finetune_dataset import customFinetuneDataset from utils.data.custom_batch_sampler import CustomBatchSampler from utils.util import check_dir在torchvision.models里面存放了Alexnet的模型。
2.主函数
from image_handler import show_images import numpy as np if __name__ == ' __main__': device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") data_loaders,data_sizes = load_data('./data/classifier_car') #加载alexnet神经网洛 model = models.alexnet(pretraine = True) print(model) data_loader = data_loaders["train"] print("一次迭代取得所有的正负数据,如果是多个类则取得多类数据集合") """ index: 323 inage_id: 200 target: 1 image.shape: (254,342,3)[xmin,ymin,xnax,ymax]: [80,39,422,293] """ inputs,targets = next(data_loader.__iter__()) print(inputs[0].size(),type(inputs[0])) trans = transforms.ToPILImage() print(type(trans(inputs[0]))) print(targets) print(inputs.shape) titles = ["TRUE" if i.item() else "False" for i in targets[0:60]] images = [np.array(trans(i))for i in inputs[0:60]] show_images(images,titles=titles,num_cols=12) # #把alexnet变成二分类模型,在最后一行改为2分类。 num_features = model.classifier[6].in_features model.classifier[6] = nn.Linear(num_features,2) print("记alexnet变成二分类模型,在最后一行改为2分类",model) model = model.to(device) criterion = nn.CrossEntroyLoss() optimizer = optim.SGD(model.parameters(),lr=1e-3, momentum=0.9) lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=7,gamma=0.1) best_model = train_model(data_loaders,model,criterion,optimizer,lr_scheduler,device=device num_epachs=10) check_dir('./models') torch.save(best_model.state_dict(),'models/alexnet_car.pth ')这里需要指出,pretrain参数是指是否要进行迁移学习,为true则表示将先人训练好的参数我们拿来使用,我们无需重新训练。即数据集处理完之后,我们使用finetune方法alexnet的网络模型和参数做二分类,因此我们要对二分类的数据集进行训练。
因此我们第一步处理完数据集后,还要对二分类的数据集进行处理!
这个函数下节说!
2.二分类数据集处理
2.1 code(cerate_classifier_data.py)
1.主函数如下
if __namne__== '__main__': car_root_dir = '../../data/voc_car/' classifier_root_dir = '../../data/classifier_car/' check_dir(classifier_root_dir) gs = selectivesearch.get_selective_search() for name in ['train' , 'val' ]: #以voc_car目录下的文件为源头 src_root_dir = os.path.join(car_root_dir,name) src_annotation_dir = os.path.join(src_root_dir,'Annotations') src_jpeg_dir = os.path.join(src_root_dir,'JPEGImages') #以classifier_car目录下的文件为目的 #dst_root_dir = data/classifier_car/(train/val) #dst_annotation_dir = data/classifier_car/(train/val)/Annotations #dst_jpeg_dir = data/classifier_car/(train/val)/JPEGImages dst_root_dir = os.path.join(classifier_root_dir,name) dst_annotation_dir = os.path.join(dst_root_dir,'Annotations') dst_jpeg_dir = os.path.join(dst_root_dir,'JPEGImages') #创建 classifier_car目录下的目录结构 check_dir(dst_root_dir) check_dir(dst_annotation_dir) check_dir(dst_jpeg_dir) total_num_positive = 0 total_numn_negative = 0 #每个samples就是一条图片信息 voc_car/train(val)/car.csv samples = parse_car_csv(src_root_dir) #将源目录中的csv文件复制到classifier_car下面 src_csv_path = os.path.join(src_root_dir, 'car.csv') dst_csv_path = os.path.join(dst_root_dir,'car.csv') #data/voc_car/train(val)/car.csv #data/classifier_root_dir/train(val)/car.csv shutil.copyfile(src_csv_path, dst_csv_path) for sample_name in samples: #开始处理每一张图片 try: since = time.time() #将csv文件中的文件名补0得到正式的文件名 sample_name = sample_name.zfill(6) #取得源标注信息 #data/voc_car/(train/val)/Annotations/xxxxxx.xml src_annotation_path = os.path.join(src_annotation_dir,sample_name + '.xml') #取得源图片 #data/voc_car/(train/val)/JPEGImages/xxxxxx.img src_jpeg_path = os.path.join(src_jpeg_dir,sample_name+'.jpg') ##获取正负样本,正样本就是voc标识框,因此无需在进行加和处理 #返回的是一个rect的列表 positive_list,negative_list =parse_annotation_jpeg(src_annotation_path,src_jpeg_path,gs) total_num_positive = len(positive_list) total_num_negative = len(negative_list) # data/classifier_car/(train/val)/Annotations/xxxxxx_1.csv # data/classifier_car/(train/val)/Annotations/xxxxxx_0.csv dst_annotation_positive_path = os.path.join(dst_annotation_dir,sample_name + '_1' + '.csv') dst_annotation_negative_path = os.path.join(dst_annotation_dir,sample_name + '_0'+ '.csv") #data/classifier_car/(train/val)/JPEGImages/xxxxxx.jpg dst_jpeg_path = os.path.join(dst_jpeg_dir,sample_name+'.jpg') #保存图片 #data/voc_car/(train/val)/JPEGImages/xxxxxx.img #data/classifier_car/(train/val)/JPEGImages/xxxxxx.jpg shutil.copyfile(src_jpeg_path, dst_jpeg_path) #保存正负样本标注 np.savetxt(dst_annotation_positive_path,np.array(positive_list),fmt= '%d',delimiter=' ') np.savetxt(dst_annotation_negative_path,np.array(negative_list),fmt= '%d',delimiter=' ') time_elapsed = time.time()-since print('parse {}.png in {:.Of}m {:.0f)s'.format(sample_name,time_elapsed //60,time_elapsed % 60)) except Exception as err: print(err) continue print('%s positive num:%d' % (name,total_num_positive)) print("%s negative num:%d' % (name,total_num_negative)) print( " done ' )我们来看这段代码,car_root_dir 是我们上一篇博客说的从VOC数据集中抽取car数据集的目录,classifier_root_dir 是我们这步想要对二分类的数据集进行处理的目录,然后我们创建这个目录。
这个函数的目的是改变标注形式,原来我们在car_root_dir 中的标注形式是这样的:

car_root_dir 中的标注形式 在这一步中我们要将数据格式处理成这种:
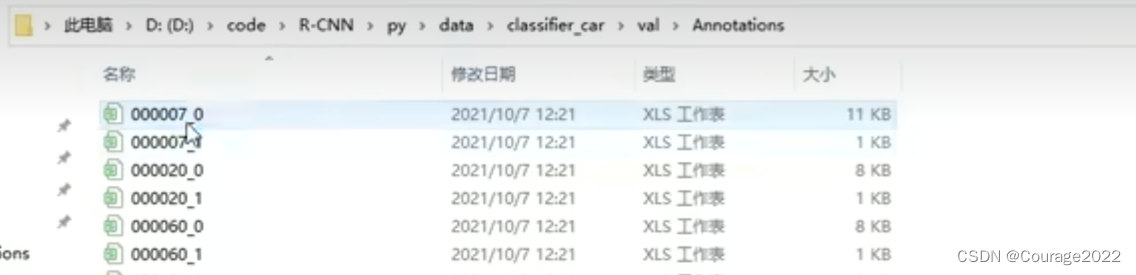
classifier_root_dir 中的标注形式(1) 每一个文件是这样的,这里的东西就是我们通过区域候选建议生成的一个个的候选框。

classifier_root_dir 中的标注形式(2) _0表示是一个负例,即候选框里面没有汽车。_1表示一个正例,即候选框里面有汽车。.
那如何确认正例负例呢:因为我们的标注文件里面有bndbox选项(即标注好的框大小),我们拿每一个经过区域候选建议生成的框和标注框体计算IOU并满足一定条件,则将候选框体标注为正例,否则标注为负例。
selectivesearch是一个.py文件我们上一讲说过,get_selective_search是里面的一个函数,最终返回给gs获取候选框。
其他的细节见标注。
2.get_selective_search
def get_selective_search(): gs = cv2.ximgproc.segmentation.createselectiveSearchSegmentation() return gs返回候选框。
3.parse_car_csv
def parse_car_csv(csv_dir): csv_path = os.path.join(csv_dir, 'car.csv') samples = np.loadtxt(csv_path, dtype=np.str) return samples获取csv内容,每个samples就是一条图片信息。
4.parse_annotation_jpeg
# train # positive num: 625 # negative num: 366028 # val # positive num: 624 # negative num: 321474 @data/voc_car/(train/val)/Annotations/xxxxxx.xml @data/voc_car/(train/val)/JEPGImage/xxxxxx.jpg def parse_annotation_jpeg(annotation_path,jpeg_path,gs): """ 获取正负样本(注:忽略属性difficult = True的标注边界框) 正样本:标注边界框 负杆本:IoU大于0,小于等于0.3。为了进一步限制负样本数目,其大小必须大于标注框的1/5 """ print("jpeg_path",jpeg_path) #打开该文件 img = cv2.imread(jpeg_path) selectivesearch.config(gs,img,strategy='q') #计算候选建议 nects = selectivesearch.get_rects(gs) print("rects",len(rects)) #获取标注边界框 bndboxs = parse_xml(annotation_path) print("bndboxs", bndboxs) #标注框大小,如果有多个边界框,则叹得最大的边界框大小 maximum_bndbox_size = 0 for bndbox in bndboxs: xmin, ymin , xmax , ymax = bndbox bndbox_size = (ymax - ymin)*(xmax - xmin) if bndbox_size > maximum_bndbox_size: maximum_bndbox_size = bndbox_size #获取候选建该和标注边界框的IoU,输入为 iou_list = compute_ious(rects,bndboxs) print("计算预选框和实框的iou列表",len(iou_list)) positive_list = list() negative_list = list() #iou_list和 rect 列表长度应该一致 for i in range(len(iou_list)): xmin,ymin,xmax,ymax = rects[i] rect_size = (ymax - ymin) * (xmax - xmin) iou_score = iou_list[i] #如果某个框体的iou值在0-0.3之间且框体大少低于真实框体的五分之一 if 0 < iou_score <= 0.3 and rect_size > maximum_bndbox_size / 5.0: #负样本 negative_list.append(rects[i]) else: pass #返回预测框体和负样本框体列表 retunn bndboxs,negative_list①compute_ious(rects,bndboxs):这里调用函数计算IOU,输入是利用区域候选建议计算出来的很多框,bandbox是该图片的真实的框体。
②此函数返回给上层函数什么:正样本 and 负样本列表
正样本只返回了标注框(即)@data/voc_car/(train/val)/Annotations/xxxxxx.xml中的框
负样本返回了满足iou以及框体大小条件的框。
!要记得还有没在负列表和正列表的框呢
5.iou 计算交并比
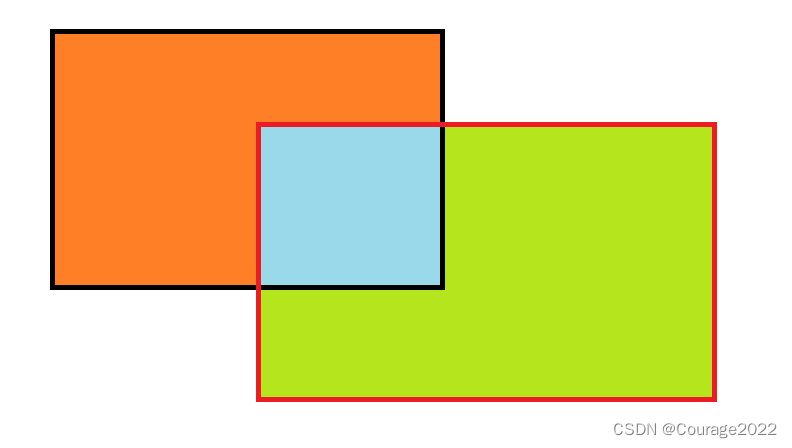
简单来说,交并比就是交集/并集的比值,即蓝色区域/(绿色区域+橙色区域)的比值。
def compute_ious(rects,bndboxs): iou_list = list() for rect in rects: # iou计算一个rect和指定的多个框的iou值,如果bndboxs是多个,则得到的结果也是多个值的列表。 scores = iou(rect,bndboxs) #取得预选桩和最终判定框体之间iou最大的那个值。组成iou列表。 iou_list.append(max(scores)) return iou_listdef iou(pred_box, target_box): """ 计算候选建议框和标注框的IoU :param pred_box:大小为[4] :param target_box:大小为[N,4] :return: [N] """ if len(target_box.shape) == 1: target_box = tanget_box[np.newaxis,:] xA = np.maximum(pred_box[0],target_box[:,0]) yA = np.maximum(pred_box[1],target_box[:,1]) xB = np.minimum(pred_box[2],target_box[:,2]) yB = np.minimum(pred_box[3],target_box[:,3]) #计算交集面积 intersection = np.maximum(0.0,xB - xA) * np.maximum(0.0,yB - yA) #计算两个边界框面积 boxAArea = (pred_box[2] - pred_box[0]) * (pred_box[3] - pred_box[1]) boxBArea = (target_box[:,2] - target_box[:,0])* (target_box[:,3]- target_boxt:,1]) scores = intersection / (boxAArea + boxBArea - intersection) return scores为了更好的理解,看下列代码;
import numpy as np X = np.array([[0,1],[2,3],[4,5],[6,7],[8,9],[10,11],[12,13],[14,15],[16,17],[18,19]]) print X[:,0]
x[n,:]表示在n个数组(维)中取全部数据,直观来说,x[n,:]就是取第n集合的所有数据,
iou函数中targetbox的形式是N个框,每个框是4维的。那么这里xA,xB,yB,yB都是N维的,score也是N维的。记录N个标注框和区域候选框的IoU分数。
compute_ious只返回分数最高的iou值。compute_ious最终返回是一张图片的每个区域建议候选框与标注文件中rect的IoU值的列表。即有多少个预选框,我们就有多少个IoU值。

相关文章
- Java实现 蓝桥杯 算法训练 多阶乘计算
- Java实现 蓝桥杯 算法训练 多阶乘计算
- Java实现 蓝桥杯 算法训练 Airport Configuration
- Java实现 蓝桥杯 算法训练 天数计算
- Java实现 蓝桥杯VIP 算法训练 sign函数
- Java实现 蓝桥杯VIP 算法训练 连接字符串
- Java实现 蓝桥杯VIP 算法训练 平方计算
- Java实现 蓝桥杯VIP 算法训练 平方计算
- Java实现 蓝桥杯VIP 算法训练 矩阵加法
- Java实现 蓝桥杯VIP 算法训练 入学考试
- Java实现 蓝桥杯VIP 算法训练 薪水计算
- Java实现 蓝桥杯VIP 算法训练 薪水计算
- Java实现 蓝桥杯VIP 算法训练 薪水计算
- Java实现 蓝桥杯VIP 算法训练 最大值与最小值的计算
- Java实现 蓝桥杯VIP 算法训练 最大值与最小值的计算
- Java实现 蓝桥杯VIP 算法训练 猴子分苹果
- Java实现 蓝桥杯VIP 算法训练 阶乘末尾
- Java实现 蓝桥杯 算法训练 Anagrams问题
- keras系列︱图像多分类训练与利用bottleneck features进行微调(三)
- 机器学习入门15 - 训练神经网络 (Training Neural Networks)
- Python:python语言中与时间有关的库函数简介、安装、使用方法(获取当前时间/计算程序块前后运行时间/模型训练时间或耗费时间)之详细攻略
- NLP:自然语言处理技术领域的代表性算法概述(技术迭代路线图/发展时间路线)、四大技术范式变迁概述(统计时代→大模型时代)、四个时代的技术方法论探究(少数公司可承担的训练成本原因)之详细攻略
- ML之xgboost:利用xgboost算法(自带特征重要性可视化+且作为阈值训练模型)训练mushroom蘑菇数据集(22+1,6513+1611)来预测蘑菇是否毒性(二分类预测)
- DL之DNN:自定义2层神经网络TwoLayerNet模型(计算梯度两种方法)利用MNIST数据集进行训练、预测
- DL之CNN:自定义SimpleConvNet【3层,im2col优化】利用mnist数据集实现手写数字识别多分类训练来评估模型
- Python:python语言中与时间有关的库函数简介、安装、使用方法(获取当前时间/计算程序块前后运行时间/模型训练时间或耗费时间)之详细攻略
- torch.nn.DataParallel()--多个GPU加速训练
- 【ChatGPT】ColossalChat:目前最接近 ChatGPT 原始技术方案的实用开源项目——以 LLaMA 为基础预训练模型,推出 ColossalChat
- POJ训练计划2418_Hardwood Species(Trie树)
- 天天快乐编程集训队2021暑假训练-0810-数据结构题解
- 一个基于特征向量的近似网页去重算法——term用SVM人工提取训练,基于term的特征向量,倒排索引查询相似文档,同时利用cos计算相似度
- 【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】1 初赛Rank12的总结与分析
- 行为分析(商用级别)04 -训练、评估、demo测试自定义的数据集-落地核心关键(重点篇)